StyleSpeech
v1.0.2
Pytorch Implémentation de Meta-StylesPeEEECH: Génération adaptative de texte à la parole multi-haut-parleurs.
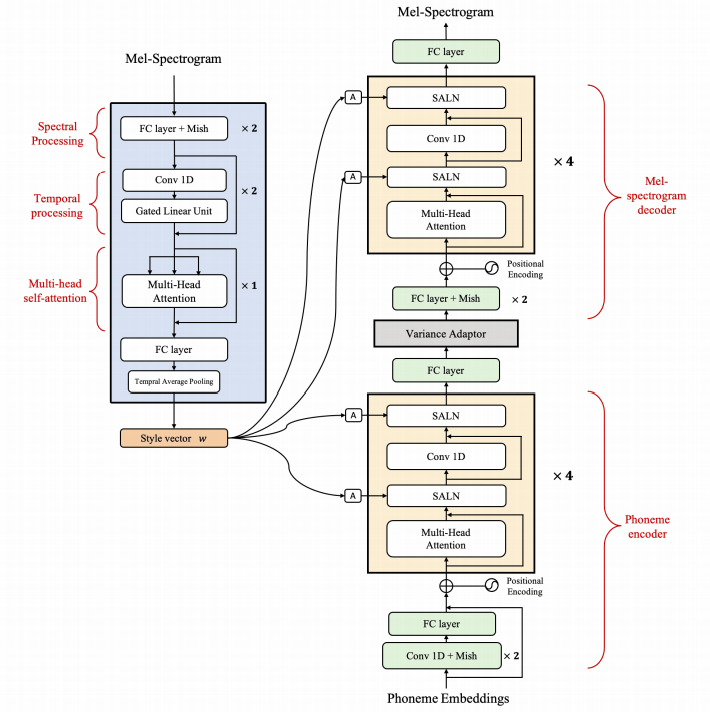
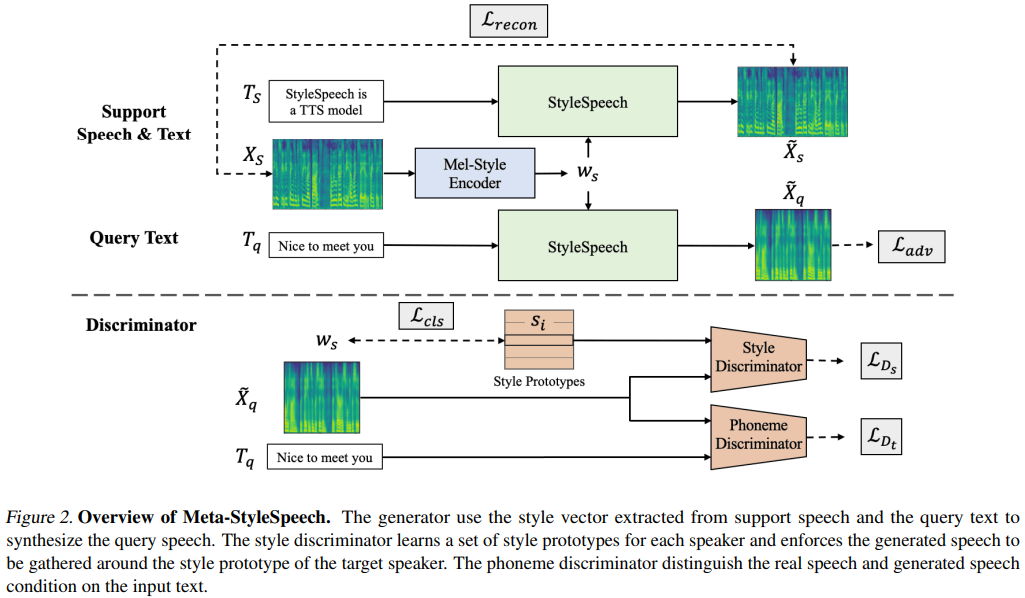
naive ) main )Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
Vous devez télécharger des modèles pré-entraînés et les mettre dans output/ckpt/LibriTTS_meta_learner/ .
Pour les TTS multi-haut-parleurs anglais, exécutez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Les énoncés générés seront placés en output/result/ . Votre discours synthétisé aura le style de ref_audio .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Pour synthétiser toutes les énoncés dans preprocessed_data/LibriTTS/val.txt . Cela peut être considéré comme une reconstruction des ensembles de données de validation se référant à eux-mêmes pour le style de référence.
