client side rendering
1.0.0
Este proyecto es un estudio de caso de RSE, explora el potencial de las aplicaciones renderizadas del lado del cliente en comparación con la representación del lado del servidor.
Se puede encontrar una comparación en profundidad de todos los métodos de representación en la página de comparación de este proyecto: https://client-side-rendering.pages.dev/comparison
La representación del lado del cliente (CSR) se refiere a enviar activos estáticos al navegador web y permitirle manejar todo el proceso de representación de la aplicación.
La representación del lado del servidor (SSR) implica la representación completa de la aplicación (o página) completa en el servidor y entrega un documento HTML previamente renderizado listo para la visualización.
La generación de sitios estática (SSG) es el proceso de las páginas HTML previas a la generación como activos estáticos, que luego son enviados y mostrados por el navegador.
Contrariamente a la creencia común, el proceso de SSR en marcos modernos como React , Angular , Vue y Svelte da como resultado que la aplicación representa dos veces: una vez en el servidor y nuevamente en el navegador (esto se conoce como "hidratación"). Sin este segundo render, la aplicación sería estática e ininterable, esencialmente comportarse como una página web "sin vida".
Curiosamente, el proceso de hidratación no parece ser más rápido que un render típico (excluyendo la fase de pintura, por supuesto).
También es importante tener en cuenta que las aplicaciones SSG también deben someterse a una hidratación.
Tanto en SSR como en SSG, el documento HTML está completamente construido, proporcionando los siguientes beneficios:
Por otro lado, las aplicaciones de CSR ofrecen las siguientes ventajas:
En este estudio de caso, nos centraremos en la RSE y exploraremos formas de superar sus limitaciones aparentes al tiempo que aprovecha sus fortalezas hasta el pico.
Todas las optimizaciones se incorporarán a la aplicación implementada, que se puede encontrar aquí: https://client-side-rendering.pages.dev.
"Recientemente, SSR (Renderización del lado del servidor) ha tomado el mundo front-end de JavaScript por asalto. El hecho de que ahora pueda hacer que sus sitios y aplicaciones en el servidor los envíen a sus clientes es una idea absolutamente revolucionaria (y no es lo que todos estaban haciendo antes de que las aplicaciones del lado del cliente JS se hicieran populares en primer lugar ...).).
Sin embargo, las mismas críticas que fueron válidas para PHP, ASP, JSP, (y tales) sitios son válidas para la representación del lado del servidor hoy. Es lento, se rompe con bastante facilidad y es difícil de implementar correctamente.
La cosa es que, a pesar de lo que todos podrían estar diciéndole, probablemente no necesite SSR. Puede obtener casi todas las ventajas (sin las desventajas) utilizando el prevenimiento ".
~ Complemento de spa prerender
En los últimos años, la representación del lado del servidor ha ganado una popularidad significativa en forma de marcos como Next.js y Remix hasta el punto de que los desarrolladores a menudo se ajustan a usarlos sin comprender completamente sus limitaciones, incluso en aplicaciones que no necesitan SEO (por ejemplo, aquellos con requisitos de inicio de sesión).
Si bien SSR tiene sus ventajas, estos marcos continúan enfatizando su velocidad ("rendimiento como predeterminado"), lo que sugiere que la representación del lado del cliente (CSR) es inherentemente lenta.
Además, existe una idea errónea generalizada de que el SEO perfecto solo se puede lograr con SSR, y que las aplicaciones de RSE no pueden optimizarse para los rastreadores de motores de búsqueda.
Otro argumento común para la SSR es que a medida que las aplicaciones web se hacen más grandes, sus tiempos de carga continuarán aumentando, lo que lleva a un bajo rendimiento de FCP para las aplicaciones de CSR.
Si bien es cierto que las aplicaciones se están volviendo más ricas en funciones, el tamaño de una sola página debería disminuir con el tiempo.
Esto se debe a la tendencia de crear versiones más pequeñas y eficientes de bibliotecas y marcos, como Zustand , Day.js , Headless-UI y React-Router V6 .
También podemos observar una reducción en el tamaño de los marcos a lo largo del tiempo: angular (74.1kb), reaccionar (44.5kb), Vue (34kb), sólido (7.6kb) y SVVELT (1.7kb).
Estas bibliotecas contribuyen significativamente al peso total de los scripts de una página web.
Con la división adecuada del código, el tiempo de carga inicial de una página podría disminuir con el tiempo.
Este proyecto implementa una aplicación CSR básica con optimizaciones como la división de código y la precarga. El objetivo es que el tiempo de carga de las páginas individuales permanezca estable a medida que la aplicación escala.
El objetivo es simular la estructura de paquetes de una aplicación de grado de producción y minimizar los tiempos de carga a través de solicitudes paralelizadas.
Es importante tener en cuenta que mejorar el rendimiento no debe tener el costo de la experiencia del desarrollador. Por lo tanto, la arquitectura de este proyecto solo se modificará ligeramente a partir de una configuración de React típica, evitando la estructura rígida y obstinada de marcos como Next.js, o las limitaciones de SSR en general.
Este estudio de caso se centrará en dos aspectos principales: rendimiento y SEO. Exploraremos cómo lograr los mejores puntajes en ambas áreas.
Tenga en cuenta que aunque este proyecto se implementa utilizando React, la mayoría de las optimizaciones son agnósticas marco y se basan puramente en el Bundler y el navegador web.
Asumiremos una configuración de Webpack estándar (RSPack) y agregaremos las personalizaciones requeridas a medida que avanzamos.
La primera regla general es minimizar las dependencias y, entre ellas, elegir las que tienen los tamaños de archivo más pequeños.
Por ejemplo:
Podemos usar Day.js en lugar de Momento , Zustand en lugar de Redux Toolkit , etc.
