client side rendering
1.0.0
โครงการนี้เป็นกรณีศึกษาของ CSR มันสำรวจศักยภาพของแอพที่แสดงผลฝั่งไคลเอ็นต์เมื่อเทียบกับการเรนเดอร์ฝั่งเซิร์ฟเวอร์
การเปรียบเทียบเชิงลึกของวิธีการเรนเดอร์ทั้งหมดสามารถพบได้ในหน้า เปรียบเทียบ ของโครงการนี้: https://client-side-rendering.pages.dev/comparison
การเรนเดอร์ฝั่งไคลเอ็นต์ (CSR) หมายถึงการส่งสินทรัพย์คงที่ไปยังเว็บเบราว์เซอร์และอนุญาตให้จัดการกระบวนการเรนเดอร์ทั้งหมดของแอพ
การเรนเดอร์ฝั่งเซิร์ฟเวอร์ (SSR) เกี่ยวข้องกับการเรนเดอร์แอพทั้งหมด (หรือหน้า) บนเซิร์ฟเวอร์และส่งเอกสาร HTML ที่แสดงผลล่วงหน้าพร้อมสำหรับการแสดงผล
การสร้างไซต์แบบสแตติก (SSG) เป็นกระบวนการของหน้า HTML ที่สร้างล่วงหน้าเป็นสินทรัพย์คงที่ซึ่งจะถูกส่งและแสดงโดยเบราว์เซอร์
ตรงกันข้ามกับความเชื่อทั่วไปกระบวนการ SSR ในกรอบการทำงานที่ทันสมัยเช่น React , Angular , Vue และ Svelte ส่งผลให้แอพแสดงผลสองครั้ง: ครั้งเดียวบนเซิร์ฟเวอร์และอีกครั้งบนเบราว์เซอร์ (ซึ่งเรียกว่า "ไฮเดรชั่น") หากไม่มีการเรนเดอร์ครั้งที่สองนี้แอพจะคงที่และไม่โต้ตอบเป็นหลักพฤติกรรมเหมือนเว็บเพจ "ไร้ชีวิต"
ที่น่าสนใจคือกระบวนการให้ความชุ่มชื้นไม่ได้เร็วกว่าการเรนเดอร์ทั่วไป (ไม่รวมขั้นตอนการวาดภาพแน่นอน)
สิ่งสำคัญคือต้องทราบว่าแอพ SSG ต้องได้รับความชุ่มชื้นเช่นกัน
ในทั้ง SSR และ SSG เอกสาร HTML ถูกสร้างขึ้นอย่างเต็มที่โดยให้ประโยชน์ดังต่อไปนี้:
ในทางกลับกันแอพ CSR เสนอข้อดีต่อไปนี้:
ในกรณีศึกษานี้เราจะมุ่งเน้นไปที่ CSR และสำรวจวิธีที่จะเอาชนะข้อ จำกัด ที่ชัดเจนในขณะที่ใช้ประโยชน์จากจุดแข็งไปยังจุดสูงสุด
การเพิ่มประสิทธิภาพทั้งหมดจะรวมอยู่ในแอพที่ปรับใช้ซึ่งสามารถพบได้ที่นี่: https://client-side-rendering.pages.dev
"เมื่อเร็ว ๆ นี้ SSR (การเรนเดอร์ด้านเซิร์ฟเวอร์) ได้นำโลกส่วนหน้า JavaScript โดยพายุความจริงที่ว่าตอนนี้คุณสามารถแสดงเว็บไซต์และแอพของคุณบนเซิร์ฟเวอร์ก่อนที่จะส่งพวกเขาไปยังลูกค้าของคุณเป็นแนวคิด ที่ปฏิวัติวงการ อย่างแน่นอน
อย่างไรก็ตามการวิพากษ์วิจารณ์แบบเดียวกับที่ใช้ได้สำหรับไซต์ PHP, ASP, JSP, (และเช่นนั้น) นั้นถูกต้องสำหรับการเรนเดอร์ฝั่งเซิร์ฟเวอร์ในวันนี้ มันช้าแตกค่อนข้างง่ายและยากที่จะใช้อย่างถูกต้อง
สิ่งที่เป็นแม้ว่าทุกคนจะบอกคุณคุณอาจไม่ต้องการ SSR คุณสามารถได้รับข้อดีเกือบทั้งหมดของมัน (โดยไม่มีข้อเสีย) โดยใช้ prerendering "
~ ปลั๊กอินสปาก่อน
ในช่วงไม่กี่ปีที่ผ่านมาการเรนเดอร์ฝั่งเซิร์ฟเวอร์ได้รับความนิยมอย่างมีนัยสำคัญในรูปแบบของกรอบงานเช่น next.js และ รีมิกซ์ จนถึงจุดที่นักพัฒนามักจะเริ่มต้นใช้งานโดยไม่เข้าใจข้อ จำกัด ของพวกเขาอย่างเต็มที่แม้ในแอพที่ไม่ต้องการ SEO (เช่นผู้ที่มีข้อกำหนดการเข้าสู่ระบบ)
ในขณะที่ SSR มีข้อได้เปรียบเฟรมเวิร์กเหล่านี้ยังคงเน้นความเร็วของพวกเขา ("ประสิทธิภาพเป็นค่าเริ่มต้น") แนะนำว่าการเรนเดอร์ฝั่งไคลเอ็นต์ (CSR) ช้าโดยเนื้อแท้
นอกจากนี้ยังมีความเข้าใจผิดอย่างกว้างขวางว่า SEO ที่สมบูรณ์แบบสามารถทำได้ด้วย SSR เท่านั้นและแอพ CSR ไม่สามารถปรับให้เหมาะสมสำหรับซอฟต์แวร์รวบรวมข้อมูลของเครื่องมือค้นหา
ข้อโต้แย้งทั่วไปอีกประการหนึ่งสำหรับ SSR คือเมื่อเว็บแอปขยายตัวใหญ่ขึ้นเวลาในการโหลดของพวกเขาจะเพิ่มขึ้นอย่างต่อเนื่องซึ่งนำไปสู่ประสิทธิภาพ FCP ที่ไม่ดีสำหรับแอพ CSR
ในขณะที่มันเป็นความจริงที่แอพมีความอุดมสมบูรณ์มากขึ้นขนาดของหน้าเดียวควร ลดลง เมื่อเวลาผ่านไป
นี่เป็นเพราะแนวโน้มของการสร้างห้องสมุดและเฟรมเวิร์กรุ่นเล็ก ๆ ที่มีประสิทธิภาพมากขึ้นเช่น Zustand , Day.js , Headless-Ui และ React-Router V6
นอกจากนี้เรายังสามารถสังเกตการลดขนาดของเฟรมเวิร์กเมื่อเวลาผ่านไป: Angular (74.1KB), React (44.5KB), Vue (34KB), ของแข็ง (7.6KB) และ SVELTE (1.7KB)
ห้องสมุดเหล่านี้มีส่วนสำคัญต่อน้ำหนักโดยรวมของสคริปต์ของหน้าเว็บ
ด้วยการแยกรหัสที่เหมาะสมเวลาในการโหลดเริ่มต้นของหน้าอาจ ลดลง เมื่อเวลาผ่านไป
โครงการนี้ใช้แอพ CSR พื้นฐานพร้อมการปรับให้เหมาะสมเช่นการแยกรหัสและการโหลดล่วงหน้า เป้าหมายคือเวลาในการโหลดของแต่ละหน้าเพื่อให้มีเสถียรภาพเมื่อแอพพลิเคชั่น
วัตถุประสงค์คือเพื่อจำลองโครงสร้างแพ็คเกจของแอพเกรดการผลิตและลดเวลาการโหลดผ่านคำขอแบบขนาน
เป็นสิ่งสำคัญที่จะต้องทราบว่าการปรับปรุงประสิทธิภาพไม่ควรมาจากค่าใช้จ่ายของประสบการณ์นักพัฒนา ดังนั้นสถาปัตยกรรมของโครงการนี้จะได้รับการแก้ไขเพียงเล็กน้อยจากการตั้งค่าปฏิกิริยาโดยทั่วไปหลีกเลี่ยงโครงสร้างที่เข้มงวดและมีความคิดเห็นของเฟรมเวิร์กเช่น next.js หรือข้อ จำกัด ของ SSR โดยทั่วไป
กรณีศึกษานี้จะมุ่งเน้นไปที่สองประเด็นหลัก: ประสิทธิภาพและ SEO เราจะสำรวจวิธีการบรรลุคะแนนสูงสุดในทั้งสองพื้นที่
โปรดทราบว่าแม้ว่าโครงการนี้จะถูกนำไปใช้โดยใช้ React แต่การเพิ่มประสิทธิภาพส่วนใหญ่เป็นเฟรมเวิร์กที่ไม่เชื่อเรื่องพระเจ้าและขึ้นอยู่กับ Bundler และเว็บเบราว์เซอร์อย่างหมดจด
เราจะสมมติว่าการตั้งค่า WebPack (RSPACK) มาตรฐานและเพิ่มการปรับแต่งที่จำเป็นเมื่อเราดำเนินการ
กฎข้อแรกของหัวแม่มือคือการลดการพึ่งพาและในบรรดาสิ่งเหล่านั้นเลือกรุ่นที่มีขนาดไฟล์ที่เล็กที่สุด
ตัวอย่างเช่น:
เราสามารถใช้ day.js แทน ช่วงเวลา Zustand แทนที่จะเป็น Redux Toolkit ฯลฯ
นี่เป็นสิ่งสำคัญไม่เพียง แต่สำหรับแอพ CSR เท่านั้น แต่ยังรวมถึงแอพ SSR (และ SSG) เนื่องจากการรวมกลุ่มที่ใหญ่กว่าส่งผลให้เวลาโหลดนานขึ้นล่าช้าเมื่อหน้าปรากฏหรือโต้ตอบ
ตามหลักการแล้วทุกไฟล์แฮชควรแคชและ index.html ไม่ ควรแคช
หมายความว่าเบราว์เซอร์ในขั้นต้นจะแคช main.[hash].js และจะต้อง redownload มันก็ต่อเมื่อแฮช (เนื้อหา) เปลี่ยนแปลง:

อย่างไรก็ตามเนื่องจาก main.js รวมถึงชุดทั้งหมดการเปลี่ยนแปลงเล็กน้อยในรหัสจะทำให้แคชหมดอายุซึ่งหมายความว่าเบราว์เซอร์จะต้องดาวน์โหลดอีกครั้ง
ตอนนี้ส่วนใดของชุดของเราประกอบด้วยน้ำหนักส่วนใหญ่? คำตอบคือ การอ้างอิง หรือที่เรียกว่า ผู้ขาย
ดังนั้นหากเราสามารถแยกผู้ขายออกเป็นก้อนแฮชของพวกเขาเองนั่นจะช่วยให้สามารถแยกระหว่างรหัสของเราและรหัสผู้ขายซึ่งนำไปสู่การทำให้แคชนั้นไม่ถูกต้อง
มาเพิ่ม การเพิ่มประสิทธิภาพ ต่อไปนี้ในไฟล์กำหนดค่าของเรา:
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
} สิ่งนี้จะสร้าง vendors.[hash].js :

แม้ว่านี่จะเป็นการปรับปรุงที่สำคัญ แต่จะเกิดอะไรขึ้นถ้าเราอัปเดตการพึ่งพาน้อยมาก?
