ELLEN
1.0.0
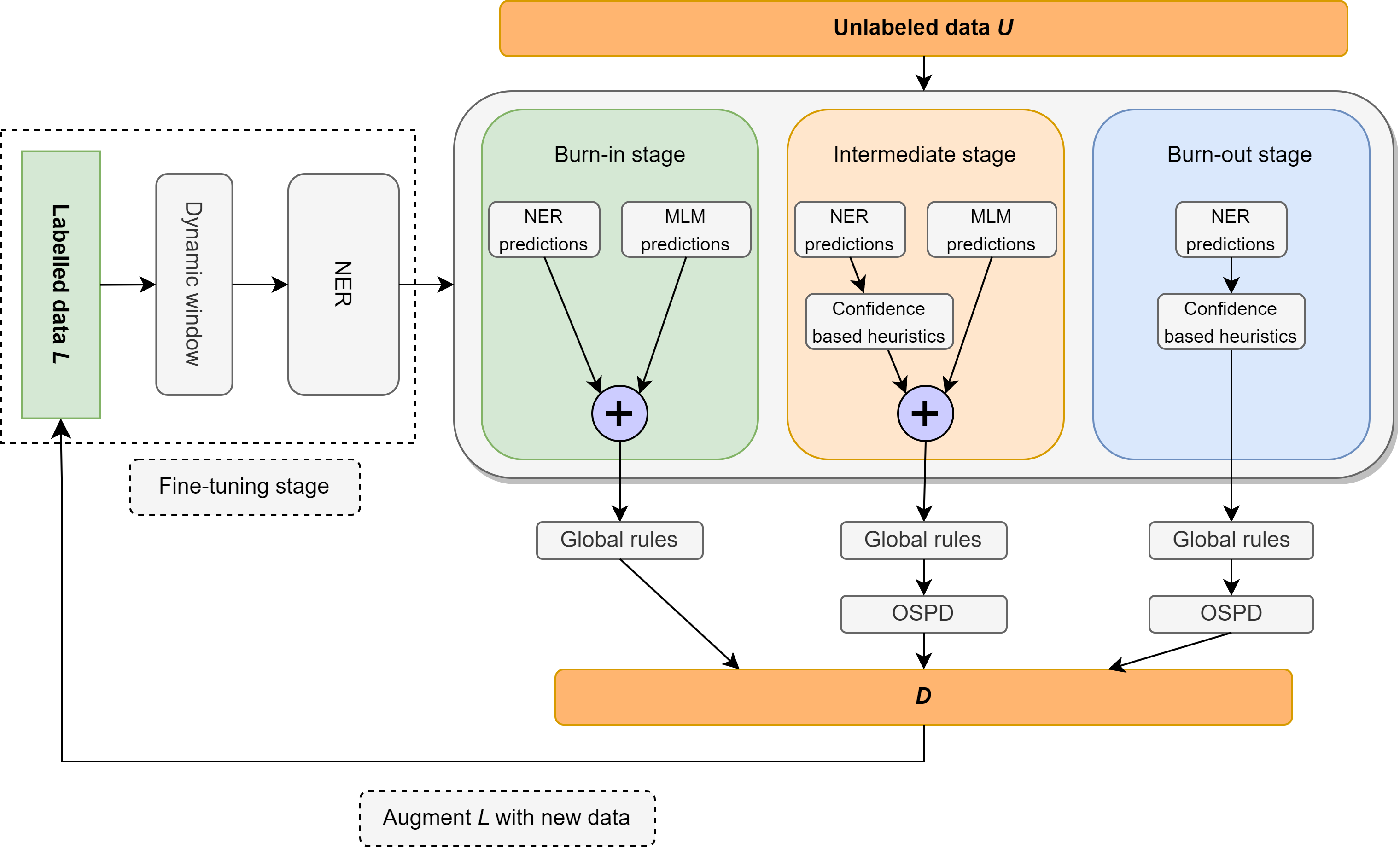
ในงานนี้เรากลับมาทบทวนปัญหาของการจดจำเอนทิตีกึ่งผู้ดูแล (NER) โดยมุ่งเน้นไปที่การกำกับดูแลที่เบามากซึ่งประกอบด้วยพจนานุกรมที่มีเพียง 10 ตัวอย่างต่อชั้นเรียน เราแนะนำ Ellen วิธีการที่เรียบง่ายแบบโมดูลอย่างเต็มที่และเป็นระบบประสาทที่ผสมผสานแบบจำลองภาษาที่ปรับแต่งได้อย่างละเอียดเข้ากับกฎภาษาศาสตร์ กฎเหล่านี้รวมถึงข้อมูลเชิงลึกเช่น "หนึ่งในวาทกรรมต่อวาทกรรม" โดยใช้แบบจำลองภาษาที่สวมหน้ากากเป็น ner ที่ไม่มีผู้ดูแลใช้ประโยชน์จากแท็กส่วนหนึ่งของการพูดเพื่อระบุและกำจัดหน่วยงานที่ไม่มีป้ายกำกับเป็นลบเท็จ Ellen บรรลุประสิทธิภาพที่แข็งแกร่งมากในชุดข้อมูล CONLL-2003 เมื่อใช้การกำกับดูแลน้อยที่สุดจากพจนานุกรมด้านบน นอกจากนี้ยังมีประสิทธิภาพสูงกว่าวิธีการกึ่งผู้ดูแลกึ่งที่มีอยู่ส่วนใหญ่ (และซับซ้อนมากขึ้น) ภายใต้การตั้งค่าการกำกับดูแลเดียวกันที่ใช้กันทั่วไปในวรรณคดี (เช่น 5% ของข้อมูลการฝึกอบรม) นอกจากนี้เราประเมินโมเดล CONLL-2003 ของเราในสถานการณ์ที่ไม่มีการยิงใน WNUT-17 ซึ่งเราพบว่ามันมีประสิทธิภาพสูงกว่า GPT-3.5 และบรรลุประสิทธิภาพที่เทียบเท่ากับ GPT-4 ในการตั้งค่าที่ไม่มีการยิงเอลเลนยังประสบความสำเร็จมากกว่า 75% ของประสิทธิภาพของโมเดลที่แข็งแกร่งและมีการดูแลอย่างเต็มที่ซึ่งได้รับการฝึกฝนเกี่ยวกับข้อมูลทองคำ
รหัสพร้อมกล้องจะเปิดตัวเร็ว ๆ นี้
| ความแม่นยำ | ระลึกถึง | F1 |
|---|---|---|
| 74.63% | 79.26% | 76.87% |
Ellen †มีประสิทธิภาพสูงกว่าวิธีที่ซับซ้อนมากขึ้นเช่นการเรียนรู้แบบ PU-Learning และตัวแปรต่อเนื่องแบบแปรผัน (VSL-GG-Hier) เมื่อใช้ 5% ของข้อมูลเป็นการกำกับดูแล
