StyleSpeech
v1.0.2
Pytorch-Implementierung von Meta-StyleSpeech: Multi-Speaker-adaptive Text-to-Speech-Generierung.
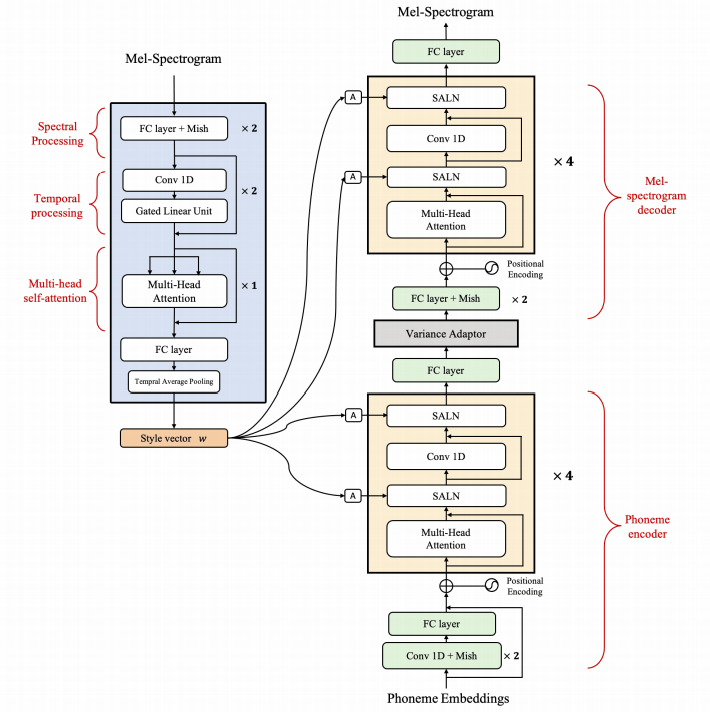
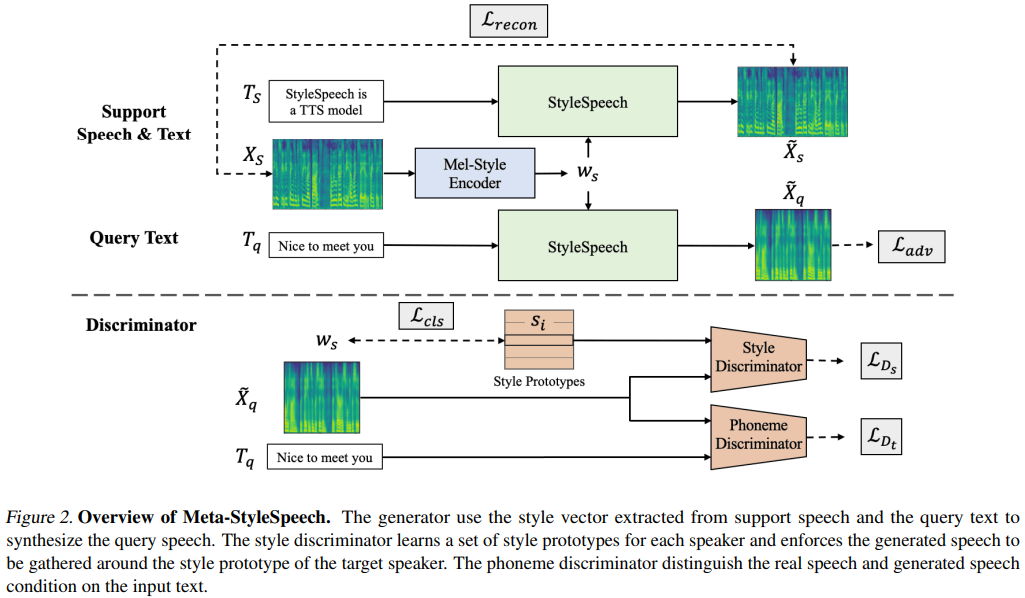
naive Zweig) main )Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Sie müssen vorgefertigte Modelle herunterladen und in output/ckpt/LibriTTS_meta_learner/ einfügen.
Für englische Multi-Sprecher-TTs laufen
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Die erzeugten Äußerungen werden in output/result/ . Ihre synthetisierte Rede hat den Stil von ref_audio .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
So synthetisieren Sie alle Äußerungen in preprocessed_data/LibriTTS/val.txt . Dies kann als Rekonstruktion von Validierungsdatensätzen angesehen werden, die sich als Referenzstil auf sich selbst beziehen.