ในกรณีเช่นนี้แคชของผู้ขายทั้งหมดจะเป็นโมฆะ
ดังนั้นเพื่อปรับปรุงให้ดียิ่งขึ้นเราจะแยก การพึ่งพาแต่ละครั้ง ให้เป็นก้อนแฮชของตัวเอง:
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ } สิ่งนี้จะสร้างไฟล์เช่น react-dom.[hash].js ซึ่งมีผู้ขายรายใหญ่รายเดียวและไฟล์ [id].[hash].js ซึ่งมีผู้ขาย (เล็ก) ที่เหลือทั้งหมด:
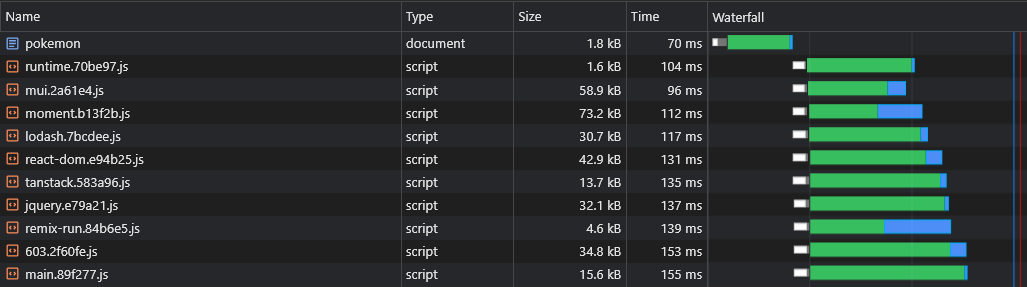
ข้อมูลเพิ่มเติมเกี่ยวกับการกำหนดค่าเริ่มต้น (เช่นขนาดเกณฑ์แยก) สามารถพบได้ที่นี่:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
คุณสมบัติมากมายที่เราเขียนจบลงด้วยการใช้งานในหน้าเว็บของเราเพียงไม่กี่หน้าเท่านั้นดังนั้นเราจึงต้องการให้พวกเขาโหลดเฉพาะเมื่อผู้ใช้เข้าชมหน้าเว็บที่พวกเขากำลังใช้อยู่
ตัวอย่างเช่นเราไม่ต้องการให้ผู้ใช้ต้องรอจนกว่าแพ็คเกจ React-Big-Calendar จะถูกดาวน์โหลดแยกวิเคราะห์และดำเนินการหากพวกเขาเพียงแค่โหลด โฮมเพจ เราต้องการให้สิ่งนั้นเกิดขึ้นเมื่อพวกเขาเยี่ยมชมหน้า ปฏิทิน
วิธีที่เราสามารถทำได้คือ (โดยเฉพาะ) โดยการแยกรหัสตามเส้นทาง:
app.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) ) ดังนั้นเมื่อผู้ใช้เยี่ยมชมหน้า โปเกมอน พวกเขาจะดาวน์โหลดสคริปต์ก้อนหลักเท่านั้น (ซึ่งรวมถึงการพึ่งพาที่ใช้ร่วมกันทั้งหมดเช่นเฟรมเวิร์ก) และโปเก pokemon.[hash].js
หมายเหตุ: ควรดาวน์โหลดแอพทั้งหมดเพื่อให้ผู้ใช้จะได้สัมผัสกับการนำทางเหมือนแอพพลิเคชั่นทันที แต่มันเป็นความคิดที่ไม่ดีที่จะแบทช์สินทรัพย์ทั้งหมดเป็นสคริปต์เดียวล่าช้าการเรนเดอร์แรกของหน้า
สินทรัพย์เหล่านี้ควรดาวน์โหลดแบบอะซิงโครนัสและหลังจากที่หน้าผู้ใช้ต้องการการเรนเดอร์เสร็จสิ้นและมองเห็นได้ทั้งหมด
การแยกรหัสมีข้อบกพร่องที่สำคัญอย่างหนึ่ง - รันไทม์ไม่ทราบว่าจำเป็นต้องใช้ชิ้น Async ใดจนกว่าสคริปต์หลักจะดำเนินการซึ่งนำไปสู่การถูกดึงออกมาในความล่าช้าอย่างมีนัยสำคัญ (เนื่องจากพวกเขาทำการเดินทางกลับไปยัง CDN อีกครั้ง):

วิธีที่เราสามารถแก้ปัญหานี้ได้คือการเขียนปลั๊กอินที่กำหนดเองที่จะฝังสคริปต์ในเอกสารซึ่งจะรับผิดชอบในการโหลดสินทรัพย์ที่เกี่ยวข้องล่วงหน้า:
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}สคริปต์/ฉีดยา-เครื่องแต่งกาย-plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginสคริปต์/preload-assets.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( ) ไฟล์ pages.js นำเข้าสามารถพบได้ที่นี่
ด้วยวิธีนี้เบราว์เซอร์สามารถดึงสคริปต์เฉพาะหน้า คู่ขนาน กับสินทรัพย์ที่สำคัญในการแสดงผล:
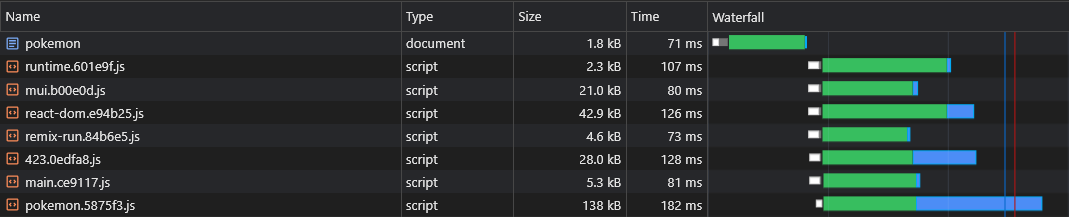
การแยกรหัสแนะนำปัญหาอื่น: การทำซ้ำผู้ขาย ASYNC
สมมติว่าเรามีสองชิ้น async: lorem-ipsum.[hash].js และ pokemon.[hash].js หากทั้งคู่มีการพึ่งพาการพึ่งพาเดียวกันซึ่งไม่ได้เป็นส่วนหนึ่งของก้อนหลักนั่นหมายความว่าผู้ใช้จะดาวน์โหลดการพึ่งพานั้น สองครั้ง
ดังนั้นหากการพึ่งพานั้นเป็น moment และมีน้ำหนัก 72KB minzipped ขนาดของ Async CHUNK ทั้งคู่จะเป็น อย่างน้อย 72KB
เราจำเป็นต้องแยกการพึ่งพานี้ออกจากชิ้น async เหล่านี้เพื่อให้สามารถแบ่งปันระหว่างพวกเขา:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
} ตอนนี้ทั้ง lorem-ipsum.[hash].js และ pokemon.[hash].js จะใช้ moment.[hash].js chunk ช่วยให้ผู้ใช้มีการรับส่งข้อมูลเครือข่ายจำนวนมาก
