client side rendering
1.0.0
该项目是CSR的案例研究,它探讨了与服务器端渲染相比,客户端渲染应用程序的潜力。
可以在此项目的比较页面上找到所有渲染方法的深入比较:https://client-side-rendering.pages.dev/comparison
客户端渲染(CSR)是指将静态资产发送到Web浏览器,并允许其处理应用程序的整个渲染过程。
服务器端渲染(SSR)涉及在服务器上渲染整个应用程序(或页面),并提供预渲染的HTML文档以进行显示。
静态站点生成(SSG)是将HTML页面作为静态资产预先生成的过程,然后由浏览器发送和显示。
与普遍的信念相反,现代框架中的SSR过程(例如React , Angular , Vue和Svelte )导致应用程序渲染两次:一次在服务器上,然后在浏览器上再次呈现(这被称为“水合”)。如果没有第二次渲染,该应用将是静态且无与伦比的,本质上的行为就像是“无生命”的网页。
有趣的是,水合过程似乎并不比典型的渲染速度快(当然不包括绘画阶段)。
同样重要的是要注意,SSG应用程序也必须进行水合。
在SSR和SSG中,HTML文档已完全构建,提供了以下好处:
另一方面,CSR应用程序提供以下优势:
在此案例研究中,我们将重点关注CSR,并探索如何克服其明显局限性的方法,同时利用其优势到峰值。
所有优化将被整合到已部署的应用程序中,可以在此处找到:https://client-side-rendering.pages.dev。
“最近,SSR(服务器端渲染)席卷了JavaScript前端世界。您现在可以在服务器上渲染网站和应用程序之前将其发送给客户是一个绝对革命性的想法(而且完全不是每个人在JS客户端应用程序在首先流行之前所做的事情...)。
但是,对PHP,ASP,JSP和此类站点有效的同样批评对于今天的服务器端渲染有效。它很慢,很容易折断,很难正确实施。
事实是,尽管每个人都可能告诉您,但您可能不需要SSR。您几乎可以通过使用预处理获得几乎所有的优势(没有缺点)。”
〜PRERENDER SPA插件
近年来,服务器端渲染以诸如Next.js和Remix的框架形式的形式获得了巨大的知名度,以至于开发人员通常默认使用它们而不完全理解其限制,即使在不需要SEO的应用程序中(例如,那些具有login要求的应用程序)。
尽管SSR具有其优势,但这些框架继续强调其速度(“默认的性能”),这表明客户端渲染(CSR)固有地慢。
此外,存在一个广泛的误解,即只能使用SSR实现完美的SEO,并且CSR应用程序不能针对搜索引擎爬网进行优化。
SSR的另一个常见论点是,随着Web应用程序的增长,它们的加载时间将继续增加,从而导致CSR应用程序的FCP性能差。
虽然应用程序的确变得越来越丰富,但单页的大小实际上应该随着时间的推移而减小。
这是由于创建库和框架的较小,更高效的版本的趋势,例如zustand , day.js , headless-ui和react-router v6 。
我们还可以观察到框架随时间的尺寸减少:角(74.1kb),React(44.5kb),Vue(34KB),实心(7.6KB)和Svelte(1.7KB)。
这些库对网页脚本的整体重量产生了重大贡献。
通过适当的代码分解,页面的初始加载时间可能会随着时间的推移而减少。
该项目实现了一个基本的CSR应用程序,具有优化的代码分解和预加载。目的是让单个页面的加载时间在应用程序尺度时保持稳定。
目的是模拟生产级应用程序的软件包结构,并通过并行的请求最大程度地减少加载时间。
重要的是要注意,提高性能不应以开发人员的经验为代价。因此,该项目的体系结构只会从典型的反应设置中稍微修改,避免了Next.js(例如JS)或SSR的局限性的刚性,有见识的结构。
该案例研究将重点介绍两个主要方面:绩效和SEO。我们将探索如何在这两个领域中取得最高分。
请注意,尽管该项目是使用React实施的,但大多数优化都是框架 - 不可固定的,纯粹基于Bundler和Web浏览器。
我们将假设标准的WebPack(RSPACK)设置,并在进步时添加所需的自定义。
第一个经验法则是最大程度地减少依赖性,其中包括最小的文件大小。
例如:
我们可以使用day.js ,而不是瞬间, zustand,而不是redux工具包,等等。
这不仅对CSR应用程序,而且对于SSR(和SSG)应用程序也很重要,因为较大的捆绑包会导致更长的负载时间,因此在页面变得可见或交互式时会延迟。
理想情况下,每个哈希文件都应被缓存,并且index.html绝不应该被缓存。
这意味着浏览器最初将缓存main.[hash].js ,并且只有在其哈希(内容)更改时才必须重新下载:

但是,由于main.js包括整个捆绑包,因此代码的最小变化将导致其缓存到期,这意味着浏览器必须再次下载。
现在,我们的捆绑包中的哪一部分包括大部分重量?答案是依赖项,也称为供应商。
因此,如果我们可以将供应商分为自己的哈希块,那将允许我们的代码和供应商代码之间的分离,从而减少缓存无效。
让我们将以下优化添加到我们的配置文件中:
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
}这将创建一个vendors.[hash].js文件:

尽管这是一个实质性的改进,但是如果我们更新一个很小的依赖性会怎样?
