StyleSpeech
v1.0.2
การใช้งาน Pytorch ของ Meta-Stylespeech: การสร้างข้อความแบบหลายลำโพงแบบปรับได้
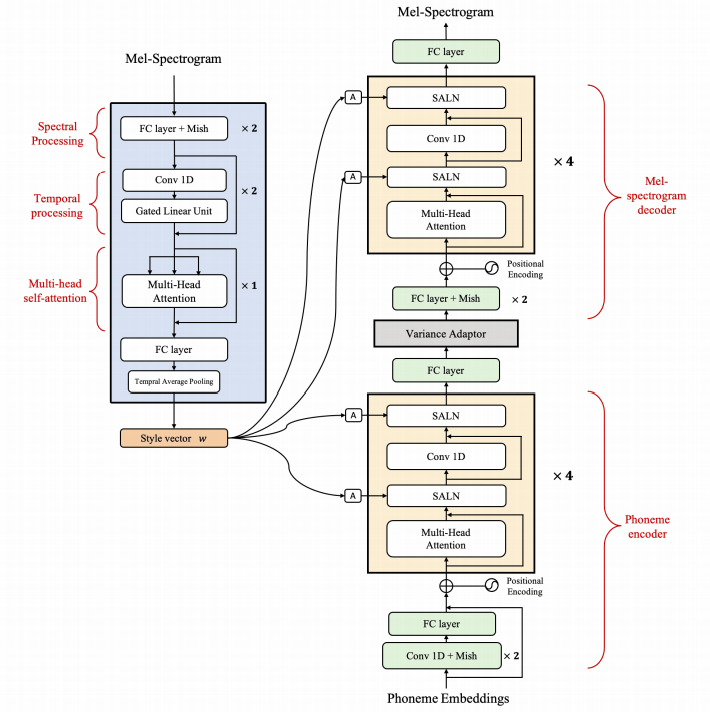
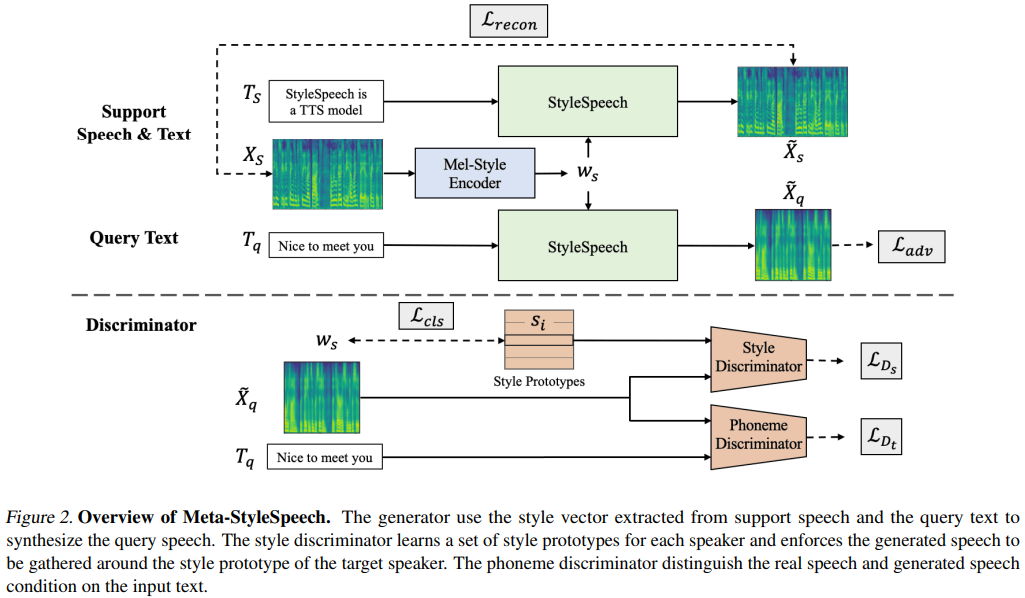
naive ) main )คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
คุณต้องดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมและวางไว้ใน output/ckpt/LibriTTS_meta_learner/
สำหรับ TTs หลายลำโพงภาษาอังกฤษ Run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
คำพูดที่สร้างขึ้นจะถูกนำไปใช้ใน output/result/ คำพูดที่สังเคราะห์ของคุณจะมีสไตล์ของ ref_audio
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/LibriTTS/val.txt สิ่งนี้สามารถดูได้ว่าเป็นการสร้างชุดข้อมูลการตรวจสอบความถูกต้องที่อ้างถึงตัวเองสำหรับรูปแบบการอ้างอิง
