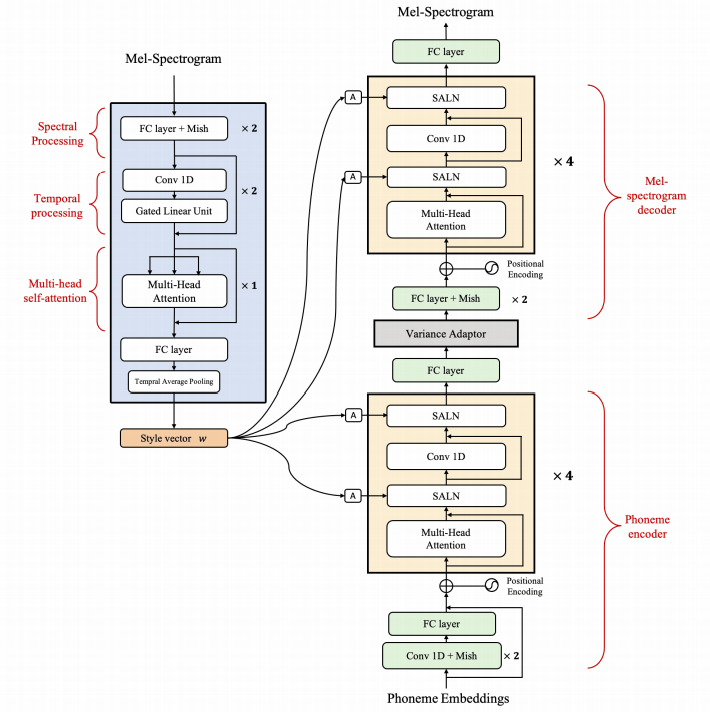
StyleSpeech
v1.0.2
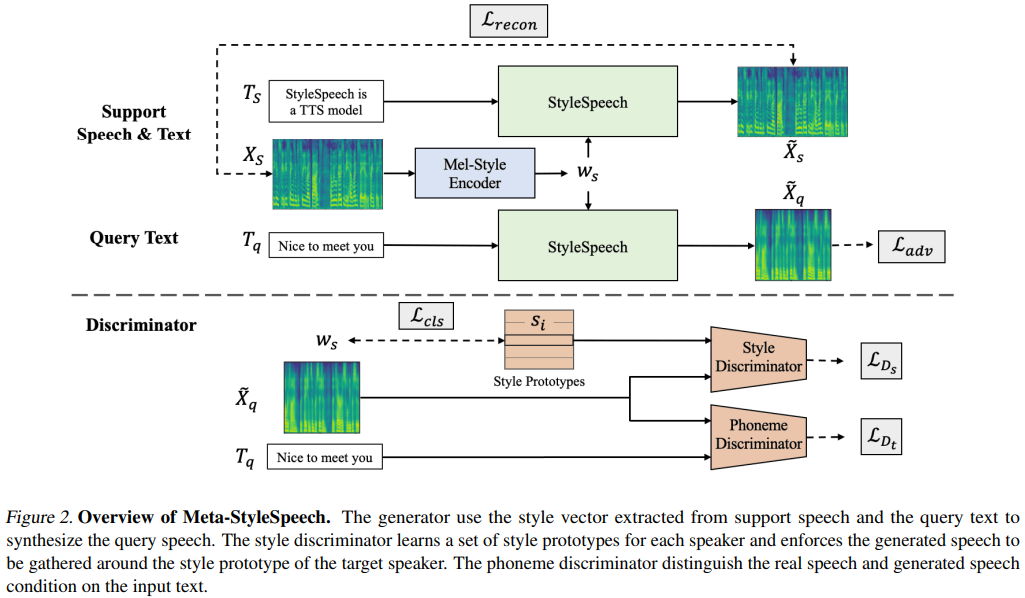
Meta-StylesPeech的Pytorch实现:多演讲者自适应文本到语音的生成。
naive分支) main分支)您可以使用
pip3 install -r requirements.txt
您必须下载验证的型号,并将其放入output/ckpt/LibriTTS_meta_learner/ 。
对于英语多演讲者TTS,运行
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
生成的话语将放入output/result/ 。您的综合语音将具有ref_audio的风格。
也支持批次推理,尝试
