ELLEN
1.0.0
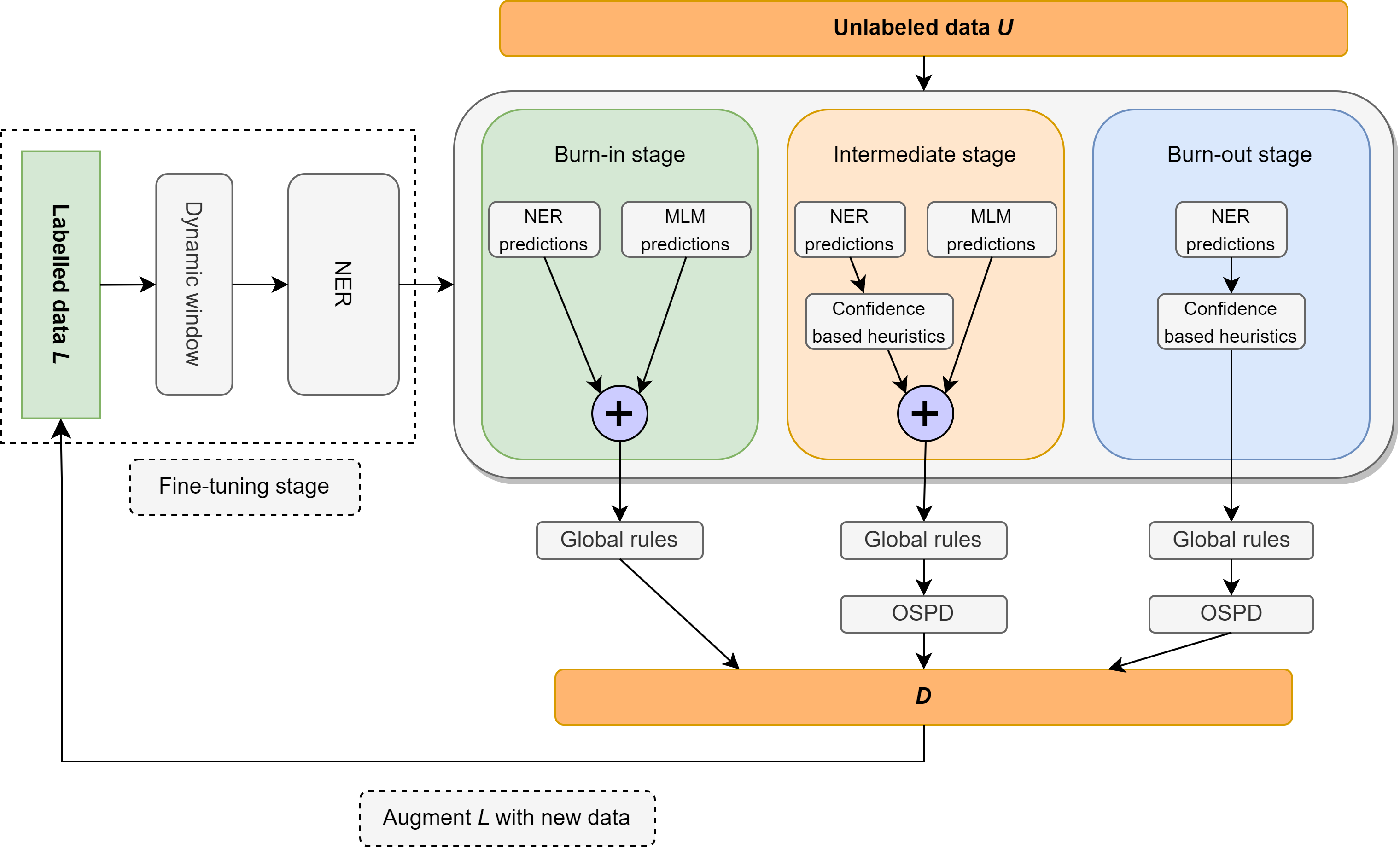
Dalam karya ini, kami meninjau kembali masalah pengakuan entitas bernama semi-diawasi (NER) yang berfokus pada pengawasan yang sangat ringan, yang terdiri dari leksikon yang hanya berisi 10 contoh per kelas. Kami memperkenalkan Ellen, metode simbolik neuro-simbolik yang sederhana, sepenuhnya modular yang memadukan model bahasa yang disesuaikan dengan aturan linguistik. Aturan-aturan ini mencakup wawasan seperti "satu indera per wacana", menggunakan model bahasa bertopeng sebagai NER yang tidak diawasi, memanfaatkan tag sebagian pidato untuk mengidentifikasi dan menghilangkan entitas yang tidak berlabel sebagai negatif palsu, dan intuisi lainnya tentang skor kepercayaan diri dalam konteks lokal dan global. Ellen mencapai kinerja yang sangat kuat pada dataset CONLL-2003 saat menggunakan pengawasan minimal dari leksikon di atas. Ini juga mengungguli sebagian besar metode NER semi-diawasi yang ada (dan jauh lebih kompleks) di bawah pengaturan pengawasan yang sama yang biasa digunakan dalam literatur (yaitu, 5% dari data pelatihan). Lebih lanjut, kami mengevaluasi model CONLL-2003 kami dalam skenario zero-shot di WNUT-17 di mana kami menemukan bahwa itu mengungguli GPT-3.5 dan mencapai kinerja yang sebanding dengan GPT-4. Dalam pengaturan zero-shot, Ellen juga mencapai lebih dari 75% kinerja model yang kuat dan diawasi sepenuhnya dilatih pada data emas.
Kode siap kamera akan segera dirilis.
| Presisi | Mengingat | F1 |
