client side rendering
1.0.0
Dieses Projekt ist eine Fallstudie von CSR, die das Potenzial von clientseitigen Apps im Vergleich zum serverseitigen Rendering untersucht.
Ein umfassender Vergleich aller Rendering-Methoden finden Sie auf der Vergleichsseite dieses Projekts: https://client-sside-rendering.pages.dev/Comparison
Das Client-Side-Rendering (CSR) bezieht sich auf das Senden statischer Vermögenswerte an den Webbrowser und das Ermöglichung des gesamten Rendering-Prozesses der App.
Das Server-Side-Rendering (SSR) umfasst das Rendern der gesamten App (oder Seite) auf dem Server und die Bereitstellung eines vorgezogenen HTML-Dokuments zur Anzeige.
Die statische Stättegenerierung (SSG) ist der Prozess der vorgenerierenden HTML-Seiten als statische Vermögenswerte, die dann vom Browser gesendet und angezeigt werden.
Im Gegensatz zur allgemeinen Meinung führt der SSR -Prozess in modernen Frameworks wie React , Angular , Vue und Svelte dazu, dass die App zweimal rendert: einmal auf dem Server und erneut auf dem Browser (dies wird als "Hydratation" bezeichnet). Ohne dieses zweite Rendern wäre die App statisch und unintern und verhält sich im Wesentlichen wie eine "leblose" Webseite.
Interessanterweise scheint der Hydratationsprozess nicht schneller zu sein als ein typischer Renderung (natürlich ohne die Malphase).
Es ist auch wichtig zu beachten, dass SSG -Apps ebenfalls einer Flüssigkeitszufuhr unterzogen werden müssen.
Sowohl in SSR als auch in SSG ist das HTML -Dokument vollständig konstruiert und bietet die folgenden Vorteile:
Auf der anderen Seite bieten CSR -Apps die folgenden Vorteile:
In dieser Fallstudie konzentrieren wir uns auf CSR und untersuchen Wege, um seine offensichtlichen Einschränkungen zu überwinden und gleichzeitig die Stärken auf den Höhepunkt zu nutzen.
Alle Optimierungen werden in die bereitgestellte App aufgenommen, die hier zu finden ist: https://client-sside-rendering.pages.dev.
"Vor kurzem hat SSR (Server Side Rendering) die JavaScript-Front-End-Welt im Sturm erobert. Die Tatsache, dass Sie jetzt Ihre Websites und Apps auf dem Server rendern können, bevor Sie sie an Ihre Kunden senden, ist eine absolut revolutionäre Idee (und völlig nicht das, was jeder tat, bevor JS Client-Side-Apps in erster Linie populär wurden ...).
Die gleichen Kritikpunkte, die für PHP, ASP, JSP, (und solche) Websites gültig waren, gelten jedoch für die heutige Server-Seite. Es ist langsam, bricht ziemlich leicht und ist schwer ordnungsgemäß umzusetzen.
Trotz dessen, was Ihnen jeder sagt, brauchen Sie wahrscheinlich keine SSR. Sie können fast alle Vorteile davon (ohne Nachteile) durch Nutzung von Vorbereitungen erhalten. "
~ Prerender Spa Plugin
In den letzten Jahren hat das serverseitige Rendering in Form von Frameworks wie Next.js und Remix bis zu dem Punkt erhebliche Beliebtheit erlangt, dass Entwickler sie häufig standardmäßig verwenden, ohne ihre Einschränkungen vollständig zu verstehen, selbst in Apps, die keine SEO benötigen (z. B. Personen mit Anmeldungsanforderungen).
Während SSR seine Vorteile hat, betonen diese Frameworks weiterhin ihre Geschwindigkeit ("Leistung als Standard"), was darauf hindeutet, dass das Kunden-Side-Rendering (CSR) von Natur aus langsam ist.
Darüber hinaus gibt es ein weit verbreitetes Missverständnis, dass perfekte SEO nur mit SSR erreicht werden kann und dass CSR -Apps für Suchmaschinencrawler nicht optimiert werden können.
Ein weiteres häufiges Argument für SSR ist, dass die Web -Apps mit größerem Wachstum der Ladezeiten weiter steigen, was zu einer schlechten FCP -Leistung für CSR -Apps führt.
Während es wahr ist, dass Apps zu Funktionen werden, sollte die Größe einer einzelnen Seite im Laufe der Zeit tatsächlich abnehmen .
Dies ist auf den Trend zurückzuführen, kleinere, effizientere Versionen von Bibliotheken und Frameworks wie Zustand , Day.js , Headless-UI und React-Router V6 zu erstellen.
Wir können auch eine Verringerung der Größe der Frameworks im Laufe der Zeit beobachten: Winkel (74,1 KB), React (44,5 KB), VUE (34 KB), Feststoff (7,6 KB) und Sufle (1,7 KB).
Diese Bibliotheken tragen erheblich zum Gesamtgewicht der Skripte einer Webseite bei.
Bei ordnungsgemäßer Codespaltung könnte die anfängliche Ladezeit einer Seite im Laufe der Zeit abnehmen .
Dieses Projekt implementiert eine grundlegende CSR-App mit Optimierungen wie Codespaltung und Vorspannung. Ziel ist es, dass die Ladezeit einzelner Seiten stabil bleibt, wenn die App skaliert.
Ziel ist es, die Paketstruktur einer Produktions-App zu simulieren und die Ladezeiten durch parallelisierte Anforderungen zu minimieren.
Es ist wichtig zu beachten, dass die Verbesserung der Leistung nicht auf Kosten der Entwicklererfahrung erfolgen sollte. Daher wird die Architektur dieses Projekts nur geringfügig aus einem typischen React -Setup modifiziert, wodurch die starre, Meinung von Frameworks wie Next.js oder die Einschränkungen von SSR im Allgemeinen vermieden wird.
Diese Fallstudie konzentriert sich auf zwei Hauptaspekte: Leistung und SEO. Wir werden untersuchen, wie in beiden Bereichen Top -Ergebnisse erzielt werden können.
Beachten Sie, dass dieses Projekt zwar mit React implementiert wird, die meisten Optimierungen jedoch Framework-Agnostic sind und nur auf dem Bundler und dem Webbrowser basieren.
Wir nehmen ein Standard -Webpack (RSPack) -Setup an und fügen die erforderlichen Anpassungen beim Fortschritt hinzu.
Die erste Faustregel lautet, Abhängigkeiten zu minimieren und darunter diejenigen mit den kleinsten Dateigrößen zu wählen.
Zum Beispiel:
Wir können Day.js anstelle des Moments verwenden, Zustand anstelle von Redux -Toolkit usw.
Dies ist nicht nur für CSR -Apps, sondern auch für SSR- (und SSG) -Apps wichtig, da größere Bündel zu längeren Lastzeiten führen und sich verzögern, wenn die Seite sichtbar oder interaktiv wird.
Im Idealfall sollte jede Hashed -Datei zwischengespeichert werden und index.html niemals zwischengespeichert werden.
Dies bedeutet, dass der Browser zunächst main.[hash].js

Da main.js jedoch das gesamte Bundle enthält, würde die geringste Änderung des Codes sein Cache auslaufen, was bedeutet, dass der Browser ihn erneut herunterladen müsste.