La hauteur / volume / le taux de parole des énoncés synthétisés peut être contrôlé en spécifiant les rapports de pitch / énergie / durée souhaités. Par exemple, on peut augmenter le taux de parole de 20% et diminuer le volume de 20% par
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
Notez que la contrôlabilité provient de FastSpeech2 et non un intérêt vital du stylespeech. Veuillez vous référer à Styler [Demo, Code] pour la contrôlabilité de chaque facteur de style.
Les ensembles de données pris en charge sont
Courir
python3 prepare_align.py config/LibriTTS/preprocess.yaml
pour certaines préparatifs.
Pour l'alignement forcé, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pré-extractés pour les ensembles de données sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/LibriTTS/TextGrid/ . Alternativement, vous pouvez exécuter l'aligneur par vous-même.
Après cela, exécutez le script de prétraitement par
python3 preprocess.py config/LibriTTS/preprocess.yaml
Former votre modèle avec
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Comme décrit dans l'article, le script commencera de la pré-formation du modèle naïf jusqu'à des étapes meta_learning_warmup , puis méta-entraîner le modèle pour des étapes supplémentaires via une formation épisodique.
Utiliser
tensorboard --logdir output/log/LibriTTS
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
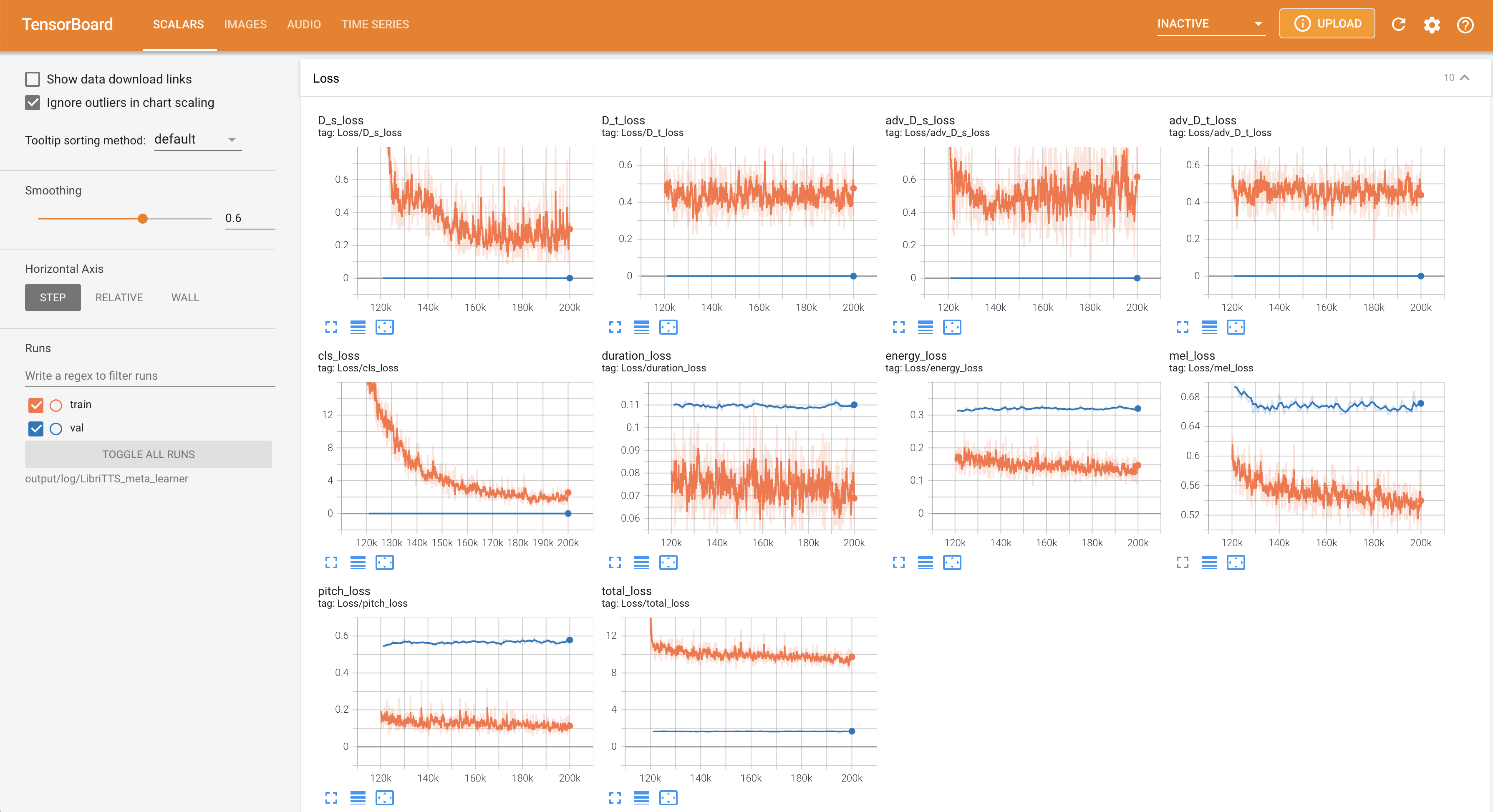
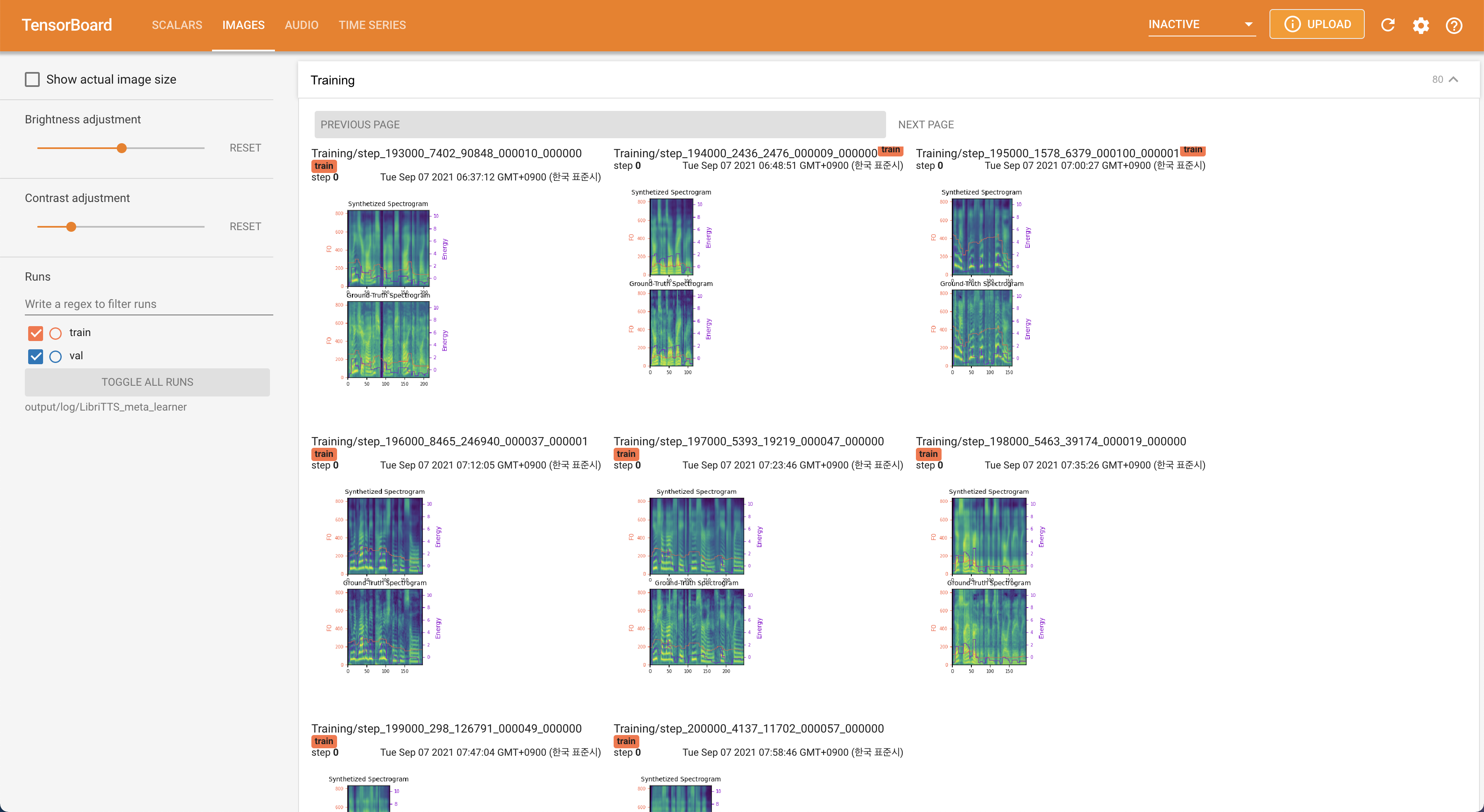
22050Hz au lieu de 16kHz .80 à 128 .28.197M .16 lots lors de la formation au lieu de 48 ou 20 principalement en raison du manque de capacité de mémoire avec un seul Titan-RTX 24GIB . Cela peut être réalisé par le script suivant pour filtrer les données plus longtemps que max_seq_len : python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train_filtered.txt au même emplacement de train.txt . @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


