MultiSpeech
1.0.0
这是多语言的Pytorch实现:多演讲者文本到Transformer的语音
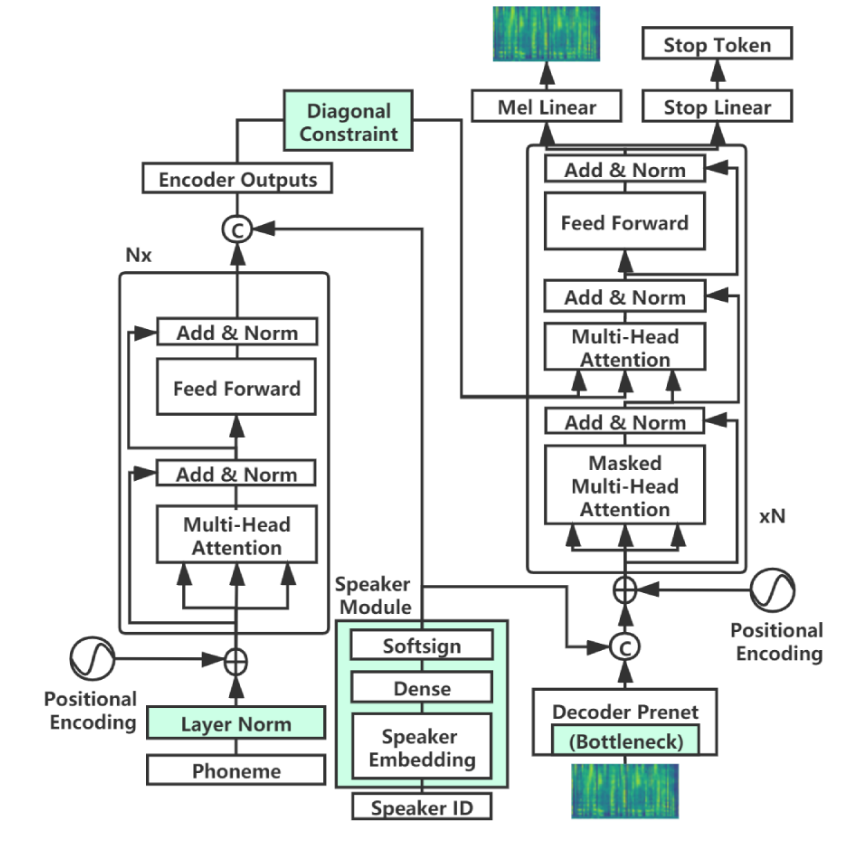
为了在数据上训练模型,请按照以下步骤操作
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
扬声器ID应该是整数,从0开始
python -m venv env source env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