Welchen Teil unseres Bündels umfasst nun den größten Teil seines Gewichts? Die Antwort sind die Abhängigkeiten , auch Anbieter genannt.
Wenn wir also die Anbieter in ihren eigenen Hashed -Chunk teilen könnten, würde dies eine Trennung zwischen unserem Code und dem Anbietercode ermöglichen, was zu weniger Cache -Ungültigmachungen führt.
Fügen wir unserer Konfigurationsdatei die folgende Optimierung hinzu:
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
} Dadurch wird ein vendors.[hash].js Datei:

Obwohl dies eine erhebliche Verbesserung ist, was würde passieren, wenn wir eine sehr kleine Abhängigkeit aktualisieren würden?
In diesem Fall wird der gesamte Cache des Anbieters Chunk ungültig.
Um es noch weiter zu verbessern, werden wir jede Abhängigkeit in ihren eigenen Hashed -Stück teilen:
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ } Dadurch werden Dateien wie react-dom.[hash].js , die einen einzelnen großen Anbieter und eine [id].[hash].js
Weitere Informationen zu den Standardkonfigurationen (z. B. die Größe der geteilten Schwellenwerte) finden Sie hier:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
Viele der Funktionen, die wir schreiben, werden nur auf wenigen unserer Seiten verwendet. Daher möchten wir, dass sie nur dann geladen werden, wenn der Benutzer die Seite besucht, auf der sie verwendet werden.
Zum Beispiel möchten wir nicht, dass Benutzer warten müssen, bis das React-Big-Calendar- Paket heruntergeladen, analysiert und ausgeführt wird, wenn es lediglich die Startseite geladen hat. Wir möchten nur, dass das geschieht, wenn sie die Kalenderseite besuchen.
Die Art und Weise, wie wir dies erreichen können, ist (vorzugsweise) durch Routen-basierte Codeaufteilung:
App.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) ) Wenn Benutzer die Pokemon -Seite besuchen, laden sie nur die Haupt -Chunk -Skripte (einschließlich aller gemeinsam genutzten Abhängigkeiten wie dem Framework) und des pokemon.[hash].js Chunk.
Hinweis: Es wird aufgefordert, die gesamte App herunterzuladen, damit Benutzer sofortige, appartige Navigationen erleben. Es ist jedoch eine schlechte Idee, alle Assets in ein einzelnes Skript zu stapeln und das erste Rendern der Seite zu verzögern.
Diese Vermögenswerte sollten asynchron heruntergeladen werden und erst nachdem die von der benutzergerichtete Seite beendet wurde und völlig sichtbar ist.
Die Code -Spaltung hat einen großen Fehler - die Laufzeit weiß nicht, welche asynchronen Stücke benötigt werden, bis das Hauptskript ausgeführt wird, was dazu führt, dass sie in einer erheblichen Verzögerung abgerufen werden (da sie einen weiteren Hinweis auf die CDN machen):

Die Art und Weise, wie wir dieses Problem lösen können, besteht darin, ein benutzerdefiniertes Plugin zu schreiben, das ein Skript in das Dokument einbettet, das für die Vorladung relevanter Vermögenswerte verantwortlich ist:
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}Skripte/Inject-Assets-Plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginSkripte/Vorladungen.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( ) Die importierte Seiten von pages.js finden Sie hier.
Auf diese Weise kann der Browser das Seiten-spezifische Skript-Chunk parallel zu renderkritischen Vermögenswerten abrufen:
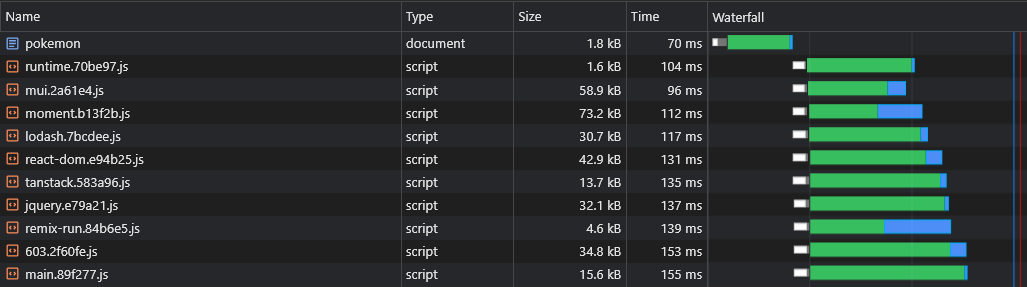
Die Codespaltung führt ein weiteres Problem ein: Async -Anbieter -Duplikation.
Sagen Sie, wir haben zwei asynchrische Stücke: lorem-ipsum.[hash].js und pokemon.[hash].js Wenn beide dieselbe Abhängigkeit enthalten, die nicht Teil des Hauptblocks ist, bedeutet dies, dass der Benutzer diese Abhängigkeit zweimal herunterlädt.