Die Tonhöhe/Volumen-/Sprechrate der synthetisierten Äußerungen kann durch Angabe der gewünschten Pitch/Energy/Dauer -Verhältnisse gesteuert werden. Zum Beispiel kann man die Sprechrate um 20 % erhöhen und das Volumen um 20 % verringern
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml --duration_control 0.8 --energy_control 0.8
Beachten Sie, dass die Kontrollierbarkeit von Fastspeech2 stammt und kein wesentliches Interesse an Stylespeech. In Styler [Demo, Code] finden Sie die Kontrollierbarkeit jedes Stilfaktors.
Die unterstützten Datensätze sind
Laufen
python3 prepare_align.py config/LibriTTS/preprocess.yaml
Für einige Vorbereitungen.
Für die erzwungene Ausrichtung wird Montreal erzwungene Aligner (MFA) verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen zu erhalten. Vorextrahierte Ausrichtungen für die Datensätze werden hier bereitgestellt. Sie müssen die Dateien in preprocessed_data/LibriTTS/TextGrid/ entpacken. Alternativ können Sie den Aligner selbst ausführen.
Führen Sie danach das Vorverarbeitungskript durch
python3 preprocess.py config/LibriTTS/preprocess.yaml
Trainieren Sie Ihr Modell mit
python3 train.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
Wie im Papier beschrieben, beginnt das Skript von der Voraussetzung des naiven Modells bis zu meta_learning_warmup Schritten und dann das Modell für zusätzliche Schritte über episodisches Training.
Verwenden
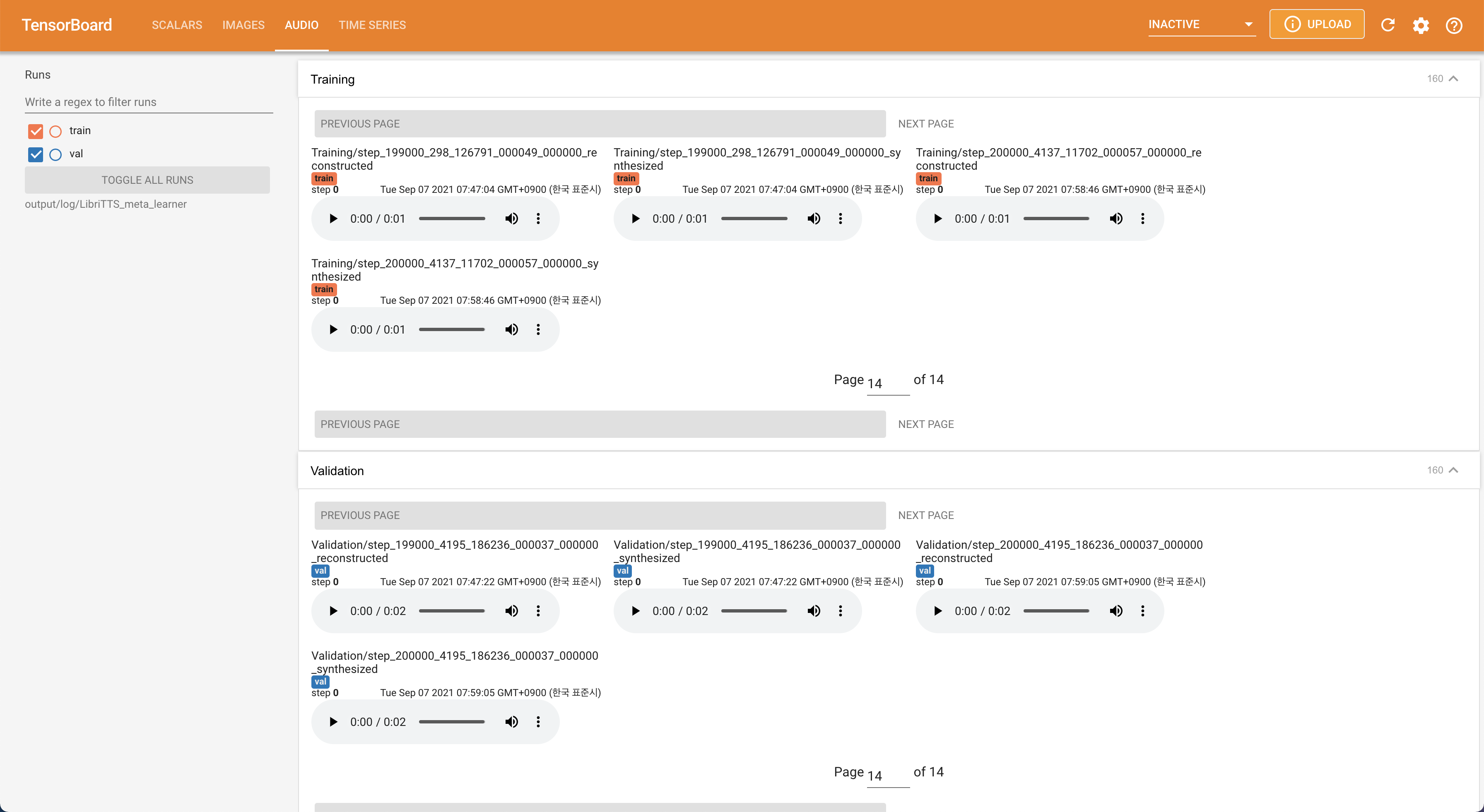
tensorboard --logdir output/log/LibriTTS
Tensorboard auf Ihrem örtlichen Haus servieren. Die Verlustkurven, synthetisierte Melspektrogramme und Audios werden gezeigt.