| วิธีการ | P | R | F1 |
|---|---|---|---|
| VSL-GG-HIER | 84.13% | 82.64% | 83.38% |
| เสียงรบกวนจาก MT + | 83.74% | 81.49% | 82.60% |
| กึ่ง-ลาด้า | 86.93% | 85.74% | 86.33% |
| ร่วมกัน | 89.88% | 85.98% | 87.68% |
| การเรียนรู้ | 85.79% | 81.03% | 83.34% |
| เอลเลน† | 81.88% | 88.01% | 84.87% |
| วิธี | LOC | ผิด | org | ต่อ | AVG |
|---|---|---|---|---|---|
| t-ner | 64.21% | 42.04% | 42.98% | 66.11% | 55.11% |
| GPT-3.5 | 49.17% | 8.06% | 29.71% | 59.84% | 39.96% |
| GPT-4 | 58.70% | 25.40% | 38.05% | 56.87% | 43.72% |
| เอลเลน+ | 44.82% | 6.21% | 26.49% | 67.00% | 41.56% |
เราแนะนำพื้นฐานที่แข็งแกร่งมากสำหรับ NER ที่ไม่ได้รับการดูแลอย่างเต็มที่โดยใช้น้อยกว่า 10 นัด (มากกว่า 56% F1 ใน Conll-03 dev!)
| ประเภทเอนทิตี | ความแม่นยำ | ระลึกถึง | F1 |
|---|---|---|---|
| โดยรวม | 61.78% | 51.90% | 56.41% |
| LOC | 69.72% | 41.53% | 52.05% |
| ผิด | 45.18% | 55.15% | 49.67% |
| org | 44.85% | 40.88% | 42.77% |
| ต่อ | 85.07% | 65.02% | 73.71% |
หากคุณพบว่างานนี้มีประโยชน์โปรดพิจารณาอ้าง:
@misc{riaz2024ellen,
title={ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition},
author={Haris Riaz and Razvan-Gabriel Dumitru and Mihai Surdeanu},
year={2024},
eprint={2403.17385},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
รหัสที่เผยแพร่ในที่เก็บนี้จะใช้ฟรีสำหรับสถานการณ์ส่วนใหญ่ภายใต้ใบอนุญาต MIT
Haris Riaz ([email protected]) หรือ ([email protected])