Wenn diese Abhängigkeit also moment ist und sie 72 KB -Minziped wiegt, beträgt die Größe von Async Chunk mindestens 72 KB.
Wir müssen diese Abhängigkeit von diesen asynchronen Stücken teilen, damit sie zwischen ihnen geteilt werden kann:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
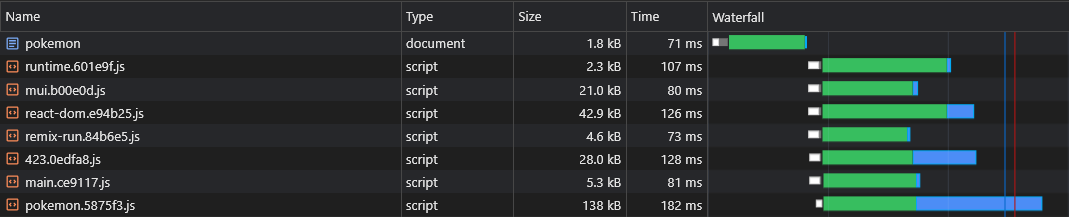
} Jetzt werden beide lorem-ipsum.[hash].js moment.[hash].js pokemon.[hash].js
Wir können jedoch nicht erzählen, welche asynchronen Anbieterbrocken vor dem Erstellen der Anwendung aufgeteilt werden. Wir würden also nicht wissen, welche asynchronen Anbieterbrocken wir vorlasten müssen (siehe Abschnitt "Vorladung asynchronischer Stücke"):
Deshalb werden wir die Namen der Chunks an den Namen des asynchronen Anbieters anhängen:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}Skripte/Inject-Assets-Plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}Skripte/Vorladungen.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
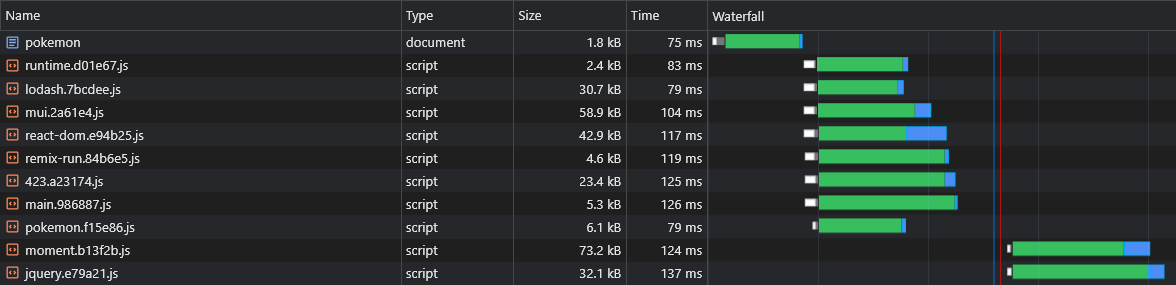
+ })Jetzt werden alle Async -Verkäufer -Stücke parallel zu ihrem übergeordneten Async -Chunk abgerufen:
Einer der vermuteten Nachteile von CSR gegenüber SSR ist, dass die Daten der Seite (Fetch -Anfragen) erst entlassen werden, nachdem JS im Browser heruntergeladen, analysiert und ausgeführt wurde:
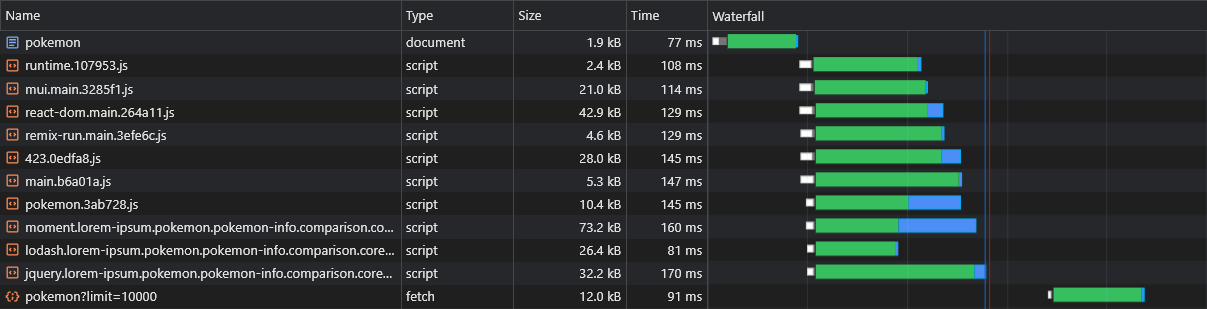
Um dies zu überwinden, werden wir das Prelading erneut, diesmal für die Daten selbst, verwenden, indem wir die fetch -API patchen:
Skripte/Inject-Assets-Plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})Skripte/Vorladungen.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets() Erinnerung: Die Datei pages.js finden Sie hier.
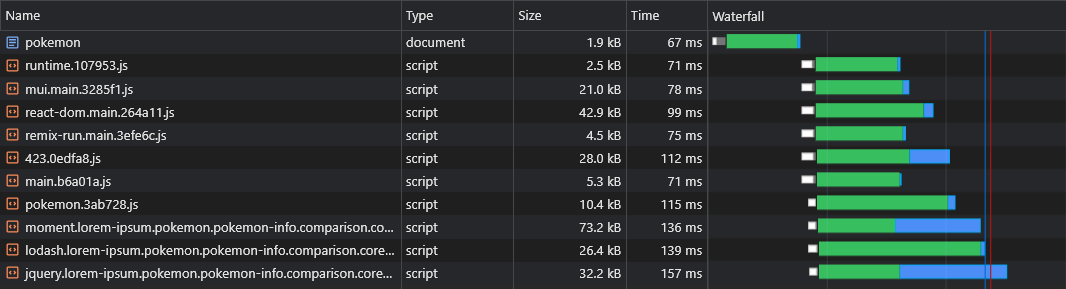
Jetzt können wir sehen, dass die Daten sofort abgerufen werden:
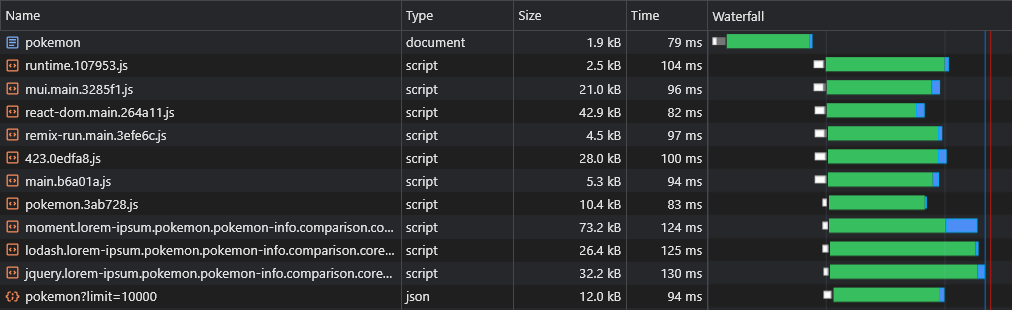
Mit dem obigen Skript können wir sogar dynamische Routendaten (wie Pokemon/: Name ) vorladen.
Benutzer sollten eine reibungslose Navigationserfahrung in unserer App haben.
Durch die Aufteilung jeder Seite führt jedoch zu einer merklichen Verzögerung bei der Navigation, da jede Seite heruntergeladen werden muss (On-Demand), bevor sie auf dem Bildschirm gerendert werden kann.
Wir möchten alle Seiten im Voraus vorab und zwischenstrahlen.
Wir können dies tun, indem wir einen einfachen Servicearbeiter schreiben:
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}SRC/Utils/Service-Arbeiter-Registrierung.TS
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}public/service-personal.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Jetzt werden alle Seiten bereits vor dem Navigieren des Benutzers vorgeholt und zwischengespeichert.
Dieser Ansatz generiert auch einen vollständigen Code -Cache .
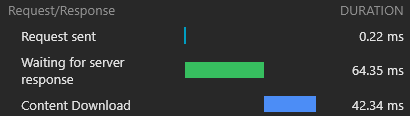
Bei der Inspektion unserer 43-KB react-dom.js -Datei können wir feststellen, dass die Zeit, die die Anfrage zur Rückgabe benötigte, 60 ms betrug, während die Zeit zum Herunterladen der Datei 3 ms betrug:

Dies zeigt die bekannte Tatsache, dass RTT einen enormen Einfluss auf die Ladezeiten der Webseiten hat, manchmal sogar mehr als Download-Geschwindigkeit und selbst wenn Assets von einer nahe gelegenen CDN-Kante wie in unserem Fall serviert werden.
Zusätzlich und vor allem können wir sehen, dass wir nach dem Herunterladen der HTML -Datei eine große Zeitspanne haben, in der der Browser untätig bleibt und nur darauf wartet, dass die Skripte eintreffen:
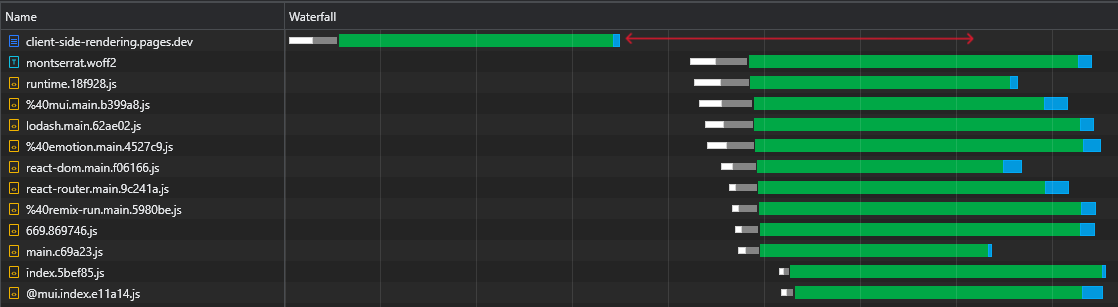
Dies ist eine Menge kostbarer Zeit (in Rot markiert), mit der der Browser Skripte herunterladen, analysiert und sogar ausführt und die Sichtbarkeit und Interaktivität der Seite beschleunigt.