在这种情况下,整个供应商块的缓存将无效。
因此,为了进一步改善它,我们将每个依赖性将其分布到自己的障碍部分:
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ }这将创建诸如react-dom.[hash].js包含一个大供应商和一个[id].[hash].js文件,其中包含所有剩余(小)供应商:
有关默认配置的更多信息(例如拆分阈值大小):
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
我们写的许多功能最终仅在我们的几页中使用,因此我们希望仅在用户访问使用的页面时才加载它们。
例如,我们不希望用户必须等到React-big-Calendar软件包仅加载主页,然后将其解析和执行。我们只希望在访问日历页面时发生这种情况。
我们可以实现这一目标的方法是(最好)通过基于路由的代码分裂:
app.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) )因此,当用户访问Pokemon页面时,他们仅下载主要的块脚本(包括所有共享依赖项,例如框架)和pokemon.[hash].js Chunk。
注意:鼓励下载整个应用程序,以便用户会体验即时,类似应用程序的导航。但是,将所有资产分解为单个脚本,从而延迟页面的第一个渲染是一个坏主意。
这些资产应异步下载,并且仅在用户要求的页面完成渲染并完全可见之后。
代码拆分具有一个主要缺陷 - 运行时不知道需要哪些异步块,直到主脚本执行为止,导致它们被大量延迟获取(因为它们对CDN进行了另一个往返):

我们解决此问题的方法是编写一个自定义插件,该插件将嵌入文档中的脚本,该脚本将负责预加载相关资产:
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}脚本/注入式 - Assets-plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPlugin脚本/preload-assets.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( )可以在此处找到导入的pages.js 。
这样,浏览器就可以与关键资产并行获取特定页面的脚本块:
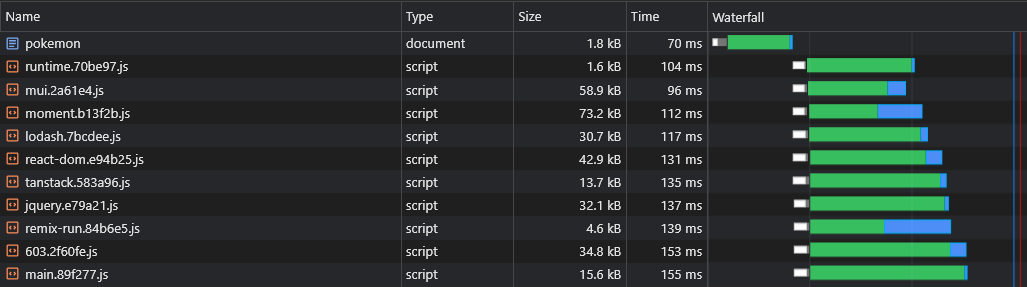
代码拆分引入了另一个问题:异步供应商重复。
假设我们有两个异步块: lorem-ipsum.[hash].js and pokemon.[hash].js 。如果它们都包含与主要块一部分相同的依赖关系,则意味着用户将两次下载该依赖项。
因此,如果所述依赖性是moment ,并且重量为72kb,那么异步块的尺寸至少为72kb。
我们需要将这种依赖性与这些异步块分开,以便它们之间可以共享:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
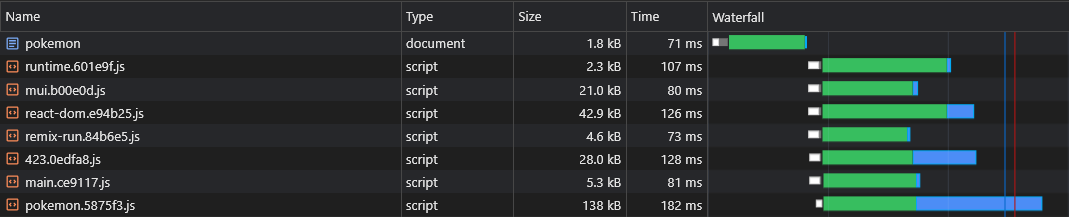
}现在两个lorem-ipsum.[hash].js和pokemon.[hash].js将使用提取的moment.[hash].js块,使用户宽泛了很多网络流量(并为这些资产提供更好的高速缓存持久性)。
但是,在构建应用程序之前,我们无法分解哪个异步供应商块,因此我们不知道我们需要预加载哪个异步供应商块(请参阅“预加载异步异步”部分”部分:
这就是为什么我们将这些块名称附加到异步供应商的名称:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}脚本/注入式 - Assets-plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}脚本/preload-assets.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