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
综合preprocessed_data/LibriTTS/val.txt中的所有话语。这可以看作是验证数据集的重建,以引用参考样式。
可以通过指定所需的音高/能量/持续时间比来控制合成话语的音高/音量/口语速率。例如,一个人可以将语言率提高20%,并将数量减少20%
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
请注意,可控性源自FastSpeech2,而不是StylesPeech的重要利益。有关每个样式因子的可控性,请参阅Styler [演示,代码]。
支持的数据集是
跑步
python3 prepare_align.py config/LibriTTS/preprocess.yaml
用于一些准备工作。
对于强制对准,蒙特利尔强制对准器(MFA)用于获得发音和音素序列之间的比对。此处提供了数据集的预提取对齐。您必须在preprocessed_data/LibriTTS/TextGrid/中解压缩文件。或者,您可以自己运行对准器。
之后,通过
python3 preprocess.py config/LibriTTS/preprocess.yaml
培训您的模型
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
如本文所述,该脚本将从预先培训幼稚的模型开始,直到meta_learning_warmup步骤,然后通过情节培训进行元模型以进行其他步骤。
使用
tensorboard --logdir output/log/LibriTTS
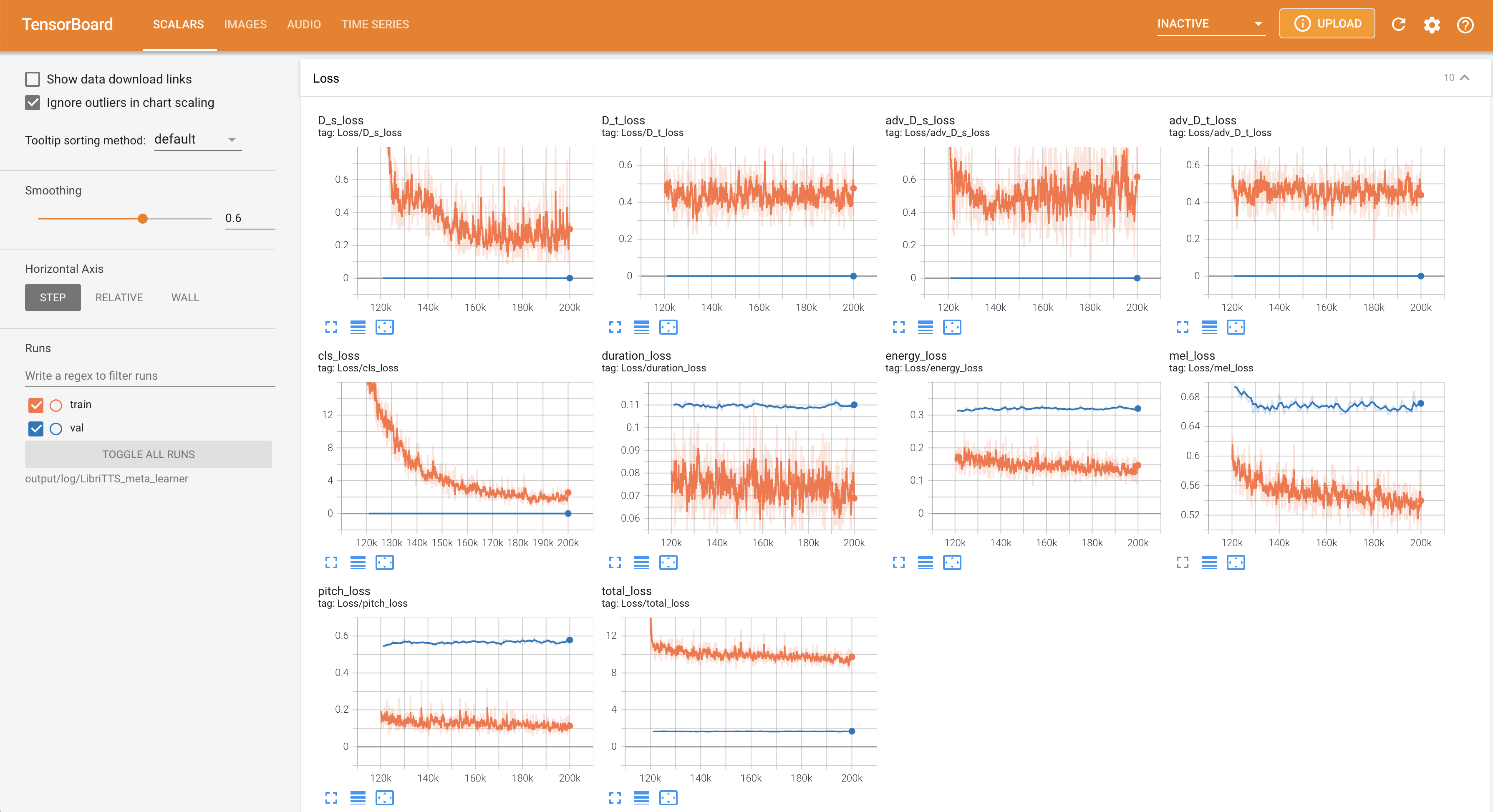