Diese Ineffizienz wird jedes Mal wieder auftreten, wenn sich die Vermögenswerte ändern (teilweise Cache). Dies geschieht nicht nur beim ersten Besuch.
Wie können wir diese Leerlaufzeit beseitigen?
Wir könnten alle anfänglichen (kritischen) Skripte im Dokument einführen, damit sie beginnen, zu herunterladen, zu analysieren und auszuführen, bis die asynchronen Seitenvermögen ankommen:

Wir können sehen, dass der Browser jetzt seine ersten Skripte erhält, ohne eine weitere Anfrage an die CDN senden zu müssen.
Daher sendet der Browser zuerst Anfragen für die asynchronen Stücke und die vorinstallierten Daten, und während diese anhängig sind, wird die Hauptskripte weiter heruntergeladen und ausgeführt.
Wir können sehen, dass die asynchronen Stücke gleich nach dem Abschluss des Herunterladens, Parsens und Ausführens der HTML -Datei (in blau markiert) herunterladen, die viel Zeit spart.
Während diese Änderung einen signifikanten Unterschied in schnellen Netzwerken macht, ist sie für langsamere Netzwerke noch wichtiger, bei denen die Verzögerung größer ist und die RTT viel wirkungsvoller ist.
Diese Lösung hat jedoch 2 Hauptprobleme:
Um diese Probleme zu überwinden, können wir uns nicht mehr an eine statische HTML -Datei halten, und so werden wir die Leistung eines Servers ausbreiten. Oder genauer gesagt die Leistung eines Cloudflare -serverlosen Arbeiters.
Dieser Arbeiter sollte jede HTML -Dokumentanforderung abfangen und eine Antwort anpassen, die perfekt zu ihr passt.
Der gesamte Fluss sollte wie folgt beschrieben werden:
X-Cached -Headers. Wenn ein solcher Header existiert, wird es über seine Werte iteriert und nur die relevanten* Vermögenswerte in der Reaktion in der Lage. Wenn ein solcher Header nicht vorhanden ist, wird alle relevanten* Vermögenswerte in der Antwort eingerichtet.X-Cached -Header, in dem alle zwischengespeicherten Vermögenswerte angegeben sind.* Sowohl anfängliche als auch Seitenspezifische Vermögenswerte.
Dies stellt sicher, dass der Browser genau die Vermögenswerte erhält, die er benötigt (nicht mehr, nicht weniger), um die aktuelle Seite in einem einzigen Roundtrip anzuzeigen!
Skripte/Inject-Assets-Plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpublic/_worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}SRC/Utils/Extract-Inline-Skripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptsSRC/Utils/Service-Arbeiter-Registrierung.TS
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}public/service-personal.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Die Ergebnisse für eine frische (völlig ungekochte) Last sind außergewöhnlich:


Bei der nächsten Last reagiert der Cloudflare -Mitarbeiter mit einem minimalen HTML -Dokument (1,8 KB) und alle Vermögenswerte werden sofort aus dem Cache bedient.
Diese Optimierung führt uns zu einem anderen - Spaltbrocken in noch kleinere Teile.
Als Faustregel kann das Aufteilen des Bündels in zu viele Stücke die Leistung beeinträchtigen. Dies liegt daran, dass die Seite erst dann gerendert wird, wenn alle Dateien heruntergeladen sind und je mehr Brocken es gibt, desto größer ist die Wahrscheinlichkeit, dass sich einer von ihnen verzögert (da Hardware und Netzwerkgeschwindigkeit nicht linear sind).
Aber in unserem Fall ist es irrelevant, da wir alle relevanten Stücke investieren und so auf einmal abgerufen werden.
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},Diese extreme Aufteilung führt zu einer besseren Cache -Persistenz und zu schnelleren Ladezeiten mit teilweise Cache.
Wenn ein statischer Vermögenswert aus einem CDN abgeholt wird, enthält es einen ETag -Header, der ein Inhaltshash der Ressource ist. Bei nachfolgenden Anfragen prüft der Browser, ob er über einen gespeicherten ETAG verfügt. Wenn dies der Fall ist, sendet es den ETAG in einem Header If-None-Match . Das CDN vergleicht dann den empfangenen ETAG mit dem aktuellen: Wenn sie übereinstimmen, gibt es einen 304 Not Modified Status zurück, der angibt, dass der Browser das zwischengespeicherte Vermögenswert verwenden kann. Wenn nicht, gibt es das neue Vermögenswert mit einem 200 -Status zurück.
In einer herkömmlichen CSR -App führt das Nachladen einer Seite dazu, dass die HTML eine 304 Not Modified , wobei andere Vermögenswerte aus dem Cache bedient werden. Jede Route hat einen einzigartigen ETAG, also haben also /lorem-ipsum und /pokemon unterschiedliche Cache-Einträge, auch wenn ihre ETAGs identisch sind.
In einem CSR -Spa wird für jede Seitenanforderung dieselbe ETAG verwendet, da es nur eine HTML -Datei gibt. Da der ETAG pro Route gespeichert ist, sendet der Browser keinen Header für If-None-Match besuchte Seiten für nicht besuchte Seiten, was zu einem 200 Status und einem erneuten Laden der HTML führt, obwohl es sich um dieselbe Datei handelt.
Wir können jedoch durch Zusammenarbeit zwischen den Arbeitnehmern problemlos unsere eigene (verbesserte) Implementierung dieses Verhaltens erstellen:
Skripte/Inject-Assets-Plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}public/_worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}public/service-personal.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} Beachten Sie, dass eine benutzerdefinierte X-ETag für Situationen enthalten ist, in denen das CDN nicht automatisch einen ETag sendet.
Jetzt antwortet unser serverloser Mitarbeiter immer mit einem 304 Not Modified Statuscode, wenn es keine Änderungen gibt, selbst für nicht besuchte Seiten.
Wenn ein Servicearbeiter verwendet wird, verzögert der Browser, der die anfängliche HTML -Dokumentenanforderung sendet, bis der Servicearbeiter geladen ist, was je nach Hardware eine leichte bis mäßige Seitenverzögerung verursachen kann.
Die native Lösung für dieses Problem wird als Navigationsvorspannung bezeichnet. Wir werden dies implementieren, um sicherzustellen, dass die Dokumentenanfrage sofort gesendet wird, ohne darauf zu warten, dass der Servicemitarbeiter geladen wird:
SRC/Utils/Service-Arbeiter-Registrierung.TS
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}public/service-personal.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Mit dieser Implementierung wird die Dokumentenanfrage unabhängig vom Servicemitarbeiter unabhängig gesendet.