Esto es importante no solo para las aplicaciones de CSR sino también para las aplicaciones SSR (y SSG), ya que los paquetes más grandes dan como resultado tiempos de carga más largos, retrasando cuando la página se vuelve visible o interactiva.
Idealmente, cada archivo hash debe almacenarse en caché, y index.html nunca debe almacenarse en caché.
Significa que el navegador inicialmente caché main.[hash].js y tendría que descargarlo solo si su hash (contenido) cambia:

Sin embargo, dado que main.js incluye todo el paquete, el más mínimo cambio en el código haría que su caché expire, lo que significa que el navegador tendría que descargarlo nuevamente.
Ahora, ¿qué parte de nuestro paquete comprende la mayor parte de su peso? La respuesta son las dependencias , también llamadas proveedores .
Entonces, si pudiéramos dividir a los proveedores en su propio trozo de hash, eso permitiría una separación entre nuestro código y el código de proveedores, lo que lleva a menos invalidaciones de caché.
Agregamos la siguiente optimización a nuestro archivo de configuración:
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
} Esto creará un vendors.[hash].js archivo:

Aunque esta es una mejora sustancial, ¿qué pasaría si actualizamos una dependencia muy pequeña?
En tal caso, el caché de los proveedores completos invalidará.
Entonces, para mejorarlo aún más, dividiremos cada dependencia en su propio trozo de hash:
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ } Esto creará archivos como react-dom.[hash].js que contienen un solo proveedor grande y un [id].[hash].js Archivo que contiene todos los proveedores restantes (pequeños):
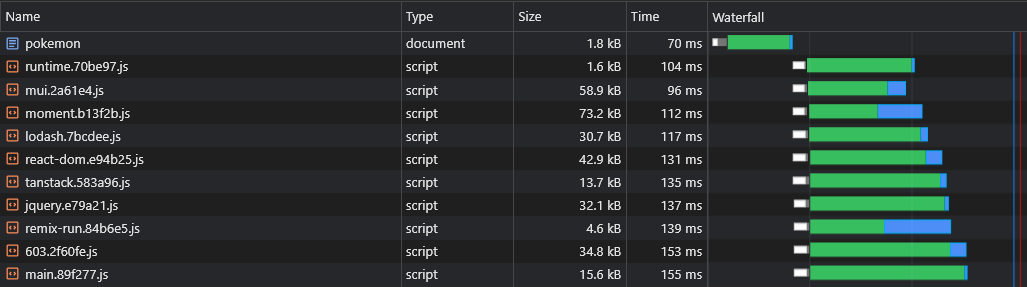
Puede encontrar más información sobre las configuraciones predeterminadas (como el tamaño del umbral dividido) aquí:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
Muchas de las características que escribimos terminan utilizándose solo en algunas de nuestras páginas, por lo que nos gustaría que se carguen solo cuando el usuario visita la página en la que se está utilizando.
Por ejemplo, no quisiéramos que los usuarios tengan que esperar hasta que el paquete React-Big-Calendar se descargue, analice y ejecute si simplemente cargaron la página de inicio . Solo quisiéramos que eso suceda cuando visiten la página del calendario .
La forma en que podemos lograr esto es (preferiblemente) mediante la división de código basado en la ruta:
App.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) ) Entonces, cuando los usuarios visitan la página de Pokémon , solo descargan los scripts de fragmentos principales (que incluye todas las dependencias compartidas, como el marco) y el pokemon.[hash].js fragmentando.
Nota: Se alienta a descargar toda la aplicación para que los usuarios experimenten navegaciones instantáneas, similares a la aplicación. Pero es una mala idea agrupar todos los activos en un solo script, retrasando el primer render de la página.
Estos activos deben descargarse de forma asincrónica y solo después de que la página solicitada por el usuario haya terminado de representar y es completamente visible.
La división del código tiene un defecto importante: el tiempo de ejecución no sabe qué fragmentos de asíncea se necesitan hasta que el script principal se ejecuta, lo que lleva a que se obtengan en un retraso significativo (ya que hacen otro viaje redondo al CDN):

La forma en que podemos resolver este problema es escribir un complemento personalizado que incrustará un script en el documento que será responsable de la precarga de los activos relevantes:
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}scripts/inyect-assets-plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginscripts/precarga-assets.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( ) El archivo de pages.js importado se puede encontrar aquí.
De esta manera, el navegador puede obtener el fragmento de script específico de la página en paralelo con activos críticos de renderizado:
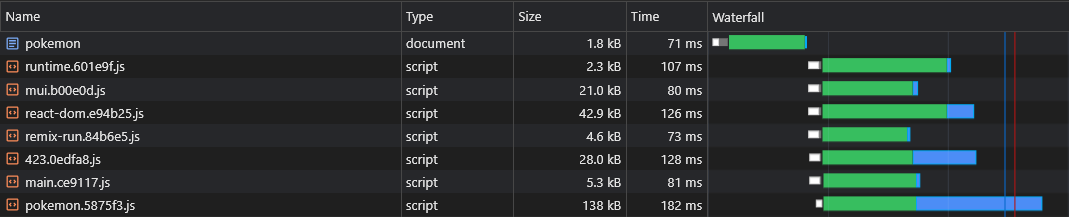
La división del código introduce otro problema: la duplicación del proveedor de async.
Digamos que tenemos dos trozos de asíncrono: lorem-ipsum.[hash].js y pokemon.[hash].js . Si ambos incluyen la misma dependencia que no es parte de la fragmentación principal, eso significa que el usuario descargará esa dependencia dos veces .
Entonces, si eso se dice que la dependencia es moment y pesa 72 kb minzipped, entonces el tamaño del trozo de async será de al menos 72 kb.
Necesitamos dividir esta dependencia de estos fragmentos de asíncrono para que pueda compartirse entre ellos:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
} Ahora tanto lorem-ipsum.[hash].js como pokemon.[hash].js usará el moment.[hash].js fragmentando, ahorrando al usuario mucho tráfico de red (y le da a estos activos una mejor persistencia de caché).