อย่างไรก็ตามเราไม่มีทางบอกได้ว่ากลุ่มผู้ขาย Async จะถูกแยกออกก่อนที่เราจะสร้างแอปพลิเคชันดังนั้นเราจึงไม่รู้ว่าผู้ขาย Async คนไหนที่เราต้องโหลดไว้ล่วงหน้า
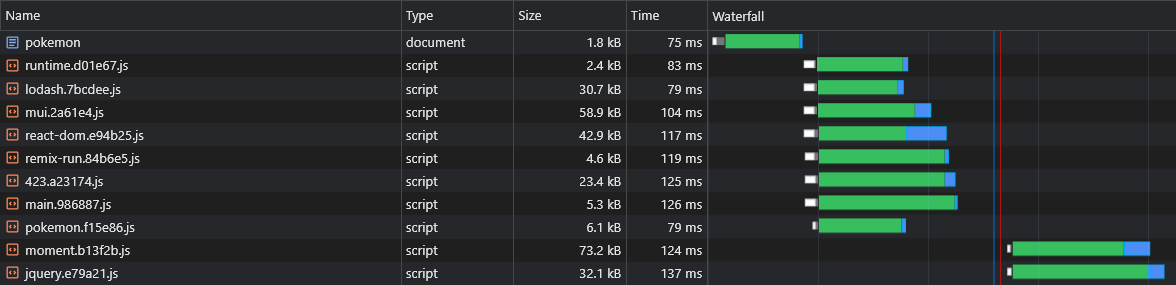
นั่นเป็นเหตุผลที่เราจะผนวกชื่อชิ้นเข้ากับชื่อผู้ขาย async:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}สคริปต์/ฉีดยา-เครื่องแต่งกาย-plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}สคริปต์/preload-assets.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ })ตอนนี้กลุ่มผู้ขาย Async ทั้งหมดจะถูกดึงไปพร้อมกับผู้ปกครอง Async Chunk:
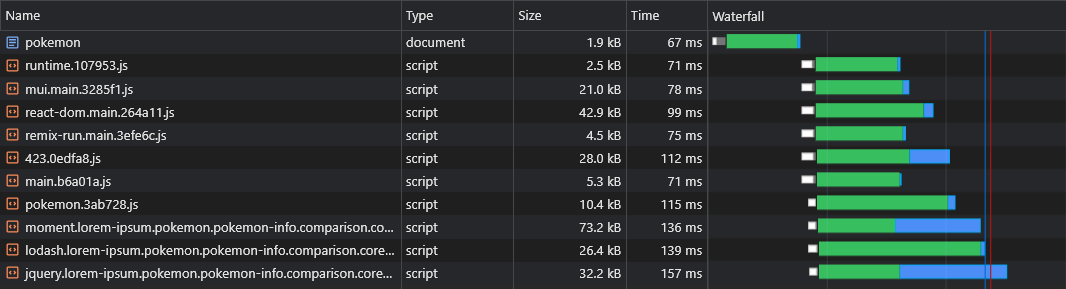
หนึ่งในข้อเสียที่สันนิษฐานของ CSR ผ่าน SSR คือข้อมูลของหน้า (คำขอดึงข้อมูล) จะถูกไล่ออกหลังจากดาวน์โหลด JS แยกวิเคราะห์และดำเนินการในเบราว์เซอร์เท่านั้น:
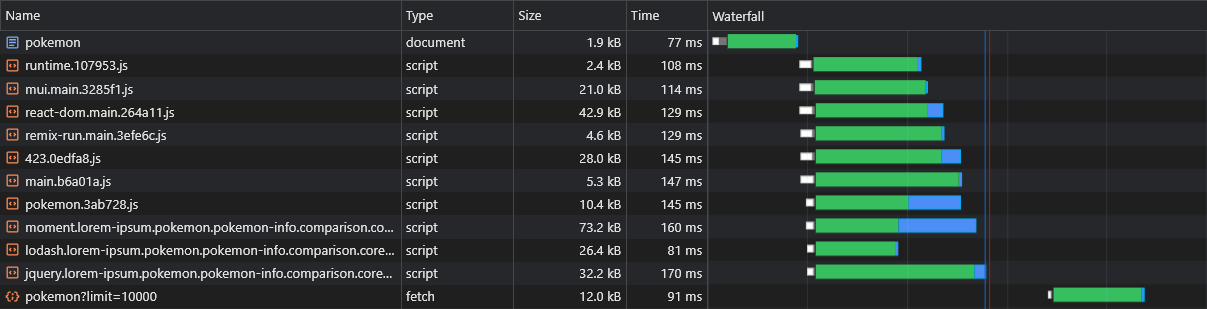
เพื่อเอาชนะสิ่งนี้เราจะใช้การโหลดล่วงหน้าอีกครั้งคราวนี้สำหรับข้อมูลของตัวเองโดยการแก้ไข fetch API:
สคริปต์/ฉีดยา-เครื่องแต่งกาย-plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})สคริปต์/preload-assets.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets() การแจ้งเตือน: ไฟล์ pages.js สามารถพบได้ที่นี่
ตอนนี้เราจะเห็นว่าข้อมูลกำลังถูกดึงออกมาทันที:
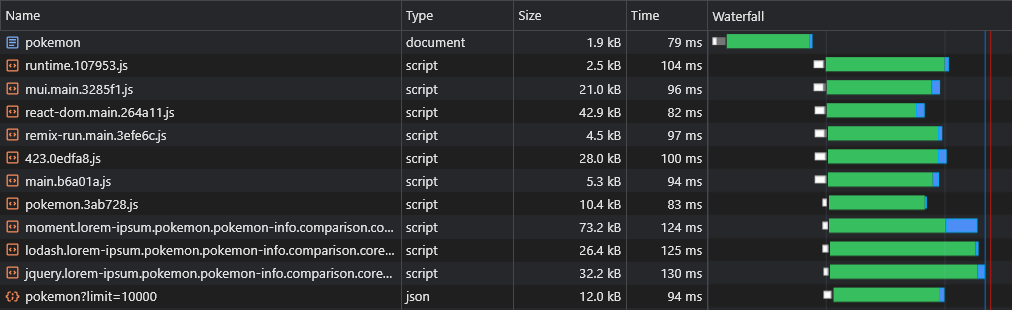
ด้วยสคริปต์ด้านบนเราสามารถโหลดข้อมูลเส้นทางไดนามิกล่วงหน้า (เช่น โปเกมอน/: ชื่อ )
ผู้ใช้ควรมีประสบการณ์การนำทางที่ราบรื่นในแอพของเรา
อย่างไรก็ตามการแยกทุกหน้าทำให้เกิดความล่าช้าอย่างเห็นได้ชัดในการนำทางเนื่องจากทุกหน้าจะต้องดาวน์โหลด (ตามความต้องการ) ก่อนที่จะสามารถแสดงผลบนหน้าจอ
เราต้องการดึงข้อมูลล่วงหน้าและแคชหน้าทั้งหมดล่วงหน้า
เราสามารถทำได้โดยการเขียนพนักงานบริการง่ายๆ:
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}src/utils/service-worker-registration.ts
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}สาธารณะ/service-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )ตอนนี้ทุกหน้าจะถูกดึงออกมาล่วงหน้าและแคชก่อนที่ผู้ใช้จะพยายามนำทางไปยังพวกเขา
วิธีการนี้จะสร้าง แคชรหัส เต็ม
เมื่อตรวจสอบไฟล์ react-dom.js 43KB ของเราเราจะเห็นได้ว่าเวลาที่ใช้ในการร้องขอให้ส่งคืนคือ 60ms ในขณะที่เวลาที่ใช้ในการดาวน์โหลดไฟล์คือ 3ms:

สิ่งนี้แสดงให้เห็นถึงความจริงที่รู้จักกันดีว่า RTT มีผลกระทบอย่างมากต่อเวลาโหลดหน้าเว็บบางครั้งยิ่งกว่าความเร็วในการดาวน์โหลดและแม้กระทั่งเมื่อมีการเสิร์ฟสินทรัพย์จากขอบ CDN ใกล้เคียงเหมือนในกรณีของเรา
นอกจากนี้และที่สำคัญกว่านั้นเราจะเห็นได้ว่าหลังจากดาวน์โหลดไฟล์ HTML แล้วเรามีช่วงเวลาขนาดใหญ่ที่เบราว์เซอร์ยังคงไม่ได้ใช้งานและรอสคริปต์มาถึง:
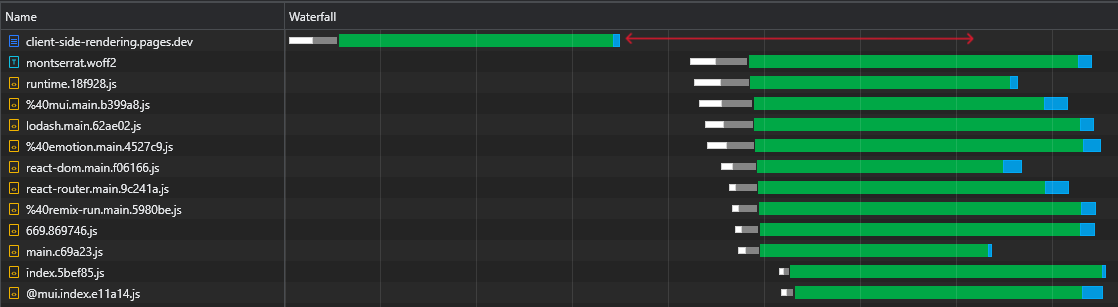
นี่เป็นเวลาที่มีค่ามาก (ทำเครื่องหมายเป็นสีแดง) ที่เบราว์เซอร์สามารถใช้ในการดาวน์โหลดแยกวิเคราะห์และดำเนินการสคริปต์เร่งการมองเห็นและการโต้ตอบของหน้าเว็บ
ความไร้ประสิทธิภาพนี้จะ reoccur ทุกครั้งที่สินทรัพย์เปลี่ยนแปลง (แคชบางส่วน) นี่ไม่ใช่สิ่งที่เกิดขึ้นในการเยี่ยมชมครั้งแรกเท่านั้น
แล้วเราจะกำจัดเวลาว่างนี้ได้อย่างไร?
