client side rendering
1.0.0
Ce projet est une étude de cas de la RSE, il explore le potentiel des applications rendues côté client par rapport au rendu côté serveur.
Une comparaison approfondie de toutes les méthodes de rendu peut être trouvée sur la page de comparaison de ce projet: https://client-side-redering.pages.dev/comparison
Le rendu côté client (RSE) fait référence à l'envoi d'actifs statiques au navigateur Web et à lui permettre de gérer l'ensemble du processus de rendu de l'application.
Le rendu côté serveur (SSR) implique le rendu de l'ensemble de l'application (ou de la page) sur le serveur et la livraison d'un document HTML pré-rendu prêt pour l'affichage.
La génération de sites statique (SSG) est le processus de pré-générer des pages HTML sous forme d'actifs statiques, qui sont ensuite envoyés et affichés par le navigateur.
Contrairement à la croyance commune, le processus SSR dans les cadres modernes comme React , Angular , Vue et Svelte entraîne le rendu de l'application deux fois: une fois sur le serveur et à nouveau sur le navigateur (c'est ce qu'on appelle "l'hydratation"). Sans ce deuxième rendu, l'application serait statique et non interactive, se comportait essentiellement comme une page Web "sans vie".
Fait intéressant, le processus d'hydratation ne semble pas être plus rapide qu'un rendu typique (à l'exclusion de la phase de peinture, bien sûr).
Il est également important de noter que les applications SSG doivent également subir l'hydratation.
Dans SSR et SSG, le document HTML est entièrement construit, offrant les avantages suivants:
D'un autre côté, les applications CSR offrent les avantages suivants:
Dans cette étude de cas, nous nous concentrerons sur la RSE et explorerons les moyens de surmonter ses limites apparentes tout en tirant parti de ses forces au sommet.
Toutes les optimisations seront incorporées dans l'application déployée, qui peut être trouvée ici: https://client-side-redering.pages.dev.
"Récemment, SSR (rendu côté serveur) a pris la tempête du monde frontal JavaScript.
Cependant, les mêmes critiques qui étaient valables pour PHP, ASP, JSP (et ces) sites sont valables pour le rendu côté serveur aujourd'hui. Il est lent, se casse assez facilement et est difficile à mettre en œuvre correctement.
Le fait est que, malgré ce que tout le monde pourrait vous dire, vous n'avez probablement pas besoin de SSR. Vous pouvez en obtenir presque tous les avantages (sans les inconvénients) en utilisant la prétention. "
~ Plugin Spa à prétention
Ces dernières années, le rendu côté serveur a gagné en popularité significative sous la forme de cadres tels que Next.js et Remix au point que les développeurs les utilisent souvent sans comprendre pleinement leurs limites, même dans les applications qui n'ont pas besoin de référencement (par exemple, celles qui ont des exigences de connexion).
Bien que SSR ait ses avantages, ces cadres continuent de souligner leur vitesse ("Performance en par défaut"), ce qui suggère que le rendu côté client (RSE) est intrinsèquement lent.
De plus, il existe une idée fausse répandue selon laquelle le référencement parfait ne peut être réalisé qu'avec SSR, et que les applications CSR ne peuvent pas être optimisées pour les robots de recherche.
Un autre argument courant pour la RSS est que à mesure que les applications Web grandissent, leurs temps de chargement continueront d'augmenter, conduisant à de mauvaises performances FCP pour les applications CSR.
S'il est vrai que les applications deviennent plus riches en fonctionnalités, la taille d'une seule page devrait en fait diminuer avec le temps.
Cela est dû à la tendance de la création de versions plus petites et plus efficaces des bibliothèques et des cadres, tels que Zustand , Day.js , Headless-UI et React-Router V6 .
Nous pouvons également observer une réduction de la taille des cadres au fil du temps: angulaire (74,1kb), réact (44,5 Ko), Vue (34KB), solide (7,6 Ko) et Svelte (1,7 Ko).
Ces bibliothèques contribuent de manière significative au poids global des scripts d'une page Web.
Avec un bon code de code, le temps de chargement initial d'une page pourrait diminuer avec le temps.
Ce projet met en œuvre une application CSR de base avec des optimisations comme le coup de code et le préchargement. L'objectif est que le temps de chargement des pages individuelles reste stable à mesure que l'application évolue.
L'objectif est de simuler la structure de package d'une application de qualité de production et de minimiser les temps de chargement via des demandes parallélisées.
Il est important de noter que l'amélioration des performances ne devrait pas se faire au prix de l'expérience du développeur. Par conséquent, l'architecture de ce projet ne sera que légèrement modifiée à partir d'une configuration de réaction typique, en évitant la structure rigide et opinionnée des cadres comme Next.js, ou les limites de la RSS en général.
Cette étude de cas se concentrera sur deux aspects principaux: les performances et le référencement. Nous explorerons comment atteindre les meilleurs scores dans les deux domaines.
Notez que bien que ce projet soit mis en œuvre à l'aide de React, la plupart des optimisations sont agnostiques du cadre et sont purement basées sur le bundler et le navigateur Web.
Nous assumerons une configuration WebPack (RSPACK) standard et ajouterons les personnalisations requises au fur et à mesure que nous progressons.
La première règle de base consiste à minimiser les dépendances et, parmi celles-ci, à choisir celles avec les plus petites tailles de fichiers.
Par exemple:
Nous pouvons utiliser day.js au lieu du moment , zustand au lieu de la boîte à outils redux , etc.
Ceci est important non seulement pour les applications CSR, mais aussi pour les applications SSR (et SSG), car des faisceaux plus grands entraînent des temps de chargement plus longs, retardant lorsque la page devient visible ou interactive.
Idéalement, chaque fichier hachée doit être mis en cache et index.html ne doit jamais être mis en cache.
Cela signifie que le navigateur mettrait initialement le cache main.[hash].js et ne devrait pas le télécharger de refonte uniquement si son hachage (contenu) change:

Cependant, puisque main.js inclut l'ensemble du bundle, le moindre changement de code entraînerait l'expiration de son cache, ce qui signifie que le navigateur devrait le télécharger à nouveau.
Maintenant, quelle partie de notre paquet comprend la majeure partie de son poids? La réponse est les dépendances , également appelées vendeurs .
Donc, si nous pouvions diviser les vendeurs en leur propre morceau hachée, cela permettrait une séparation entre notre code et le code des fournisseurs, conduisant à moins d'invalidations de cache.
Ajoutons l' optimisation suivante à notre fichier de configuration:
Rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
} Cela créera un vendors.[hash].js Fichier:

Bien qu'il s'agisse d'une amélioration substantielle, que se passerait-il si nous mettions à jour une très faible dépendance?