Sin embargo, no tenemos forma de decir qué fragmentos de proveedores de asíncrono se dividirán antes de construir la aplicación, por lo que no sabríamos qué trozos de proveedor de asíncrono necesitamos precargar (consulte la sección "Trozos asíncronos de precarga"):
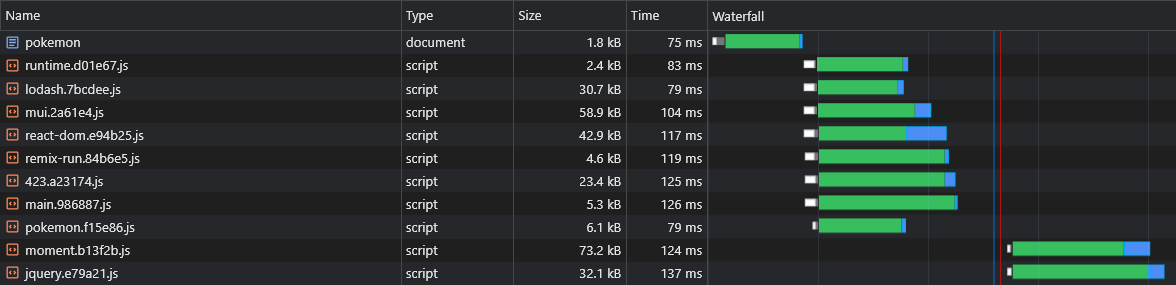
Es por eso que agregaremos los nombres de los fragmentos al nombre del proveedor async:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}scripts/inyect-assets-plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}scripts/precarga-assets.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ })Ahora todos los trozos de proveedores asíncronos se obtendrán en paralelo con su trozo de async de padres:
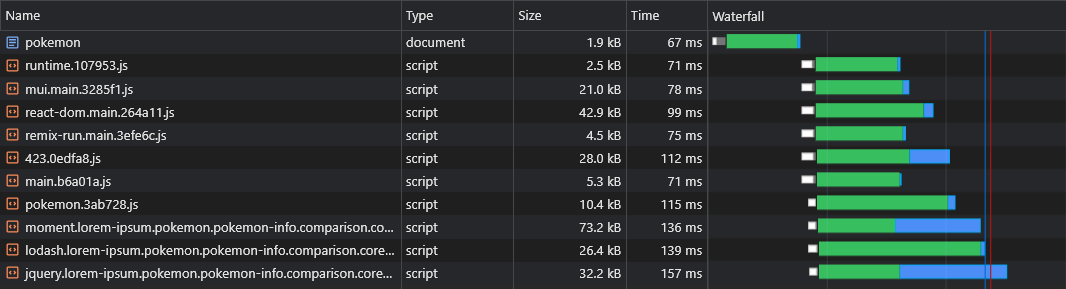
Una de las presuntas desventajas de la RSE sobre SSR es que los datos de la página (solicitudes de búsqueda) se dispararán solo después de que JS haya sido descargado, analizado y ejecutado en el navegador:
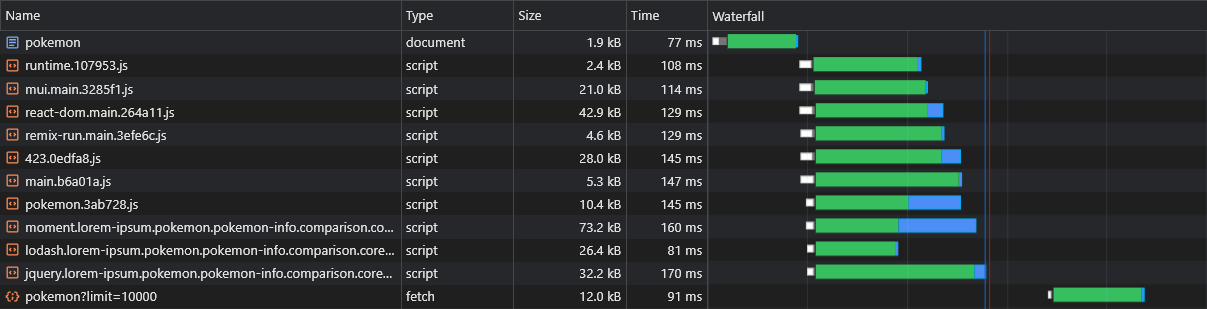
Para superar esto, usaremos la precarga una vez más, esta vez para los datos en sí, al parchear la API fetch :
scripts/inyect-assets-plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})scripts/precarga-assets.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets() Recordatorio: el archivo pages.js se puede encontrar aquí.
Ahora podemos ver que los datos se están obteniendo de inmediato:
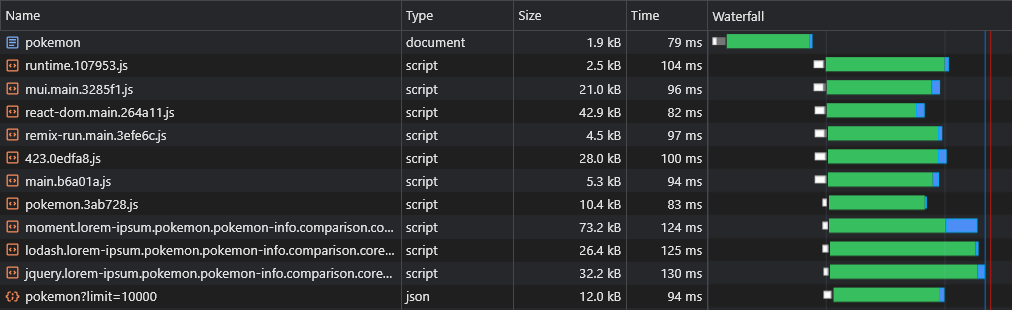
Con el script anterior, incluso podemos precargar los datos de rutas dinámicas (como Pokemon/: Nombre ).
