MultiSpeech
1.0.0
이것은 Multispeech의 Pytorch 구현 : 변압기를 사용한 Multi-Speaker 텍스트
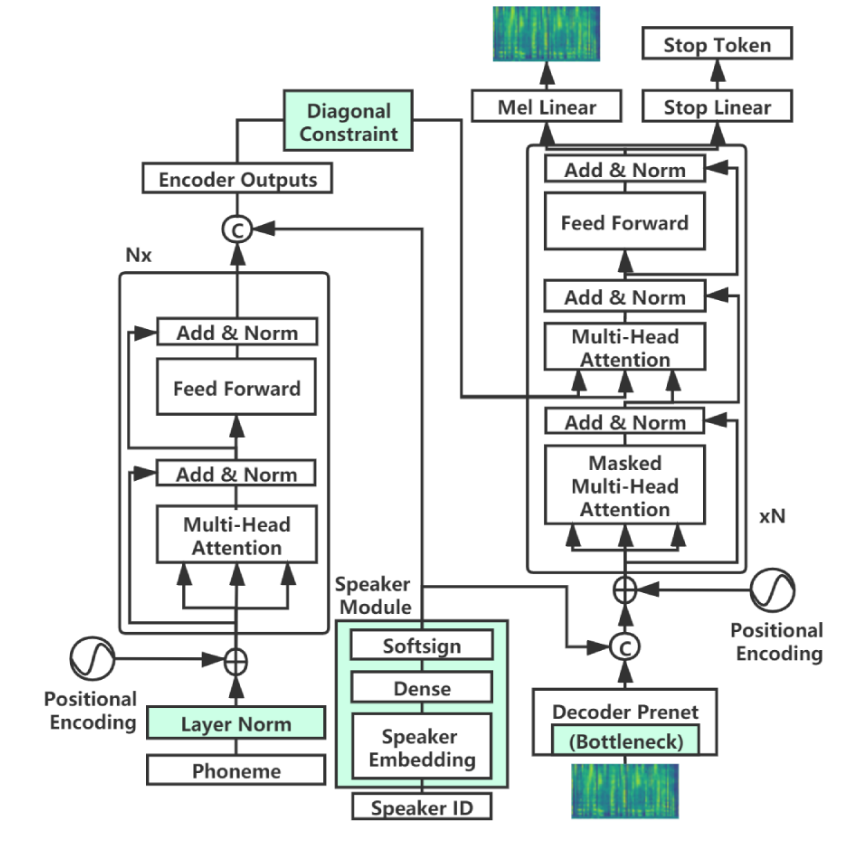
데이터에 대한 모델을 교육하려면 아래 단계를 따르십시오.
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
스피커 ID는 정수 여야하며 0부터 시작합니다.
python -m venv env source env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