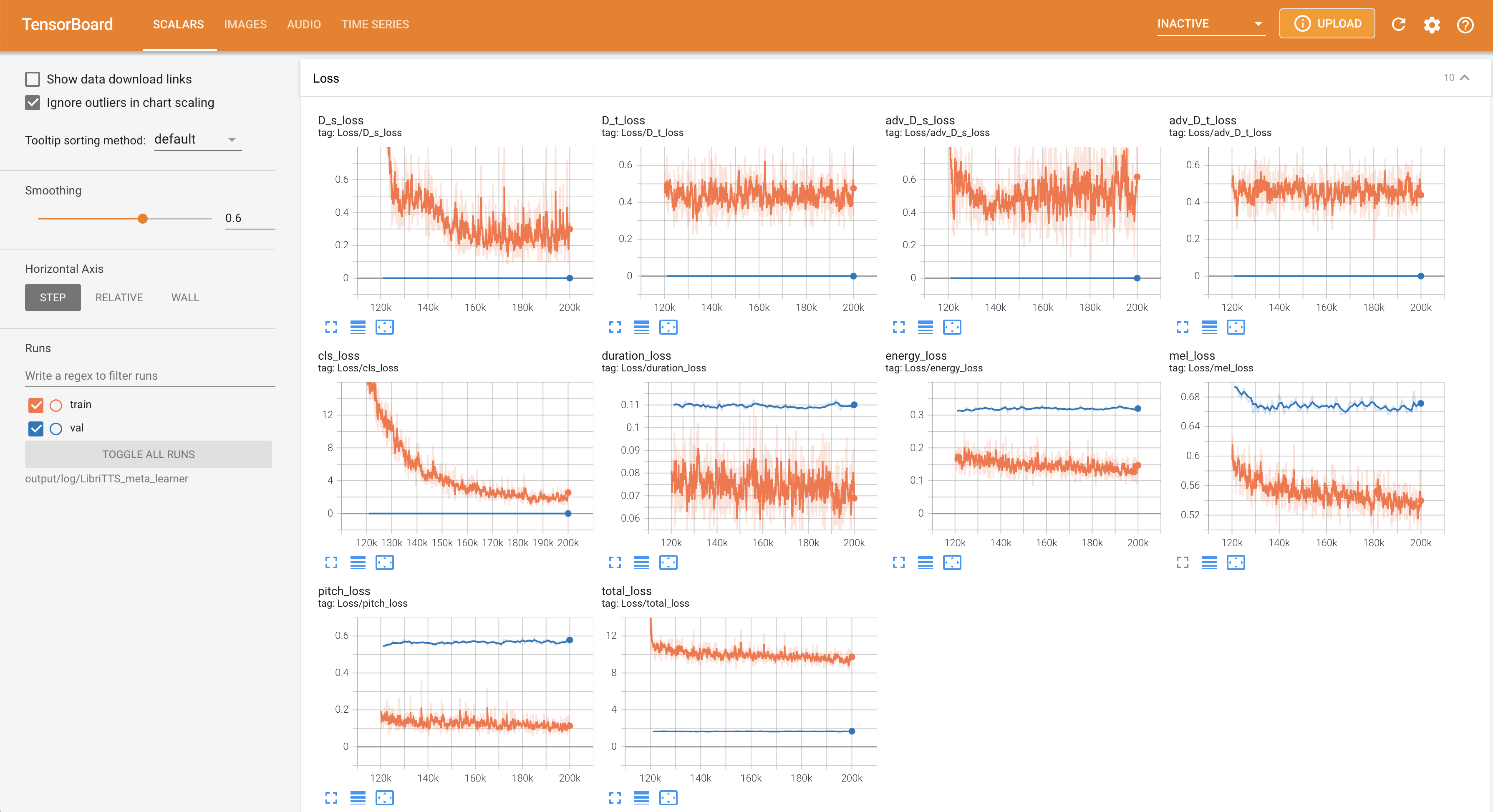
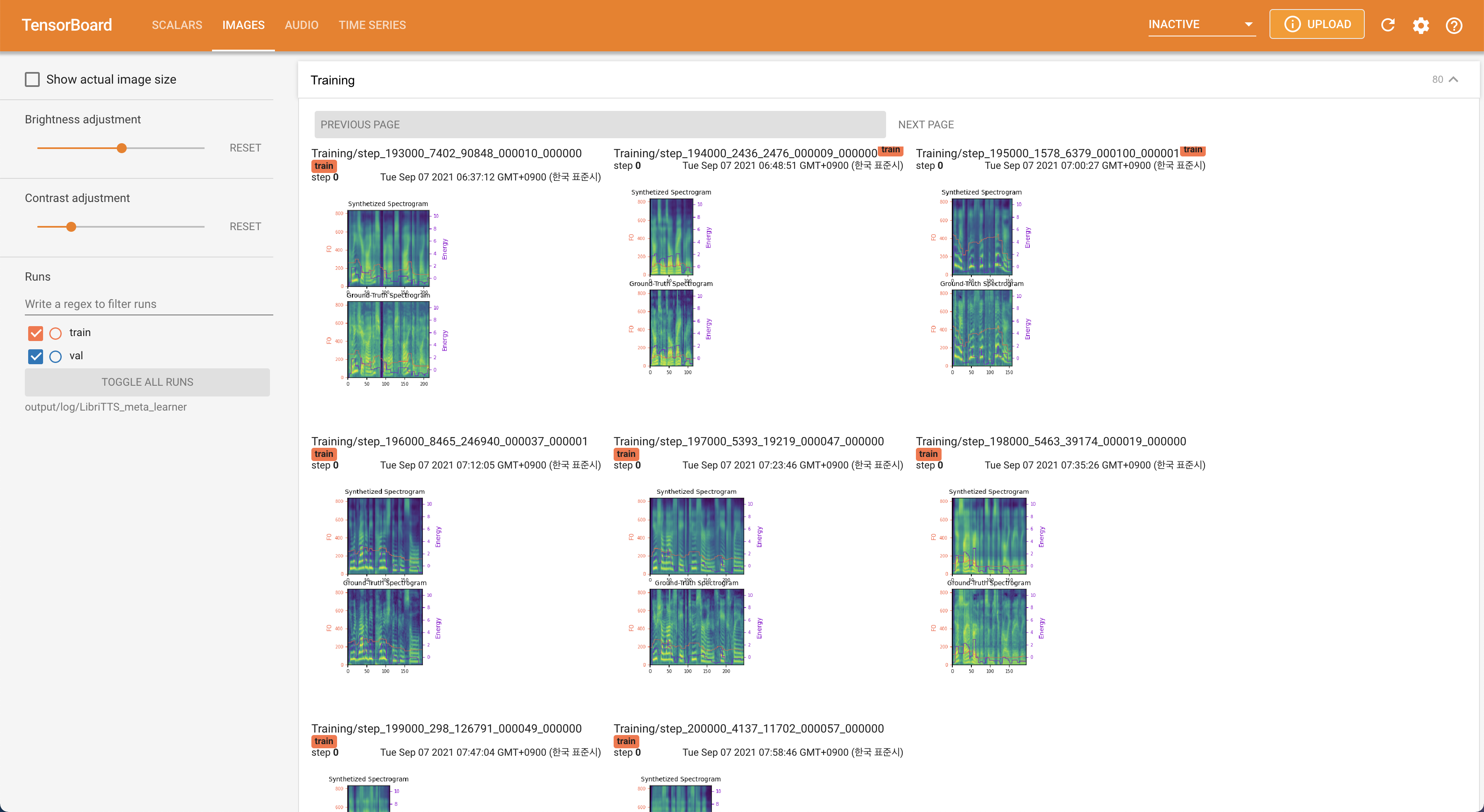
22050Hz Abtastrate anstelle von 16kHz .80 bis 128 zu verbessern.28.197M .16 Chargengröße für das Training anstelle von 48 oder 20 hauptsächlich aufgrund des Mangels an Speicherkapazität mit einem einzigen 24-Gib-Titan-RTX . Dies kann durch das folgende Skript erreicht werden, um Daten länger als max_seq_len herauszufiltern: python3 filelist_filtering.py -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml
train_filtered.txt am selben Ort von train.txt . @misc{lee2021stylespeech,
author = {Lee, Keon},
title = {StyleSpeech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/StyleSpeech}}
}