Los usuarios deben tener una experiencia de navegación sin problemas en nuestra aplicación.
Sin embargo, dividir cada página provoca un retraso notable en la navegación, ya que cada página debe descargarse (bajo demanda) antes de que pueda ser representada en la pantalla.
Nos gustaría prevenir y almacenar en caché todas las páginas con anticipación.
Podemos hacer esto escribiendo un trabajador de servicio simple:
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}SRC/Utils/Service-Worker-Registration.ts
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}Public/Service-Worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Ahora todas las páginas serán prevenidas y almacenadas en caché incluso antes de que el usuario intente navegar hacia ellas.
Este enfoque también generará un caché de código completo.
Al inspeccionar nuestro archivo de 43kb react-dom.js , podemos ver que el tiempo que tomó para la solicitud de regresar fue de 60 ms, mientras que el tiempo que tardó en descargar el archivo fue de 3 ms:

Esto demuestra el hecho bien conocido de que RTT tiene un gran impacto en los tiempos de carga de las páginas web, a veces incluso más que la velocidad de descarga, e incluso cuando los activos se sirven desde un borde CDN cercano como en nuestro caso.
Además y, lo que es más importante, podemos ver que después de descargar el archivo HTML, tenemos un gran tiempo de tiempo donde el navegador permanece inactivo y solo espera a que lleguen los scripts:
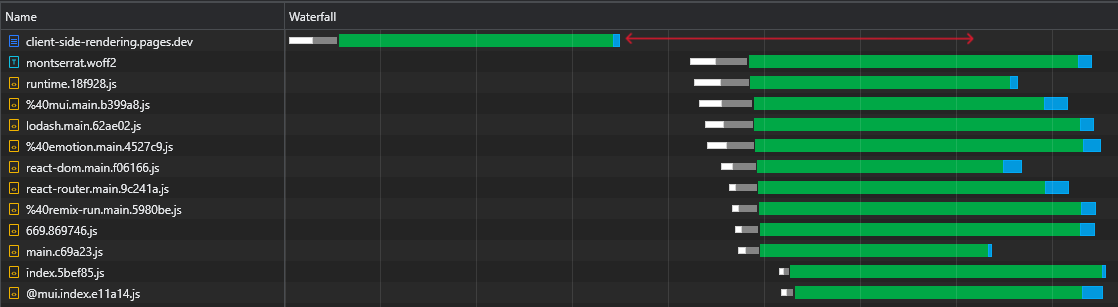
Este es mucho tiempo precioso (marcado en rojo) que el navegador podría usar para descargar, analizar e incluso ejecutar scripts, acelerando la visibilidad e interactividad de la página.
Esta ineficiencia volverá a ocurrir cada vez que cambien los activos (caché parcial). Esto no es algo que solo suceda en la primera visita.
Entonces, ¿cómo podemos eliminar este tiempo de inactividad?
Podríamos en línea todos los scripts iniciales (críticos) en el documento, para que comiencen a descargar, analizar y ejecutar hasta que lleguen los activos de la página Async:

Podemos ver que el navegador ahora recibe sus scripts iniciales sin tener que enviar otra solicitud al CDN.
Por lo tanto, el navegador primero enviará solicitudes para los fragmentos de Async y los datos precargados, y aunque estos están pendientes, continuará descargando y ejecutando los scripts principales.
Podemos ver que los fragmentos de Async comienzan a descargar (marcados en azul) justo después de que el archivo HTML termine de descargar, analizar y ejecutar, lo que ahorra mucho tiempo.
Si bien este cambio está marcando una diferencia significativa en las redes rápidas, es aún más crucial para las redes más lentas, donde el retraso es mayor y el RTT es mucho más impactante.
Sin embargo, esta solución tiene 2 problemas principales:
Para superar estos problemas, ya no podemos atenerse a un archivo HTML estático, por lo que levortamos la potencia de un servidor. O, más precisamente, el poder de un trabajador sin servidor de CloudFlare.
Este trabajador debe interceptar cada solicitud de documento HTML y adaptar una respuesta que se ajuste perfectamente.
Todo el flujo debe describirse de la siguiente manera:
X-Cached en la solicitud. Si existe dicho encabezado, iterará sobre sus valores y en línea solo los activos* relevantes* que están ausentes de él en la respuesta. Si dicho encabezado no existe, en línea todos los activos* relevantes* en la respuesta.X-Cached que especifica todos sus activos en caché.* Activos iniciales y específicos de la página.
¡Esto asegura que el navegador reciba exactamente los activos que necesita (no más, nada menos) para mostrar la página actual en un solo ida y vuelta !
scripts/inyect-assets-plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpúblico/_Worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src/utils/extracto-inline-scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptsSRC/Utils/Service-Worker-Registration.ts
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}Public/Service-Worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Los resultados para una carga fresca (completamente sin inclinar) son excepcionales:

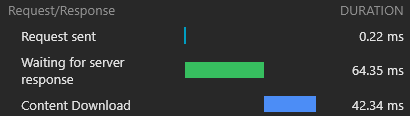

En la siguiente carga, el trabajador de CloudFlare responde con un documento HTML mínimo (1.8kb) y todos los activos se cumplen inmediatamente desde el caché.
Esta optimización nos lleva a otro: dividir trozos a piezas aún más pequeñas.
Como regla general, dividir el paquete en demasiados trozos puede dañar el rendimiento. Esto se debe a que la página no se representará hasta que se descarguen todos sus archivos, y cuanto más fragmentos hay, mayor será la probabilidad de que uno de ellos se retrase (ya que el hardware y la velocidad de la red no son lineales).
Pero en nuestro caso es irrelevante, ya que en línea todos los trozos relevantes y, por lo tanto, son recortados de una vez.