Dans un tel cas, le cache de l'ensemble des vendeurs invalidera.
Ainsi, afin de l'améliorer encore plus, nous partagerons chaque dépendance à son propre morceau hachée:
Rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ } Cela créera des fichiers comme react-dom.[hash].js qui contiennent un seul grand fournisseur et un fichier [id].[hash].js qui contient tous les (petits) fournisseurs restants:
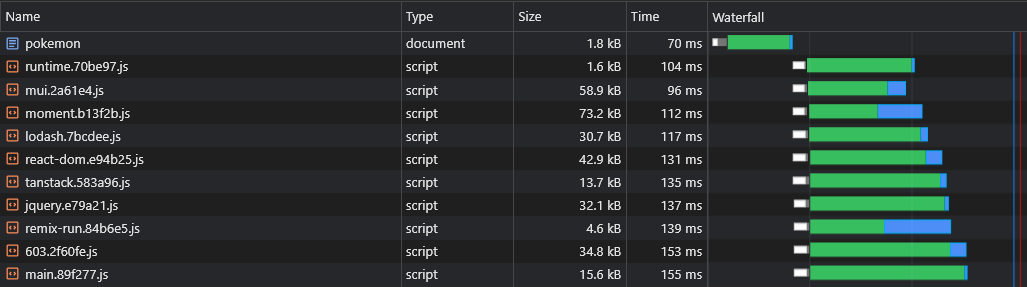
Plus d'informations sur les configurations par défaut (telles que la taille du seuil divisé) peuvent être trouvées ici:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
Beaucoup de fonctionnalités que nous écrivons finissent par être utilisées uniquement dans quelques-unes de nos pages, nous souhaitons donc qu'ils soient chargés uniquement lorsque l'utilisateur visite la page dans laquelle ils sont utilisés.
Par exemple, nous ne voudrions pas que les utilisateurs aient à attendre que le package React-Big-Calendar soit téléchargé, analysé et exécuté s'ils ont simplement chargé la page d'accueil . Nous voudrions que cela se produise lorsqu'ils visitent la page de calendrier .
La façon dont nous pouvons y parvenir est (de préférence) par division de code basée sur des itinéraires:
App.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) ) Ainsi, lorsque les utilisateurs visitent la page Pokemon , ils téléchargent uniquement les scripts principaux (qui incluent toutes les dépendances partagées telles que le framework) et le pokemon.[hash].js Chunk.
Remarque: il est encouragé à télécharger l'intégralité de l'application afin que les utilisateurs subissent des navigations instantanées, semblables à l'application. Mais c'est une mauvaise idée de parler de tous les actifs en un seul script, retardant le premier rendu de la page.
Ces actifs doivent être téléchargés de manière asynchrone et seulement après la fin de la page demandée par l'utilisateur et est entièrement visible.
Le fractionnement du code a un défaut majeur - l'exécution ne sait pas quels morceaux asynchronisés sont nécessaires jusqu'à ce que le script principal s'exécute, ce qui les conduisait à être récupérés dans un retard significatif (car ils font un autre aller-retour au CDN):

La façon dont nous pouvons résoudre ce problème est en écrivant un plugin personnalisé qui intégrera un script dans le document qui sera responsable de précharger les actifs pertinents:
Rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}scripts / inject-assets-plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginscripts / preload-asts.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
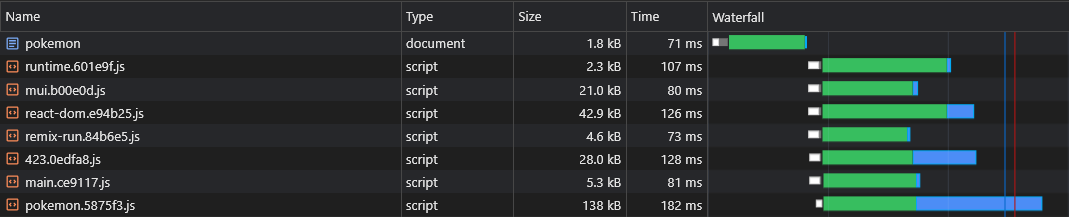
preloadAssets ( ) Le fichier pages.js importé est disponible ici.
De cette façon, le navigateur est capable de récupérer le morceau de script spécifique à la page en parallèle avec les actifs critiques de rendu:
Le fractionnement de code présente un autre problème: la duplication asynchrone du fournisseur.
Disons que nous avons deux morceaux asynchronisés: lorem-ipsum.[hash].js et pokemon.[hash].js . S'ils incluent tous les deux la même dépendance qui ne fait pas partie du morceau principal, cela signifie que l'utilisateur téléchargera cette dépendance deux fois .
Donc, si cette dépendance est moment et qu'il pèse 72 Ko Minzipped, la taille de Async Chunk sera à au moins 72 Ko.