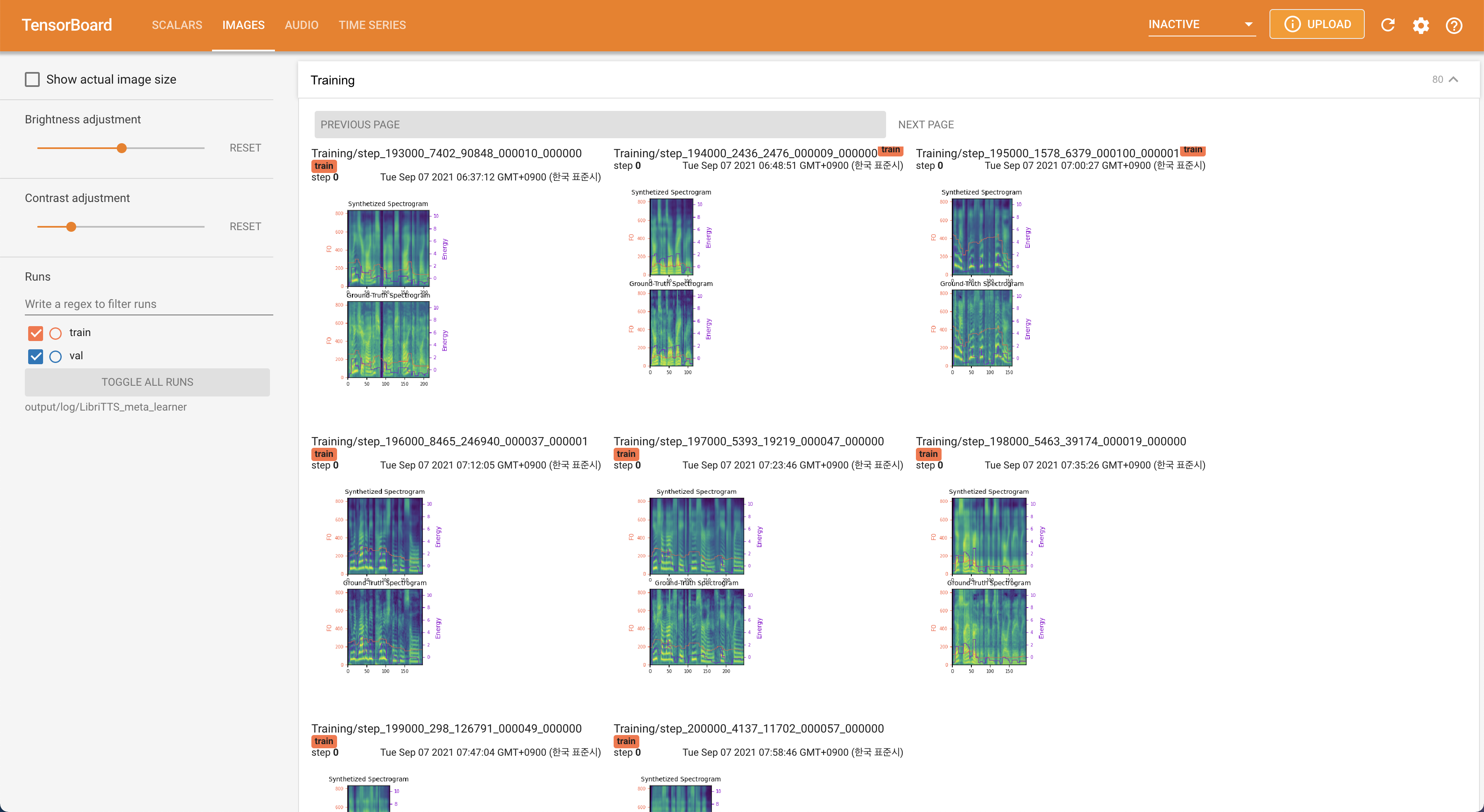
在您的本地主机上提供张板。显示了损耗曲线,合成的MEL光谱图和音频。
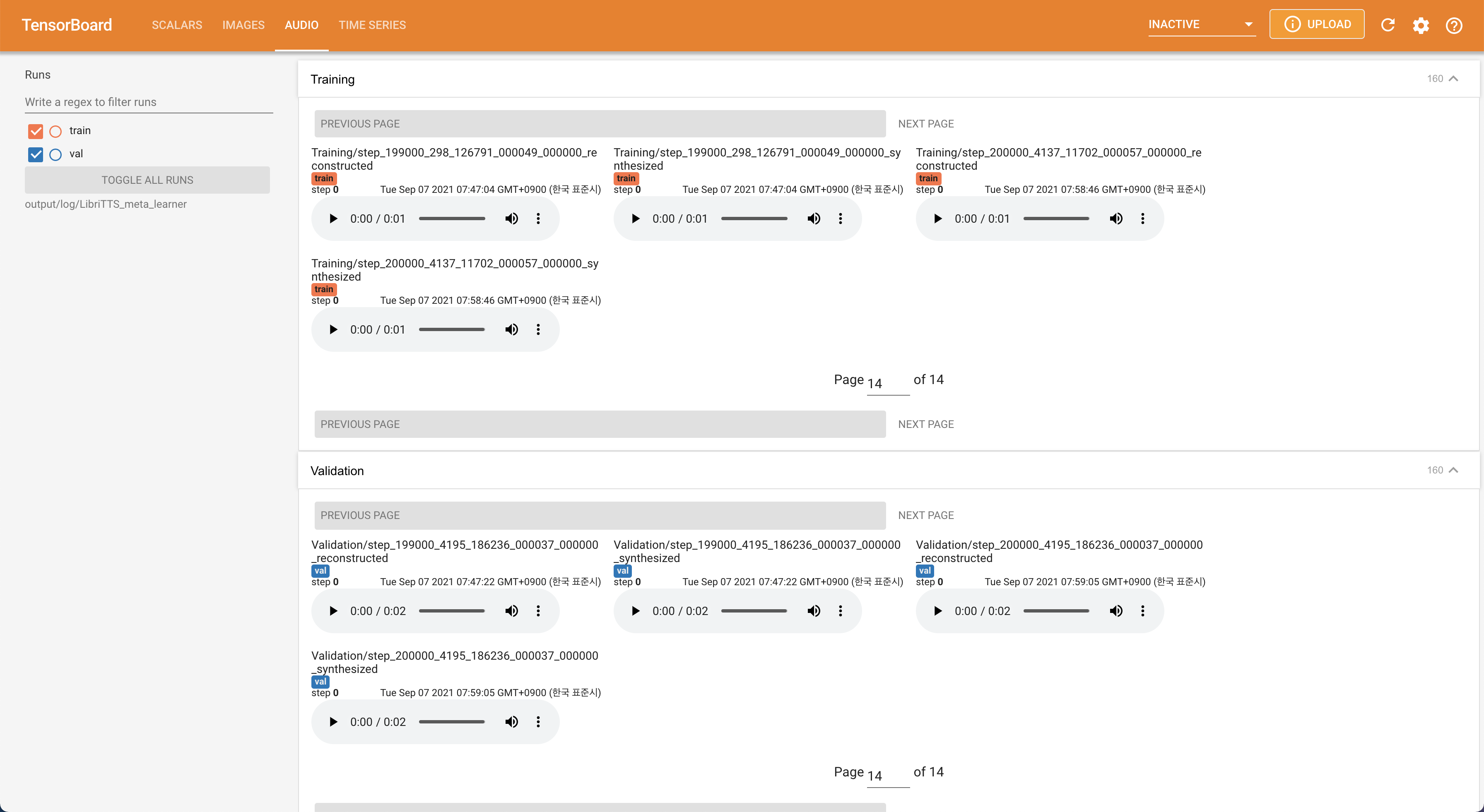
22050Hz采样率,而不是16kHz 。80到128 Uplample输入MEL-SPECTROGRAM。28.197M 。16批量的大小,而不是48或20这主要是由于单个24GIB TITAN-RTX缺乏记忆能力。这可以通过以下脚本来实现,以比max_seq_len过滤更长的数据: python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train.txt的同一位置生成train_filtered.txt 。 @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