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},Esta división extrema conducirá a una mejor persistencia de caché y, a su vez, a tiempos de carga más rápidos con caché parcial.
Cuando se obtiene un activo estático de un CDN, incluye un encabezado ETag , que es un hash de contenido del recurso. En las solicitudes posteriores, el navegador verifica si tiene un ETAG almacenado. Si lo hace, envía el Etag en un encabezado If-None-Match . El CDN luego compara el ETAG recibido con el actual: si coinciden, devuelve un estado 304 Not Modified , lo que indica que el navegador puede usar el activo en caché; Si no, devuelve el nuevo activo con un estado 200 .
En una aplicación tradicional de CSR, la recarga de una página da como resultado que el HTML obtenga un 304 Not Modified , con otros activos atendidos del caché. Cada ruta tiene un ETAG único, SO /lorem-ipsum y /pokemon tienen diferentes entradas de caché, incluso si sus Etag son idénticas.
En un SPA CSR, dado que solo hay un archivo HTML, se usa el mismo ETAG para cada solicitud de página. Sin embargo, debido a que el ETAG se almacena por ruta, el navegador no enviará un encabezado If-None-Match para páginas no visitadas, lo que lleva a un estado 200 y una descarga de HTML, a pesar de que es el mismo archivo.
Sin embargo, podemos crear fácilmente nuestra propia implementación (mejorada) de este comportamiento a través de la colaboración entre los trabajadores:
scripts/inyect-assets-plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}público/_Worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}Public/Service-Worker.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} Tenga en cuenta que se incluye un X-ETag personalizado para situaciones en las que el CDN no envía automáticamente un ETag .
Ahora nuestro trabajador sin servidor siempre responderá con un código de estado 304 Not Modified cuando no haya cambios, incluso para páginas no visitadas.
Cuando se utiliza un trabajador de servicio, el navegador retrasa que envían la solicitud de documento HTML inicial hasta que se cargue el trabajador de servicio, lo que puede causar un retraso de página ligera a moderada dependiendo del hardware.
La solución nativa a este problema se llama precarga de navegación . Implementaremos esto para garantizar que la solicitud de documento se envíe de inmediato, sin esperar a que el trabajador del servicio cargue:
SRC/Utils/Service-Worker-Registration.ts
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}Public/Service-Worker.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Con esta implementación, la solicitud de documento se enviará inmediatamente, independientemente del trabajador de servicio.
Nota: requiere reaccionar (v18), esbelte o solid.js
Cuando dividimos una página de la aplicación principal, separamos su fase de renderizado, lo que significa que la aplicación se convertirá antes de que la página se presente.
Entonces, cuando nos movemos de una página de asíncrata a otra, vemos un espacio en blanco que permanece hasta que la página se represente:
Esto sucede debido al enfoque común de envolver solo las rutas con suspenso:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18 nos introdujo al gancho useTransition , lo que nos permite retrasar un renderizado hasta que se cumplan algunos criterios.
Usaremos este gancho para retrasar la navegación de la página hasta que esté lista:
usransitionnavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkAhora las páginas de Async sentirán que nunca se dividieron de la aplicación principal.
Podemos precargar otras páginas datos al pasar el rondado de enlaces (escritorio) o cuando los enlaces ingresan a la vista (móvil):
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >Tenga en cuenta que esto puede cargar innecesariamente el servidor API.
Algunos usuarios dejan la aplicación abierta por períodos prolongados de tiempo, por lo que otra cosa que podemos hacer es revalidar (descargar nuevos activos de) la aplicación mientras se ejecuta:
servicio-trabajador-registro.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}El código anterior revalúa la aplicación cada hora.
El proceso de revalidación es extremadamente barato, ya que solo implica volver a colocar al trabajador de servicio (que devolverá un código de estado no modificado 304 si no se cambia).
Cuando el trabajador del servicio cambia , significa que hay nuevos activos disponibles, por lo que se descargarán y almacenarán selectivamente.
Dividimos nuestro paquete en muchos trozos pequeños, mejorando enormemente las habilidades de almacenamiento en caché de nuestra aplicación.
Dividimos cada página para que al cargar una, solo lo relevante se descarga de inmediato.
Hemos logrado hacer que la carga inicial (sin caché) de nuestra aplicación sea extremadamente rápida, todo lo que una página requiere cargar se inyecta dinámicamente.
Incluso precaremos los datos de la página, eliminando los famosos datos que obtienen una cascada que se sabe que tienen aplicaciones de RSE.
Además, precoltan todas las páginas, lo que hace que parezca que nunca se dividieron del código principal del paquete.
Todos estos se lograron sin comprometer la experiencia del desarrollador y sin dictar qué marco JS elegir.
La mayor ventaja de una aplicación estática es que se puede servir completamente de un CDN.
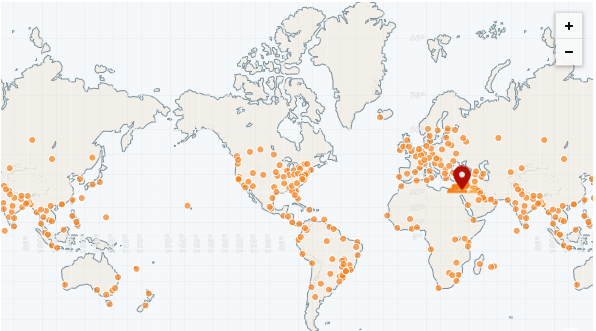
Un CDN tiene muchos POP (puntos de presencia), también llamados "redes de borde". Estos POP se distribuyen en todo el mundo y, por lo tanto, pueden servir archivos a cada región mucho más rápido que un servidor remoto.
El CDN más rápido hasta la fecha es CloudFlare, que tiene más de 250 POP (y contando):
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-edge-network-performance
Podemos implementar fácilmente nuestra aplicación usando las páginas de CloudFlare:
https://pages.cloudflare.com
Para concluir esta sección, realizaremos un punto de referencia de nuestra aplicación en comparación con el sitio de documentación de Next.js , que es completamente SSG .