Nous devons diviser cette dépendance de ces morceaux asynchrones afin qu'il puisse être partagé entre eux:
Rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
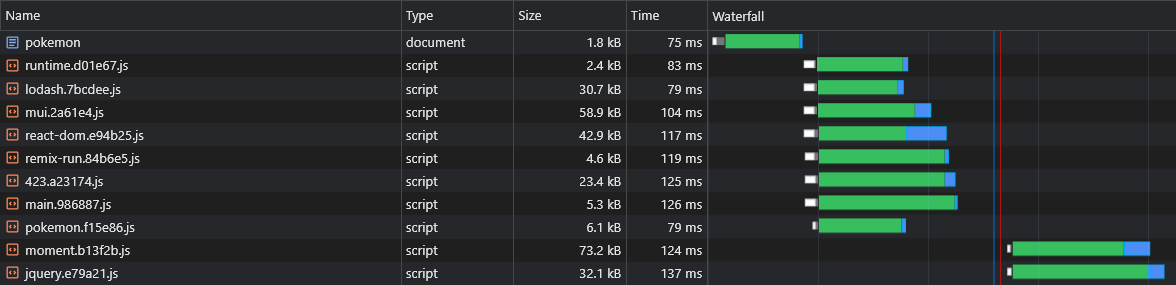
} Maintenant, à la fois lorem-ipsum.[hash].js et pokemon.[hash].js utilisera le moment.[hash].js
Cependant, nous n'avons aucun moyen de dire quels morceaux de fournisseur asynchrone seront divisés avant de construire l'application, nous ne saurions donc pas quels morceaux de fournisseur asynchrone dont nous devons précharger (reportez-vous à la "section de préchargement des morceaux asynchrones"):
C'est pourquoi nous allons ajouter les noms des morceaux au nom du fournisseur asynchrone:
Rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}scripts / inject-assets-plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}scripts / preload-asts.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ })Désormais, tous les morceaux de fournisseur asynchrone seront récupérés en parallèle avec leur morceau asynchrone parent:
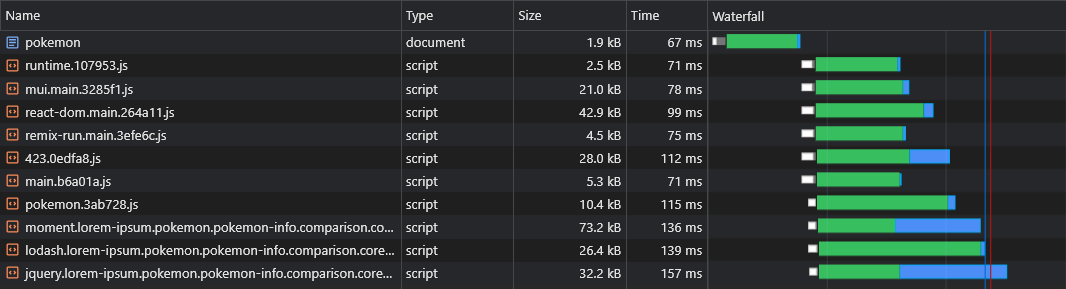
L'un des inconvénients présumés de la RSE sur SSR est que les données de la page (demandes de récupération) ne seront licenciées qu'après le téléchargement, l'analyse et l'exécution de JS: le navigateur:
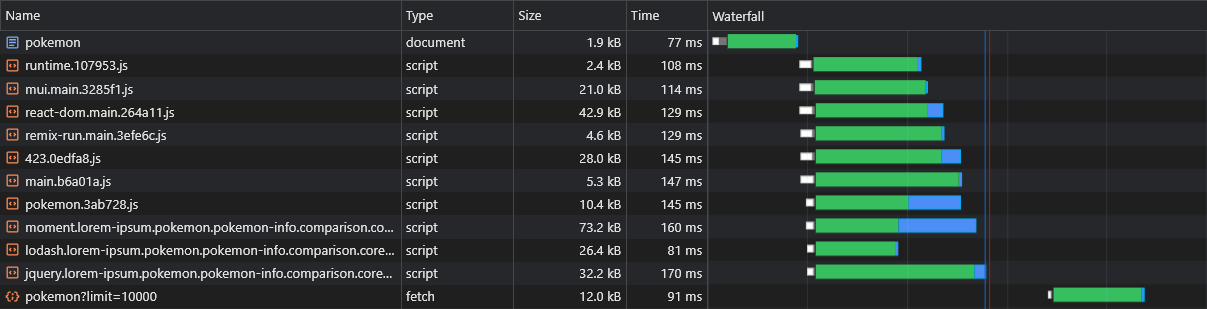
Pour surmonter cela, nous utiliserons à nouveau le préchargement, cette fois pour les données elle-même, en corrigeant l'API fetch :
scripts / inject-assets-plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})scripts / preload-asts.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets() Rappel: le fichier pages.js peut être trouvé ici.
Nous pouvons maintenant voir que les données sont récupérées immédiatement:
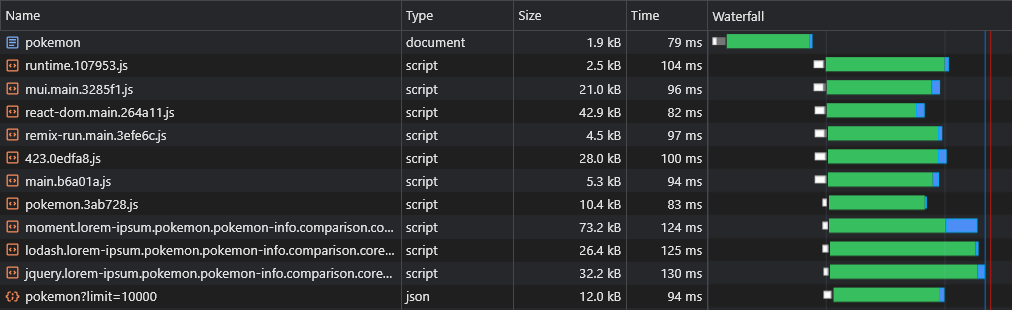
Avec le script ci-dessus, nous pouvons même précharger des données de routes dynamiques (telles que Pokemon /: Name ).
Les utilisateurs doivent avoir une expérience de navigation en douceur dans notre application.
Cependant, la division de chaque page provoque un retard notable dans la navigation, car chaque page doit être téléchargée (à la demande) avant de pouvoir être rendue à l'écran.
Nous voudrions prédécrocher et mettre en cache toutes les pages à l'avance.
Nous pouvons le faire en écrivant un employé de service simple:
Rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}src / utils / service-travailleur-inscription.ts
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}public / service-travailleur.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Désormais, toutes les pages seront prédéfinies et mises en cache avant même que l'utilisateur essaie d'y accéder.
Cette approche générera également un cache de code complet.
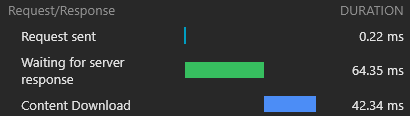
Lors de l'inspection de notre fichier react-dom.js de 43KB, nous pouvons voir que le temps qu'il a fallu pour que la demande revienne était de 60 ms pendant que le temps qu'il a fallu pour télécharger le fichier était de 3 ms:

Cela démontre le fait bien connu que RTT a un impact énorme sur les temps de chargement des pages Web, parfois encore plus que la vitesse de téléchargement, et même lorsque les actifs sont servis à partir d'un bord CDN à proximité comme dans notre cas.
De plus et plus important encore, nous pouvons voir qu'après le téléchargement du fichier HTML, nous avons un grand temps où le navigateur reste inactif et attend simplement que les scripts arrivent:
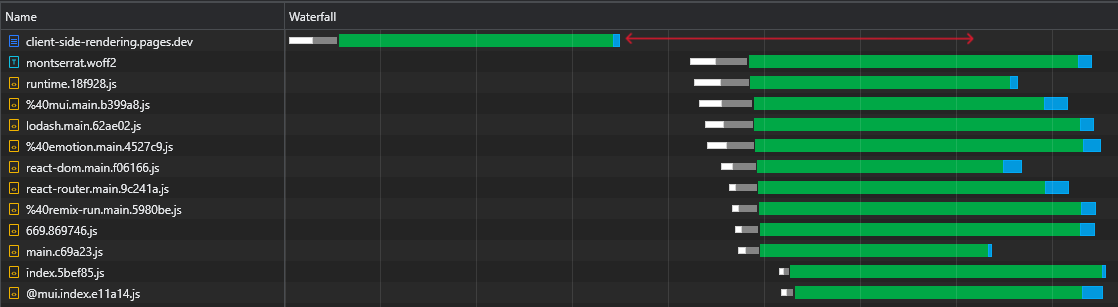
C'est beaucoup de temps précieux (marqué en rouge) que le navigateur pourrait utiliser pour télécharger, analyser et même exécuter des scripts, accélérant la visibilité et l'interactivité de la page.