เราสามารถอินไลน์สคริปต์เริ่มต้น (สำคัญ) ทั้งหมดในเอกสารเพื่อให้พวกเขาเริ่มดาวน์โหลดแยกวิเคราะห์และดำเนินการจนกว่าสินทรัพย์หน้า Async จะมาถึง:

เราจะเห็นได้ว่าตอนนี้เบราว์เซอร์ได้รับสคริปต์เริ่มต้นโดยไม่ต้องส่งคำขออื่นไปยัง CDN
ดังนั้นเบราว์เซอร์จะส่งคำขอสำหรับ Async Chunks และข้อมูลที่โหลดไว้ล่วงหน้าก่อนและในขณะที่อยู่ระหว่างการพิจารณามันจะยังคงดาวน์โหลดและดำเนินการสคริปต์หลักต่อไป
เราจะเห็นได้ว่า Async Chunks เริ่มดาวน์โหลด (ทำเครื่องหมายเป็นสีน้ำเงิน) ทันทีหลังจากไฟล์ HTML เสร็จสิ้นการดาวน์โหลดการแยกวิเคราะห์และการดำเนินการซึ่งช่วยประหยัดเวลาได้มาก
ในขณะที่การเปลี่ยนแปลงนี้สร้างความแตกต่างอย่างมีนัยสำคัญในเครือข่ายที่รวดเร็ว แต่ก็ยิ่งสำคัญยิ่งกว่าสำหรับเครือข่ายที่ช้ากว่าซึ่งความล่าช้ามีขนาดใหญ่ขึ้นและ RTT มีผลกระทบมากขึ้น
อย่างไรก็ตามโซลูชันนี้มี 2 ประเด็นสำคัญ:
เพื่อเอาชนะปัญหาเหล่านี้เราไม่สามารถยึดติดกับไฟล์ HTML แบบคงที่อีกต่อไปและดังนั้นเราจะ leaverage พลังของเซิร์ฟเวอร์ หรืออย่างแม่นยำยิ่งขึ้นพลังของคนงานที่ไม่มีเซิร์ฟเวอร์ CloudFlare
คนงานนี้ควรสกัดกั้นการร้องขอเอกสาร HTML ทุกครั้งและปรับการตอบสนองที่เหมาะกับมันอย่างสมบูรณ์แบบ
การไหลทั้งหมดควรอธิบายดังนี้:
X-Cached ในคำขอ หากส่วนหัวดังกล่าวมีอยู่มันจะวนซ้ำค่าของมันและอินไลน์เฉพาะสินทรัพย์* ที่เกี่ยวข้องที่ขาดหายไปในการตอบสนอง หากส่วนหัวดังกล่าวไม่มีอยู่มันจะอินไลน์สินทรัพย์* ที่เกี่ยวข้องทั้งหมดในการตอบกลับX-Cached ที่ระบุสินทรัพย์ที่แคชทั้งหมด* ทั้งสินทรัพย์เริ่มต้นและหน้าเฉพาะ
สิ่งนี้ทำให้มั่นใจได้ว่าเบราว์เซอร์จะได้รับสินทรัพย์ที่ต้องการ (ไม่มากไม่น้อย) เพื่อแสดงหน้าปัจจุบัน ในรอบเดียว !
สคริปต์/ฉีดยา-เครื่องแต่งกาย-plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginสาธารณะ/_worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src/utils/extract-inline-scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptssrc/utils/service-worker-registration.ts
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}สาธารณะ/service-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )ผลลัพธ์สำหรับโหลดสด (uncached ทั้งหมด) นั้นยอดเยี่ยม:

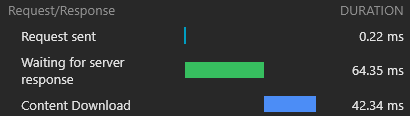

ในการโหลดครั้งต่อไปผู้ปฏิบัติงาน CloudFlare จะตอบสนองด้วยเอกสาร HTML น้อยที่สุด (1.8KB) และสินทรัพย์ทั้งหมดจะถูกเสิร์ฟจากแคชทันที
การเพิ่มประสิทธิภาพนี้นำเราไปสู่อีกอันหนึ่ง - แยกชิ้นส่วนเล็ก ๆ
ตามกฎของหัวแม่มือการแยกมัดออกเป็นชิ้นจำนวนมากเกินไปอาจทำร้ายประสิทธิภาพได้ นี่เป็นเพราะหน้าจะไม่แสดงผลจนกว่าไฟล์ทั้งหมดจะถูกดาวน์โหลดและยิ่งมีชิ้นมากเท่าใดโอกาสที่หนึ่งในนั้นจะล่าช้ามากขึ้น (เช่นฮาร์ดแวร์และความเร็วเครือข่ายไม่ใช่เชิงเส้น)
แต่ในกรณีของเรามันไม่เกี่ยวข้องเนื่องจากเราอินไลน์ชิ้นส่วนที่เกี่ยวข้องทั้งหมดและดังนั้นพวกเขาจึงถูกดึงทั้งหมดในครั้งเดียว
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},การแยกที่รุนแรงนี้จะนำไปสู่การคงอยู่ของแคชที่ดีขึ้นและในทางกลับกันเพื่อเวลาโหลดที่เร็วขึ้นด้วยแคชบางส่วน
เมื่อสินทรัพย์คงที่ถูกนำมาจาก CDN จะมีส่วนหัว ETag ซึ่งเป็นแฮชเนื้อหาของทรัพยากร ในคำขอที่ตามมาเบราว์เซอร์จะตรวจสอบว่ามี ETAG ที่เก็บไว้หรือไม่ ถ้าเป็นเช่นนั้นมันจะส่ง ETAG ในส่วนหัว If-None-Match จากนั้น CDN จะเปรียบเทียบ ETAG ที่ได้รับกับปัจจุบัน: หากตรงกับมันจะส่งคืนสถานะ 304 Not Modified ซึ่งระบุว่าเบราว์เซอร์สามารถใช้สินทรัพย์แคช; ถ้าไม่ส่งคืนสินทรัพย์ใหม่ด้วยสถานะ 200
ในแอพ CSR แบบดั้งเดิมการโหลดหน้าเว็บจะส่งผลให้ HTML ได้รับ 304 Not Modified โดยมีสินทรัพย์อื่น ๆ ที่เสิร์ฟจากแคช แต่ละเส้นทางมี ETAG ที่เป็นเอกลักษณ์ดังนั้น /lorem-ipsum และ /pokemon มีรายการแคชที่แตกต่างกันแม้ว่า etags ของพวกเขาจะเหมือนกัน