Compararemos la página de accesibilidad minimalista con nuestra página Lorem Ipsum . Ambas páginas incluyen ~ 246kb de JS en sus fragmentos críticos de renderizado (precargas y prevenidas que vienen después son irrelevantes).
Puede hacer clic en cada enlace para realizar un punto de referencia en vivo.
Accesibilidad | Next.js
Lorem ipsum | Representación del lado del cliente
Realicé el punto de referencia de PageSpeed Insights de Google (simulando una red 4G lenta) unas 20 veces para cada página y elegí el puntaje más alto.
Estos son los resultados:
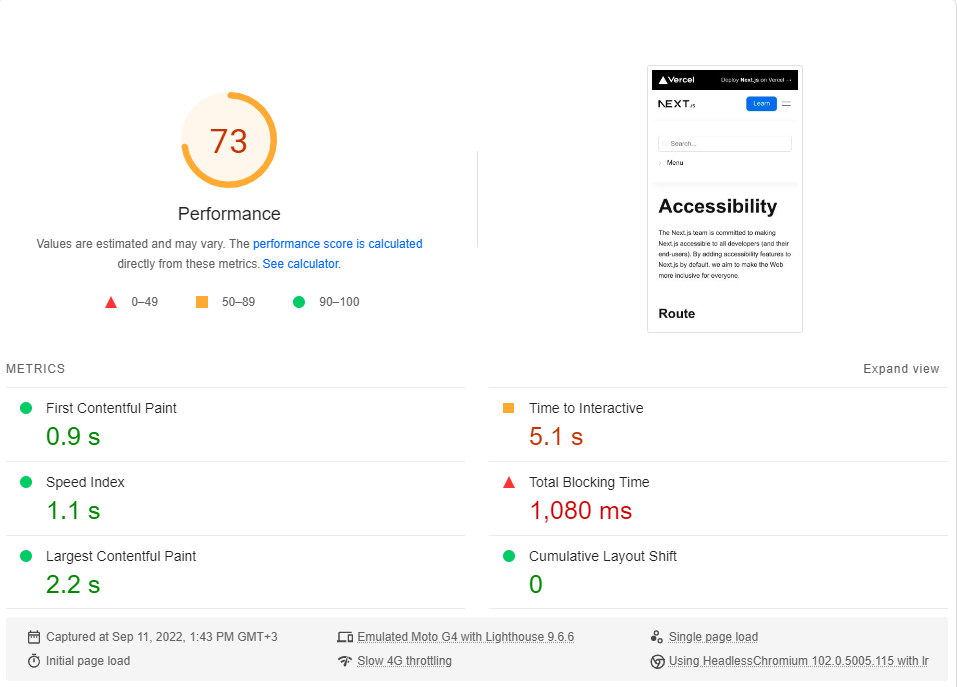
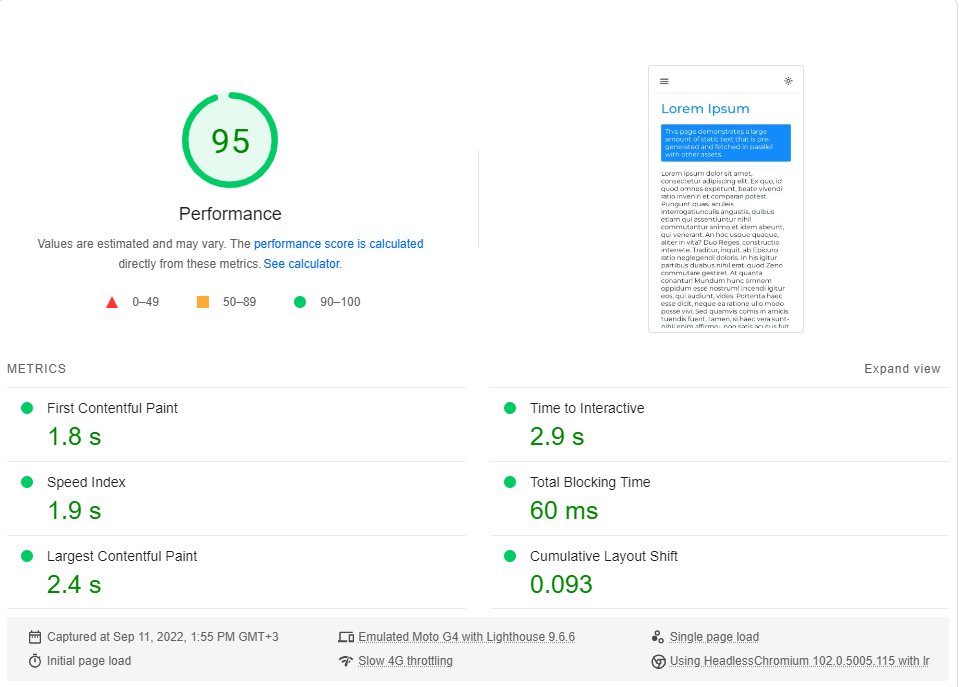
Resulta que el rendimiento no es un valor predeterminado en Next.js.
Tenga en cuenta que este punto de referencia solo prueba la primera carga de la página, sin siquiera considerar cómo funciona la aplicación cuando está completamente almacenado en caché (donde realmente brilla la RSE).
