StyleSpeech
v1.0.2
تنفيذ Pytorch من Meta-Stylespeech: توليد النص إلى الكلام التكيفي متعدد الناطقين.
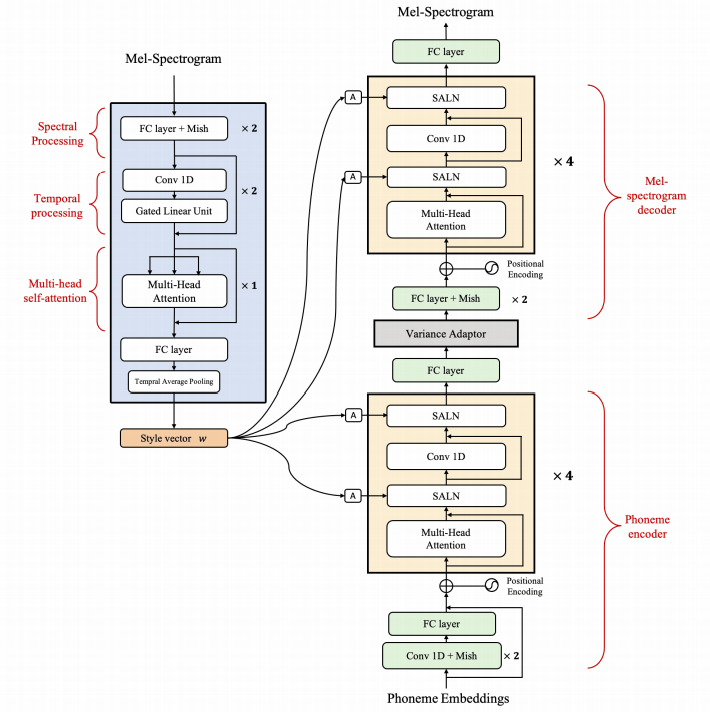
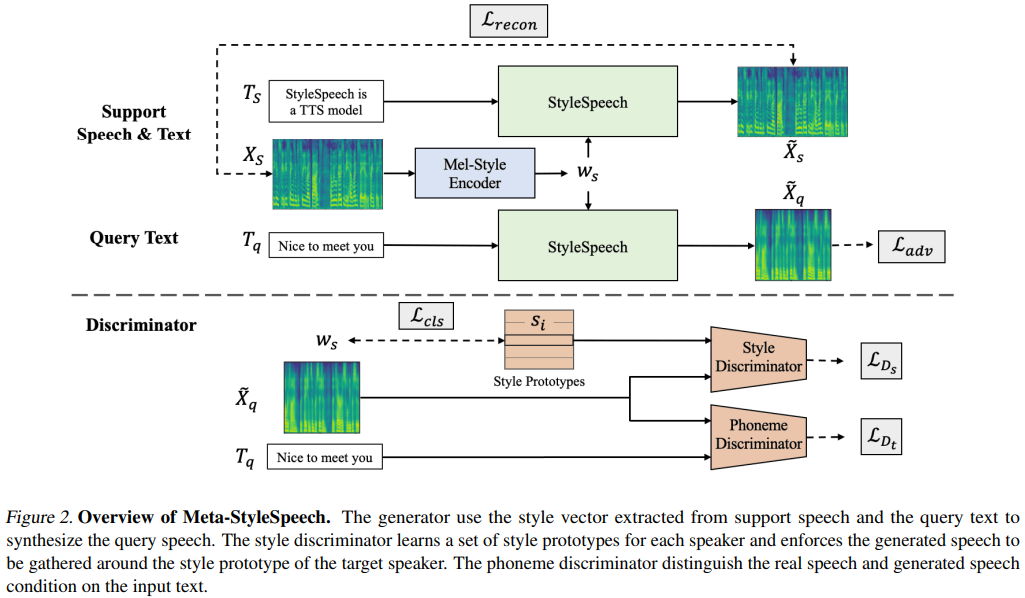
naive ) main )يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
يجب عليك تنزيل النماذج المسبقة ووضعها في output/ckpt/LibriTTS_meta_learner/ .
ل TTS متعددة الناطقين باللغة الإنجليزية ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
سيتم وضع الكلمات المولدة في output/result/ . سيكون لكل خطابك المصنوع نمط ref_audio .
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
لتوليف جميع الكلمات في preprocessed_data/LibriTTS/val.txt . يمكن اعتبار ذلك بمثابة إعادة بناء مجموعات بيانات التحقق من الصحة التي تشير إلى أنفسهم للنمط المرجعي.
