StyleSpeech
v1.0.2
Implementación de Pytorch de Meta-Stylespeech: generación de texto a voz adaptativa de múltiples altavoces.
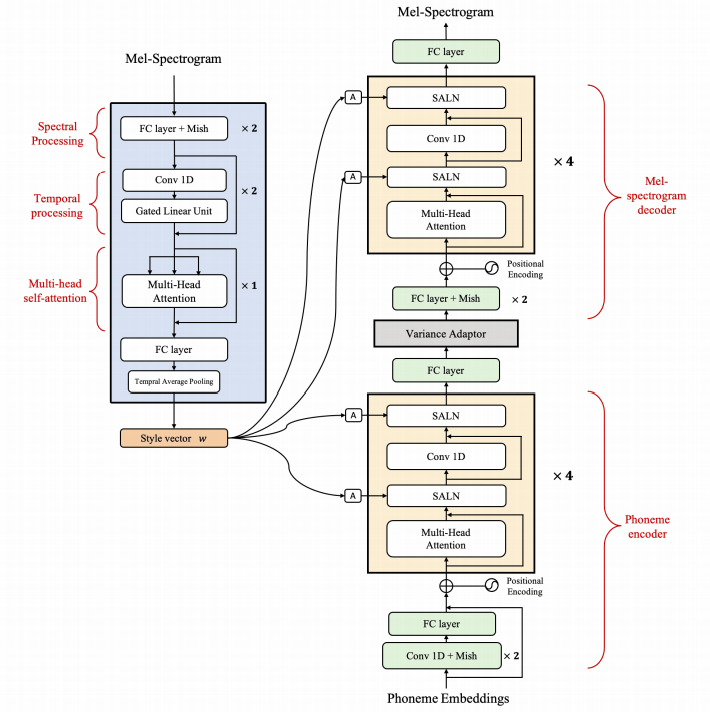
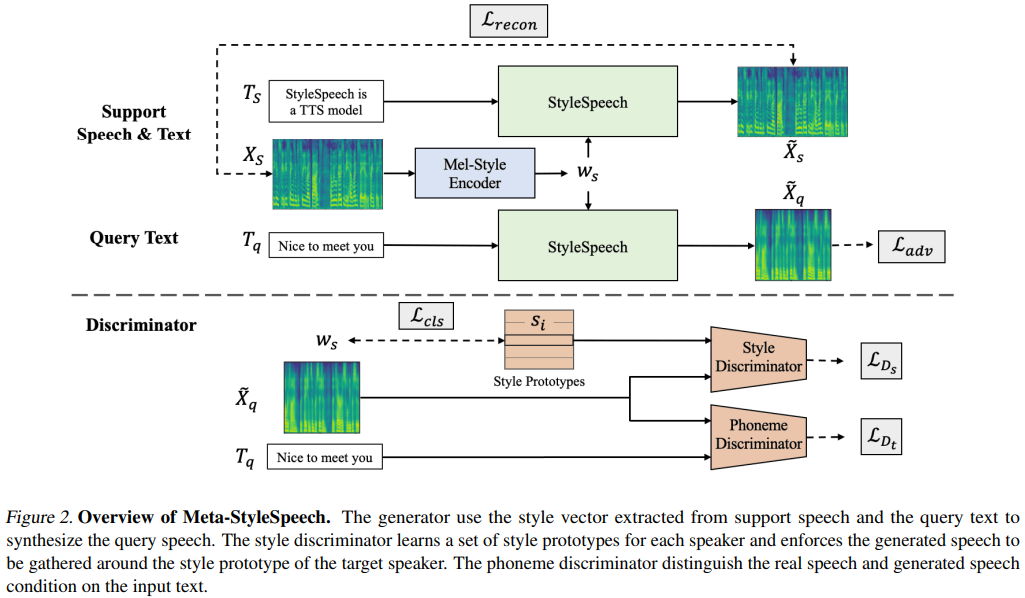
naive ) main )Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Debe descargar modelos previos a la aparición y ponerlos en output/ckpt/LibriTTS_meta_learner/ .
Para TTS en inglés múltiple, ejecutar
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Las expresiones generadas se colocarán en output/result/ . Su discurso sintetizado tendrá el estilo de ref_audio .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Para sintetizar todas las expresiones en preprocessed_data/LibriTTS/val.txt . Esto se puede ver como una reconstrucción de conjuntos de datos de validación que se refieren a sí mismos para el estilo de referencia.