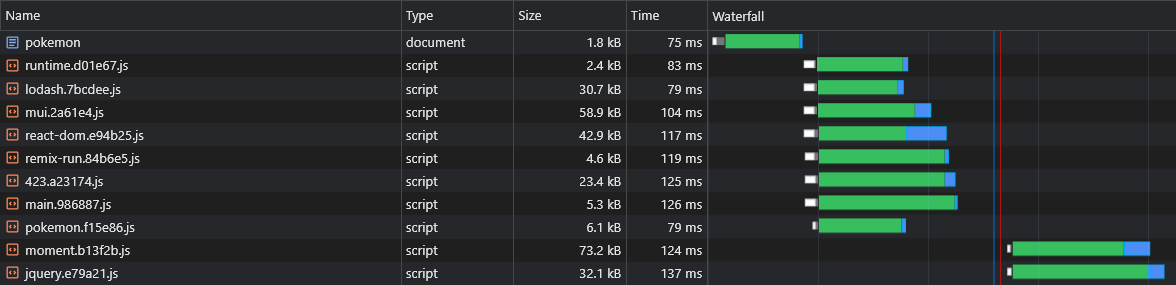
+ })现在,所有异步供应商的块将与他们的父母异步块并行获取:
SSR上CSR的假定缺点之一是该页面的数据(提取请求)只有在浏览器中下载,解析和执行JS之后才能触发:
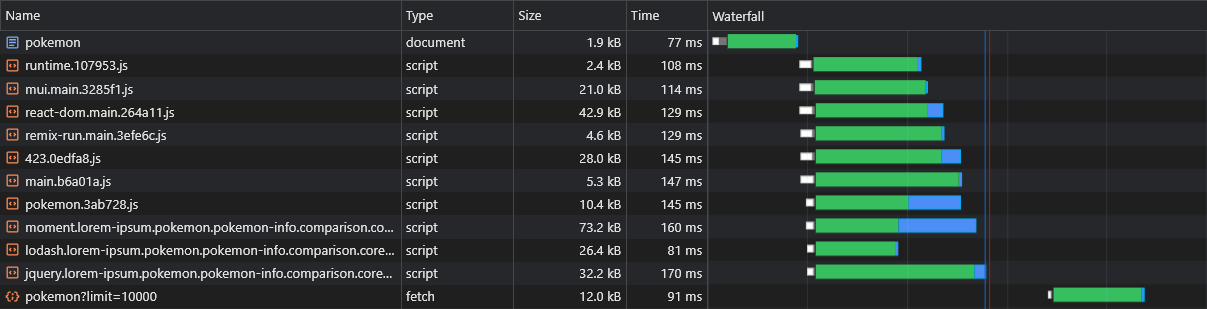
为了克服这一点,我们将通过修补fetch API再次使用预加载,这一次是数据本身:
脚本/注入式 - Assets-plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})脚本/preload-assets.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets()提醒:可以在此处找到pages.js文件。
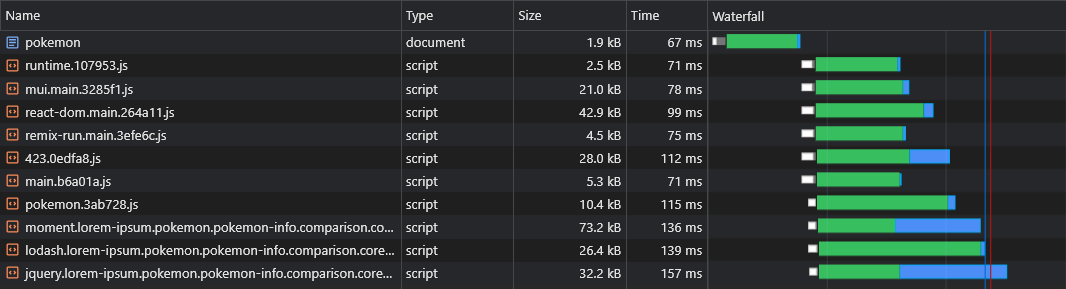
现在,我们可以看到数据立即获取:
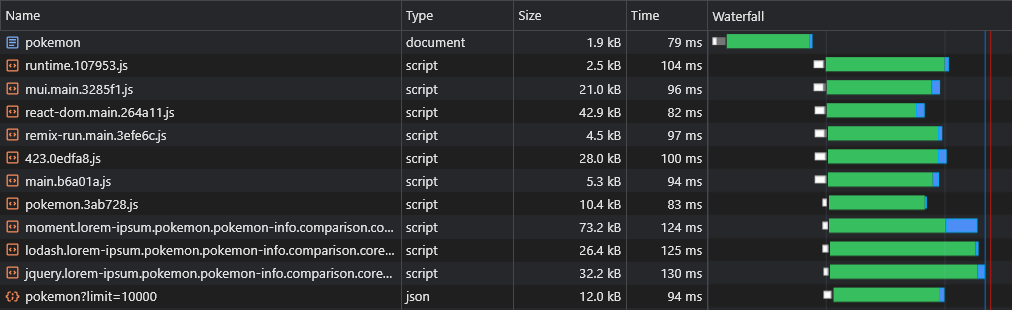
使用上面的脚本,我们甚至可以预上动态路由数据(例如Pokemon/:name )。
用户应该在我们的应用中具有平稳的导航体验。
但是,将每个页面分开会导致导航的明显延迟,因为必须在屏幕上渲染每个页面(按需)。
我们希望提前预取时所有页面。
我们可以通过写一个简单的服务工作者来做到这一点:
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}src/utils/service-worker-registration.ts
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}public/services-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )现在,所有页面都将在用户试图导航到它们之前预摘要和缓存。
此方法还将生成完整的代码缓存。
在检查我们的43KB react-dom.js文件时,我们可以看到,返回请求所需的时间为60ms,而下载该文件的时间为3ms:

这表明了一个众所周知的事实,即RTT对网页加载时间有很大影响,有时甚至超过下载速度,即使在我们的情况下从附近的CDN Edge提供资产也是如此。
此外,更重要的是,我们可以看到,下载了HTML文件后,我们有一个较大的时间板,浏览器会闲置,只等待脚本到达:
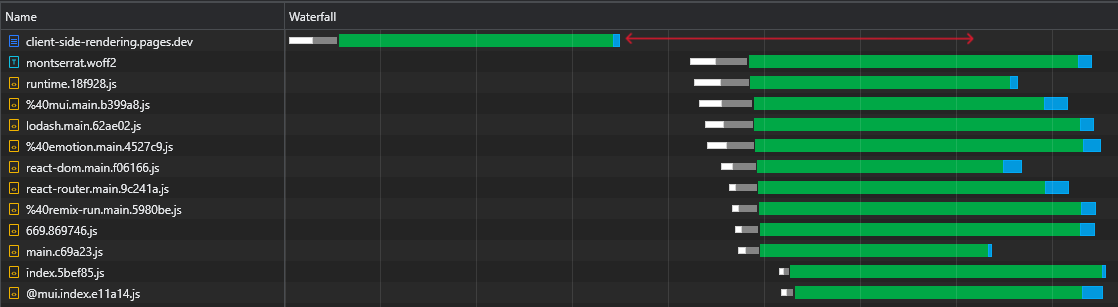
这是很多宝贵的时间(以红色为标记),浏览器可以用来下载,解析甚至执行脚本,从而加快页面的可见性和交互性。
每次资产都会发生变化(部分缓存)时,这种效率低下将再次发生。这不是只发生在第一次访问中的事情。
那么我们如何消除这个空闲时间呢?
我们可以嵌入文档中的所有初始(关键)脚本,以便它们将开始下载,解析和执行,直到异步页面资产到达:

我们可以看到,浏览器现在可以获取其初始脚本,而无需向CDN发送另一个请求。
因此,浏览器将首先发送异步块和预加载数据的请求,尽管这些请求正在待处理,但它将继续下载并执行主脚本。
我们可以看到,在HTML文件完成下载,解析和执行之后,异步块开始下载(以蓝色为标记),这节省了很多时间。
尽管这种变化在快速网络上产生了重大影响,但对于较慢的网络而言,它更为重要,因为延迟更大,RTT的影响力更大。
但是,该解决方案有两个主要问题:
为了克服这些问题,我们不能再坚持使用静态HTML文件,因此我们将利用服务器的功能。或者,更确切地说,是Cloudflare无服务器工作者的功能。
该工人应拦截每个HTML文档请求,并量身定制一个非常适合它的响应。
整个流程应如下描述:
X-Cached标头。如果存在此类标题,它将迭代其价值和仅在响应中缺乏的相关*资产。如果不存在此类标题,它将在响应中内联所有相关*资产。X-Cached标头。*初始资产和页面特定资产。
这样可以确保浏览器准确地收到所需的资产(不再,不再)以单个往返显示当前页面!