يمكن السيطرة على معدل الملعب/الحجم/التحدث للكلمات التوليف عن طريق تحديد نسب الملعب/الطاقة/المدة المطلوبة. على سبيل المثال ، يمكن للمرء زيادة معدل التحدث بنسبة 20 ٪ وتقليل الحجم بنسبة 20 ٪ بنسبة 20 ٪
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
لاحظ أن قابلية التحكم نشأت من Fastspeade2 وليس مصلحة حيوية للأنماط. يرجى الرجوع إلى Styler [Demo ، Code] من أجل التحكم في كل عامل نمط.
مجموعات البيانات المدعومة
يجري
python3 prepare_align.py config/LibriTTS/preprocess.yaml
لبعض الاستعدادات.
بالنسبة للمحاذاة القسرية ، يتم استخدام Montreal القسري Aligner (MFA) للحصول على المحاذاة بين الكلمات وتسلسلات الصوت. يتم توفير محاذاة مسبقًا لمجموعات البيانات هنا. يجب عليك إلغاء ضغط الملفات في preprocessed_data/LibriTTS/TextGrid/ . بالتناوب ، يمكنك تشغيل جهاز Aligner بنفسك.
بعد ذلك ، قم بتشغيل البرنامج النصي المسبق
python3 preprocess.py config/LibriTTS/preprocess.yaml
تدريب النموذج الخاص بك مع
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
كما هو موضح في الورقة ، سيبدأ البرنامج النصي من تدريب النموذج الساذج مسبقًا حتى خطوات meta_learning_warmup ثم تدريب النموذج لخطوات إضافية عبر التدريب العرضي.
يستخدم
tensorboard --logdir output/log/LibriTTS