Cette inefficacité se reproduira à chaque fois que les actifs changent (cache partiel). Ce n'est pas quelque chose qui ne se produit que lors de la toute première visite.
Alors, comment pouvons-nous éliminer ce temps d'inactivité?
Nous pourrions en informer tous les scripts initiaux (critiques) dans le document, afin qu'ils commencent à télécharger, analyser et exécuter jusqu'à l'arrivée des actifs de la page asynchronisés:

Nous pouvons voir que le navigateur obtient désormais ses scripts initiaux sans avoir à envoyer une autre demande au CDN.
Ainsi, le navigateur enverra d'abord les demandes pour les morceaux asynchrones et les données préchargées, et bien qu'elles soient en attente, elle continuera à télécharger et à exécuter les scripts principaux.
Nous pouvons voir que les morceaux asynchrones commencent à télécharger (marqué en bleu) juste après que le fichier HTML ait terminé le téléchargement, l'analyse et l'exécution, ce qui fait gagner beaucoup de temps.
Bien que ce changement fasse une différence significative sur les réseaux rapides, il est encore plus crucial pour les réseaux plus lents, où le retard est plus grand et le RTT est beaucoup plus percutant.
Cependant, cette solution a 2 problèmes majeurs:
Pour surmonter ces problèmes, nous ne pouvons plus nous en tenir à un fichier HTML statique, et nous allons donc sauter la puissance d'un serveur. Ou, plus précisément, la puissance d'un travailleur sans serveur CloudFlare.
Ce travailleur doit intercepter chaque demande de document HTML et adapter une réponse qui lui convient parfaitement.
L'ensemble du flux doit être décrit comme suit:
X-Cached dans la demande. Si un tel en-tête existe, il iratera sur ses valeurs et en ligne uniquement les actifs pertinents * qui en sont absents dans la réponse. Si un tel en-tête n'existe pas, il en insertera tous les actifs pertinents dans la réponse.X-Cached spécifiant tous ses actifs mis en cache.* Assets initiaux et spécifiques à la page.
Cela garantit que le navigateur reçoit exactement les actifs dont il a besoin (plus, pas moins) pour afficher la page actuelle en une seule aller-retour !
scripts / inject-assets-plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpublic / _Worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src / utils / extrait-inline-scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptssrc / utils / service-travailleur-inscription.ts
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}public / service-travailleur.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Les résultats pour une charge fraîche (entièrement non achetée) sont exceptionnelles:


Sur la charge suivante, le travailleur CloudFlare répond par un document HTML minimal (1,8 kb) et tous les actifs sont immédiatement servis à partir du cache.
Cette optimisation nous amène à un autre - diviser des morceaux en morceaux encore plus petits.
En règle générale, la division du paquet en trop de morceaux peut nuire aux performances. En effet, la page ne sera pas rendue tant que tous ses fichiers ne seront pas téléchargés et plus il y a de morceaux, plus la probabilité que l'une d'entre elles soit retardée soit retardée (car le matériel et la vitesse du réseau sont non linéaires).
Mais dans notre cas, ce n'est pas pertinent, puisque nous inlassons tous les morceaux pertinents et ils sont donc allés en même temps.
Rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},Cette division extrême conduira à une meilleure persistance de cache, et à son tour, à des temps de chargement plus rapides avec un cache partiel.
Lorsqu'un actif statique est récupéré à partir d'un CDN, il comprend un en-tête ETag , qui est un hachage de contenu de la ressource. Sur les demandes suivantes, le navigateur vérifie s'il a un ETAG stocké. Si c'est le cas, il envoie l'ETAG dans un en-tête If-None-Match . Le CDN compare alors l'ETAG reçu avec celui actuel: s'ils correspondent, il renvoie un statut 304 Not Modified , indiquant que le navigateur peut utiliser l'actif mis en cache; Sinon, il renvoie le nouvel actif avec un statut 200 .
Dans une application CSR traditionnelle, le rechargement d'une page entraîne le HTML obtenant un 304 Not Modified , avec d'autres actifs servis à partir du cache. Chaque itinéraire a un ETAG unique, donc /lorem-ipsum et /pokemon ont différentes entrées de cache, même si leurs ETAG sont identiques.
Dans un spa CSR, comme il n'y a qu'un seul fichier HTML, le même ETAG est utilisé pour chaque demande de page. Cependant, comme l'ETAG est stocké par itinéraire, le navigateur n'enverra pas un en-tête de If-None-Match pour des pages non visitées, conduisant à un statut 200 et à un chargement rafraîchissant du HTML, même s'il s'agit du même fichier.
Cependant, nous pouvons facilement créer notre propre implémentation (améliorée) de ce comportement grâce à une collaboration entre les travailleurs:
scripts / inject-assets-plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}public / _Worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}public / service-travailleur.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} Notez qu'un X-ETag personnalisé est inclus pour les situations où le CDN n'envoie pas automatiquement un ETag .
Maintenant, notre travailleur sans serveur répondra toujours par un code d'état 304 Not Modified chaque fois qu'il n'y a pas de modifications, même pour les pages non visitées.
Lorsqu'un travailleur de service est utilisé, le navigateur retarde l'envoi de la demande de document HTML initiale jusqu'à ce que le travailleur du service soit chargé, ce qui peut entraîner un délai de page léger à modéré en fonction du matériel.
La solution native à ce problème est appelée précharge de navigation . Nous allons l'implémenter pour s'assurer que la demande de document est envoyée immédiatement, sans attendre que le travailleur du service se charge:
src / utils / service-travailleur-inscription.ts
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}public / service-travailleur.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Avec cette implémentation, la demande de document sera envoyée immédiatement, indépendamment du travailleur des services.
Remarque: nécessite React (v18), svelte ou solide.js
Lorsque nous divisons une page de l'application principale, nous séparons sa phase de rendu, ce qui signifie que l'application sera rendu avant les rendus de la page.
