ELLEN
1.0.0
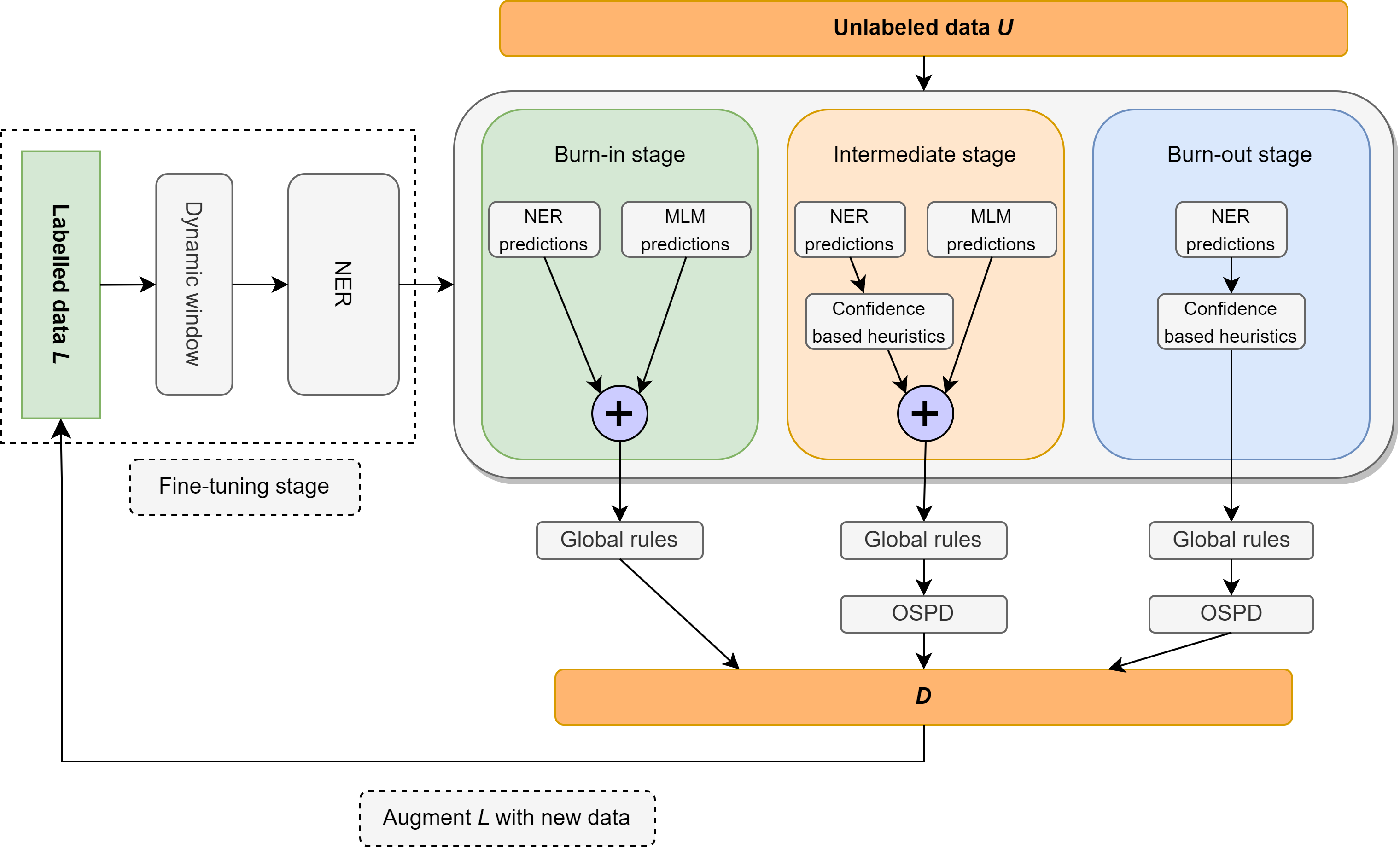
En este trabajo, revisamos el problema del reconocimiento de entidad con nombre semi-supervisado (NER) centrado en la supervisión extremadamente ligera, que consiste en un léxico que contiene solo 10 ejemplos por clase. Introducimos a Ellen, un método neuroimbólico simple, totalmente modular, que combina modelos de lenguaje sintonizados con reglas lingüísticas. Estas reglas incluyen ideas como "un sentido por discurso", utilizando un modelo de lenguaje enmascarado como un NER no supervisado, aprovechando las etiquetas de parte del voz para identificar y eliminar entidades no etiquetadas como falsos negativos, y otras intuiciones sobre los puntajes de confianza clasificadores en el contexto local y global. Ellen logra un rendimiento muy fuerte en el conjunto de datos Conll-2003 cuando usa la supervisión mínima del léxico anterior. También supera a la mayoría de los métodos NER semi-supervisados existentes (y considerablemente más complejos) bajo los mismos entornos de supervisión comúnmente utilizados en la literatura (es decir, el 5% de los datos de capacitación). Además, evaluamos nuestro modelo Conll-2003 en un escenario de disparo cero en WNUT-17, donde encontramos que supera a GPT-3.5 y logra un rendimiento comparable a GPT-4. En un entorno de disparo cero, Ellen también logra más del 75% del rendimiento de un modelo fuerte y totalmente supervisado entrenado en datos de oro.
El código listo para la cámara se lanzará pronto.
| Precisión | Recordar | F1 |
|---|---|---|
| 74.63% | 79.26% | 76.87% |
Ellen † supera los métodos más complejos, como el aprendizaje PU y los etiquetadores secuenciales variacionales (VSL-SGG-Hier) cuando usan el 5% de los datos como supervisión.
| Métodos | PAG | Riñonal | F1 |
|---|---|---|---|
| VSL-SGG-HIER | 84.13% | 82.64% | 83.38% |
| Mt + ruido | 83.74% | 81.49% | 82.60% |
| Semi-lada | 86.93% | 85.74% | 86.33% |
| Articulación | 89.88% | 85.98% | 87.68% |
| Aprendizaje | 85.79% | 81.03% | 83.34% |
| Ellen † | 81.88% | 88.01% | 84.87% |
| Método | Loc | Maga | Organizar | POR | Aviso |
|---|---|---|---|---|---|
| T-ganador | 64.21% | 42.04% | 42.98% | 66.11% | 55.11% |
| GPT-3.5 | 49.17% | 8.06% | 29.71% | 59.84% | 39.96% |
| GPT-4 | 58.70% | 25.40% | 38.05% | 56.87% | 43.72% |
| Ellen+ | 44.82% | 6.21% | 26.49% | 67.00% | 41.56% |
Introducimos una línea de base muy fuerte para NER totalmente sin supervisión que usa menos de 10 disparos (más del 56% F1 en el desarrollo de Conll-03!)
| Tipo de entidad | Precisión | Recordar | F1 |
|---|---|---|---|
| En general | 61.78% | 51.90% | 56.41% |
| Loc | 69.72% | 41.53% | 52.05% |
| Maga | 45.18% | 55.15% | 49.67% |
| Organizar | 44.85% | 40.88% | 42.77% |
| POR | 85.07% | 65.02% | 73.71% |
Si encuentra útil este trabajo, considere citar:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
El código publicado en este repositorio será gratuito para la mayoría de las circunstancias bajo la licencia MIT.
Haris Riaz ([email protected]) o ([email protected])