HINWEIS: Erfordert React (v18), Svelte oder Solid.js
Wenn wir eine Seite aus der Haupt -App teilen, trennen wir ihre Renderphase, was bedeutet, dass die App vor der Seite rendert.
Wenn wir also von einer asynchronen Seite zur anderen wechseln, sehen wir einen leeren Raum, der verbleibt, bis die Seite gerendert wird:
Dies geschieht aufgrund des gemeinsamen Ansatzes, nur die Routen mit Spannung zu wickeln:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18 führte uns in den useTransition -Hook vor, der es uns ermöglicht, ein Render zu verzögern, bis einige Kriterien erfüllt sind.
Wir werden diesen Haken verwenden, um die Navigation der Seite zu verzögern, bis er fertig ist:
UsetransitionNavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkJetzt werden asynchronisierte Seiten sich nie aus der Haupt -App getrennt.
Wir können andere Seitendaten vorladen, wenn wir über Links (Desktop) schweben oder wenn Links das Ansichtsfenster (Mobile) eingeben:
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >Beachten Sie, dass dies den API -Server unnötig laden kann.
Einige Benutzer lassen die App über einen längeren Zeitraum geöffnet. Eine andere Sache, die wir tun können, ist die App neu (herunterzuladen), während sie ausgeführt wird:
Service-Arbeiter-Registrierung.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}Der obige Code stellt die App jede Stunde neu.
Der Neuaufbauprozess ist äußerst billig, da nur der Servicearbeiter neu ausgerichtet ist (bei der ein 304 nicht geänderter Statuscode zurückgeführt wird, wenn sie nicht geändert werden).
Wenn sich der Servicearbeiter ändert , bedeutet dies, dass neue Vermögenswerte verfügbar sind und somit selektiv heruntergeladen und zwischengespeichert werden.
Wir haben unser Bündel in viele kleine Stücke geteilt und die Caching -Fähigkeiten unserer App erheblich verbessert.
Wir teilen jede Seite so auf, dass beim Laden eines nur das, was relevant ist, sofort heruntergeladen wird.
Wir haben es geschafft, die anfängliche (cachlose) Last unserer App extrem schnell zu machen. Alles, was eine Seite zum Laden benötigt, wird dynamisch injiziert.
Wir laden sogar die Daten der Seite vor und beseitigen die berühmten Daten, die Wasserfall abrufen, von denen CSR -Apps bekannt sind.
Außerdem sehen wir alle Seiten vor, wodurch es so aussieht, als ob sie niemals aus dem Hauptbündelcode geteilt wurden.
All dies wurde erreicht, ohne die Entwicklererfahrung zu beeinträchtigen und ohne zu diktieren, welches JS -Framework zu wählen ist.
Der größte Vorteil einer statischen App besteht darin, dass sie vollständig von einem CDN bedient werden kann.
Ein CDN hat viele Pops (Präsenzpunkte), auch "Edge Networks" genannt. Diese POPs sind rund um den Globus verteilt und können Dateien für jede Region viel schneller bedienen als ein Remote -Server.
Die schnellste CDN bisher ist CloudFlare mit mehr als 250 POPs (und Zählungen):
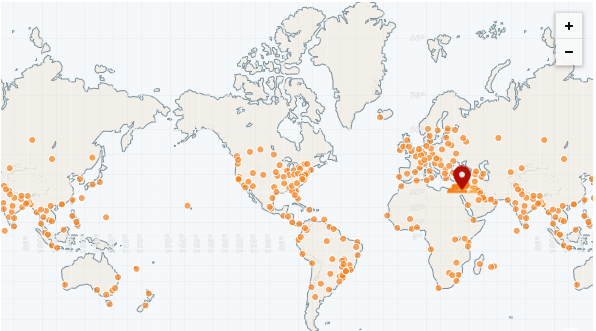
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-eded-network-performance
Wir können unsere App einfach mit Cloudflare -Seiten bereitstellen:
https://pages.cloudflare.com
Um diesen Abschnitt abzuschließen, werden wir im Vergleich zur Dokumentationsstelle von Next .
Wir werden die Seite mit minimalistischer Zugänglichkeit mit unserer LOREM IPSUM -Seite vergleichen. Beide Seiten enthalten ~ 246 KB JS in ihren renderkritischen Stücken (Voranschläge und Vorabschläge, die danach kommen, sind irrelevant).
Sie können auf jeden Link klicken, um einen Live -Benchmark auszuführen.
Barrierefreiheit | Weiter.js
Lorem ipsum | Kundenseitiges Rendering
Ich habe für jede Seite Googles PageSpeed Insights -Benchmark (simuliert ein langsames 4G -Netzwerk) durchgeführt und die höchste Punktzahl ausgewählt.
Dies sind die Ergebnisse:
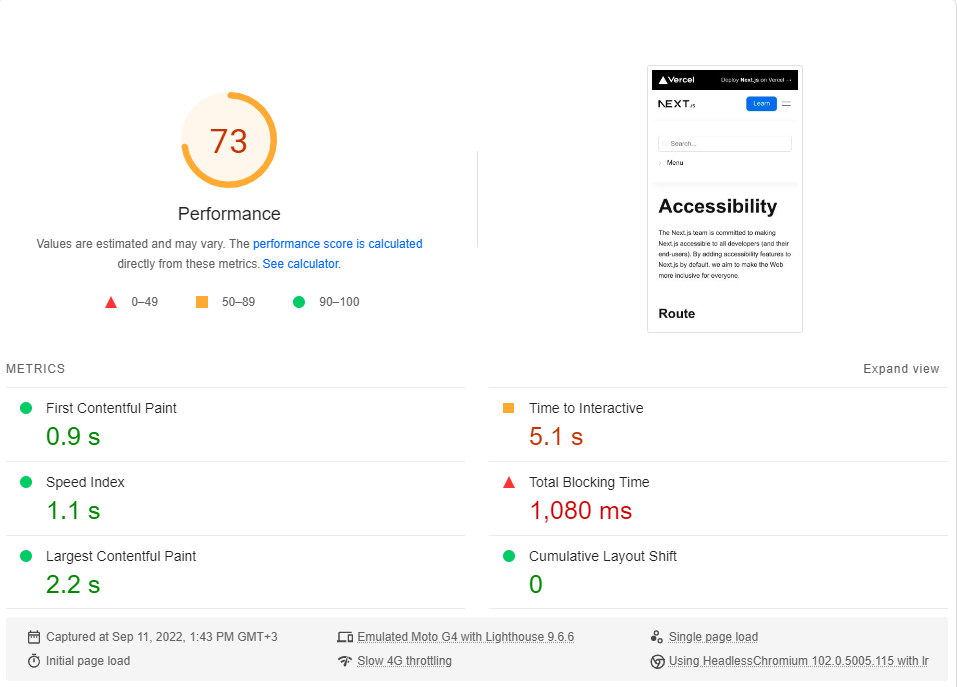
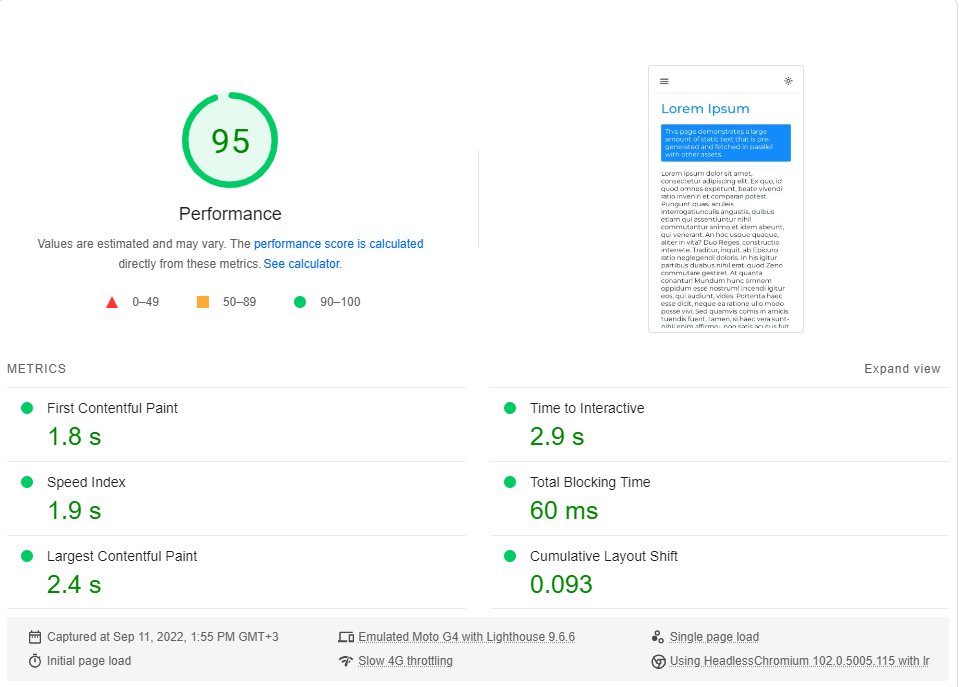
Wie sich herausstellt, ist die Leistung in Next.js.