Ainsi, lorsque nous passons d'une page asynchrone à une autre, nous voyons un espace vide qui reste jusqu'à ce que la page soit rendue:
Cela se produit en raison de l'approche commune de l'emballage uniquement des itinéraires avec suspense:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18 nous a présenté le crochet useTransition , ce qui nous permet de retarder un rendu jusqu'à ce que certains critères soient remplis.
Nous utiliserons ce crochet pour retarder la navigation de la page jusqu'à ce qu'elle soit prête:
usetransitionnavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkMaintenant, les pages asynchrones auront l'impression de ne jamais avoir été séparées de l'application principale.
Nous pouvons précharger d'autres données de pages lors de la survol des liens (bureau) ou lorsque les liens entrent dans la fenêtre (mobile):
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >Notez que cela peut charger inutilement le serveur API.
Certains utilisateurs quittent l'application ouverte pendant de longues périodes, donc une autre chose que nous pouvons faire est de revérifier (télécharger de nouveaux actifs de) l'application pendant qu'il s'exécute:
service de service.
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}Le code ci-dessus revalide l'application toutes les heures.
Le processus de revalidation est extrêmement bon marché, car il implique de refaire le travailleur du service (qui renverra un code d'état 304 non modifié s'il n'est pas modifié).
Lorsque le travailleur des services change , cela signifie que de nouveaux actifs sont disponibles, et donc ils seront téléchargés et mis en cache de manière sélective.
Nous avons divisé notre paquet en de nombreux petits morceaux, améliorant considérablement les capacités de mise en cache de notre application.
Nous divisons chaque page afin qu'en chargeant un, seul ce qui est pertinent est en cours de téléchargement immédiatement.
Nous avons réussi à rendre la charge initiale (sans mise en cache) de notre application extrêmement rapide, tout ce dont une page nécessite de charger est injecté dynamiquement.
Nous préchargez même les données de la page, éliminant la célèbre cascade de données que les applications CSR sont connues.
De plus, nous présablissons toutes les pages, ce qui donne l'impression qu'ils n'ont jamais été divisés à partir du code du bundle principal.
Tous ces éléments ont été réalisés sans compromettre l'expérience du développeur et sans dicter le cadre JS à choisir.
Le plus grand avantage d'une application statique est qu'il peut être entièrement servi à partir d'un CDN.
Un CDN a de nombreux POP (points de présence), également appelés "Networks Edge". Ces POP sont distribués dans le monde entier et sont donc en mesure de servir des fichiers dans chaque région beaucoup plus rapidement qu'un serveur distant.
Le CDN le plus rapide à ce jour est CloudFlare, qui a plus de 250 pops (et comptage):
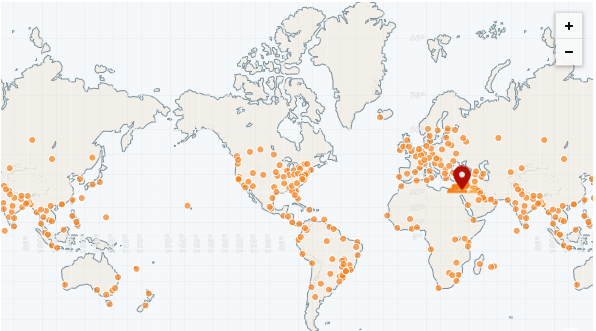
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-edge-network-performance
Nous pouvons facilement déployer notre application à l'aide de pages CloudFlare:
https://pages.cloudflare.com
Pour conclure cette section, nous effectuerons une référence de notre application par rapport au site de documentation de Next.js , qui est entièrement SSG .
Nous comparerons la page d'accessibilité minimaliste à notre page Lorem Ipsum . Les deux pages incluent ~ 246 Ko de JS dans leurs morceaux critiques de rendu (préchargement et préfestés qui se présentent sont sans importance).
Vous pouvez cliquer sur chaque lien pour effectuer une référence en direct.
Accessibilité | Next.js
Lorem ipsum | Rendu côté client
J'ai effectué la référence PagesPeed Insights de Google (simulant un réseau 4G lent) environ 20 fois pour chaque page et choisi le score le plus élevé.
Ce sont les résultats:
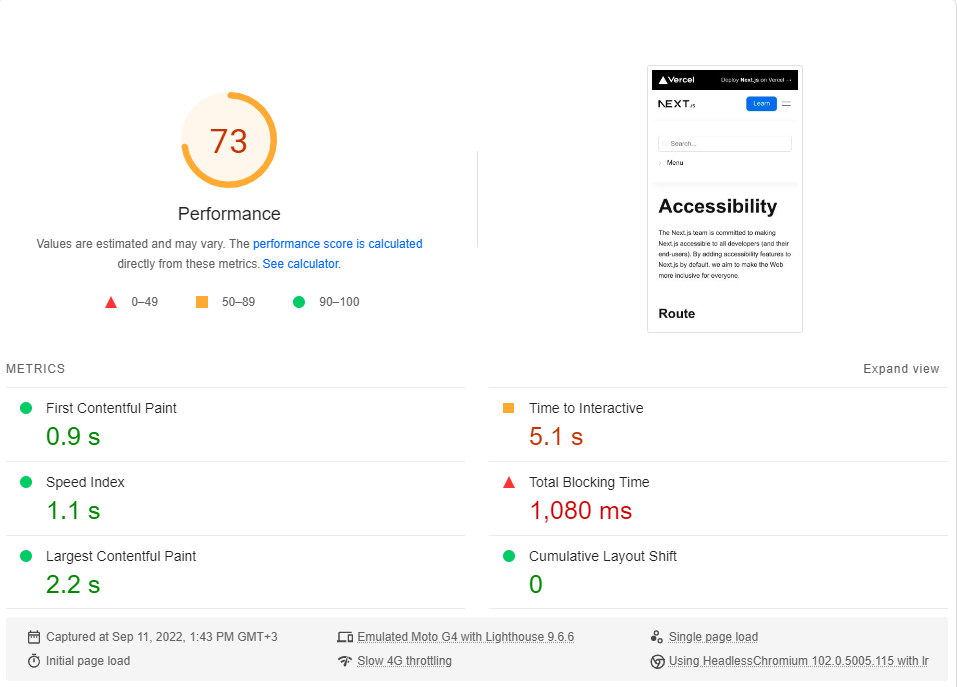
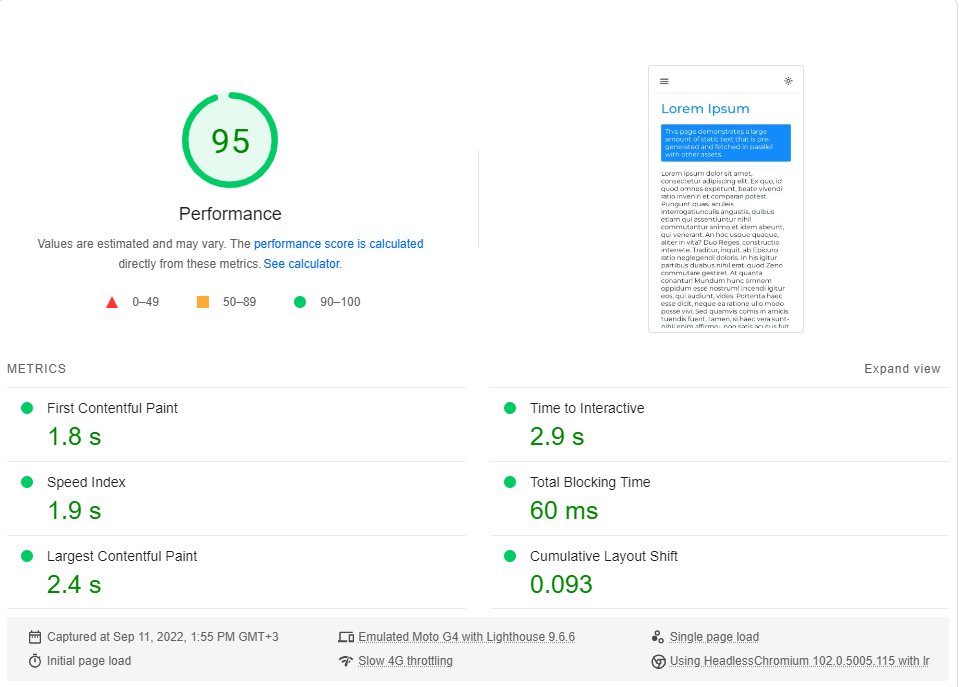
Il s'avère que les performances ne sont pas une valeur par défaut dans next.js.
