MultiSpeech
1.0.0
Dies ist eine Pytorch-Implementierung von Multispeech: Multi-Sprecher-Text zur Sprache mit Transformator
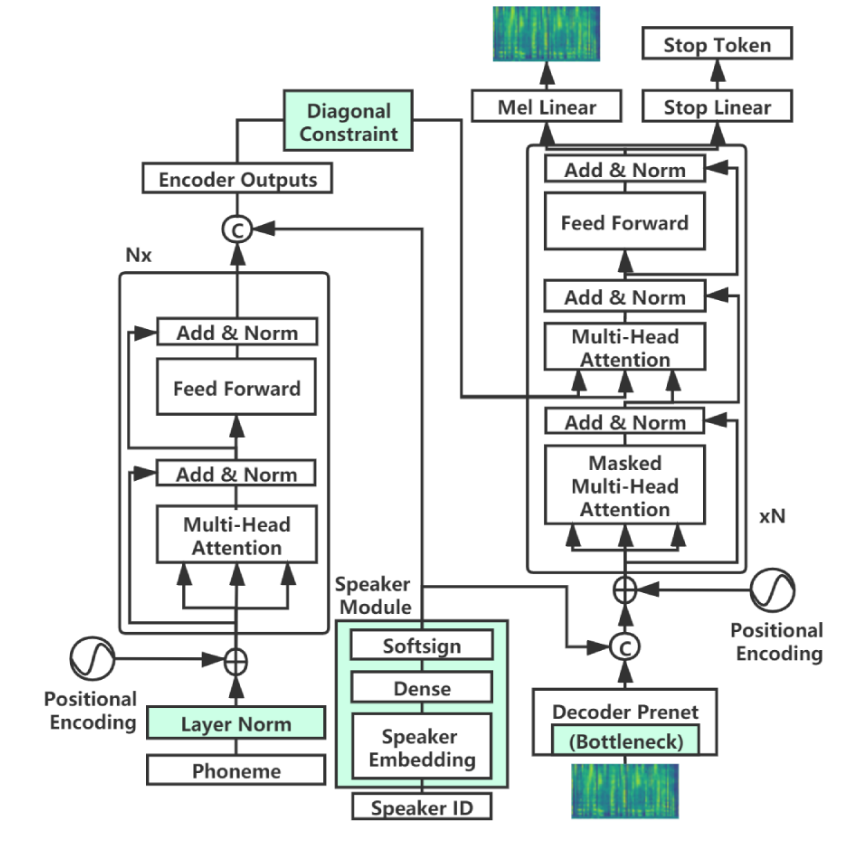
Um das Modell auf Ihren Daten zu trainieren, befolgen Sie die folgenden Schritte
speaker_id,audio_path,text,duration
0|file/to/file.wav|the text in that file|3.2
Die Lautsprecher -ID sollte ganzzahlig sein und von 0 beginnt
python -m venv env source env/bin/activatepip install -r requirements.txtpython train.py --train_path train_data.txt --test_path test_data.txt --checkpoint_dir outdir --epoch 100 --batch_size 64