ระดับเสียง/ปริมาตร/การพูดของคำพูดสังเคราะห์สามารถควบคุมได้โดยการระบุอัตราส่วนระดับเสียง/พลังงาน/ระยะเวลาที่ต้องการ ตัวอย่างเช่นหนึ่งสามารถเพิ่มอัตราการพูดได้ 20 % และลดปริมาณลง 20 % โดย
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
โปรดทราบว่าความสามารถในการควบคุมได้มาจาก FastSpeech2 และไม่ใช่ความสนใจที่สำคัญของ Stylespeech โปรดดู Styler [Demo, Code] สำหรับความสามารถในการควบคุมของแต่ละสไตล์
ชุดข้อมูลที่รองรับคือ
วิ่ง
python3 prepare_align.py config/LibriTTS/preprocess.yaml
สำหรับการเตรียมการบางอย่าง
สำหรับการจัดตำแหน่งที่ถูกบังคับมอนทรีออลบังคับให้ผู้จัดตำแหน่ง (MFA) ใช้เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิม การจัดตำแหน่งที่สกัดไว้ล่วงหน้าสำหรับชุดข้อมูลมีให้ที่นี่ คุณต้องคลายซิปไฟล์ใน preprocessed_data/LibriTTS/TextGrid/ อีกวิธีหนึ่งคุณสามารถเรียกใช้การจัดตำแหน่งด้วยตัวเอง
หลังจากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้าโดย
python3 preprocess.py config/LibriTTS/preprocess.yaml
ฝึกอบรมแบบจำลองของคุณด้วย
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
ตามที่อธิบายไว้ในกระดาษสคริปต์จะเริ่มต้นจากการฝึกอบรมรุ่นที่ไร้เดียงสาก่อนจนถึงขั้นตอน meta_learning_warmup จากนั้น meta-train โมเดลสำหรับขั้นตอนเพิ่มเติมผ่านการฝึกอบรมเป็นฉาก
ใช้