Notez que cette référence ne teste que la première charge de la page, sans même considérer comment l'application fonctionne lorsqu'elle est entièrement mise en cache (où la RSE brille vraiment).
Il est courant que Google ait des problèmes d'indexation correctement des applications CSR (JS).
Cela aurait pu être le cas en 2017, mais à ce jour: Google index les applications CSR pour la plupart parfaitement.
Les pages indexées auront un titre, une description, du contenu et tous les autres attributs liés au référencement, tant que nous nous souvenons de les définir dynamiquement (soit manuellement comme celui-ci, soit en utilisant un package tel que React-Helmet ).
https://www.google.com/search?q=site:https://client-side-redering.pages.dev
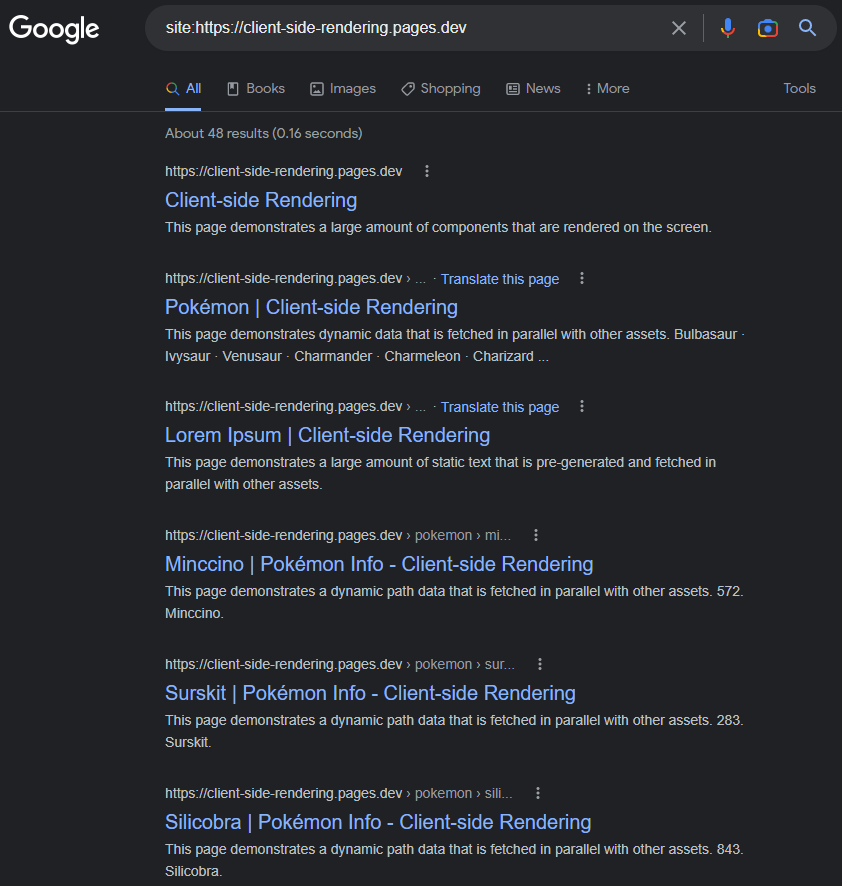
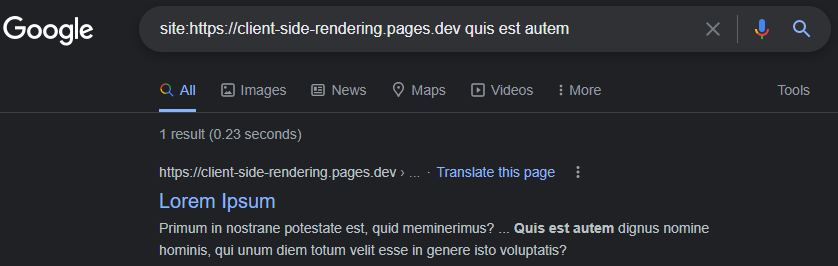
Capacité de Googlebot Le rendu JS peut être facilement démontré en effectuant un test URL en direct de notre application dans la console de recherche Google :
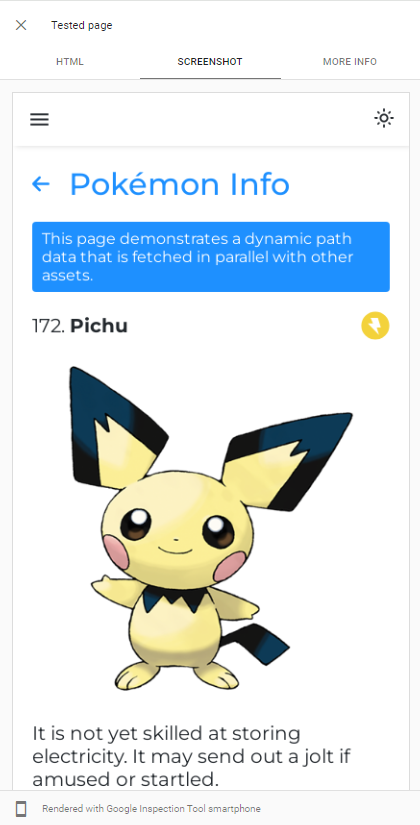
Googlebot utilise la dernière version de Chromium pour faire en sorte que les applications, de sorte que la seule chose que nous devrions faire est de nous assurer que notre application se charge rapidement et qu'elle est rapide pour récupérer les données.