Beachten Sie, dass dieser Benchmark nur die erste Last der Seite testet, ohne zu überlegen, wie die App funktioniert, wenn sie vollständig zwischengespeichert wird (wo CSR wirklich leuchtet).
Es ist eine häufige Minconception, dass Google Probleme hat, CSR (JS) -Apps (JS) ordnungsgemäß zu indizieren.
Das könnte 2017 der Fall gewesen sein, aber bis heute: Google Indizes CSR -Apps meist einwandfrei.
Indexierte Seiten haben einen Titel, eine Beschreibung, einen Inhalt und alle anderen SEO-bezogenen Attribute, solange wir daran denken, sie dynamisch festzulegen (entweder manuell wie dieses oder ein Paket wie React-Helmet ).
https://www.google.com/search?q=sit:https://client-side-rendering.pages.dev
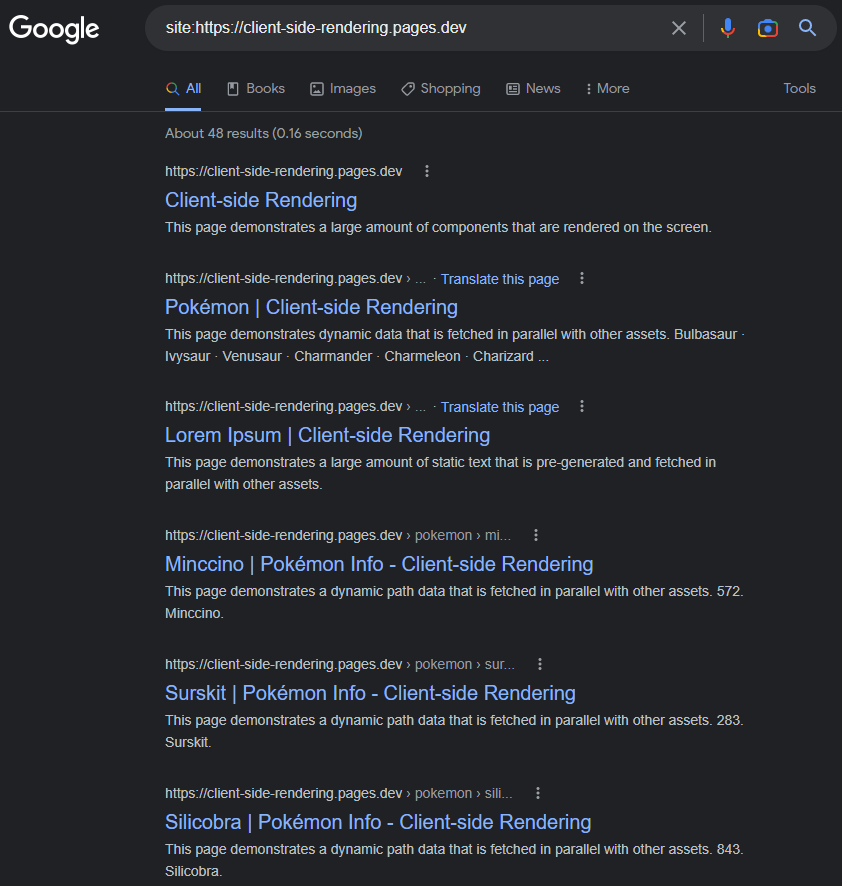
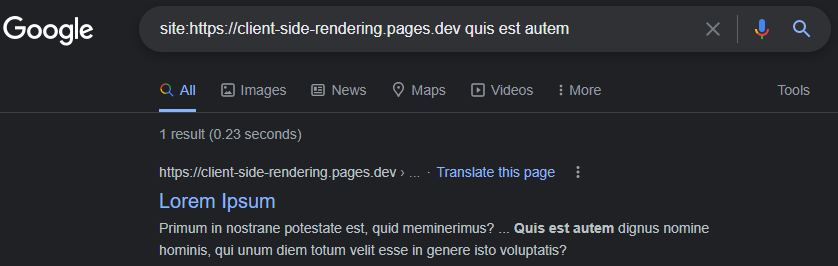
Die Fähigkeit von GoogleBot Der Render JS kann leicht nachweisen, indem ein Live -URL -Test unserer App in der Google -Suchkonsole durchgeführt wird:
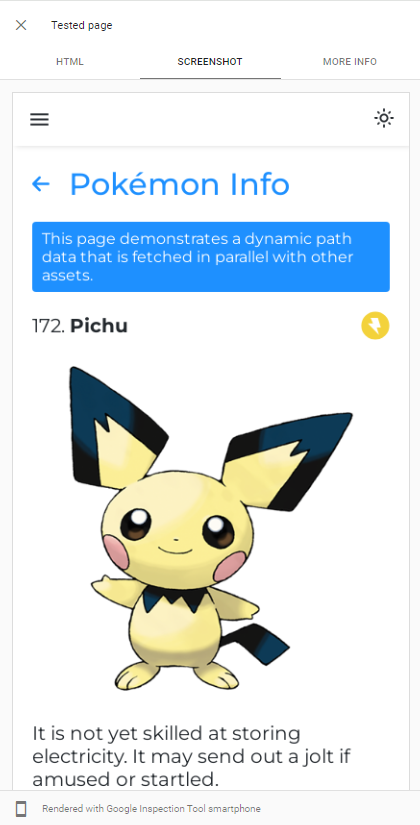
GoogleBot verwendet die neueste Version von Chromium, um Apps zu kriechen. Wir sollten daher nur sicherstellen, dass unsere App schnell geladen wird und dass sie schnell Daten abrufen können.
