ELLEN
1.0.0
Dans ce travail, nous revisitons le problème de la reconnaissance de l'entité nommée semi-supervisée (NER) se concentrant sur une supervision extrêmement légère, composée d'un lexique ne contenant que 10 exemples par classe. Nous présentons Ellen, une méthode simple, entièrement modulaire, neuro-symbolique qui mélange des modèles de langage affinés avec des règles linguistiques. Ces règles incluent des informations telles que «un sens par discours», en utilisant un modèle de langage masqué comme un NER non supervisé, en tirant parti des étiquettes de disposition pour identifier et éliminer les entités non marquées comme de faux négatifs et d'autres intuitions sur les scores de confiance des classificateurs dans le contexte local et mondial. Ellen obtient des performances très solides sur l'ensemble de données CONLL-2003 lors de l'utilisation de la supervision minimale du lexique ci-dessus. Il surpasse également les méthodes NER semi-supervisées les plus existantes (et considérablement plus complexes) dans les mêmes paramètres de supervision couramment utilisés dans la littérature (c'est-à-dire 5% des données de formation). De plus, nous évaluons notre modèle CONLL-2003 dans un scénario zéro-shot sur WNUT-17 où nous constatons qu'il surpasse GPT-3.5 et atteint des performances comparables à GPT-4. Dans un réglage zéro-shot, Ellen obtient également plus de 75% des performances d'un modèle solide et entièrement supervisé formé sur les données d'or.
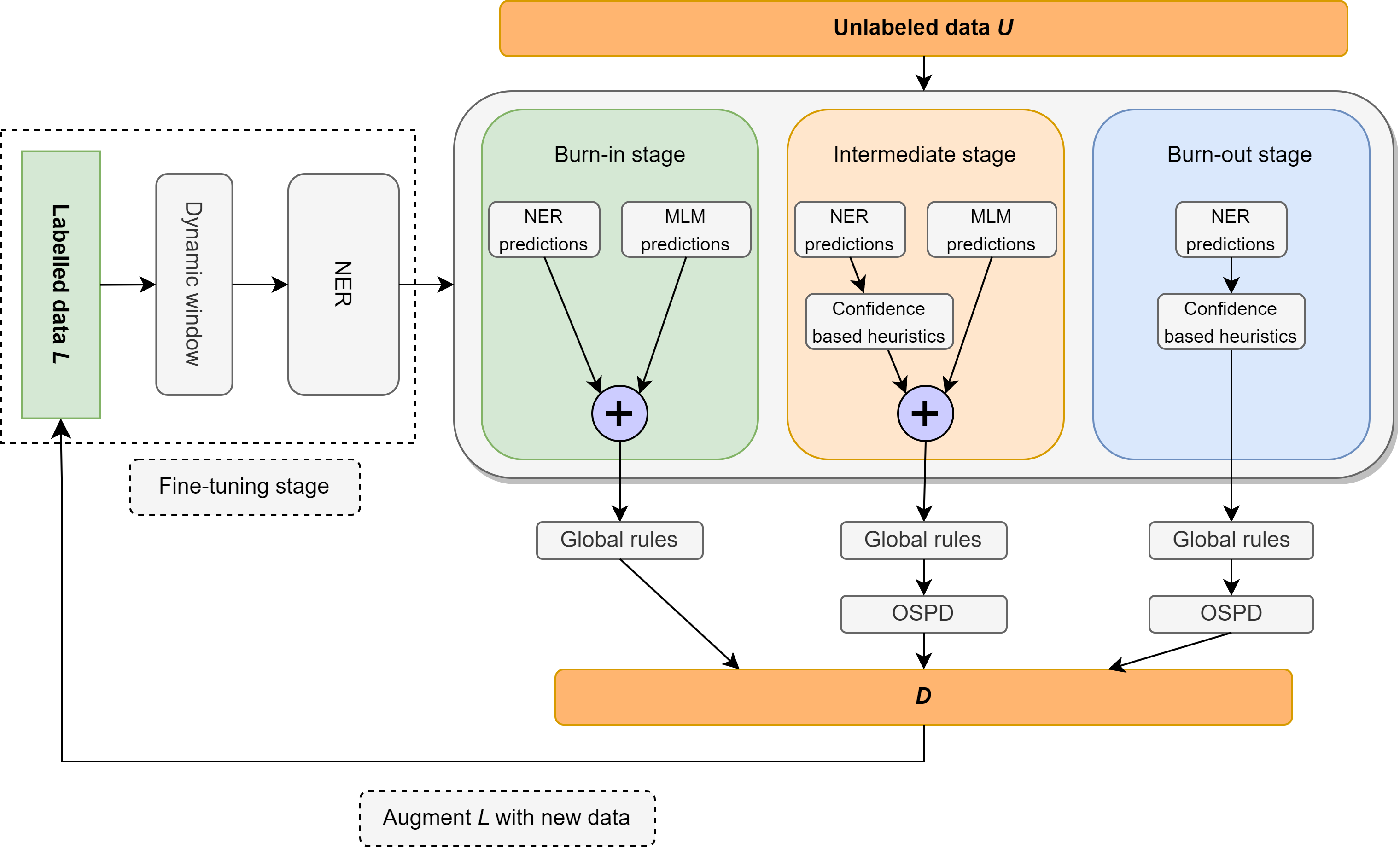
Le code prêt à la caméra sera publié bientôt.
| Précision | Rappel | F1 |
|---|---|---|
| 74,63% | 79,26% | 76,87% |
Ellen † surpasse les méthodes plus complexes telles que le PU-Learning et les étiqueteurs séquentiels variationnels (VSL-GG-HIER) lors de l'utilisation de 5% des données comme supervision.
| Méthodes | P | R | F1 |
|---|---|---|---|
| VSL-GG-HIER | 84,13% | 82,64% | 83,38% |
| MT + bruit | 83,74% | 81,49% | 82,60% |
| Semi-lada | 86,93% | 85,74% | 86,33% |
| Conjoint | 89,88% | 85,98% | 87,68% |
| Ventilateur | 85,79% | 81,03% | 83,34% |
| Ellen † | 81,88% | 88,01% | 84,87% |
| Méthode | Localiser | Mission | Org | PAR | AVG |
|---|---|---|---|---|---|
| T-ner | 64,21% | 42,04% | 42,98% | 66,11% | 55,11% |
| GPT-3.5 | 49,17% | 8,06% | 29,71% | 59,84% | 39,96% |
| Gpt-4 | 58,70% | 25,40% | 38,05% | 56,87% | 43,72% |
| Ellen + | 44,82% | 6,21% | 26,49% | 67,00% | 41,56% |
Nous introduisons une ligne de base très forte pour le NER entièrement non supervisé en utilisant moins de 10 coups (plus de 56% F1 sur CONLL-03 Dev!)
| Type d'entité | Précision | Rappel | F1 |
|---|---|---|---|
| Dans l'ensemble | 61,78% | 51,90% | 56,41% |
| Localiser | 69,72% | 41,53% | 52,05% |
| Mission | 45,18% | 55,15% | 49,67% |
| Org | 44,85% | 40,88% | 42,77% |
| PAR | 85,07% | 65,02% | 73,71% |
Si vous trouvez ce travail utile, veuillez envisager de citer:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Le code publié dans ce référentiel sera gratuit pour la plupart des circonstances dans le cadre de la licence MIT.
Haris Riaz ([email protected]) ou ([email protected])


