MultiSpeech
1.0.0
Ceci est une implémentation Pytorch de MultiSseech: texte multi-haut-parleurs à la parole avec transformateur
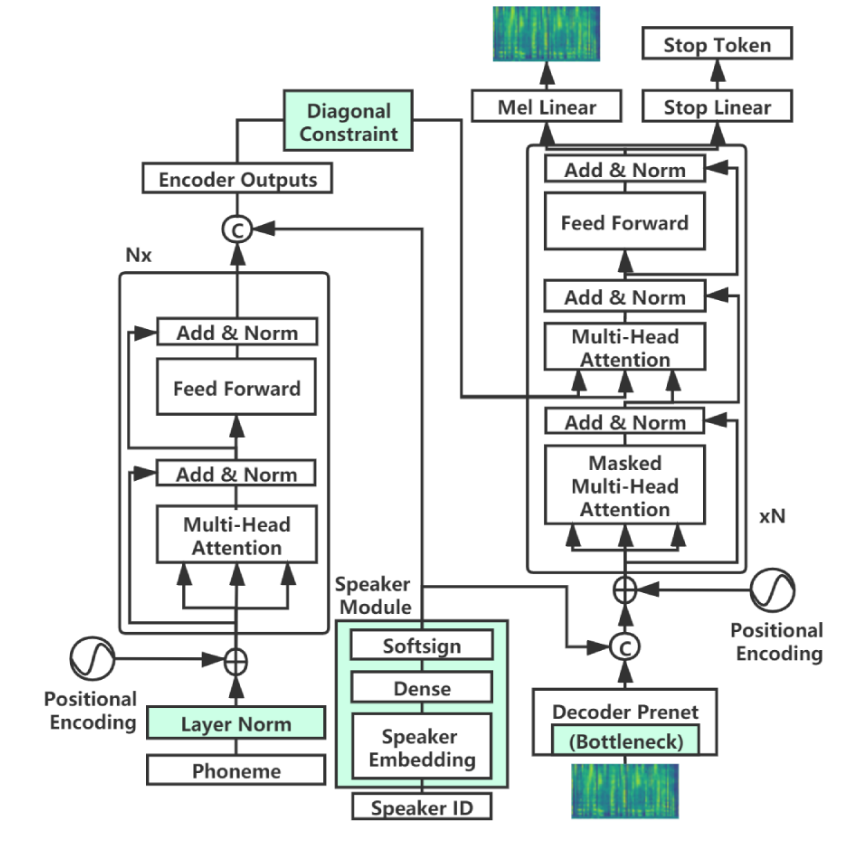
Afin de former le modèle sur vos données, suivez les étapes ci-dessous
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
L'ID du haut-parleur doit être entier et commence à 0
python -m venv env source env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

