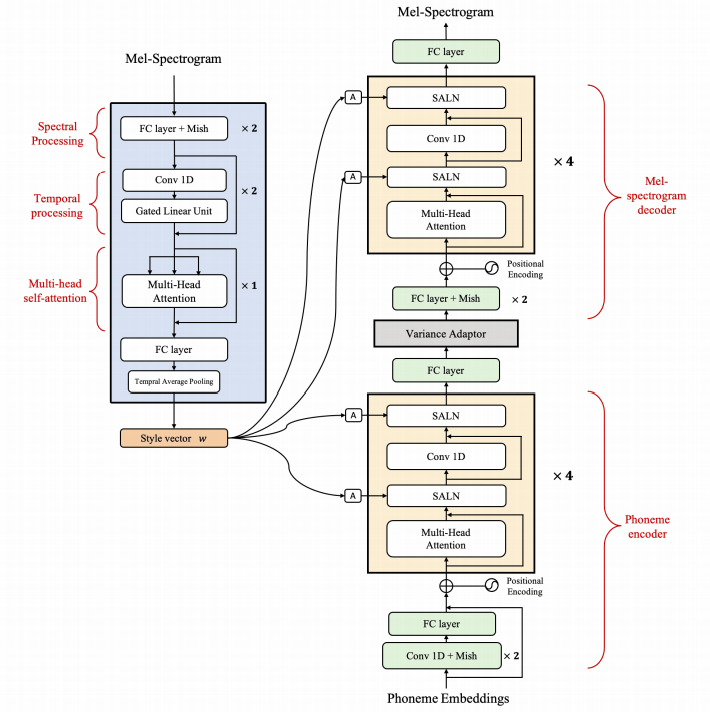
StyleSpeech
v1.0.2
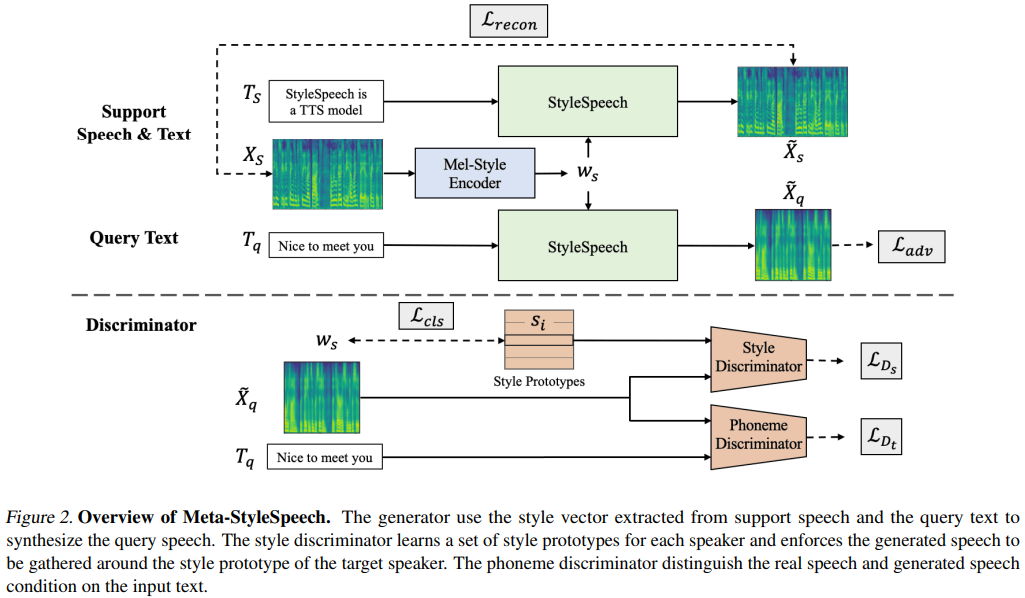
Meta-StyleSpeech의 Pytorch 구현 : 멀티 스피커 어댑티브 텍스트 음성 연설 생성.
naive 지점) main 브랜치)파이썬 종속성을 설치할 수 있습니다
pip3 install -r requirements.txt
사전 치료 된 모델을 다운로드하여 output/ckpt/LibriTTS_meta_learner/ 에 넣어야합니다.
영어 멀티 스피커 TTS의 경우 실행하십시오
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
생성 된 발화는 output/result/ 에 넣습니다. 합성 된 연설에는 ref_audio 의 스타일이 있습니다.
배치 추론도 지원됩니다
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
preprocessed_data/LibriTTS/val.txt 의 모든 발화를 종합합니다. 이것은 참조 스타일에 대해 자신을 언급하는 검증 데이터 세트의 재구성으로 볼 수 있습니다.
합성 된 발화의 피치/볼륨/말하기 속도는 원하는 피치/에너지/지속 시간 비율을 지정하여 제어 할 수 있습니다. 예를 들어, 말하기 속도를 20 % 증가시키고 양을 20 % 감소시킬 수 있습니다.
