MultiSpeech
1.0.0
これはマルチスピーチのPytorch実装です:トランスを使用したマルチスピーカーテキストからスピーチへ
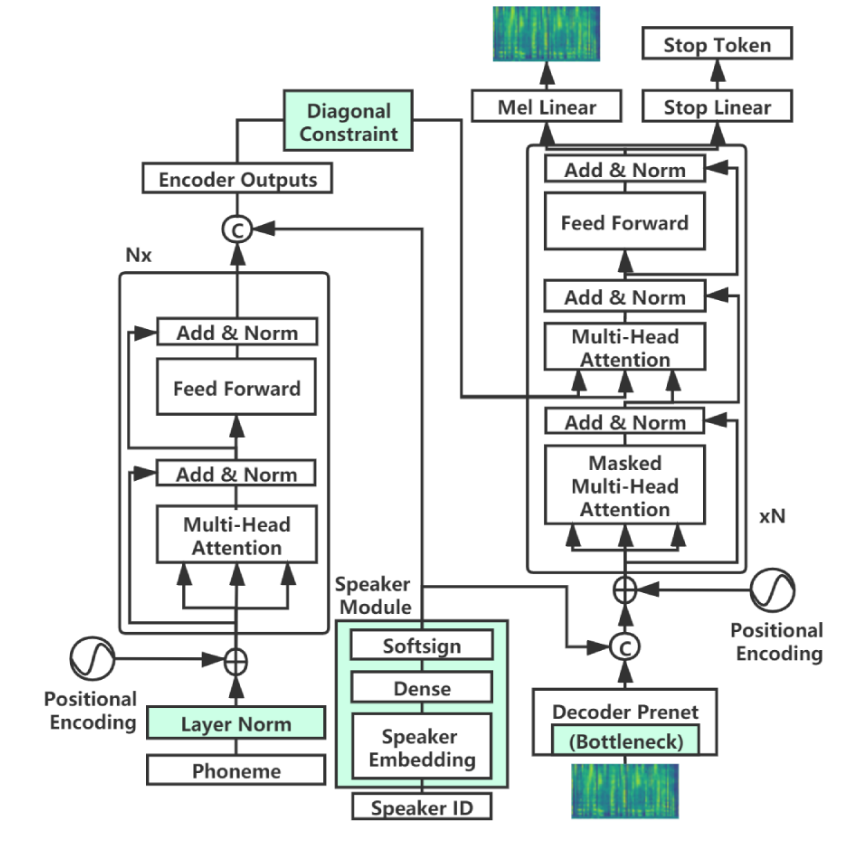
データでモデルをトレーニングするために、以下の手順に従ってください
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
スピーカーIDは整数である必要があり、0から始まります
python -m venv env source env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

