ELLEN
1.0.0
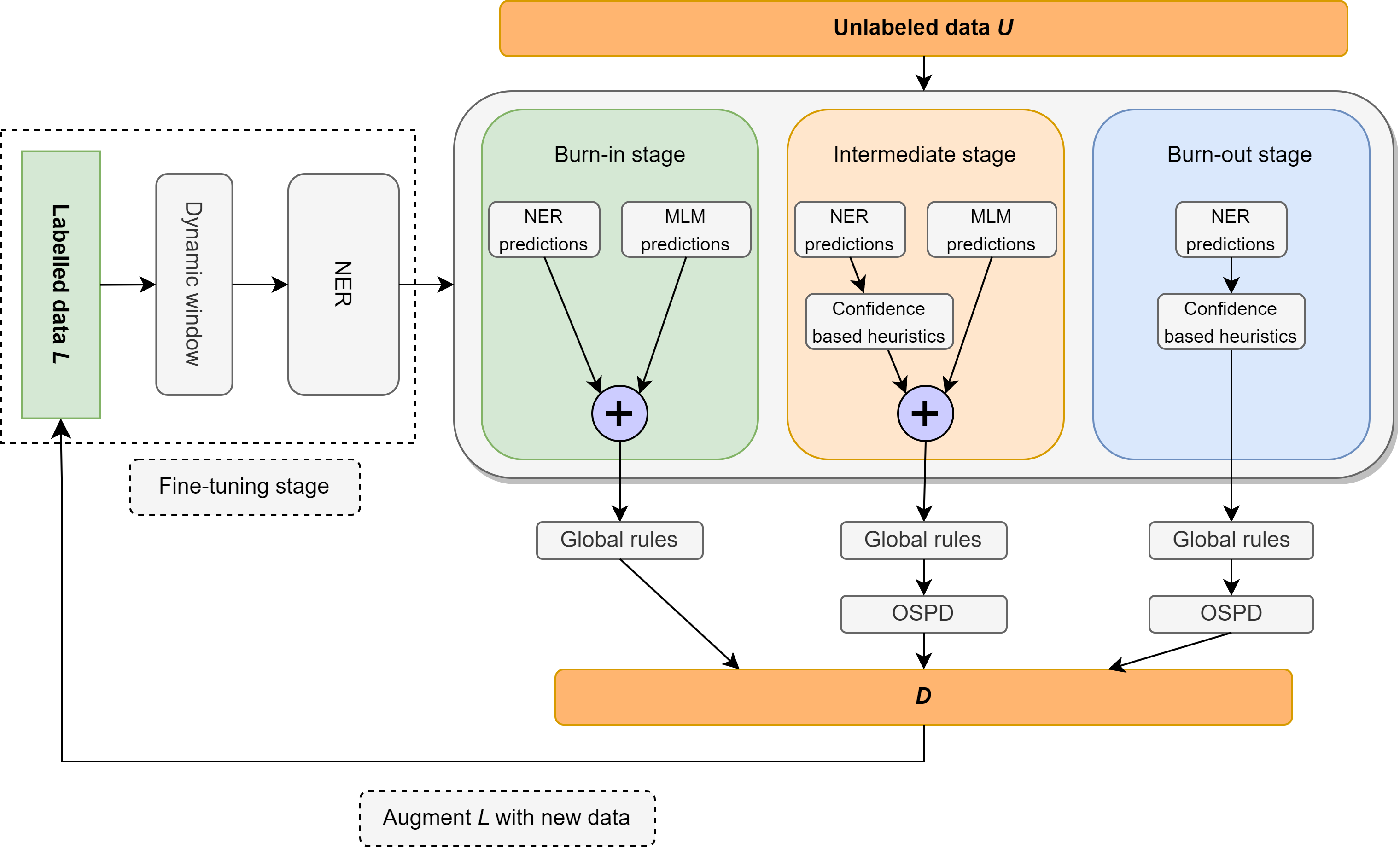
この作業では、クラスごとに10の例を含むレキシコンで構成される、非常に軽い監督に焦点を当てた、半監督の名前付きエンティティ認識(NER)の問題を再検討します。微調整された言語モデルと言語ルールをブレンドするシンプルで完全にモジュール化された神経腫瘍法であるエレンを紹介します。これらのルールには、「談話ごとの1つの感覚」などの洞察、マスクされた言語モデルを監視なしのNERとして使用すること、スピーチの一部のタグを活用して、非標識エンティティを偽陰性として識別および排除すること、およびローカルおよびグローバルなコンテキストでの分類器信頼スコアに関するその他の直感が含まれます。エレンは、上記のLexiconからの最小限の監督を使用する場合、CONLL-2003データセットで非常に強力なパフォーマンスを達成します。また、文献で一般的に使用されているのと同じ監督設定(つまり、トレーニングデータの5%)の下で、ほとんどの既存の(そしてかなり複雑な)半監視NERメソッドよりも優れています。さらに、WNUT-17のゼロショットシナリオでCONLL-2003モデルを評価し、GPT-3.5を上回り、GPT-4に匹敵するパフォーマンスを達成します。ゼロショット設定では、エレンは金データで訓練された強力で完全に監視されているモデルのパフォーマンスの75%以上を達成しています。
カメラ対応コードはまもなくリリースされます。
| 精度 | 想起 | F1 |
|---|---|---|
| 74.63% | 79.26% | 76.87% |
Ellen†は、データの5%を監督として使用する場合、PU-Learningや変分シーケンシャルラベル(VSL-GG-Hier)などのより複雑な方法を上回ります。
| 方法 | p | r | F1 |
|---|---|---|---|
| vsl-gg-hier | 84.13% | 82.64% | 83.38% |
| MT +ノイズ | 83.74% | 81.49% | 82.60% |
| セミーダ | 86.93% | 85.74% | 86.33% |
| ジョイントプロップ | 89.88% | 85.98% | 87.68% |
| PU-Learning | 85.79% | 81.03% | 83.34% |
| エレン† | 81.88% | 88.01% | 84.87% |
| 方法 | loc | その他 | 組織 | あたり | 平均 |
|---|---|---|---|---|---|
| T-ner | 64.21% | 42.04% | 42.98% | 66.11% | 55.11% |
| GPT-3.5 | 49.17% | 8.06% | 29.71% | 59.84% | 39.96% |
| GPT-4 | 58.70% | 25.40% | 38.05% | 56.87% | 43.72% |
| エレン+ | 44.82% | 6.21% | 26.49% | 67.00% | 41.56% |
10ショット未満(CONLL-03 DEVで56%F1以上)を使用して、完全に監視されていないNERの非常に強力なベースラインを導入します。
| エンティティタイプ | 精度 | 想起 | F1 |
|---|---|---|---|
| 全体 | 61.78% | 51.90% | 56.41% |
| loc | 69.72% | 41.53% | 52.05% |
| その他 | 45.18% | 55.15% | 49.67% |
| 組織 | 44.85% | 40.88% | 42.77% |
| あたり | 85.07% | 65.02% | 73.71% |
この作業が便利だと思う場合は、引用を検討してください。
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
このリポジトリでリリースされたコードは、MITライセンスの下でほとんどの状況で自由に使用できます。
Haris Riaz([email protected])または([email protected])