ใน CSR SPA เนื่องจากมีไฟล์ HTML เพียงไฟล์เดียวจึงใช้ ETAG เดียวกันสำหรับการร้องขอทุกหน้า อย่างไรก็ตามเนื่องจาก ETAG ถูกเก็บไว้ต่อเส้นทางเบราว์เซอร์จะไม่ส่งส่วนหัว If-None-Match สำหรับหน้าเว็บที่ไม่ได้เข้าชมซึ่งนำไปสู่สถานะ 200 และการโหลด redownload ของ HTML แม้ว่าจะเป็นไฟล์เดียวกัน
อย่างไรก็ตามเราสามารถสร้างการใช้งานของเราเองได้อย่างง่ายดาย (ปรับปรุง) ของพฤติกรรมนี้ผ่านการทำงานร่วมกันระหว่างคนงาน:
สคริปต์/ฉีดยา-เครื่องแต่งกาย-plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}สาธารณะ/_worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}สาธารณะ/service-worker.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} โปรดทราบว่ารวมถึง X-ETag ที่กำหนดเองสำหรับสถานการณ์ที่ CDN ไม่ได้ส่ง ETag โดยอัตโนมัติ
ตอนนี้ผู้ปฏิบัติงานที่ไม่มีเซิร์ฟเวอร์ของเราจะตอบกลับด้วยรหัสสถานะ 304 Not Modified เมื่อใดก็ตามที่ไม่มีการเปลี่ยนแปลงแม้กระทั่งสำหรับหน้าเว็บที่ไม่ได้เข้าชม
เมื่อมีการใช้งานพนักงานบริการเบราว์เซอร์จะล่าช้าในการส่งคำขอเอกสาร HTML เริ่มต้นจนกว่าจะมีการโหลดพนักงานบริการซึ่งอาจทำให้เกิดการหน่วงเวลาเล็กน้อยถึงปานกลางขึ้นอยู่กับฮาร์ดแวร์
การแก้ปัญหาดั้งเดิมของปัญหานี้เรียกว่า การนำทางล่วงหน้า เราจะนำไปใช้สิ่งนี้เพื่อให้แน่ใจว่าคำขอเอกสารจะถูกส่งทันทีโดยไม่ต้องรอให้พนักงานบริการโหลด:
src/utils/service-worker-registration.ts
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}สาธารณะ/service-worker.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )ด้วยการใช้งานนี้คำขอเอกสารจะถูกส่งทันทีโดยไม่ขึ้นกับพนักงานบริการ
หมายเหตุ: ต้องมีปฏิกิริยา (v18), svelte หรือ solid.js
เมื่อเราแยกหน้าออกจากแอพหลักเราจะแยกเฟสเรนเดอร์ออกซึ่งหมายความว่าแอพจะแสดงผลก่อนที่หน้าจะแสดงผล
ดังนั้นเมื่อเราย้ายจากหน้าหนึ่งไปยังอีกหน้าหนึ่งเราจะเห็นพื้นที่ว่างที่ยังคงอยู่จนกว่าหน้าจะแสดงผล:
สิ่งนี้เกิดขึ้นเนื่องจากวิธีการทั่วไปของการห่อเส้นทางที่มีความสงสัยเท่านั้น:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18 แนะนำให้เรารู้จักกับ Hook useTransition ซึ่งช่วยให้เราสามารถชะลอการแสดงผลจนกว่าจะตรงตามเกณฑ์บางอย่าง
เราจะใช้เบ็ดนี้เพื่อชะลอการนำทางของหน้าจนกว่าจะพร้อม:
usetransitionNavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkตอนนี้หน้า Async จะรู้สึกว่าพวกเขาไม่เคยแยกออกจากแอพหลัก
เราสามารถโหลดข้อมูลหน้าอื่น ๆ ล่วงหน้าได้เมื่อวางเมาส์เหนือลิงก์ (เดสก์ท็อป) หรือเมื่อลิงค์ป้อนวิวพอร์ต (มือถือ):
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >โปรดทราบว่าสิ่งนี้อาจโหลดเซิร์ฟเวอร์ API โดยไม่จำเป็น
ผู้ใช้บางคนปล่อยให้แอปเปิดเป็นระยะเวลานานดังนั้นอีกสิ่งหนึ่งที่เราสามารถทำได้คือการทบทวนอีกครั้ง (ดาวน์โหลดสินทรัพย์ใหม่) แอพในขณะที่กำลังทำงานอยู่:
Service-worker-registration.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}รหัสข้างต้นปรับเทียบแอปใหม่ทุกชั่วโมง
กระบวนการ refalidation มีราคาถูกมากเนื่องจากเกี่ยวข้องกับผู้ปฏิบัติงานบริการ (ซึ่งจะส่งคืนรหัสสถานะ 304 ที่ไม่ได้แก้ไข หากไม่เปลี่ยนแปลง)
เมื่อผู้ปฏิบัติงานบริการ มี การเปลี่ยนแปลงหมายความว่ามีสินทรัพย์ใหม่และดังนั้นพวกเขาจะถูกดาวน์โหลดและแคช
เราแบ่งชุดของเราออกเป็นชิ้นเล็ก ๆ มากมายปรับปรุงความสามารถในการแคชของแอปของเราอย่างมาก
เราแยกทุกหน้าเพื่อให้เมื่อโหลดหนึ่งสิ่งที่เกี่ยวข้องจะถูกดาวน์โหลดทันที
เราจัดการเพื่อให้โหลดเริ่มต้น (ไร้ค่า) ของแอพของเราเร็วมากทุกอย่างที่หน้าต้องโหลดจะถูกฉีดไปแบบไดนามิก
เรายังโหลดข้อมูลของหน้าล่วงหน้าโดยกำจัดน้ำตกข้อมูลที่มีชื่อเสียงซึ่งเป็นที่ทราบกันดีว่าแอพ CSR นั้นมี