Même lorsque les données mettent longtemps à récupérer, Googlebot, dans la plupart des cas, l'attendra avant de prendre un instantané de la page:
https://support.google.com/webmasters/thread/202552760/for-how-long-does-googlebot-wait-for-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
Une explication détaillée du processus de rampage JS de Googlebot peut être trouvée ici:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
Si Googlebot ne parvient pas à rendre certaines pages, cela est principalement dû à la réticence de Google à dépenser les ressources requises pour ramper le site Web, ce qui signifie qu'il a un budget de rampe faible.
Cela peut être confirmé en inspectant la page rampée (en cliquant sur la page View rampée dans la console de recherche) et en s'assurant que toutes les demandes échouées ont l' autre alerte d'erreur (ce qui signifie que ces demandes ont été intentionnellement abandonnées par Googlebot):
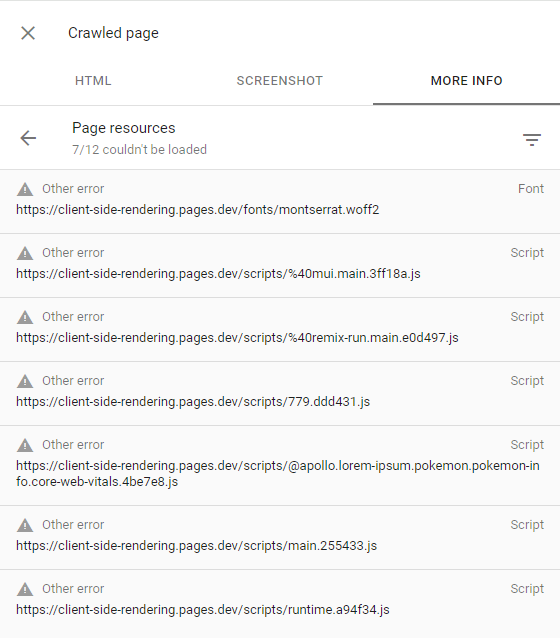
Cela ne devrait arriver qu'aux sites Web que Google considère qu'il n'y a pas de contenu intéressant ou d'avoir un trafic très faible (comme notre application de démonstration).
Plus d'informations peuvent être trouvées ici: https://support.google.com/webmasters/thread/4425254?hl=en&msgid=4426601
D'autres moteurs de recherche tels que Bing ne peuvent pas rendre JS, donc pour les faire ramper correctement notre application, nous devons leur servir la version prérentie de nos pages.
La prétention est l'acte de ramper les applications Web en production (en utilisant le chrome sans tête) et de générer un fichier HTML complet (avec données) pour chaque page.
Nous avons deux options en ce qui concerne la prétention:
La prétention sans serveur est l'approche recommandée car elle peut être très bon marché, en particulier sur GCP .
Ensuite, nous redirigeons les chenilles Web (identifiées par leur chaîne d'en-tête User-Agent ) vers notre prérenger, en utilisant un travailleur CloudFlare (par exemple):
public / _Worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
} Voici une liste à jour de tous les Agnets de bot (robots Web): https://docs.prerender.io/docs/how-to-add-additional-bots#cloudflare. N'oubliez pas d'exclure googlebot de la liste.
Prérencier , également appelé rendu dynamique , est encouragé par Microsoft et est fortement utilisé par de nombreux sites Web populaires, dont Twitter.
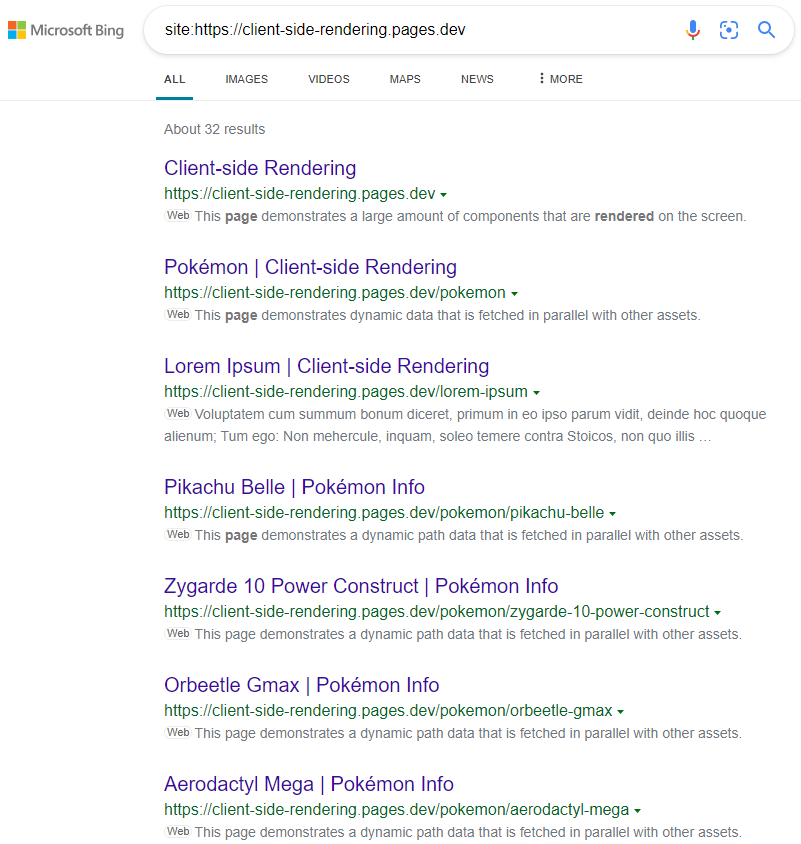
Les résultats sont comme prévu:
https://www.bing.com/search?q=site%3AHTTPS%3A%2F%2FCIENT-SIDE-Dendering.pages.dev
Notez que lors de l'utilisation de CSS-in-JS, nous pouvons désactiver l'optimisation rapide pendant la prétention si nous voulons que nos styles soient omis au DOM.