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
제어 가능성은 FastSpeech2에서 유래되며 StyleSpeech의 중요한 관심은 아닙니다. 각 스타일 요소의 제어 가능성은 스타일러 [데모, 코드]를 참조하십시오.
지원되는 데이터 세트는입니다
달리다
python3 prepare_align.py config/LibriTTS/preprocess.yaml
일부 준비.
강제 정렬의 경우, 몬트리올 강제 정렬 (MFA)은 발화와 음소 시퀀스 사이의 정렬을 얻는 데 사용됩니다. 데이터 세트에 대한 사전 추출 된 정렬이 여기에 제공됩니다. preprocessed_data/LibriTTS/TextGrid/ 에서 파일을 압축해야합니다. 또는 혼자서 Aligner를 실행할 수 있습니다.
그 후, 전처리 스크립트를 실행하십시오
python3 preprocess.py config/LibriTTS/preprocess.yaml
모델을 훈련하십시오
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
논문에 설명 된 바와 같이, 스크립트는 meta_learning_warmup 단계까지 순진한 모델을 사전 훈련하는 것부터 시작한 다음 에피소드 훈련을 통해 추가 단계를 위해 모델을 메타 트레이드합니다.
사용
tensorboard --logdir output/log/LibriTTS
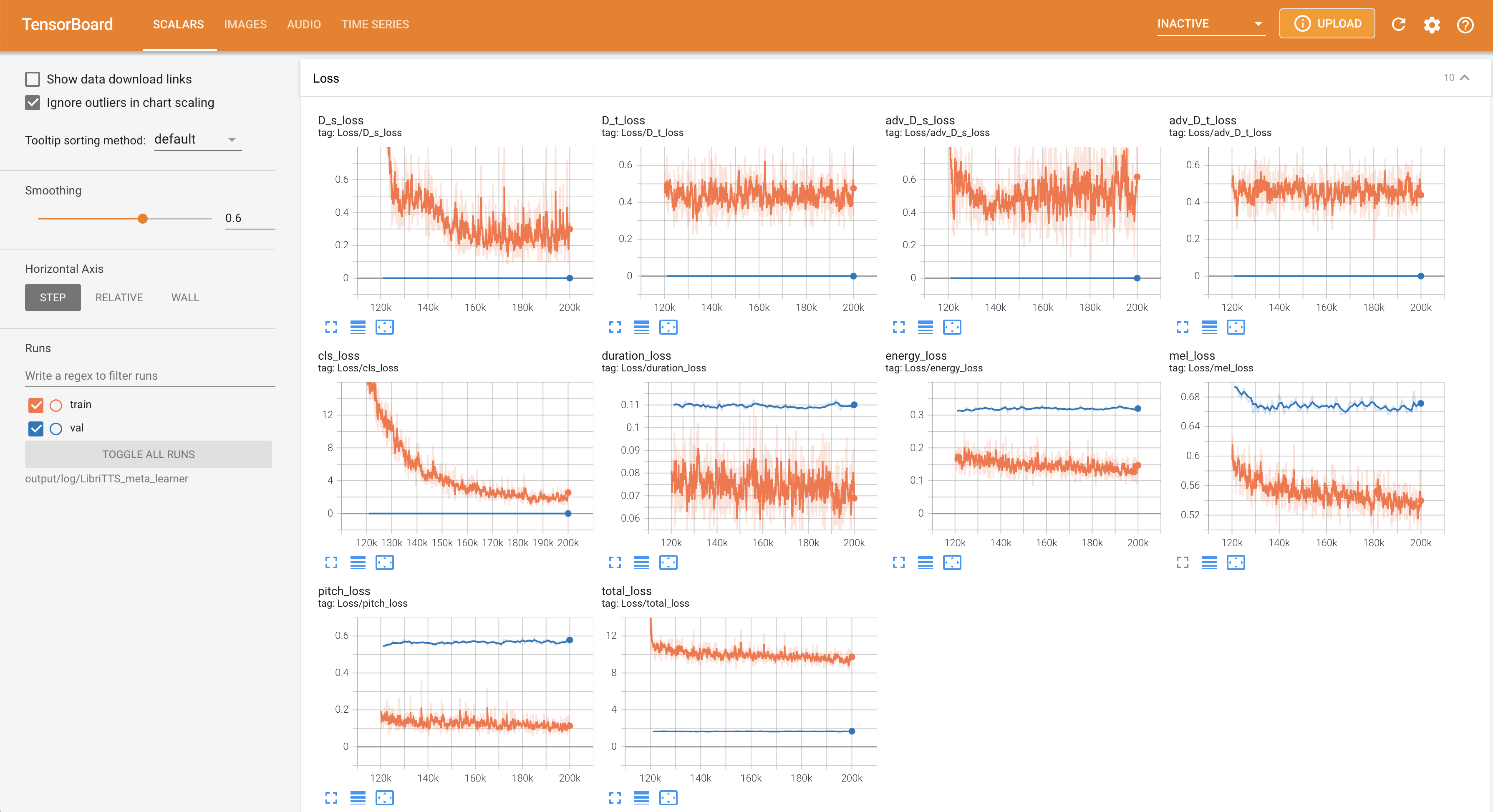
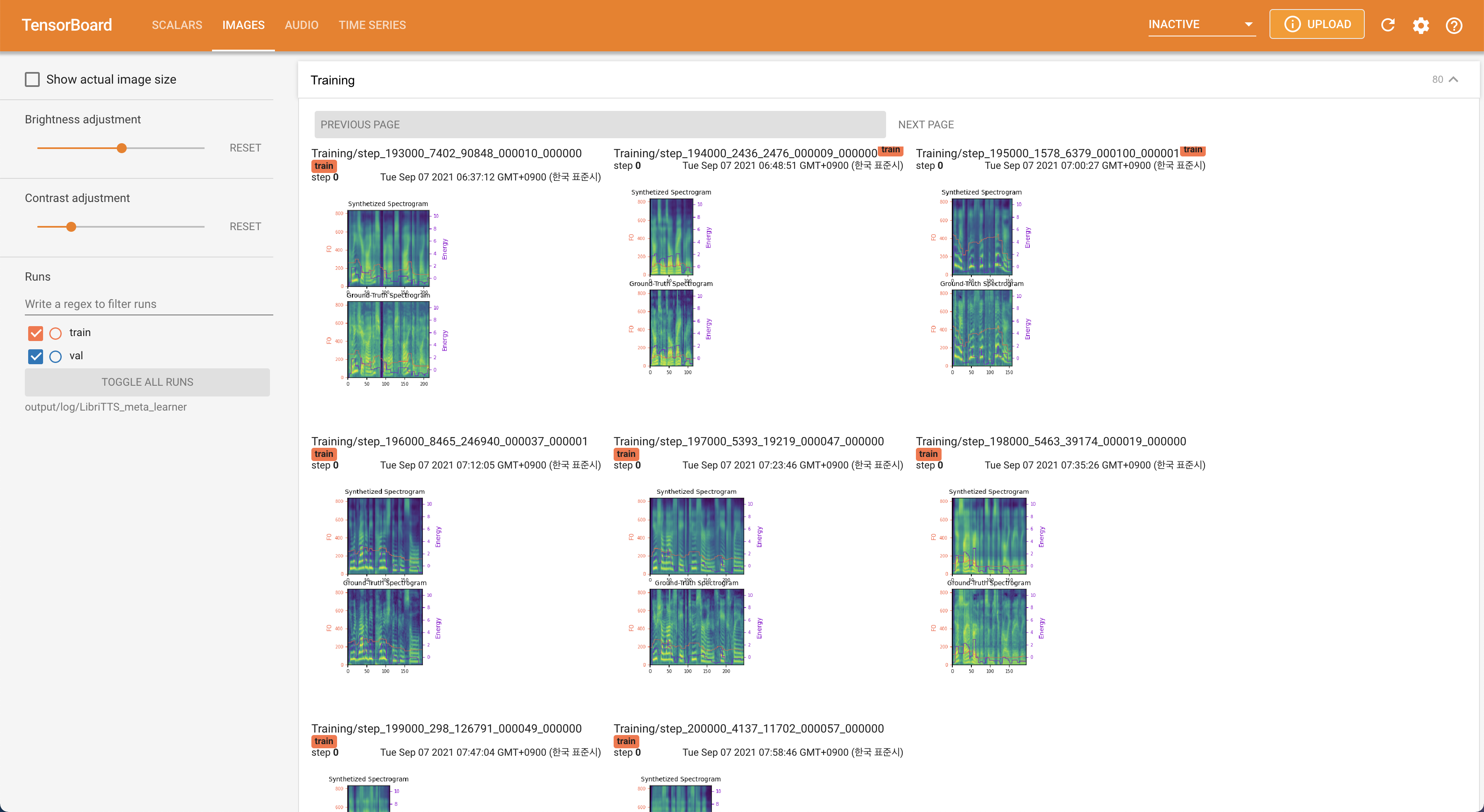
지역 호스트에서 텐서 보드를 제공합니다. 손실 곡선, 합성 된 멜 스피어 그램 및 오디오가 표시됩니다.
16kHz 대신 22050Hz 샘플링 속도를 사용하십시오.80 에서 128 까지의 멜 스피어 그램을 상향 샘플링하십시오.28.197M 입니다.48 또는 20 대신 훈련시 최대 16 배치 크기를 사용하십시오. 이는 다음 스크립트로 달성하여 max_seq_len 보다 더 긴 데이터를 필터링 할 수 있습니다. python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train.txt 의 동일한 위치에서 train_filtered.txt 가 생성됩니다. @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