脚本/注入式 - Assets-plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpublic/_worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src/utils/dractrion-inline-scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptssrc/utils/service-worker-registration.ts
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}public/services-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )新鲜(完全未适应)的负载的结果是例外:

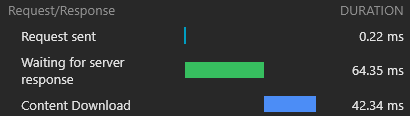

在下一个负载中,Cloudflare工人以最小(1.8KB)HTML文档做出响应,并且所有资产都立即从缓存中提供。
这种优化使我们陷入了另一个 - 将大块分成更小的碎片。
根据经验,将捆绑包分成太多的块可能会损害性能。这是因为该页面在下载所有文件之前不会呈现,并且块越多,其中一个延迟的可能性就越大(因为硬件和网络速度是非线性的)。
但是在我们的情况下,这是无关紧要的,因为我们会嵌入所有相关的块,因此它们一次被填写。
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},这种极端的分裂将导致更好的缓存持久性,进而将通过部分缓存更快地加载时间。
当从CDN获取静态资产时,它包括一个ETag标头,这是资源的内容哈希。根据随后的请求,浏览器检查是否具有存储的ETAG。如果这样做,它将以If-None-Match标头发送ETAG。然后,CDN将接收到的ETAG与当前的ETAG进行比较:如果它们匹配,则返回304 Not Modified状态,表明浏览器可以使用缓存的资产;如果没有,它将返回具有200状态的新资产。
在传统的CSR应用程序中,重新加载页面会导致HTML 304 Not Modified ,并提供了其他资产。每条路线都有独特的ETAG,即使/lorem-ipsum /pokemon ETAG相同,也有不同的缓存条目。
在CSR水疗中心,由于只有一个HTML文件,因此每个页面请求使用相同的ETAG。但是,由于ETAG是每条路线存储的,因此浏览器不会为未访问的页面发送一个If-None-Match标头,即使它是同一文件,也会导致200状态和html的重新下载。
但是,我们可以通过工人之间的协作轻松地创建自己的(改进)这种行为的实施:
脚本/注入式 - Assets-plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}public/_worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}public/services-worker.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
}请注意,对于CDN不会自动发送ETag的情况,包括自定义X-ETag 。