Selbst wenn die Daten lange Zeit dauern, wenn das Abrufen lange Zeit dauert, warten GoogleBot in den meisten Fällen darauf, bevor sie einen Schnappschuss der Seite aufnehmen:
https://support.google.com/webmasters/thread/202552760/for-how-long-doid-googlebot-wait-for-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
Eine detaillierte Erklärung des JS -Crawling -Prozesses von GoogleBot finden Sie hier:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
Wenn GoogleBot einige Seiten nicht rendert, liegt es hauptsächlich daran, dass Google mangelt, die erforderlichen Ressourcen für das Crawl auf der Website auszugeben, was bedeutet, dass es ein geringes Crawl -Budget hat.
Dies kann bestätigt werden, indem die krabbende Seite inspiziert wird (durch Klicken auf die krabbelende Seite in der Suchkonsole) und sicherzustellen, dass alle fehlgeschlagenen Anforderungen die andere Fehleralarm haben (was bedeutet, dass diese Anfragen absichtlich von GoogleBot abgebrochen wurden):
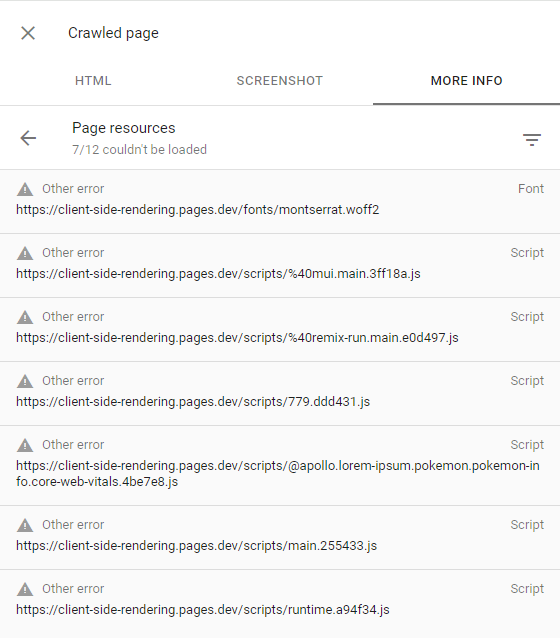
Dies sollte nur auf Websites passieren, auf denen Google keinen interessanten Inhalt oder einen sehr geringen Datenverkehr (z. B. unsere Demo -App) erlegt.
Hier finden Sie weitere Informationen
Andere Suchmaschinen wie Bing können JS nicht rendern. Damit sie unsere App ordnungsgemäß kriechen lassen, müssen wir ihnen eine vorgeborene Version unserer Seiten bedienen.
Das Vorrangern ist der Akt von Crawling -Web -Apps in der Produktion (unter Verwendung des Kopflosen Chroms) und der Generierung einer vollständigen HTML -Datei (mit Daten) für jede Seite.
Wir haben zwei Optionen, wenn es um Vorbereitungen geht:
Serverless Vorbereitung ist der empfohlene Ansatz, da es sehr billig sein kann, insbesondere bei GCP .
Anschließend leiten wir Webcrawler (identifiziert durch ihre Header-String User-Agent ) in unseren Prerenderer mit einem Cloudflare-Worker (zum Beispiel) in unserem Prerenderer:
public/_worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
} Hier finden Sie eine aktuelle Liste aller Bot-Agnets (Webcrawler): https://docs.prerender.io/docs/how-to-add-additional-bots#cloudflare. Denken Sie daran, googlebot aus der Liste auszuschließen.
Das Prerendering , auch Dynamic Rendering genannt, wird von Microsoft gefördert und wird von vielen beliebten Websites, einschließlich Twitter, stark verwendet.
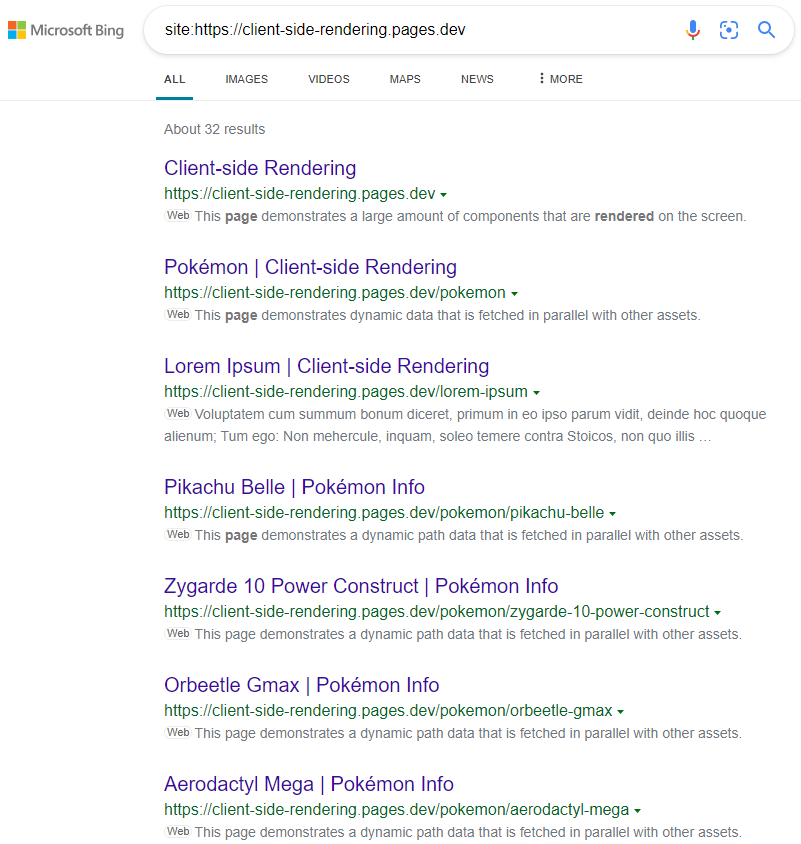
Die Ergebnisse sind wie erwartet:
https://www.bing.com/search?q=sit%3AHttps%3A%2F%2Fclient-Sside-Rendering.pages.dev
Beachten Sie, dass wir bei der Verwendung von CSS-in-JS die schnelle Optimierung während der Vorbereitung deaktivieren können, wenn wir unsere Stile in das DOM weglassen möchten.
Wenn wir einen CSR -App -Link in sozialen Medien teilen, können wir sehen, dass die Vorschau unabhängig von der Seite gleich bleibt.
Dies geschieht, weil die meisten CSR -Apps nur eine inhaltslose HTML -Datei haben und Social -Media -Crawler JS nicht rendern.