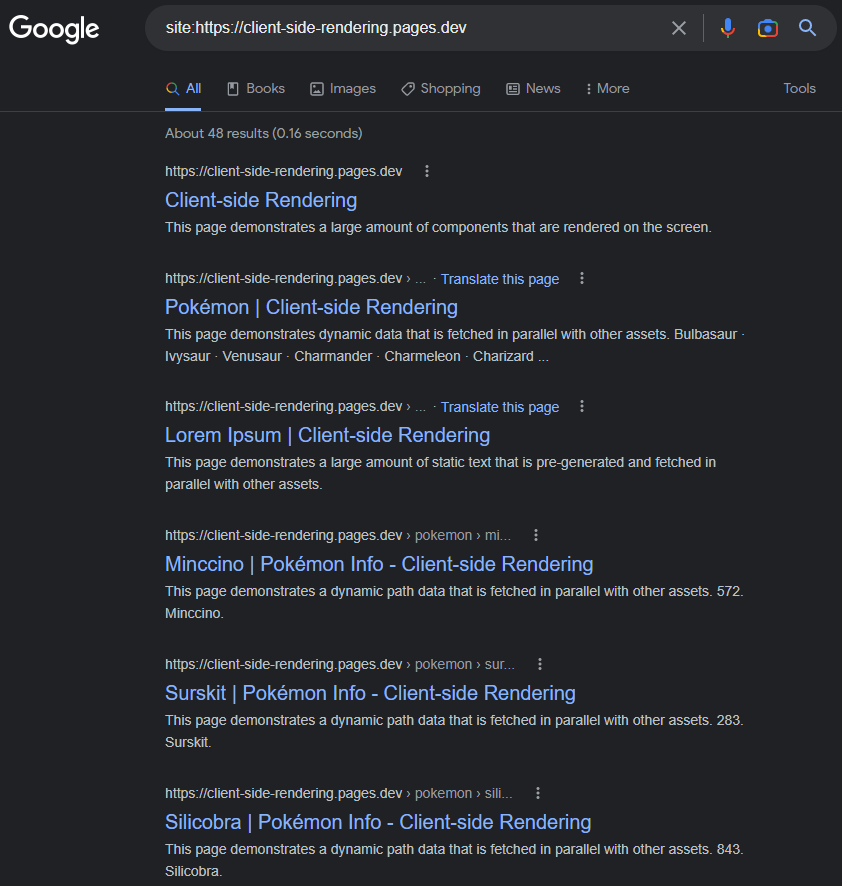
Es una incrustación común que Google está teniendo problemas para indexar adecuadamente las aplicaciones de CSR (JS).
Ese podría haber sido el caso en 2017, pero a partir de hoy: Google indexa las aplicaciones de RSE en su mayoría sin problemas.
Las páginas indexadas tendrán un título, descripción, contenido y todos los demás atributos relacionados con el SEO, siempre que recordemos establecerlos dinámicamente (ya sea manualmente así o usando un paquete como React-Helmet ).
https://www.google.com/search?q=site:https://client-side-rendering.pages.dev
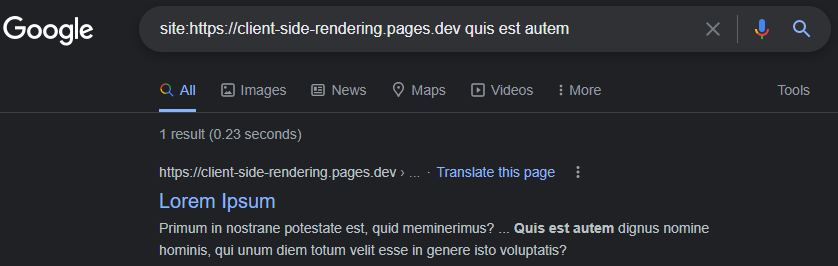
La capacidad de Googlebot, el render JS se puede demostrar fácilmente realizando una prueba de URL en vivo de nuestra aplicación en la consola de búsqueda de Google :
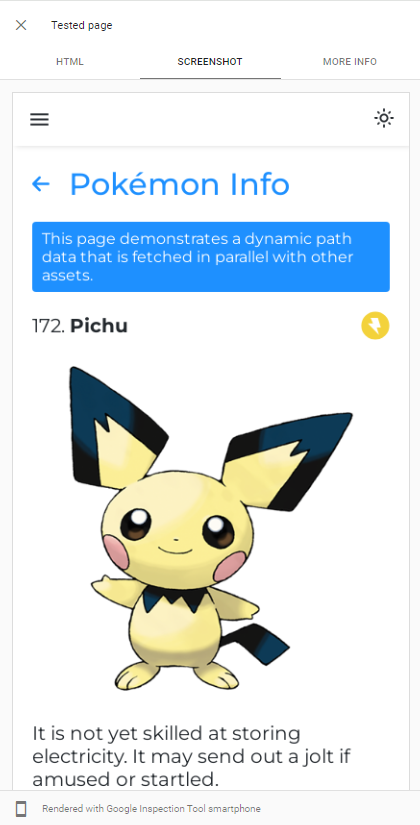
GoogleBot utiliza la última versión de Chromium para rastrear aplicaciones, por lo que lo único que debemos hacer es asegurarnos de que nuestra aplicación se cargue rápidamente y que sea rápida para obtener datos.
Incluso cuando los datos tardan mucho tiempo en buscar, Googlebot, en la mayoría de los casos, lo esperará antes de tomar una instantánea de la página:
https://support.google.com/webmasters/thread/202552760/for-how-long-does-googlebot-weit-for-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
Aquí se puede encontrar una explicación detallada del proceso JS Grawling de Googlebot:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
Si GoogleBot no rinde algunas páginas, se debe principalmente a la falta de voluntad de Google para gastar los recursos requeridos para rastrear el sitio web, lo que significa que tiene un presupuesto de bajo rastreo .