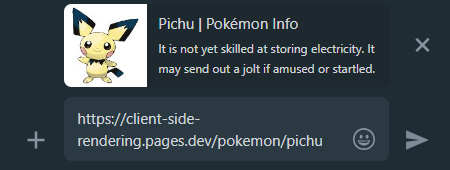
Lorsque nous partageons un lien d'application CSR dans les médias sociaux, nous pouvons voir que quelle que soit la page à laquelle nous nous lions, l'aperçu restera le même.
Cela se produit parce que la plupart des applications CSR n'ont qu'un seul fichier HTML sans contenu, et les robots de médias sociaux ne rendent pas JS.
C'est là que la prétention revient à notre aide une fois de plus, elle générera l'aperçu de partage approprié pour chaque page:
WhatsApp:
Facebook :
Afin de rendre toutes nos pages d'applications découvrant les moteurs de recherche, il est recommandé de créer un fichier sitemap.xml qui spécifie tous nos itinéraires de site Web.
Puisque nous avons déjà un fichier Pages Pages.js centralisé, nous pouvons facilement générer un plan du site pendant la construction:
création-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )Cela émettra le plan du site suivant:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >Nous pouvons soumettre manuellement notre plan du site à Google Search Console et Bing webmaster Tools .
Comme mentionné ci-dessus, une comparaison approfondie de toutes les méthodes de rendu peut être trouvée ici: https://client-side-redering.pages.dev/comparison
Nous avons vu les avantages des fichiers statiques: ils sont cachables et peuvent être servis à partir d'un CDN à proximité sans nécessiter de serveur.
Cela pourrait nous amener à croire que SSG combine les avantages de la RSE et de la SSR: cela rend notre application visuellement très rapidement ( FCP ) et indépendamment des temps de réponse de notre serveur API.
Cependant, en réalité, SSG a une limitation majeure:
Étant donné que JS n'est pas actif pendant les moments initiaux, tout ce qui s'appuie sur JS à présenter ne sera tout simplement pas visible ou sera affiché de manière incorrecte (comme les composants qui dépendent de la fonction window.matchMedia à rendre).
Un exemple classique de ce numéro peut être vu sur le site Web suivant:
https://death-to-ie11.com
Remarquez comment la minuterie n'est pas visible immédiatement? C'est parce qu'il est généré par JS, qui prend du temps à télécharger et à exécuter.
Nous voyons également un problème similaire lorsque la page «Guides» de Vercel rafraîchissait avec certains filtres appliqués:
https://vercel.com/guides?topics=analytics
Cela se produit car il y a 65536 (2^16) des combinaisons de filtres possibles, et le stockage de chaque combinaison en tant que fichier HTML distinct nécessiterait beaucoup de stockage de serveurs.
Ainsi, ils génèrent un seul fichier guides.html qui contient toutes les données, mais ce fichier statique ne sait pas quels filtres sont appliqués jusqu'à ce que JS soit chargé, provoquant un changement de mise en page.
Il est important de noter que même avec une régénération statique incrémentielle , les utilisateurs devront toujours attendre une réponse de serveur lors de la visite des pages qui n'ont pas encore été mises en cache (tout comme dans SSR).
Un autre exemple de ce numéro est JS Animations - ils peuvent apparaître statiques initialement et commencer à l'animation qu'une fois que JS est chargé.
Il existe de nombreux cas où cette fonctionnalité retardée nuit à l'expérience utilisateur, comme lorsque les sites Web affichent uniquement la barre de navigation après le chargement de JS (car ils comptent sur le stockage local pour vérifier si une entrée d'informations utilisateur existe).
Un autre problème critique, en particulier pour les sites Web de commerce électronique, est que les pages SSG peuvent afficher des données obsolètes (comme le prix ou la disponibilité d'un produit).
C'est précisément pourquoi aucun site Web de commerce électronique majeur n'utilise SSG.
C'est un fait que sous une connexion Internet rapide, la RSE et le SSR fonctionnent très bien (tant qu'elles sont toutes deux optimisées), et plus la vitesse de connexion est élevée - plus elles se rapprochent en termes de temps de chargement.
Cependant, lorsqu'il s'agit de connexions lentes (comme les réseaux mobiles), il semble que SSR ait un avantage sur la RSE concernant les temps de chargement.
Étant donné que les applications SSR sont rendues sur le serveur, le navigateur reçoit le fichier HTML entièrement construit, et il peut donc afficher la page à l'utilisateur sans attendre que JS puisse télécharger. Lorsque JS est finalement téléchargé et analysé, le cadre est capable de "hydrater" le DOM avec les fonctionnalités (sans avoir à la reconstruire).
Bien que cela semble être un gros avantage, ce comportement introduit un effet secondaire indésirable, en particulier sur les connexions plus lentes:
Jusqu'à ce que JS soit chargé, les utilisateurs peuvent cliquer où ils le souhaitent, mais l'application ne réagira à aucun de leurs événements basés sur JS.
Il s'agit d'une mauvaise expérience utilisateur lorsque les boutons ne répondent pas aux interactions utilisateur, mais cela devient un problème beaucoup plus important lorsque les événements par défaut ne sont pas évités.
Ceci est une comparaison entre le site Web de Next.js et notre application de rendu côté client sur une connexion 3G rapide:
Que s'est-il passé ici?
Étant donné que JS n'a pas encore été chargé, le site Web de Next.js n'a pas pu empêcher le comportement par défaut des éléments de balise d'ancrage ( <a> ) pour accéder à une autre page, ce qui entraîne chaque clic sur eux déclenchant un rechargement complet.
Et plus la connexion est lente - plus ce problème devient grave.
En d'autres termes, où SSR aurait dû avoir un avantage de performance sur la RSE, nous voyons un comportement très "dangereux" qui pourrait dégrader considérablement l'expérience utilisateur.
Il est impossible que ce problème se produise dans les applications CSR, depuis le moment où ils rendent - JS a déjà été entièrement chargé.
Nous avons vu que les performances de rendu côté client sont au pair et parfois encore mieux que la RSS en termes de temps de chargement initiaux (et le dépasse de loin en temps de navigation).
Nous avons également vu que Googlebot peut parfaitement indexer les applications de rendu de côté client et que nous pouvons facilement configurer un serveur de prérenrend pour servir tous les autres robots et robots.
Et surtout, nous avons réalisé tout cela simplement en ajoutant quelques fichiers et en utilisant un service PERENDEN, de sorte que chaque application CSR existante devrait être en mesure d'implémenter rapidement et facilement ces changements et d'en bénéficier.
Ces faits conduisent à la conclusion qu'il n'y a aucune raison impérieuse d'utiliser la SSR. Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