นอกจากนี้เราจะนำหน้าทุกหน้าซึ่งทำให้ดูเหมือนว่าพวกเขาไม่เคยแยกออกจากรหัสชุดหลัก
สิ่งเหล่านี้ประสบความสำเร็จโดยไม่กระทบต่อประสบการณ์นักพัฒนาและไม่มีการกำหนดกรอบ JS ให้เลือก
ข้อได้เปรียบที่ใหญ่ที่สุดของแอพคงที่คือสามารถให้บริการได้ทั้งหมดจาก CDN
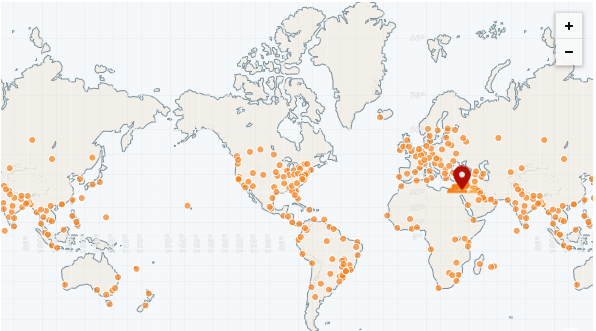
CDN มีป๊อปจำนวนมาก (จุดมีอยู่) หรือที่เรียกว่า "Edge Networks" ป๊อปเหล่านี้มีการกระจายไปทั่วโลกและสามารถให้บริการไฟล์ไปยังทุกภูมิภาค ได้ เร็วกว่าเซิร์ฟเวอร์ระยะไกล
CDN ที่เร็วที่สุดจนถึงปัจจุบันคือ CloudFlare ซึ่งมีมากกว่า 250 ป๊อป (และนับ):
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-edge-network-performance
เราสามารถปรับใช้แอปของเราได้อย่างง่ายดายโดยใช้หน้า CloudFlare:
https://pages.cloudflare.com
เพื่อสรุปส่วนนี้เราจะดำเนินการมาตรฐานของแอพของเราเมื่อเทียบกับเว็บไซต์เอกสารของ next.js ซึ่งเป็น SSG ทั้งหมด
เราจะเปรียบเทียบหน้า การเข้าถึง แบบเรียบง่ายกับหน้า Lorem Ipsum ของเรา ทั้งสองหน้ารวม ~ 246kB ของ JS ในชิ้นส่วนที่สำคัญของพวกเขา (preloads และ prefetches ที่เกิดขึ้นหลังจากนั้นไม่เกี่ยวข้อง)
คุณสามารถคลิกที่แต่ละลิงก์เพื่อดำเนินการเกณฑ์มาตรฐาน
การเข้าถึง next.js
Lorem Ipsum | การเรนเดอร์ฝั่งไคลเอ็นต์
ฉันดำเนินการมาตรฐาน ข้อมูลเชิงลึกของ Google Pagespeed (จำลองเครือข่าย 4G ที่ช้า) ประมาณ 20 ครั้งสำหรับแต่ละหน้าและเลือกคะแนนสูงสุด
นี่คือผลลัพธ์:
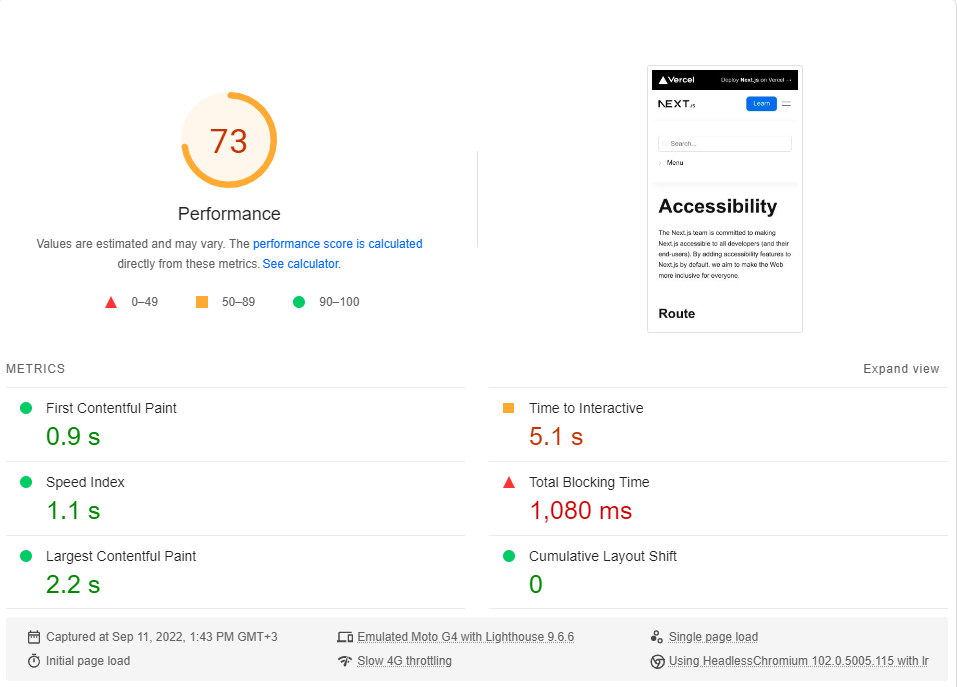
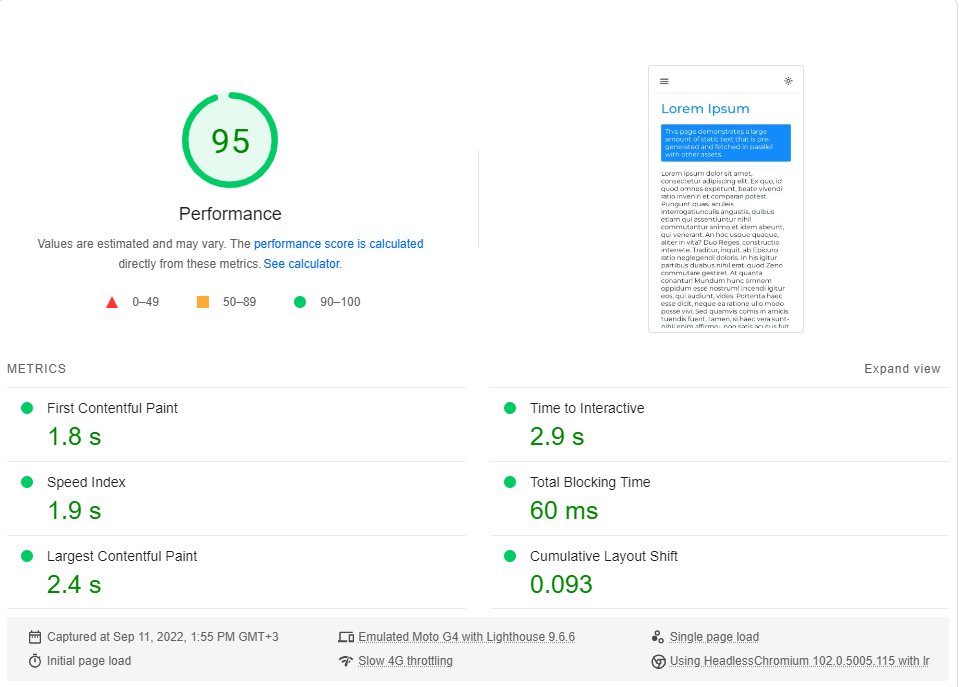
เมื่อปรากฎว่าประสิทธิภาพ ไม่ใช่ ค่าเริ่มต้นใน Next.js
โปรดทราบว่าเกณฑ์มาตรฐานนี้จะทดสอบการโหลดครั้งแรกของหน้าแรกโดยไม่ต้องพิจารณาว่าแอปทำงานอย่างไรเมื่อแคชเต็มรูปแบบ (ที่ CSR ส่องแสงจริง ๆ )
มันเป็น minconception ทั่วไปที่ Google กำลังมีปัญหาในการจัดทำดัชนีแอป CSR (JS) อย่างถูกต้อง
นั่นอาจเป็นกรณีในปี 2560 แต่ ณ วันนี้: Google ดัชนีแอพ CSR ส่วนใหญ่ไม่มีที่ติ
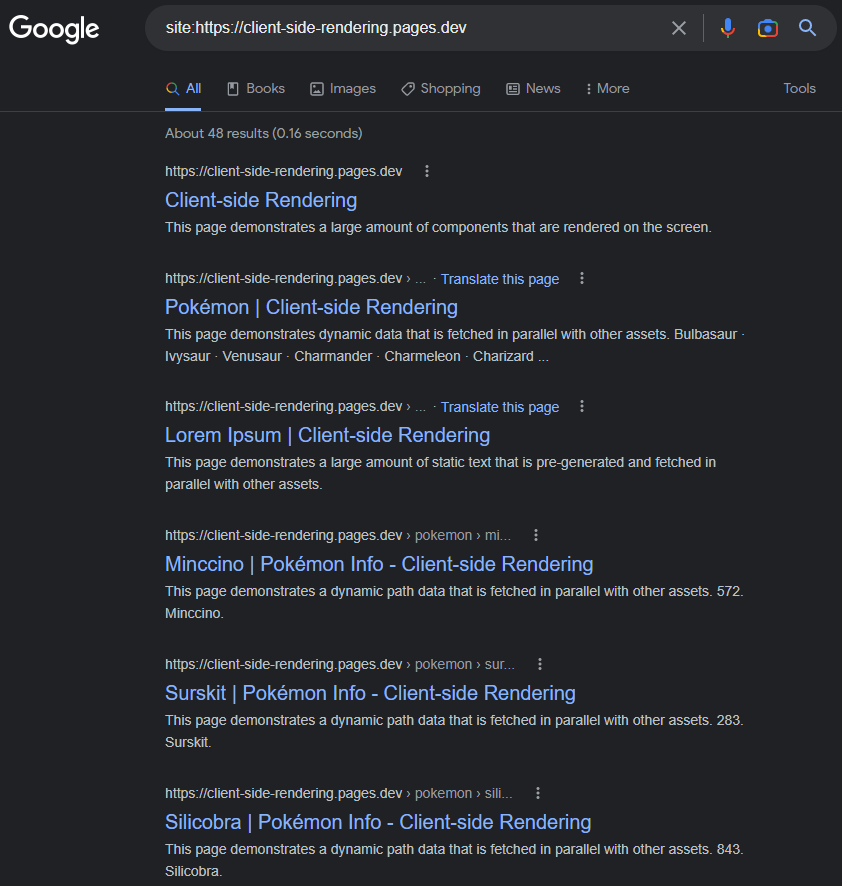
หน้าดัชนีจะมีชื่อคำอธิบายเนื้อหาและแอตทริบิวต์ที่เกี่ยวข้องกับ SEO อื่น ๆ ทั้งหมดตราบใดที่เราจำไว้ว่าจะตั้งค่าแบบไดนามิก (ไม่ว่าจะเป็นแบบนี้หรือใช้แพ็คเกจเช่น React-Helmet )
https://www.google.com/search?q=site:https://client-side-rendering.pages.dev
ความสามารถของ googlebot การแสดงผล JS สามารถแสดงได้อย่างง่ายดายโดยทำการทดสอบ URL สดของแอพของเราใน Google Search Console :
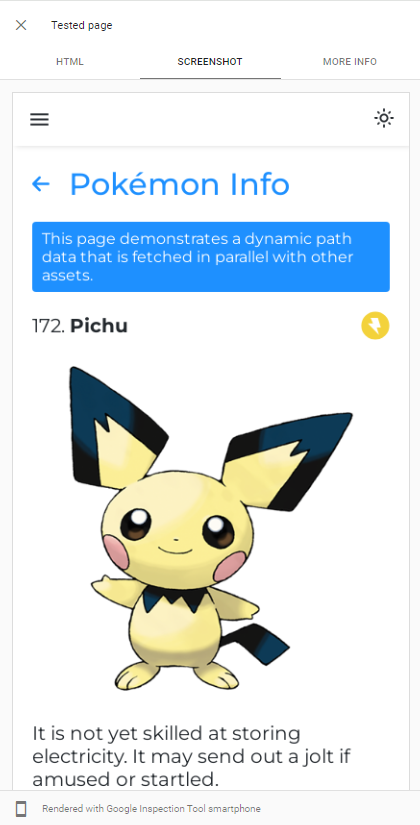
Googlebot ใช้ Chromium เวอร์ชันล่าสุดเพื่อรวบรวมข้อมูลแอพดังนั้นสิ่งเดียวที่เราควรทำคือตรวจสอบให้แน่ใจว่าแอปของเราโหลดได้อย่างรวดเร็วและสามารถดึงข้อมูลได้อย่างรวดเร็ว
แม้ว่าข้อมูลจะใช้เวลานานในการดึงข้อมูล Google Bot ในกรณีส่วนใหญ่จะรอก่อนที่จะถ่ายภาพรวมของหน้า:
https://support.google.com/webmasters/thread/202552760/for-how-long-does-googlebot-wait-for-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
คำอธิบายโดยละเอียดเกี่ยวกับกระบวนการรวบรวมข้อมูล JS ของ Google Bot สามารถพบได้ที่นี่:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
หาก Googlebot ล้มเหลวในการแสดงหน้าบางหน้าส่วนใหญ่เป็นเพราะความไม่เต็มใจของ Google ที่จะใช้ทรัพยากรที่จำเป็นในการรวบรวมข้อมูลเว็บไซต์ซึ่งหมายความว่ามี งบประมาณการรวบรวมข้อมูล ต่ำ
สิ่งนี้สามารถยืนยันได้โดยการตรวจสอบหน้ารวบรวมข้อมูล (โดยคลิก ที่ดูหน้าดูที่รวบรวมไว้ ในคอนโซลการค้นหา) และตรวจสอบให้แน่ใจว่าคำขอที่ล้มเหลวทั้งหมดมีการแจ้งเตือน ข้อผิดพลาดอื่น ๆ (ซึ่งหมายความว่าคำขอเหล่านั้นถูกยกเลิกโดย Google Bot โดยเจตนา):
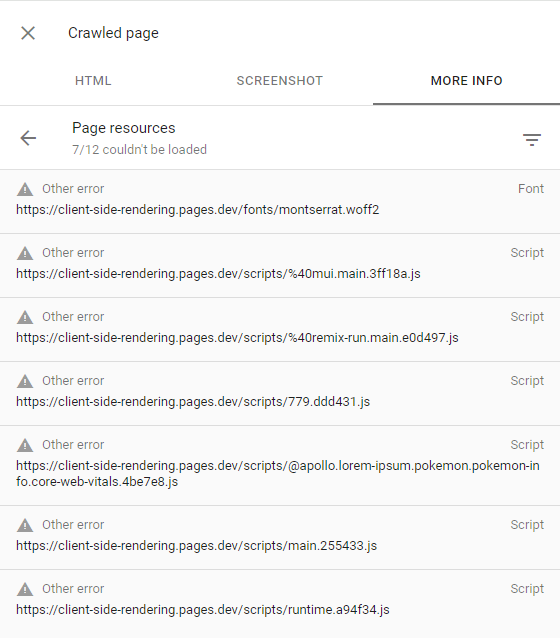