现在,即使没有更改,我们的无服务器工作人员将始终以304 Not Modified状态代码响应,即使对于未访问的页面也是如此。
使用服务工作者时,浏览器延迟发送初始HTML文档请求,直到加载服务工作者为止,这可能会导致略微到中等的页面延迟,具体取决于硬件。
对此问题的本机解决方案称为导航预紧力。我们将实施此操作,以确保立即发送文档请求,而无需等待服务工作人员加载:
src/utils/service-worker-registration.ts
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}public/services-worker.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )通过此实施,将立即发送文档请求,独立于服务工作人员。
注意:需要React(V18),Svelte或Solid.js
当我们将页面与主应用程序分开时,我们将其渲染阶段分开,这意味着该应用程序将在页面呈现之前呈现。
因此,当我们从一个异步页面移动到另一个页面时,我们会看到一个空白空间,直到页面呈现为止:
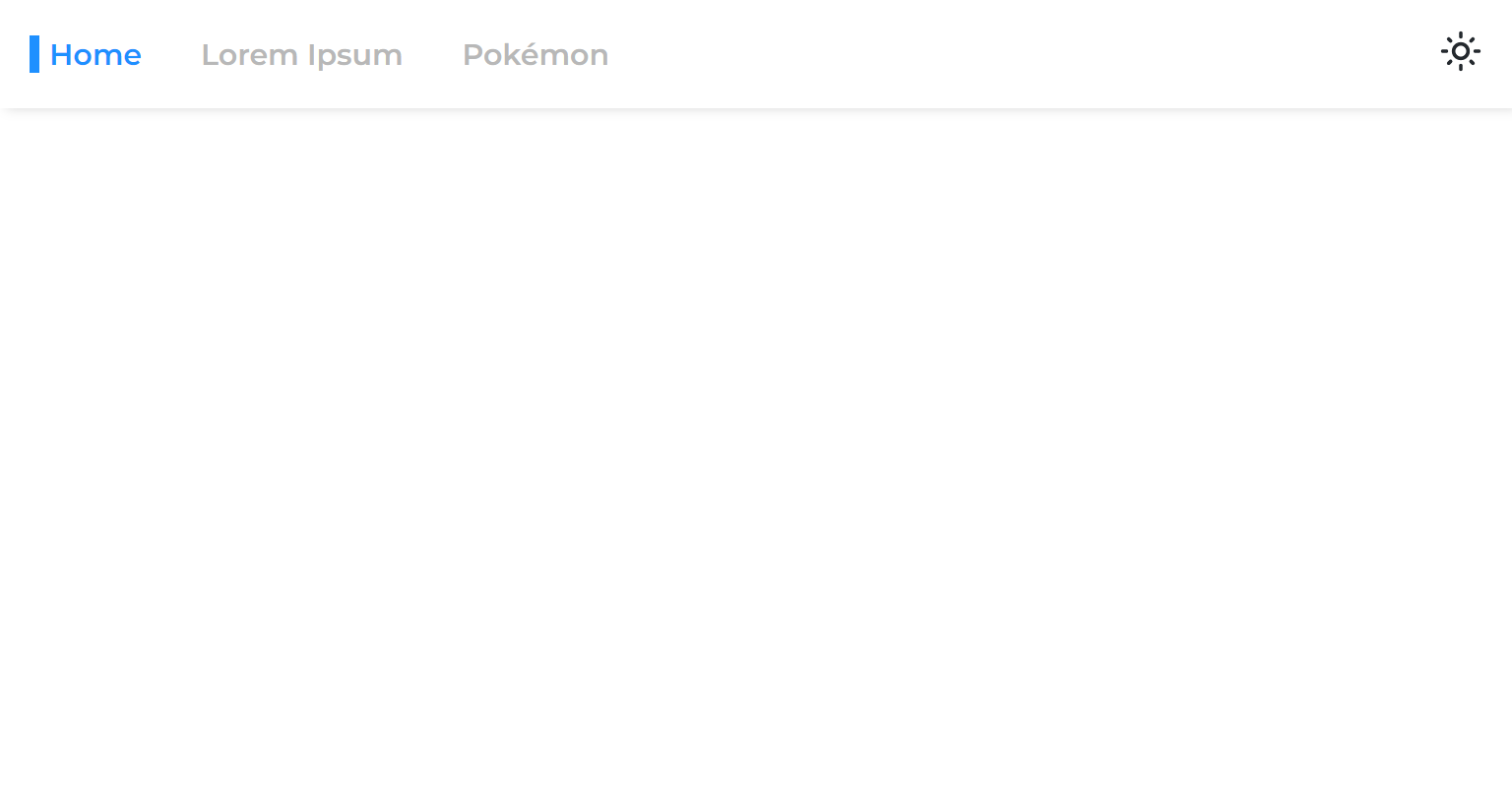
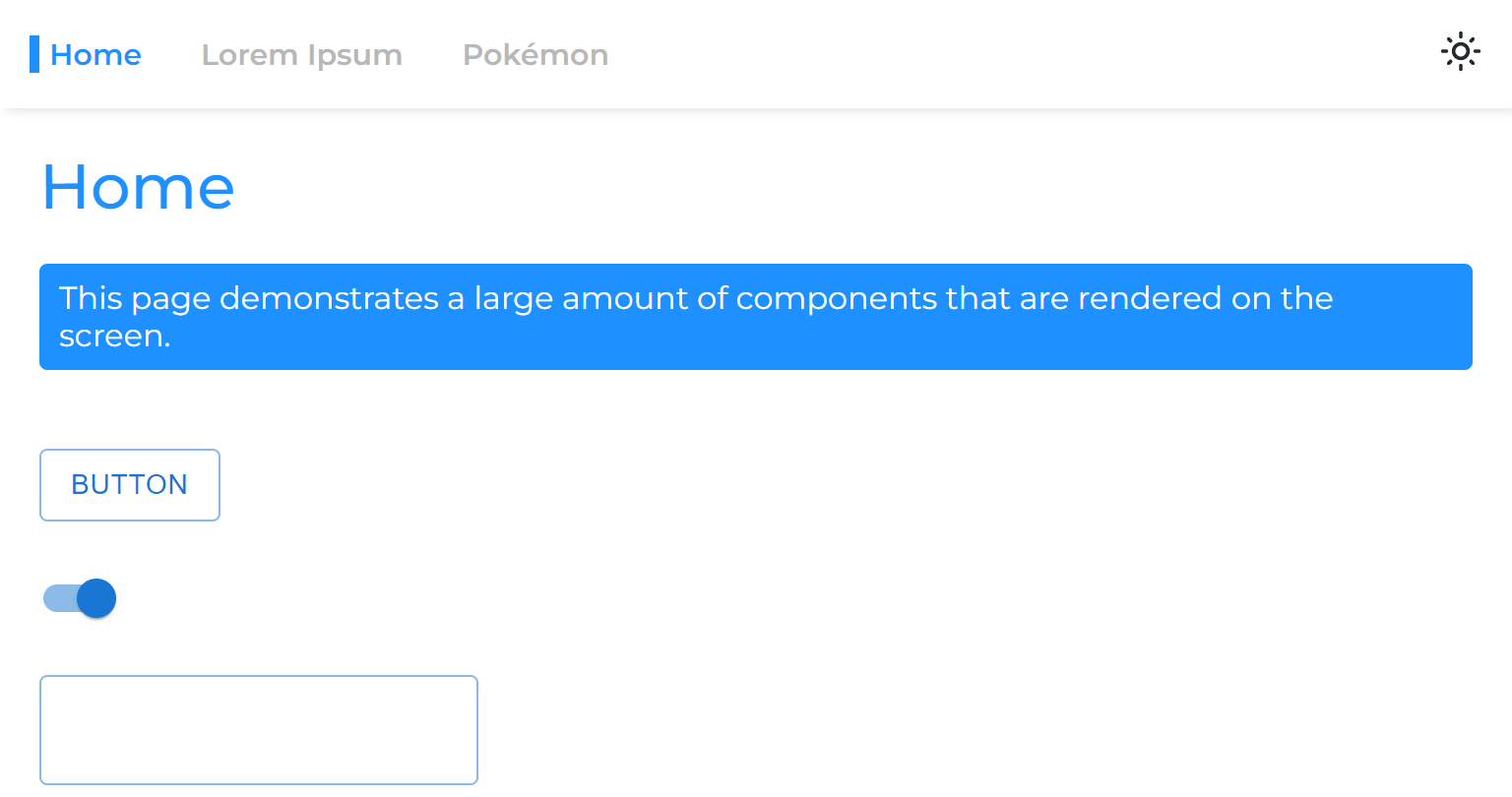
这是由于仅包裹悬念路线的共同方法而发生的:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18向我们介绍了useTransition挂钩,这使我们能够延迟渲染,直到满足某些标准为止。
我们将使用此钩子延迟页面导航,直到准备就绪:
UsetransitionNavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLink现在,异步页面会感觉它们从未与主要应用程序分开。
悬停在链接(桌面)或链接输入视口(移动)时,我们可以预加载其他页面数据:
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >请注意,这可能不必要地加载API服务器。
一些用户将该应用程序持续时间延长,因此我们可以做的另一件事是在运行时重新验证(下载新资产):
服务工作人员registration.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}上面的代码每小时将应用程序重新验证。
重新验证过程非常便宜,因为它仅涉及补充服务工作者(如果不更改,它将返回304未修改的状态代码)。
当服务工作者发生变化时,这意味着可用新资产,因此将选择性下载和缓存。
我们将捆绑包分成许多小部分,从而大大提高了应用程序的缓存能力。
我们将每个页面分开,以便在加载一个页面后,只会立即下载相关的内容。
我们已经设法使应用程序的初始(无缓存)载荷非常快,并且页面需要加载所需的所有内容都将动态注入它。
我们甚至预加载了该页面的数据,消除了CSR应用程序所拥有的著名数据获取瀑布。
此外,我们凝固了所有页面,这使得它们似乎从未与主捆绑代码分开。
所有这些都是在不妥协开发人员体验的情况下实现的,也没有决定选择哪种JS框架。
静态应用程序的最大优势是它可以完全来自CDN。
CDN具有许多流行音乐(存在点),也称为“边缘网络”。这些POP在全球范围内分布,因此能够比远程服务器更快地将文件提供给每个区域。