|---|---|---|
| 74,63% | 79,26% | 76,87% |
Ellen † mengungguli metode yang lebih kompleks seperti label pu-learning dan variasional sekuensial (VSL-GGS-Hier) saat menggunakan 5% dari data sebagai pengawasan.
| Metode | P | R | F1 |
|---|---|---|---|
| VSL-GG-Hier | 84,13% | 82,64% | 83,38% |
| Mt + noise | 83,74% | 81,49% | 82,60% |
| Semi-lada | 86,93% | 85,74% | 86,33% |
| Jointprop | 89,88% | 85,98% | 87,68% |
| Pu-learning | 85,79% | 81,03% | 83,34% |
| Ellen † | 81,88% | 88,01% | 84,87% |
| Metode | Loc | Misc | Org | PER | Rata -rata |
|---|---|---|---|---|---|
| T-ner | 64,21% | 42,04% | 42,98% | 66,11% | 55,11% |
| GPT-3.5 | 49,17% | 8,06% | 29,71% | 59,84% | 39,96% |
| GPT-4 | 58,70% | 25,40% | 38,05% | 56,87% | 43,72% |
| Ellen+ | 44,82% | 6,21% | 26,49% | 67,00% | 41,56% |
Kami memperkenalkan garis dasar yang sangat kuat untuk NER yang sepenuhnya tidak diawasi menggunakan kurang dari 10-tembakan (lebih dari 56% F1 pada Conll-03 Dev!)
| Tipe entitas | Presisi | Mengingat | F1 |
|---|---|---|---|
| Keseluruhan | 61,78% | 51,90% | 56,41% |
| Loc | 69,72% | 41,53% | 52,05% |
| Misc | 45,18% | 55,15% | 49,67% |
| Org | 44,85% | 40,88% | 42,77% |
| PER | 85,07% | 65,02% | 73,71% |
Jika Anda menemukan pekerjaan ini bermanfaat, harap pertimbangkan mengutip:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Kode yang dirilis dalam repositori ini akan bebas digunakan untuk sebagian besar keadaan di bawah lisensi MIT.
Haris Riaz ([email protected]) atau ([email protected])