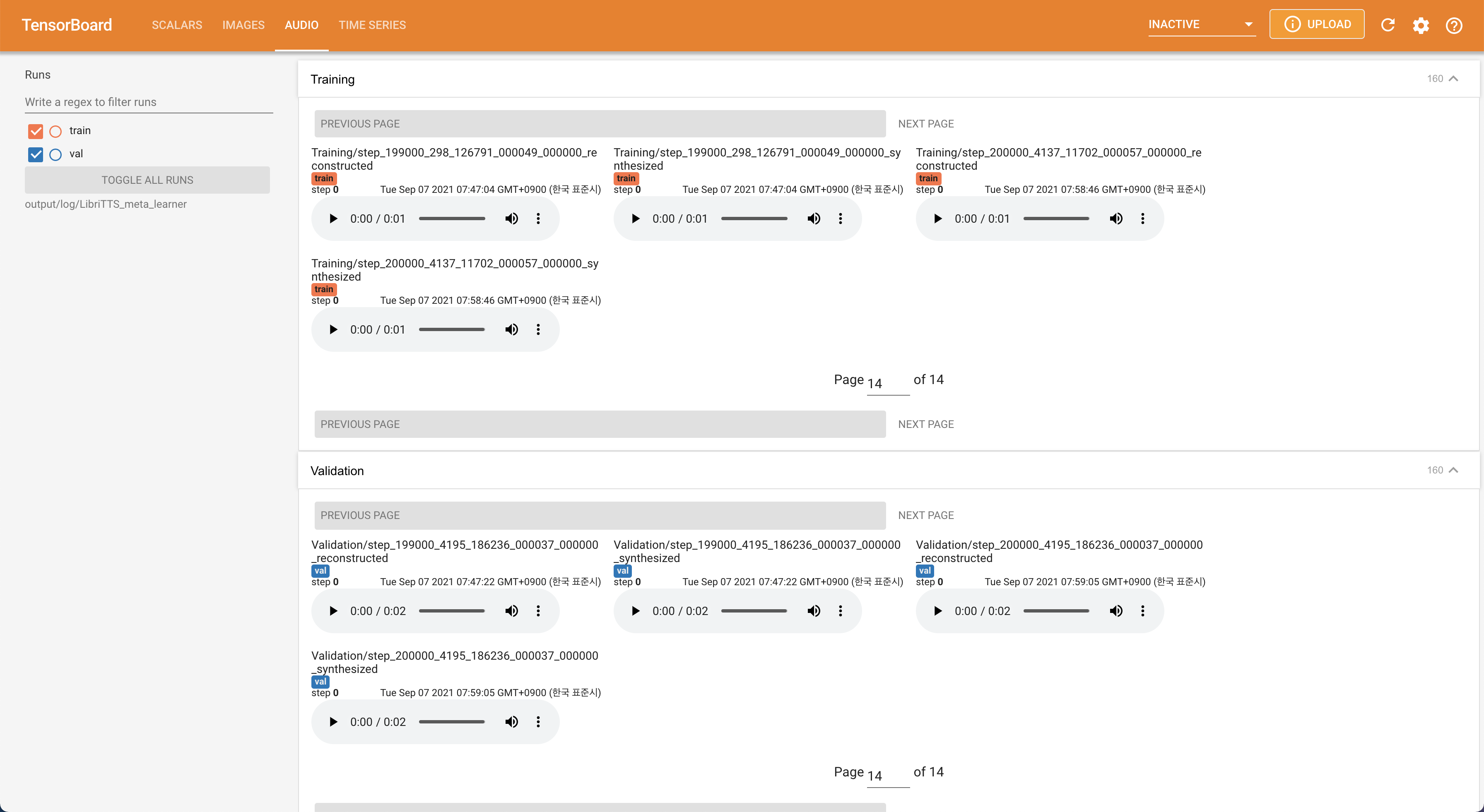
tensorboard --logdir output/log/LibriTTS
เพื่อให้บริการ Tensorboard บนบ้านของคุณ เส้นโค้งการสูญเสีย mel-spectrograms สังเคราะห์และเสียงจะแสดง
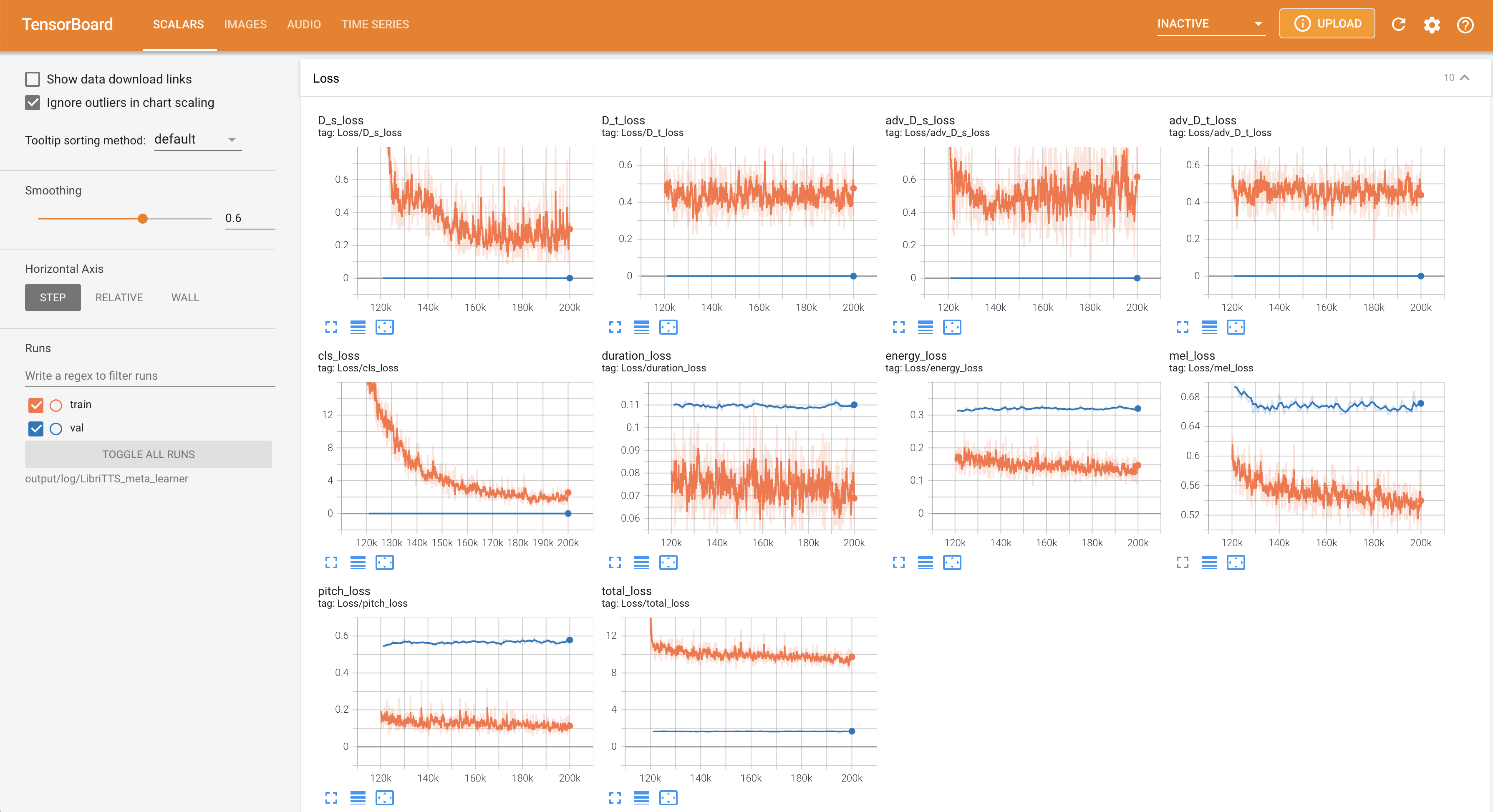
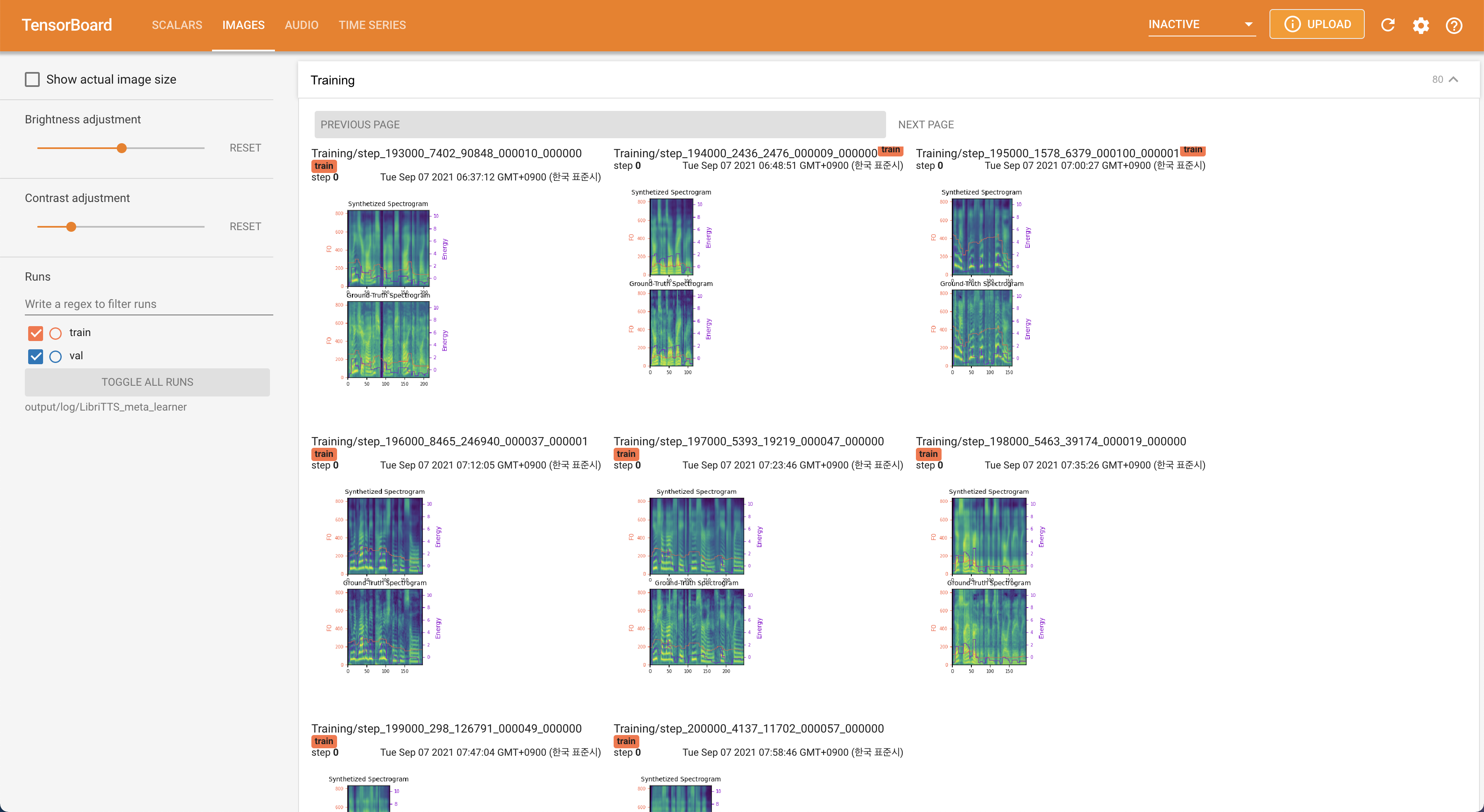
22050Hz แทน 16kHz80 ถึง 12828.197M16 แบทช์ในการฝึกอบรมแทน 48 หรือ 20 ส่วนใหญ่เนื่องจากขาดความจุหน่วยความจำที่มี 24Gib Titan-RTX เดียว สิ่งนี้สามารถทำได้โดยสคริปต์ต่อไปนี้เพื่อกรองข้อมูลที่ยาวกว่า max_seq_len : python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train_filtered.txt ในตำแหน่งเดียวกันของ train.txt @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