迄今为止最快的CDN是Cloudflare,它具有250多个流行音乐(和计数):
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-edge-network-performance
我们可以使用CloudFlare页面轻松部署我们的应用:
https://pages.cloudflare.com
总而言之,与Next.js的文档网站相比,我们将执行应用程序的基准,该文档完全是SSG 。
我们将将简约可访问性页面与我们的lorem ipsum页面进行比较。这两个页面都包含〜246KB的JS,其渲染至关重要的块(此后出现的预加载和预摘要是无关紧要的)。
您可以单击每个链接以执行实时基准测试。
可访问性| next.js
lorem ipsum |客户端渲染
我对每页约20次进行了Google的PagesPeed Insights Benchmark(模拟慢4G网络),并选择了最高分数。
这些是结果:
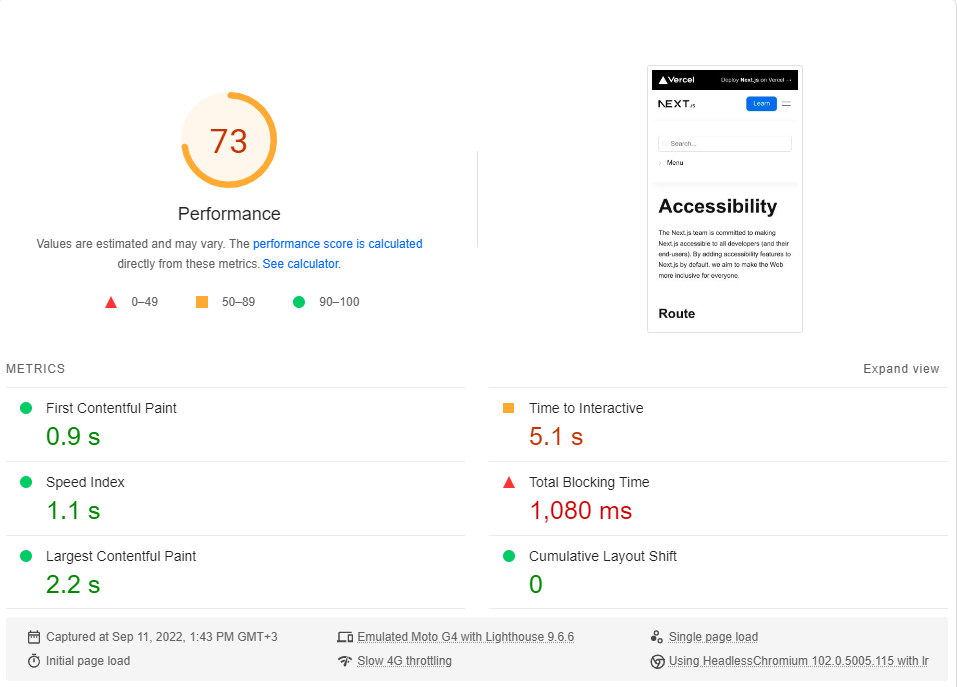
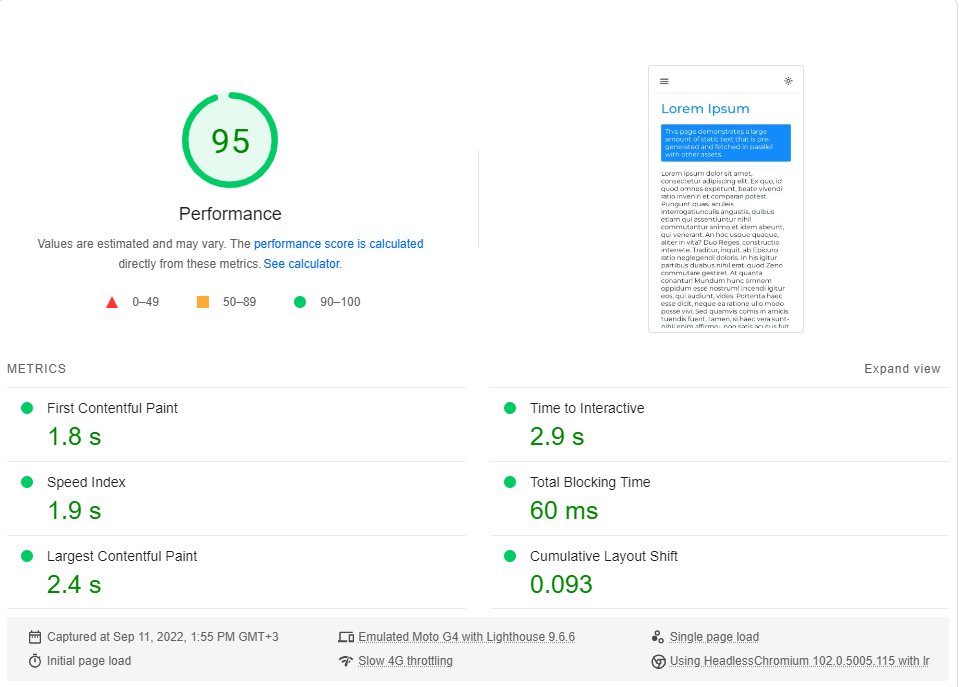
事实证明,性能不是下一步的默认值。
请注意,该基准仅测试页面的第一个负载,甚至没有考虑应用程序完全缓存时的性能(CSR真正发光)。
很常见的是,Google在正确地索引CSR(JS)应用程序时遇到困难。
在2017年可能是这种情况,但截至今天:Google索引CSR应用程序大多是完美的。
索引页面将具有标题,描述,内容和所有其他与SEO相关的属性,只要我们记得动态设置它们(要么手动像这样或使用诸如react-helmet之类的软件包)。
https://www.google.com/search?q = site:https://client-side-rendering.pages.dev
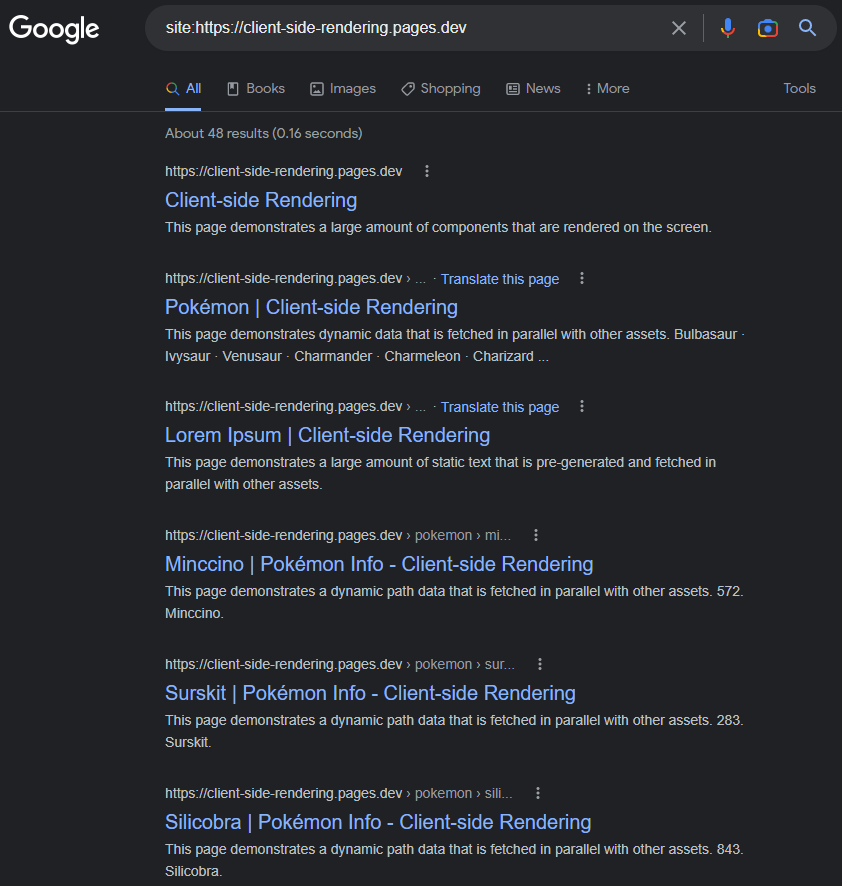
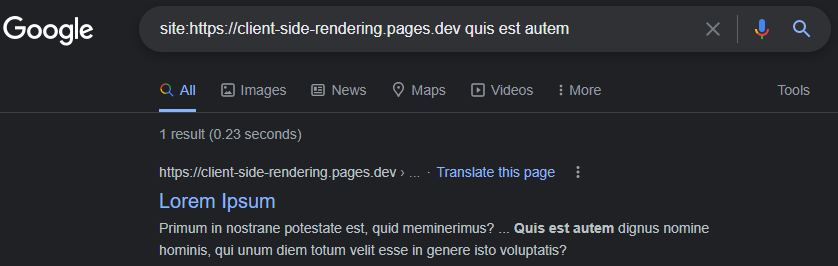
Googlebot的能力可以通过在Google搜索控制台中对我们的应用进行实时URL测试来轻松证明JS:
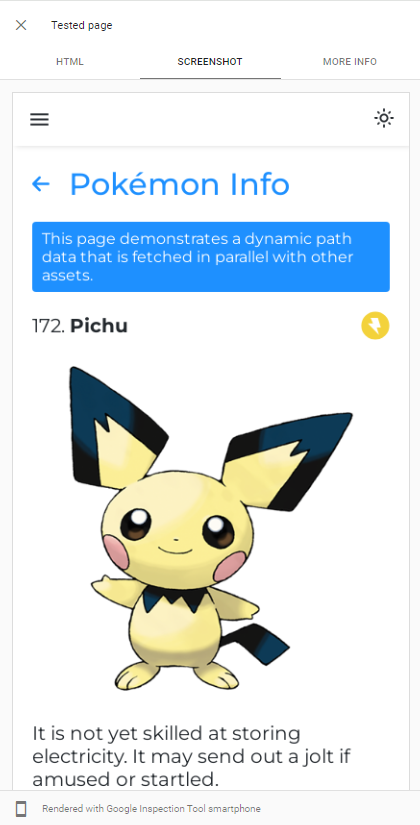
GoogleBot使用最新版本的Chromium来爬网应用,因此我们唯一要做的就是确保我们的应用程序加载快速,并且很快获取数据。
即使数据需要很长时间才能获取,在大多数情况下,GoogleBot也会等待它,然后再进行页面快照:
https://support.google.com/webmasters/thread/202552760/for-how-long-does-googlebot-wait-for-for-the-last-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl = en&sgid = 165510733
可以在此处找到对Googlebot的JS爬行过程的详细说明:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
如果Googlebot未能渲染一些页面,这主要是由于Google不愿花费所需的资源来爬网网站,这意味着它的爬网预算较低。
可以通过检查爬行页面(通过单击搜索控制台中的查看crawled页面)来确认这一点,并确保所有失败的请求都具有其他错误警报(这意味着这些请求已被Googlebot故意中止):