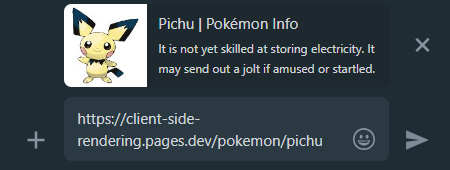
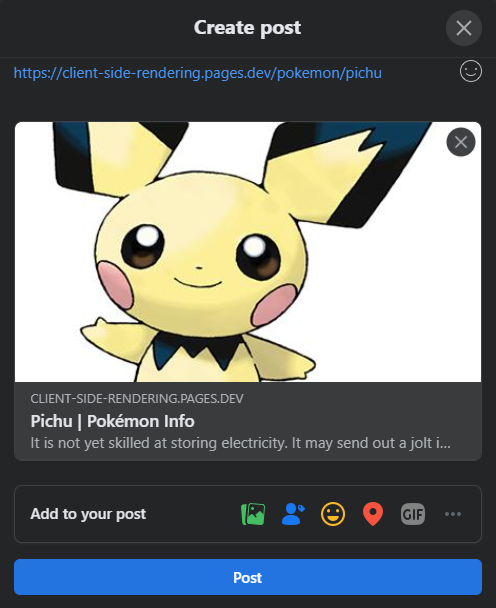
Hier kommt es noch einmal vor dem Voran der Hilfsmittel. Es wird für jede Seite die richtige Vorschau der Freigabe erzeugt:
WhatsApp:
Facebook :
Um alle unsere App -Seiten für Suchmaschinen aufmerksam zu machen, wird empfohlen, eine sitemap.xml -Datei zu erstellen, in der alle unsere Website -Routen angegeben sind.
Da wir bereits eine zentralisierte Seiten.js -Datei haben, können wir während der Build -Zeit problemlos eine Sitemap erstellen:
erstellen-sideemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )Dies wird die folgende Sitemap ausgeben:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >Wir können unsere Sitemap manuell an Google Search Console und Bing Webmaster -Tools senden.
Wie oben erwähnt, finden Sie hier ein eingehender Vergleich aller Rendering-Methoden: https://client-sside-rendering.pages.dev/Comparison
Wir haben die Vorteile statischer Dateien gesehen: Sie sind zwischengespeichert und können von einem nahe gelegenen CDN serviert werden, ohne einen Server zu benötigen.
Dies könnte zu der Annahme führen, dass SSG die Vorteile von CSR und SSR kombiniert: Dadurch wird unsere App sehr schnell ( FCP ) und unabhängig von den Antwortzeiten unseres API -Servers visuell geladen.
In Wirklichkeit hat SSG jedoch eine große Einschränkung:
Da JS in den ersten Momenten nicht aktiv ist, ist alles, was auf JS zu präsentieren ist, einfach nicht sichtbar oder wird falsch angezeigt (wie Komponenten, die vom window.matchMedia abhängen. Matchmedia -Funktion zum Rendern).
Ein klassisches Beispiel für dieses Problem ist auf der folgenden Website zu sehen:
https://death-to-ie11.com
Beachten Sie, wie der Timer nicht sofort sichtbar ist? Das liegt daran, dass es von JS generiert wird, das Zeit zum Herunterladen und Ausführen braucht.
Wir sehen auch ein ähnliches Problem, wenn die "Führer" von Vercel mit einigen angewandten Filtern erfrischt:
https://vercel.com/guides?topics=analytics
Dies geschieht, da es 65536 (2^16) mögliche Filterkombinationen gibt, und das Speichern jeder Kombination als separate HTML -Datei würde viel Serverspeicher erfordern.
Sie generieren also eine einzelne guides.html -Datei, die alle Daten enthält. Diese statische Datei weiß jedoch nicht, welche Filter angewendet werden, bis JS geladen ist, was zu einer Layoutverschiebung führt.
Es ist wichtig zu beachten, dass die Benutzer selbst bei inkrementeller statischer Regeneration noch auf eine Serverantwort warten müssen, wenn sie nicht zwischengespeichert wurden (genau wie in SSR).
Ein weiteres Beispiel für dieses Problem sind JS -Animationen - sie könnten anfangs statisch erscheinen und erst dann animieren, sobald JS geladen ist.
Es gibt viele Fälle, in denen diese verzögerte Funktionalität der Benutzererfahrung schädigt, z.
Ein weiteres kritisches Problem, insbesondere für E-Commerce-Websites, besteht darin, dass SSG-Seiten veraltete Daten (wie Preis oder Verfügbarkeit eines Produkts) anzeigen können.
Genau aus diesem Grund verwendet keine große E-Commerce-Website SSG.
Es ist eine Tatsache, dass sowohl CSR als auch SSR unter schneller Internetverbindung großartig abschneiden (solange sie beide optimiert sind) und je höher die Verbindungsgeschwindigkeit -, je näher sie in Bezug auf die Ladezeiten kommen.
Im Umgang mit langsamen Verbindungen (z. B. Mobilfunknetze) scheint SSR jedoch über CSR in Bezug auf die Ladezeiten einen Vorsprung zu haben.
Da SSR-Apps auf dem Server gerendert werden, empfängt der Browser die vollständig konstruierte HTML-Datei und kann den Benutzer die Seite anzeigen, ohne auf JS zu warten, um herunterzuladen. Wenn JS schließlich heruntergeladen und analysiert wird, kann das Framework das DOM mit Funktionalität "hydratieren" (ohne es rekonstruieren zu müssen).
Obwohl es ein großer Vorteil erscheint, führt dieses Verhalten einen unerwünschten Nebeneffekt ein, insbesondere bei langsameren Verbindungen:
Bis JS geladen ist, können Benutzer überall dort klicken, wo sie sich wünschen, aber die App reagiert nicht auf eines ihrer JS-basierten Ereignisse.
Es ist eine schlechte Benutzererfahrung, wenn Schaltflächen nicht auf Benutzerinteraktionen reagieren, aber es wird zu einem viel größeren Problem, wenn Standardereignisse nicht verhindert werden.
Dies ist ein Vergleich zwischen der Website von Next.js und unserer Kunden-Side-Rendering-App für eine schnelle 3G-Verbindung:
Was ist hier passiert?
Da JS noch nicht geladen wurde, konnte die Website von Next.JS das Standardverhalten von Anker -Tagelementen ( <a> ) nicht verhindern, zu einer anderen Seite zu navigieren, was dazu führt, dass jedes Klick auf sie eine vollständige Seite nachgeladen wird.
Und je langsamer die Verbindung ist - desto schwerwiegender wird dieses Problem.
Mit anderen Worten, wo SSR über CSR einen Leistungsvorteil haben sollen, sehen wir ein sehr "gefährliches" Verhalten, das die Benutzererfahrung erheblich beeinträchtigen könnte.
Es ist unmöglich, dass dieses Problem in CSR -Apps auftritt, da sie bereits voll geladen sind.
Wir haben gesehen, dass die Kunden-Rendering-Leistung auf NAI und manchmal sogar besser als SSR in Bezug auf die anfänglichen Ladezeiten ist (und sie in den Navigationszeiten weit übertrifft).
Wir haben auch gesehen, dass GoogleBot die client-Seite mitgelieferten Apps perfekt indexieren kann und dass wir problemlos einen Prerender-Server einrichten können, um allen anderen Bots und Crawlern zu servieren.
Und vor allem haben wir dies alles erreicht, indem wir ein paar Dateien hinzugefügt und einen Prerender -Dienst verwendet haben. Daher sollte jede vorhandene CSR -App diese Änderungen schnell und einfach implementieren und davon profitieren.
Diese Tatsachen führen zu dem Schluss, dass es keinen zwingenden Grund gibt, SSR zu verwenden. Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