La tasa de tono/volumen/habla de las expresiones sintetizadas se puede controlar especificando las relaciones de tono/energía/duración deseadas. Por ejemplo, uno puede aumentar la tasa de habla en un 20 % y disminuir el volumen en un 20 % en
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
Tenga en cuenta que la capacidad de control se origina en FastSpeech2 y no es un interés vital de StylesSpeech. Consulte Styler [demo, código] para obtener la capacidad de control de cada factor de estilo.
Los conjuntos de datos compatibles son
Correr
python3 prepare_align.py config/LibriTTS/preprocess.yaml
para algunos preparativos.
Para la alineación forzada, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones preextracidas para los conjuntos de datos. Debe descomprimir los archivos en preprocessed_data/LibriTTS/TextGrid/ . Alternativamente, puede ejecutar el alineador usted mismo.
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py config/LibriTTS/preprocess.yaml
Entrena tu modelo con
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Como se describe en el documento, el script comenzará desde la capacitación previa del modelo ingenuo hasta los pasos meta_learning_warmup y luego el meta-entrenado el modelo para pasos adicionales a través de capacitación episódica.
Usar
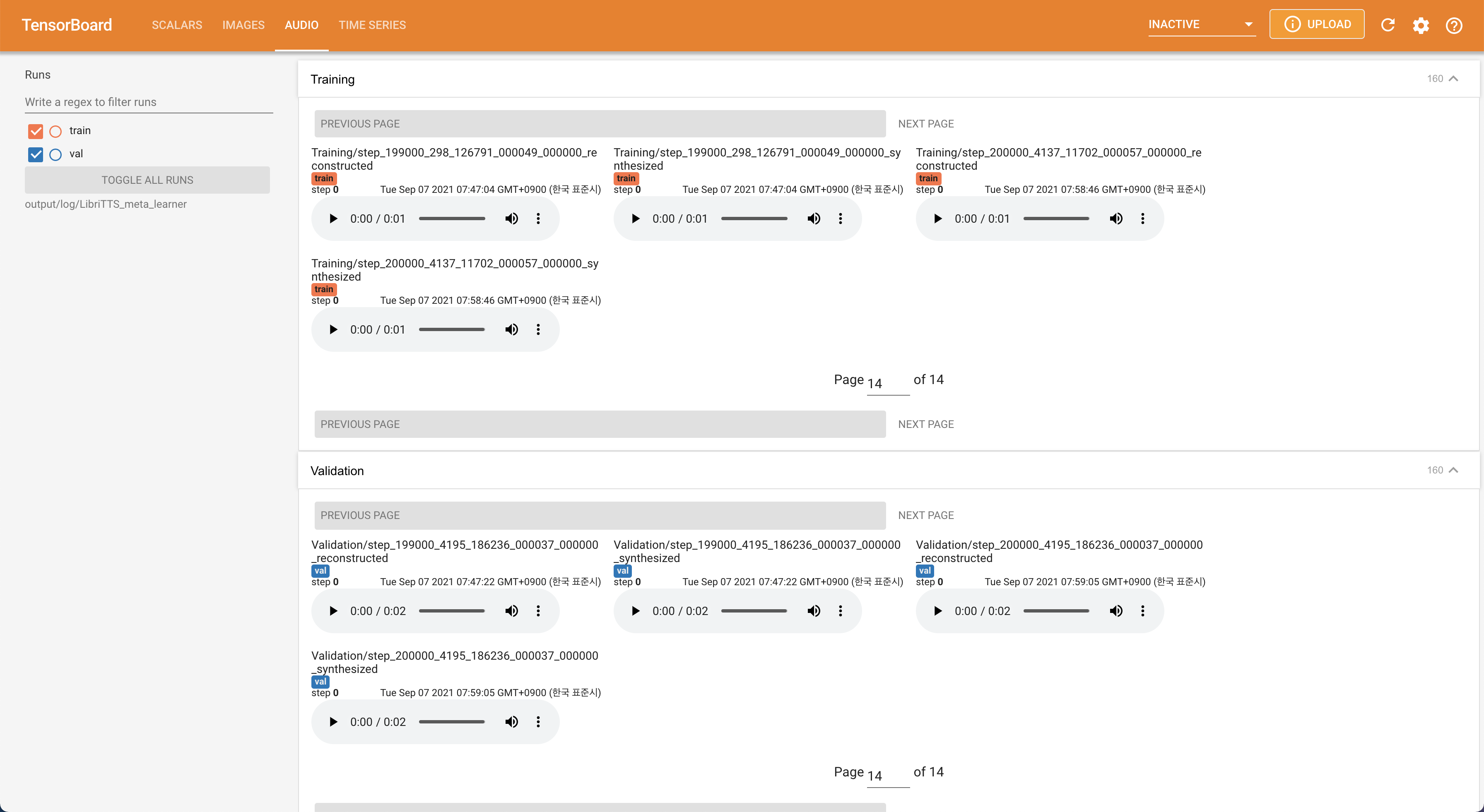
tensorboard --logdir output/log/LibriTTS
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
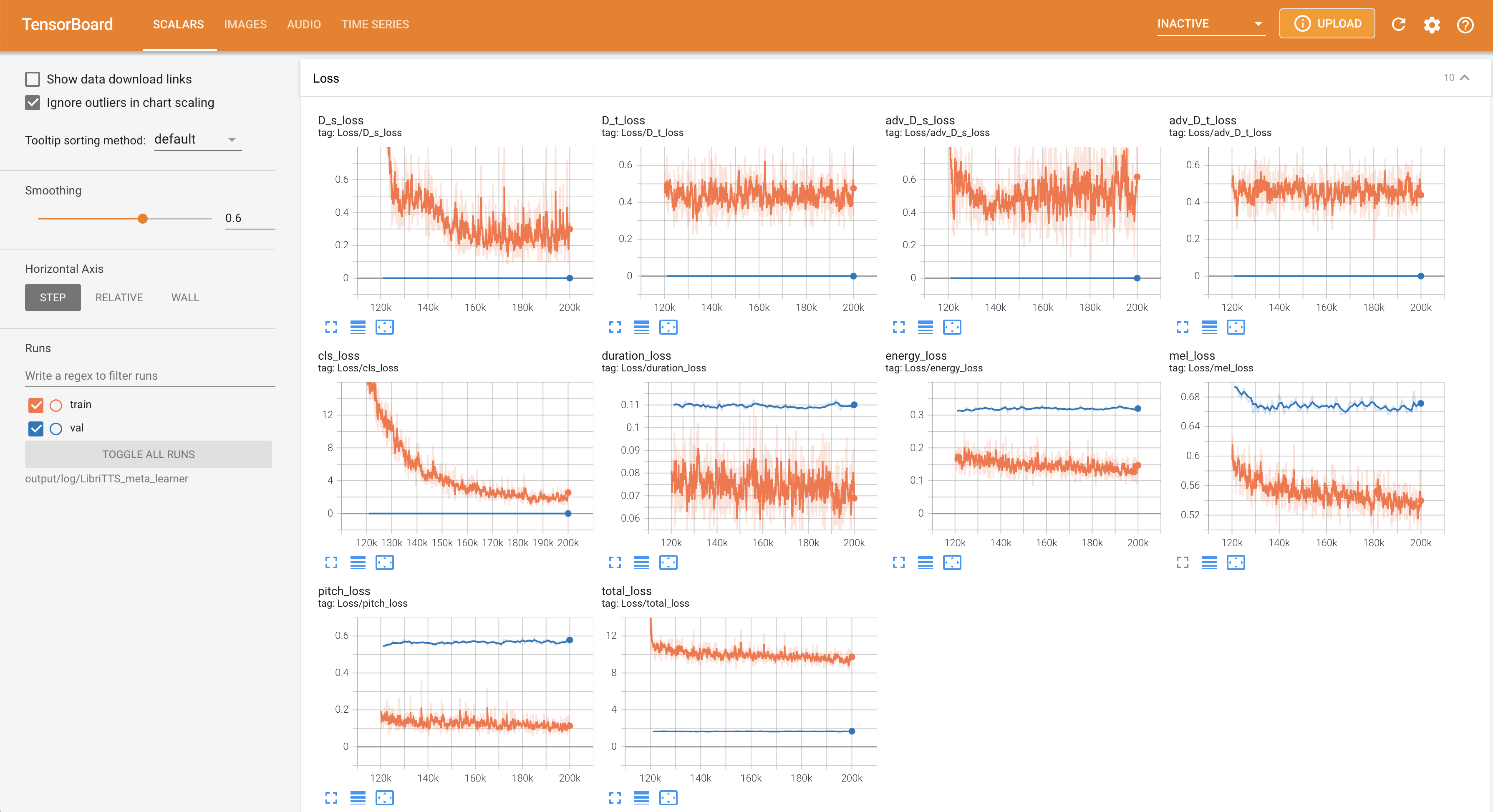
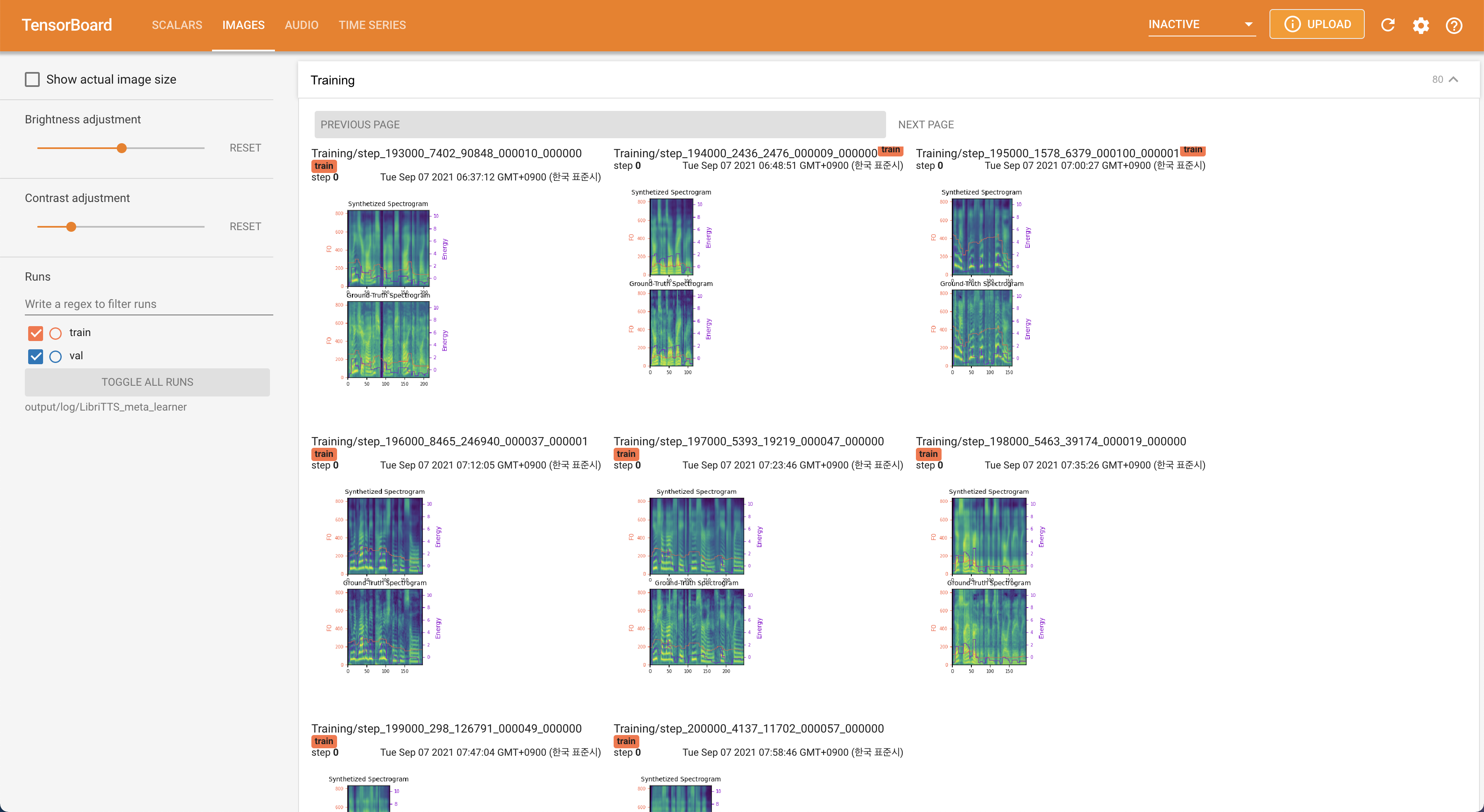
22050Hz en lugar de 16kHz .80 a 128 .28.197M .16 lotes en el entrenamiento en lugar de 48 o 20 principalmente debido a la falta de capacidad de memoria con un solo 24GIB Titan-RTX . Esto se puede lograr mediante el siguiente script para filtrar datos más tiempo que max_seq_len : python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train_filtered.txt en la misma ubicación de train.txt . @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