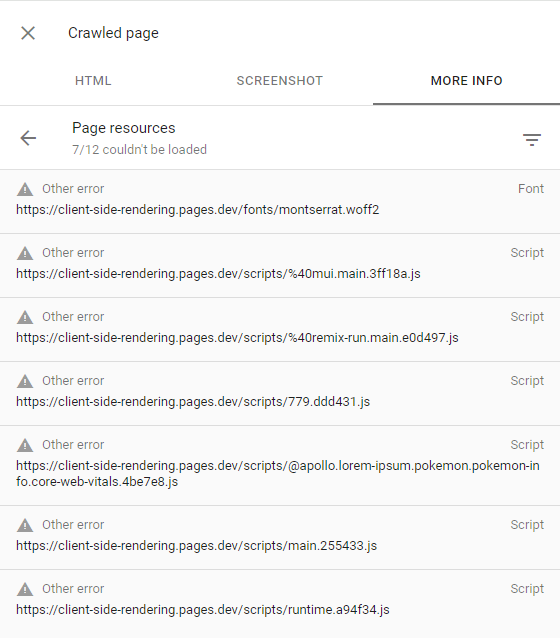
这只能发生在Google认为没有有趣的内容或流量很低的网站上(例如我们的演示应用程序)。
更多信息可以在此处找到:https://support.google.com/webmasters/thread/4425254?hl = en&mmsgid=44266601
其他搜索引擎(例如Bing)无法渲染JS,因此,为了使它们正确爬网,我们需要为它们提供页面的Prerender版本。
预处理是在生产中爬行Web应用程序(使用无头铬)并为每个页面生成完整的HTML文件(带有数据)的行为。
在预先启动方面,我们有两个选择:
无服务器预处理是推荐的方法,因为它可能非常便宜,尤其是在GCP上。
然后,我们使用CloudFlare Worker(例如)将Web爬网(由User-Agent标头字符串识别)(例如):
public/_worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
}这是所有bot agnets(Web Crawlers)的最新列表:https://docs.prerender.io/docs/how-to-to-xadd-add-additional-bots#cloudflare。请记住将googlebot从列表中排除。
Microsoft鼓励Prerendering (也称为动态渲染) ,并受到包括Twitter在内的许多流行网站的大量使用。
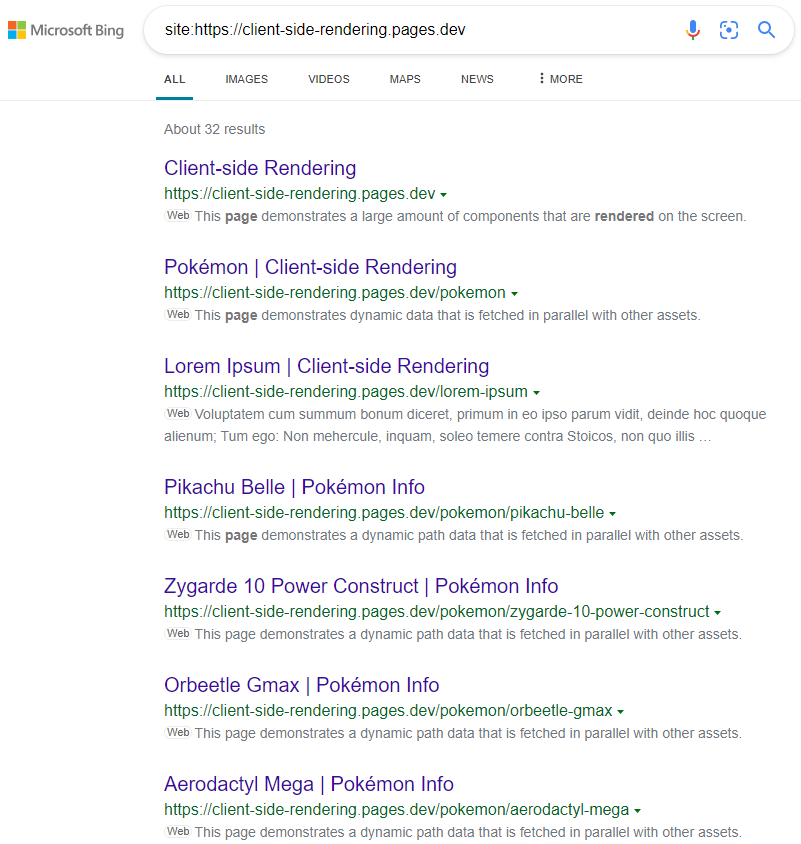
结果是预期的:
https://www.bing.com/search?q = site%3AHTTPS%3A%2F%2F%2fclient-side-Rendering.pages.dev
请注意,使用CSS-IN-JS时,如果要省略DOM的样式,我们可以在预先登录过程中禁用快速优化。
当我们在社交媒体中共享CSR应用程序链接时,我们可以看到,无论我们链接到哪个页面,预览都将保持不变。
之所以发生这种情况,是因为大多数CSR应用程序只有一个无完整的HTML文件,而社交媒体爬网也不会呈现JS。
这是预先援助的地方再次提供给我们的援助,它将为每个页面生成适当的股票预览:
WhatsApp:
Facebook :
为了使我们的所有应用程序页面都可以发现到搜索引擎,建议创建一个sitemap.xml文件,该文件指定我们所有的网站路线。
由于我们已经有一个集中式页面。
create-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )这将发出以下站点地图:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >我们可以手动向Google搜索控制台和Bing网站管理员工具手动提交站点地图。
如上所述,可以在此处找到所有渲染方法的深入比较:https://client-side-rendering.pages.dev/comparison
我们已经看到了静态文件的优势:它们是可缓存的,并且可以从附近的CDN提供,而无需服务器。
这可能会使我们相信SSG结合了CSR和SSR的好处:它使我们的应用在视觉上加载非常快( FCP ),并且独立于API服务器的响应时间。
但是,实际上,SSG有一个主要限制:
由于JS在最初的时刻没有活跃,因此依赖JS的所有内容根本看不到或将不正确显示(例如依赖window.matchMedia的组件。
可以在以下网站上看到此问题的一个经典示例:
https://death-to-ie11.com
请注意,计时器如何立即看到?那是因为它是由JS生成的,它需要时间下载和执行。
当使用某些过滤器刷新Vercel的“指南”页面时,我们还会看到类似的问题:
https://vercel.com/guides?topics= analytics
发生这种情况是因为有65536 (2^16)可能的过滤器组合,并且将每个组合作为单独的HTML文件存储将需要大量的服务器存储。
因此,他们生成一个包含所有数据的单个guides.html 。
重要的是要注意,即使使用静态静态再生,在访问尚未被缓存的页面时(就像在SSR中一样),用户仍然必须等待服务器响应。
此问题的另一个例子是JS动画 - 它们最初可能会出现静态,并且只有在加载JS后才开始动画。
在许多情况下,这种延迟功能会损害用户体验,例如,当网站加载JS后仅显示导航栏时(因为它们依靠本地存储来检查是否存在用户信息输入)。
另一个关键问题,尤其是对于电子商务网站,SSG页面可能显示过时的数据(例如产品的价格或可用性)。
这正是为什么没有主要的电子商务网站使用SSG的原因。
事实是,在快速的Internet连接下,CSR和SSR都表现出色(只要两者都已优化),并且连接速度越高 - 在加载时间方面,它们越接近。
但是,在处理缓慢的连接(例如移动网络)时,SSR似乎在加载时间方面比CSR具有优势。
由于SSR应用程序在服务器上呈现,因此浏览器会接收完整的HTML文件,因此它可以向用户显示页面而无需等待JS下载。当JS最终下载和解析时,该框架能够用功能“补充” DOM(不必重建它)。
尽管这似乎是一个很大的优势,但这种行为引入了不希望的副作用,尤其是在较慢的连接上:
在加载JS之前,用户可以在任何需要的地方单击,但是该应用不会对其基于JS的任何事件做出反应。
当按钮不响应用户交互时,这是一种糟糕的用户体验,但是当没有阻止默认事件时,这将成为一个更大的问题。
这是Next.js的网站与我们的客户端渲染应用程序的比较:快速3G连接:
这里发生了什么?
由于尚未加载JS,因此Next.js的网站无法阻止锚标记元素( <a> )导航到另一页,从而导致每次点击触发完整页面重新加载。
连接越慢 - 这个问题就越严重。
换句话说,SSR应该比CSR具有性能优势,我们看到一种非常“危险”的行为可能会大大降低用户体验。
由于它们渲染的那一刻,因此这个问题不可能发生在CSR应用程序中-JS已经被满载。
我们看到,就初始加载时间而言,客户端的渲染性能在标准杆上,有时甚至比SSR更好(在导航时间中超过了它)。
我们还看到Googlebot可以完美地索引客户端渲染的应用程序,并且我们可以轻松地设置Prerender Server来服务所有其他机器人和爬网。
最重要的是,我们仅通过添加一些文件并使用Prerender服务来实现这一切,因此每个现有的CSR应用程序都应该能够快速轻松地实施这些更改并从中受益。
这些事实得出的结论是,没有令人信服的理由使用SSR。这样做只会为我们的应用程序增加不必要的复杂性和局限性,从而降低开发人员和用户体验,同时还会产生更高的服务器成本。
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


