MultiSpeech
1.0.0
This is a PyTorch implementation of MultiSpeech: Multi-Speaker Text to Speech with Transformer
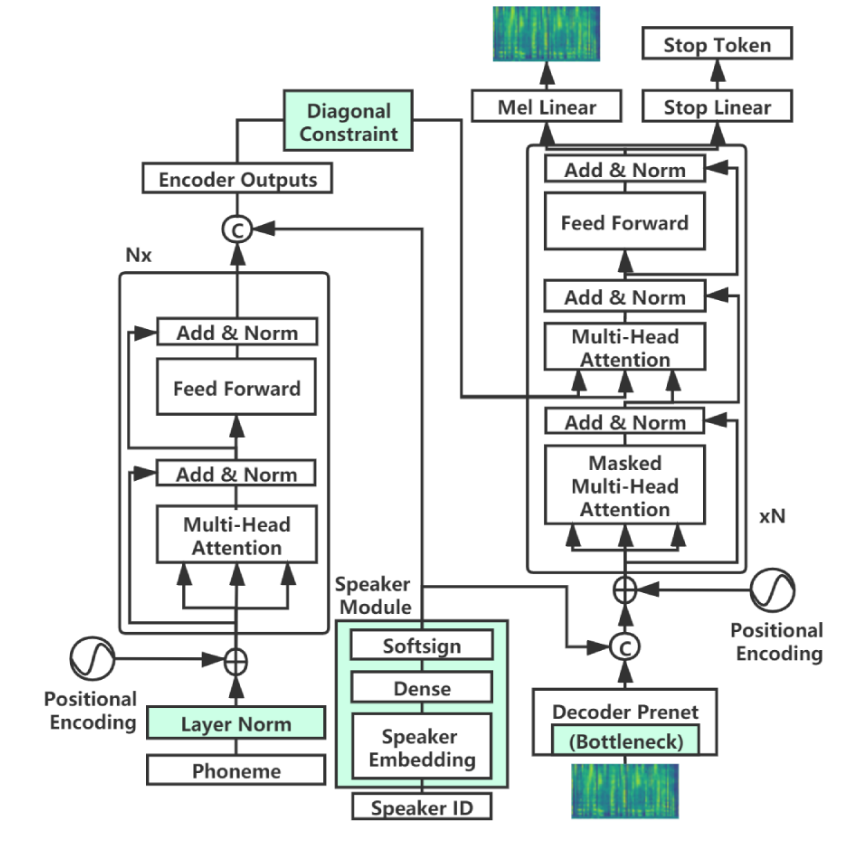
In order to train the model on your data, follow the steps below
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
The speaker id should be integer and starts from 0
python -m venv envsource env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