สิ่งนี้ควรเกิดขึ้นกับเว็บไซต์ที่ Google เห็นว่าไม่มีเนื้อหาที่น่าสนใจหรือมีปริมาณการใช้งานต่ำมาก (เช่นแอพสาธิตของเรา)
ข้อมูลเพิ่มเติมสามารถพบได้ที่นี่: https://support.google.com/webmasters/thread/4425254?hl=en&msgid=4426601
เครื่องมือค้นหาอื่น ๆ เช่น Bing ไม่สามารถแสดง JS ได้ดังนั้นเพื่อให้พวกเขารวบรวมข้อมูลแอปของเราอย่างถูกต้องเราต้องให้บริการหน้าเว็บของเรา ก่อน
Prerendering เป็นการกระทำของการรวบรวมข้อมูลเว็บแอพในการผลิต (โดยใช้ Headless Chromium) และสร้างไฟล์ HTML ที่สมบูรณ์ (พร้อมข้อมูล) สำหรับแต่ละหน้า
เรามีสองตัวเลือกเมื่อพูดถึงการทำล่วงหน้า:
การทำล่วงหน้าแบบไม่มีเซิร์ฟเวอร์เป็นวิธีที่แนะนำ เนื่องจากอาจมีราคาถูกมากโดยเฉพาะใน GCP
จากนั้นเราเปลี่ยนเส้นทางโปรแกรมรวบรวมข้อมูลเว็บ (ระบุโดยสตริงส่วนหัวของ User-Agent ) ไปยัง Perenderer ของเราโดยใช้ CloudFlare Worker (ตัวอย่างเช่น):
สาธารณะ/_worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
} นี่คือรายการที่ทันสมัยของ Bot Agnets ทั้งหมด (โปรแกรมรวบรวมข้อมูลเว็บ): https://docs.prerender.io/docs/how-to-add-additional-bots#cloudflare อย่าลืมยกเว้น googlebot จากรายการ
Prerendering หรือที่เรียกว่า การเรนเดอร์แบบไดนามิก ได้รับการสนับสนุนจาก Microsoft และมีการใช้งานอย่างหนักจากเว็บไซต์ยอดนิยมมากมายรวมถึง Twitter
ผลลัพธ์เป็นไปตามที่คาดไว้:
https://www.bing.com/search?q=Site%3AHTTPS%3A%2F%2FClient-side-rendering.pages.dev
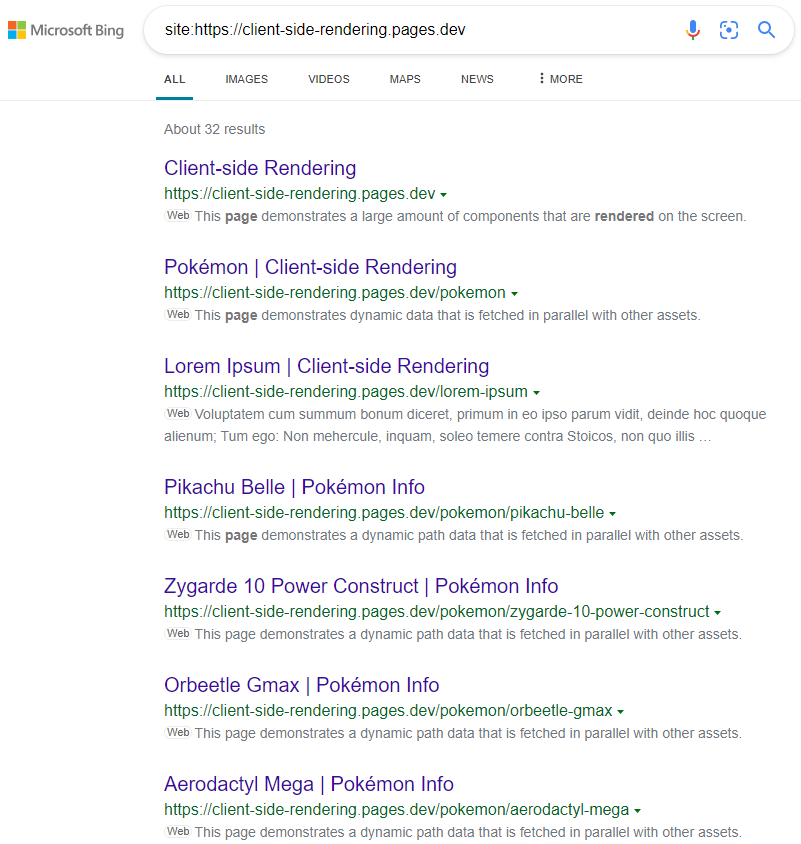
โปรดทราบว่าเมื่อใช้ CSS-in-Js เราสามารถปิดการปรับให้เหมาะสมอย่างรวดเร็วในระหว่างการทำล่วงหน้าหากเราต้องการให้สไตล์ของเราถูกละเว้นไปยัง DOM
เมื่อเราแชร์ลิงก์แอพ CSR ในโซเชียลมีเดียเราจะเห็นว่าไม่ว่าเราจะเชื่อมโยงหน้าใดตัวอย่างจะยังคงเหมือนเดิม
สิ่งนี้เกิดขึ้นเพราะแอพ CSR ส่วนใหญ่มีไฟล์ HTML ที่ไม่มีเนื้อหาเพียงหนึ่งไฟล์และตัวรวบรวมข้อมูลโซเชียลมีเดียไม่แสดง JS
นี่คือที่มาก่อนที่เราจะได้รับความช่วยเหลืออีกครั้งมันจะสร้างตัวอย่างการแชร์ที่เหมาะสมสำหรับแต่ละหน้า:
whatsapp:
Facebook :
เพื่อให้หน้าแอพทั้งหมดของเราค้นพบได้ในเครื่องมือค้นหาขอแนะนำให้สร้างไฟล์ sitemap.xml ซึ่งระบุเส้นทางเว็บไซต์ทั้งหมดของเรา
เนื่องจากเรามีไฟล์ส่วนกลาง js อยู่แล้วเราจึงสามารถสร้างแผนผังไซต์ได้อย่างง่ายดายในช่วงเวลาที่สร้าง:
create-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )สิ่งนี้จะปล่อยแผนผังไซต์ต่อไปนี้:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >เราสามารถส่งแผนผังไซต์ของเราไปยัง Google Search Console และ Bing Webmaster Tools ได้ด้วยตนเอง
ดังที่ได้กล่าวมาแล้วการเปรียบเทียบเชิงลึกของวิธีการเรนเดอร์ทั้งหมดสามารถพบได้ที่นี่: https://client-side-rendering.pages.dev/comparison
เราได้เห็นข้อดีของไฟล์คงที่: พวกเขาสามารถแคชและสามารถเสิร์ฟจาก CDN ใกล้เคียงโดยไม่ต้องใช้เซิร์ฟเวอร์
สิ่งนี้อาจทำให้เราเชื่อว่า SSG รวมประโยชน์ของทั้ง CSR และ SSR: มันทำให้แอพของเราโหลดได้อย่างรวดเร็ว ( FCP ) และเป็นอิสระจากเวลาตอบสนองของเซิร์ฟเวอร์ API ของเรา
อย่างไรก็ตามในความเป็นจริง SSG มีข้อ จำกัด ที่สำคัญ:
เนื่องจาก JS ไม่ได้ใช้งานในช่วงเวลาเริ่มต้นทุกอย่างที่ต้องพึ่งพา JS ที่จะนำเสนอก็จะไม่ปรากฏให้เห็นหรือจะแสดงไม่ถูกต้อง (เช่นส่วนประกอบที่ขึ้นอยู่กับ window.matchMedia ฟังก์ชัน MatchMedia เพื่อแสดงผล)
ตัวอย่างคลาสสิกของปัญหานี้สามารถเห็นได้ในเว็บไซต์ต่อไปนี้:
https://death-to-ie11.com
สังเกตว่าตัวจับเวลาไม่สามารถมองเห็นได้ทันที? นั่นเป็นเพราะ JS สร้างขึ้นซึ่งต้องใช้เวลาในการดาวน์โหลดและดำเนินการ
นอกจากนี้เรายังเห็นปัญหาที่คล้ายกันเมื่อหน้า 'คู่มือ' ของ Vercel สดชื่นพร้อมตัวกรองบางตัวที่ใช้:
https://vercel.com/guides?topics=analytics
