MultiSpeech
1.0.0
Esta é uma implementação de Pytorch do MultisSeech: texto multi-falante para a fala com o transformador
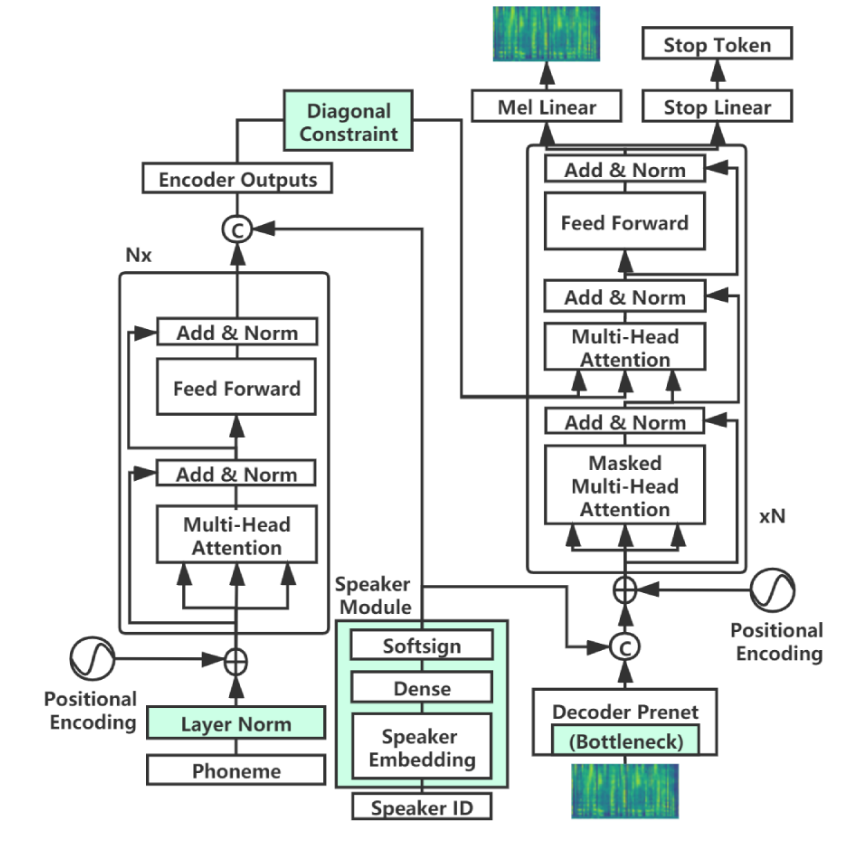
Para treinar o modelo em seus dados, siga as etapas abaixo
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
O ID do alto -falante deve ser inteiro e começa de 0
python -m venv env source env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