لخدمة Tensorboard على مضيفك المحلي. يتم عرض منحنيات الخسارة ، وتوليف الطيف الطيف ، والسمعات.
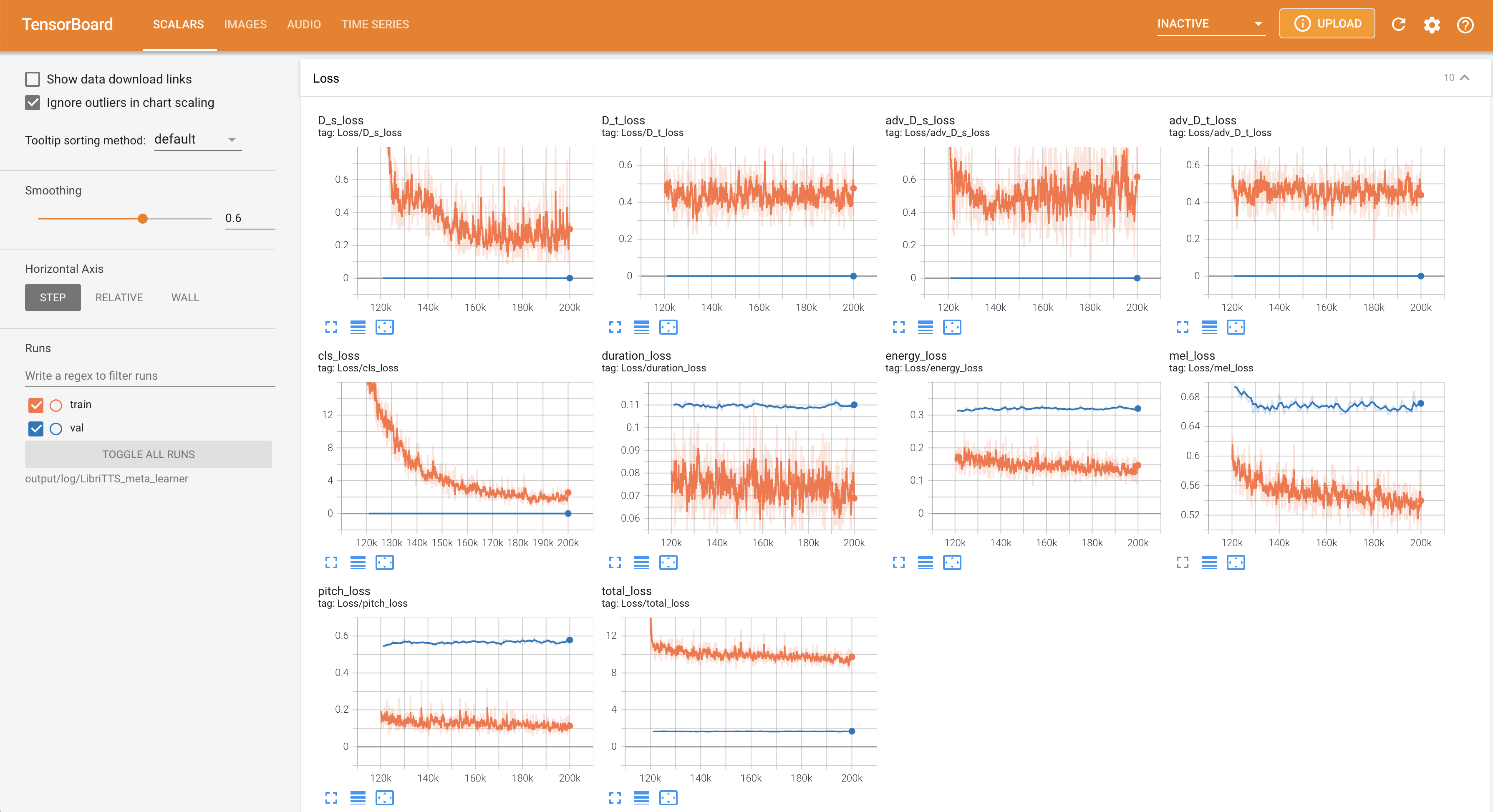
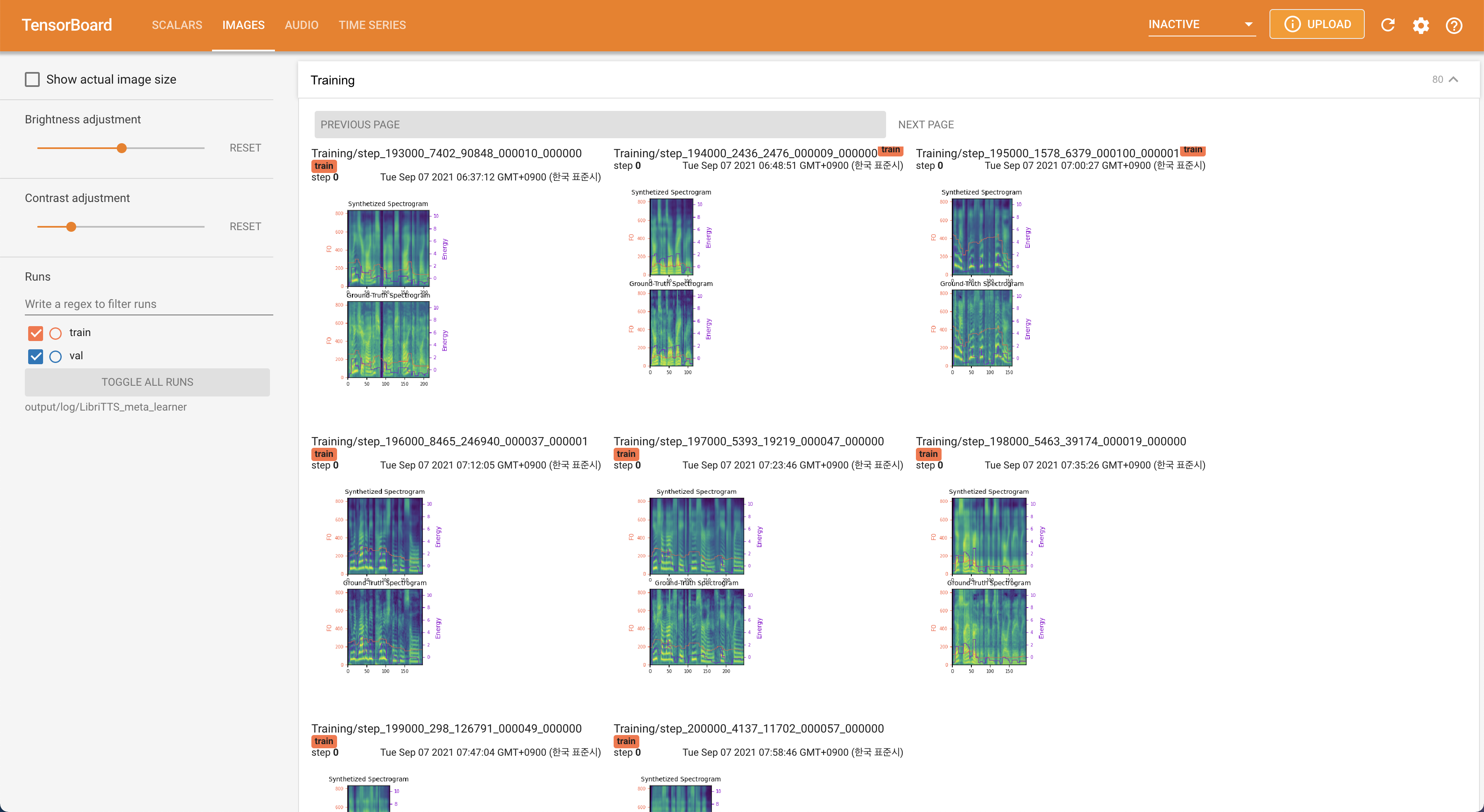
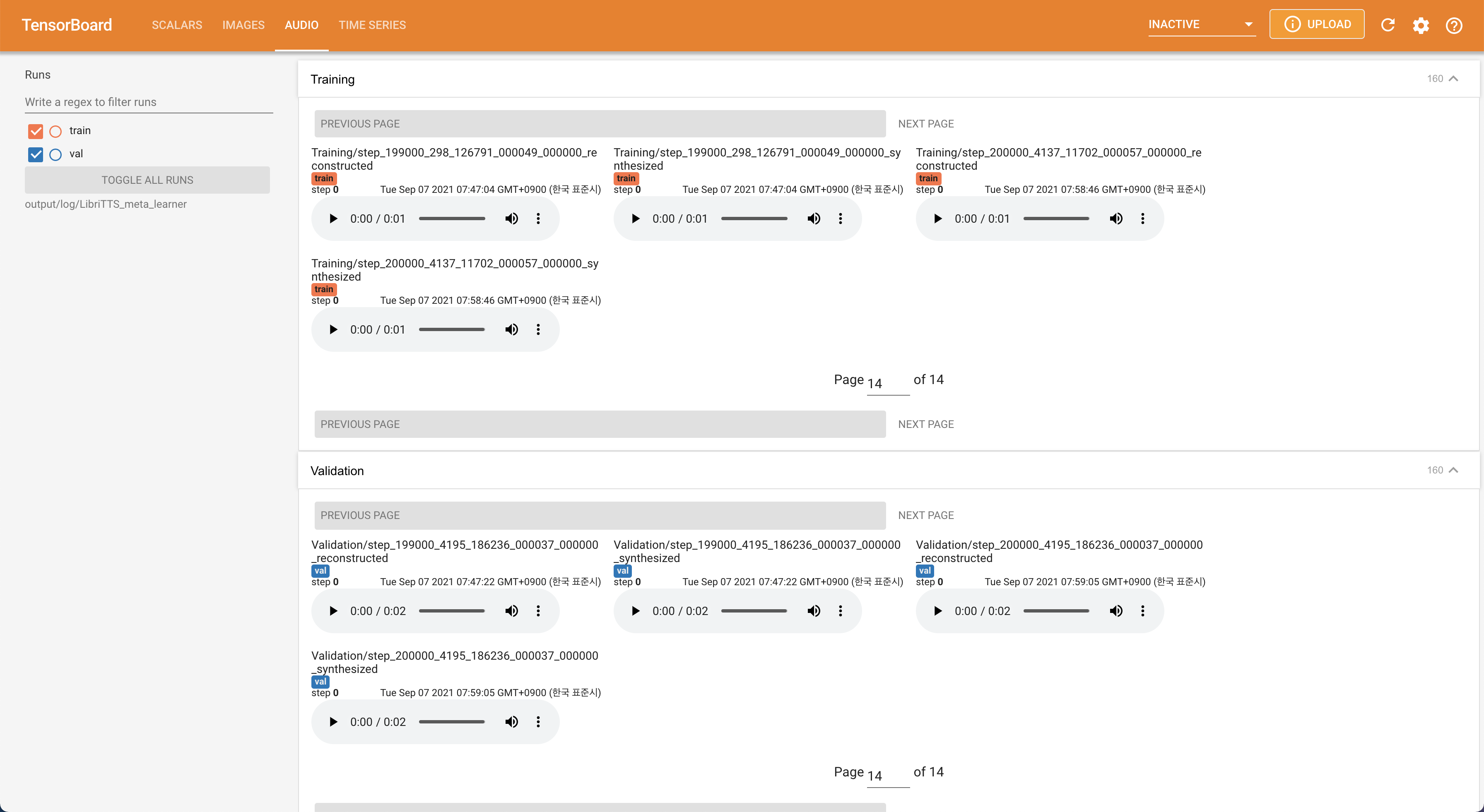
22050Hz بدلاً من 16kHz .80 إلى 128 .28.197M .16 على التدريب بدلاً من 48 أو 20 ويرجع ذلك أساسًا إلى نقص قدرة الذاكرة مع Titan-RTX 24GIB . يمكن تحقيق ذلك من خلال البرنامج النصي التالي لتصفية البيانات لفترة أطول من max_seq_len : python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train_filtered.txt في نفس موقع train.txt . @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