สิ่งนี้เกิดขึ้นเนื่องจากมีชุดค่าผสมตัวกรองที่เป็นไปได้ 65536 (2^16) และการจัดเก็บชุดค่าผสมแต่ละชุดเป็นไฟล์ HTML แยกต่างหากจะต้องใช้ที่เก็บเซิร์ฟเวอร์จำนวนมาก
ดังนั้นพวกเขาสร้างไฟล์ guides.html เดียวที่มีข้อมูลทั้งหมด แต่ไฟล์คงที่นี้ไม่ทราบว่าตัวกรองใดถูกนำไปใช้จนกว่าจะโหลด JS ทำให้เกิดการเลื่อนเลย์เอาต์
เป็นสิ่งสำคัญที่จะต้องทราบว่าแม้จะมี การฟื้นฟูแบบคงที่ที่เพิ่มขึ้น ผู้ใช้จะต้องรอการตอบสนองของเซิร์ฟเวอร์เมื่อเยี่ยมชมหน้าเว็บที่ยังไม่ได้ถูกแคช (เช่นเดียวกับใน SSR)
อีกตัวอย่างหนึ่งของปัญหานี้คือแอนิเมชั่น JS - พวกเขาอาจปรากฏตัวในขั้นต้นและเริ่มต้นภาพเคลื่อนไหวเมื่อโหลด JS เท่านั้น
มีหลายกรณีที่ฟังก์ชั่นที่ล่าช้านี้เป็นอันตรายต่อประสบการณ์ของผู้ใช้เช่นเมื่อเว็บไซต์แสดงแถบการนำทางหลังจากโหลด JS (เนื่องจากพวกเขาพึ่งพาที่เก็บข้อมูลในท้องถิ่นเพื่อตรวจสอบว่ามีการป้อนข้อมูลผู้ใช้อยู่) หรือไม่)
อีกประเด็นที่สำคัญโดยเฉพาะอย่างยิ่งสำหรับเว็บไซต์อีคอมเมิร์ซคือหน้า SSG อาจแสดงข้อมูลที่ล้าสมัย (เช่นราคาหรือความพร้อมใช้งานของผลิตภัณฑ์)
นี่คือเหตุผลที่ไม่มีเว็บไซต์อีคอมเมิร์ซที่สำคัญใช้ SSG
มันเป็นความจริงที่ว่าภายใต้การเชื่อมต่ออินเทอร์เน็ตที่รวดเร็วทั้ง CSR และ SSR ทำงานได้ดีมาก (ตราบใดที่พวกเขาได้รับการปรับให้เหมาะสมที่สุด) และความเร็วการเชื่อมต่อที่สูงขึ้น - ยิ่งใกล้เข้ามาในแง่ของเวลาโหลด
อย่างไรก็ตามเมื่อต้องรับมือกับการเชื่อมต่อที่ช้า (เช่นเครือข่ายมือถือ) ดูเหมือนว่า SSR จะมีขอบ CSR เกี่ยวกับเวลาในการโหลด
เนื่องจากแอพ SSR ถูกแสดงผลบนเซิร์ฟเวอร์เบราว์เซอร์จึงได้รับไฟล์ HTML ที่สร้างขึ้นอย่างเต็มรูปแบบและดังนั้นจึงสามารถแสดงหน้าเว็บให้กับผู้ใช้โดยไม่ต้องรอให้ JS ดาวน์โหลด เมื่อ JS ถูกดาวน์โหลดและแยกวิเคราะห์ในที่สุดเฟรมเวิร์กก็สามารถ "ไฮเดรต" DOM ที่มีฟังก์ชั่น (โดยไม่ต้องสร้างใหม่)
แม้ว่ามันจะเป็นข้อได้เปรียบที่ยิ่งใหญ่ แต่พฤติกรรมนี้ก็แนะนำผลข้างเคียงที่ไม่พึงประสงค์โดยเฉพาะอย่างยิ่งในการเชื่อมต่อที่ช้าลง:
จนกว่า JS จะถูกโหลดผู้ใช้สามารถคลิกได้ทุกที่ที่ต้องการ แต่แอพจะไม่ตอบสนองต่อเหตุการณ์ที่ใช้ JS ใด ๆ
มันเป็นประสบการณ์ของผู้ใช้ที่ไม่ดีเมื่อปุ่มไม่ตอบสนองต่อการโต้ตอบของผู้ใช้ แต่มันจะกลายเป็นปัญหาที่ใหญ่กว่ามากเมื่อเหตุการณ์เริ่มต้นไม่ได้รับการป้องกัน
นี่คือการเปรียบเทียบระหว่างเว็บไซต์ของ next.js และแอพการแสดงผลฝั่งลูกค้าของเราในการเชื่อมต่อ 3G ที่รวดเร็ว:
เกิดอะไรขึ้นที่นี่?
เนื่องจาก JS ยังไม่ได้รับการโหลดเว็บไซต์ของ Next.js ไม่สามารถป้องกันพฤติกรรมเริ่มต้นขององค์ประกอบแท็กสมอ ( <a> ) เพื่อนำทางไปยังหน้าอื่นส่งผลให้การคลิกทุกครั้งที่เรียกใช้การโหลดหน้าเต็ม
และยิ่งการเชื่อมต่อช้าลง - ยิ่งปัญหานี้รุนแรงขึ้นเท่านั้น
กล่าวอีกนัยหนึ่งที่ SSR ควรมีประสิทธิภาพเหนือ CSR เราเห็นพฤติกรรม "อันตราย" ที่อาจทำให้ประสบการณ์ผู้ใช้ลดลงอย่างมีนัยสำคัญ
เป็นไปไม่ได้ที่ปัญหานี้จะเกิดขึ้นในแอพ CSR ตั้งแต่ช่วงเวลาที่พวกเขาแสดงผล - JS ได้รับการโหลดอย่างเต็มที่แล้ว
เราเห็นว่าประสิทธิภาพการเรนเดอร์ฝั่งไคลเอ็นต์อยู่ในระดับที่เท่าเทียมกันและบางครั้งก็ดีกว่า SSR ในแง่ของเวลาการโหลดเริ่มต้น (และเกินกว่าในเวลาการนำทาง)
นอกจากนี้เรายังได้เห็นว่า Googlebot สามารถจัดทำดัชนีแอพที่แสดงผลฝั่งไคลเอ็นต์ได้อย่างสมบูรณ์แบบและเราสามารถตั้งค่าเซิร์ฟเวอร์ก่อนหน้านี้เพื่อให้บริการบอทและซอฟต์แวร์รวบรวมข้อมูลอื่น ๆ ได้อย่างง่ายดาย
และที่สำคัญที่สุดคือเราได้รับสิ่งเหล่านี้ทั้งหมดเพียงแค่เพิ่มไฟล์สองสามไฟล์และใช้บริการก่อนหน้านี้ดังนั้นแอพ CSR ที่มีอยู่ทุกแห่งควรจะสามารถใช้การเปลี่ยนแปลงและประโยชน์เหล่านี้ได้อย่างรวดเร็วและง่ายดาย
ข้อเท็จจริงเหล่านี้นำไปสู่ข้อสรุปว่าไม่มีเหตุผลที่น่าสนใจที่จะใช้ SSR Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