Esto se puede confirmar inspeccionando la página rastreada (haciendo clic en la página de rastreo de la vista en la consola de búsqueda) y asegurándose de que todas las solicitudes fallidas tengan la otra alerta de error (lo que significa que esas solicitudes fueron abortadas intencionalmente por Googlebot):
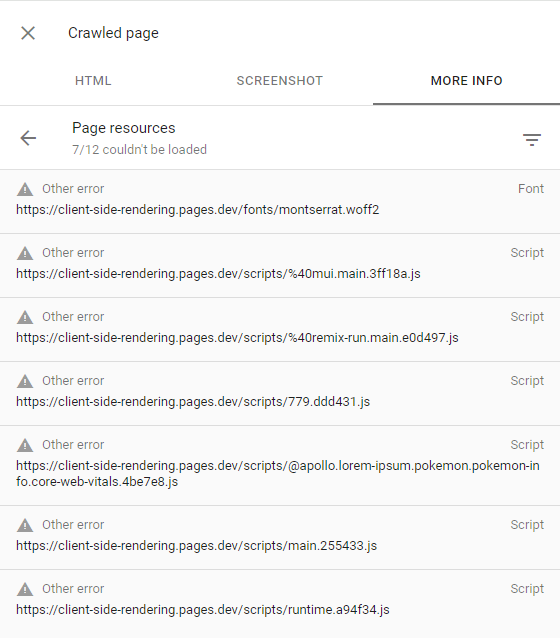
Esto solo debería suceder a los sitios web que Google considera que no tiene contenido interesante o tiene un tráfico muy bajo (como nuestra aplicación de demostración).
Puede encontrar más información aquí: https://support.google.com/webmasters/thread/4425254?hl=en&msgid=4426601
Otros motores de búsqueda como Bing no pueden renderizar JS, por lo que para que rastreen nuestra aplicación correctamente, necesitamos servirles la versión prerenderizada de nuestras páginas.
La preenderse es el acto de rastrear aplicaciones web en producción (utilizando cromo sin cabeza) y generar un archivo HTML completo (con datos) para cada página.
Tenemos dos opciones cuando se trata de prevender:
El preenderado sin servidor es el enfoque recomendado ya que puede ser muy barato, especialmente en GCP .
Luego redirigimos los rastreadores web (identificados por su cadena de encabezado User-Agent ) a nuestro prerenderer, utilizando un trabajador de CloudFlare (por ejemplo):
público/_Worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
} Aquí hay una lista actualizada de todas las Agnets BOT (rastreadores web): https://docs.perender.io/docs/how-to-add-additional-bots#cloudflare. Recuerde excluir googlebot de la lista.
Microsoft fomenta el prevenimiento , también llamado Rendering Dynamic , y es muy utilizado por muchos sitios web populares, incluido Twitter.
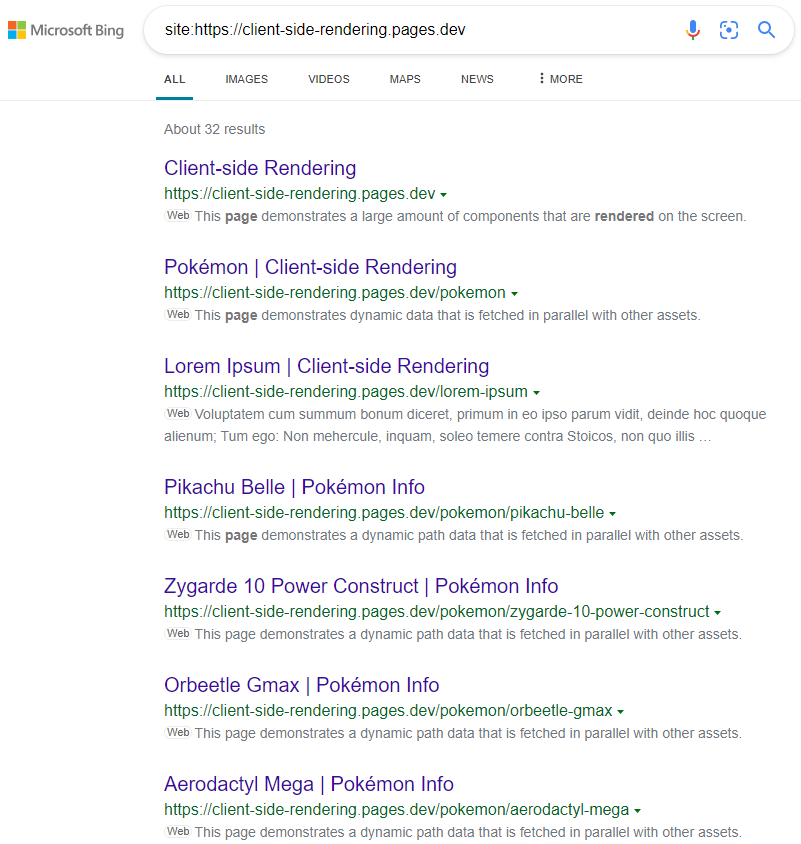
Los resultados son los esperados:
https://www.bing.com/search?q=Site%3AHTTPS%3A%2F%2Fclient-Side-Rendering.pages.dev
Tenga en cuenta que al usar CSS-in-JS, podemos deshabilitar la optimización rápida durante el preventaje si queremos que nuestros estilos se omitan al DOM.
Cuando compartimos un enlace de la aplicación CSR en las redes sociales, podemos ver que sin importar a qué página vinculemos, la vista previa seguirá siendo la misma.
Esto sucede porque la mayoría de las aplicaciones de CSR solo tienen un archivo HTML sin contenido, y los rastreadores de redes sociales no renderizan JS.
Aquí es donde el preventor viene a nuestra ayuda una vez más, generará la vista previa de acciones adecuada para cada página:
WhatsApp:
Facebook :
Para hacer que todas las páginas de nuestras aplicaciones sean descubiertas para los motores de búsqueda, se recomienda crear un archivo sitemap.xml que especifique todas las rutas de nuestro sitio web.
Dado que ya tenemos un archivo centralizado de páginas.js , podemos generar fácilmente un mapa del sitio durante el tiempo de compilación:
create-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )Esto emitirá el siguiente mapa del sitio:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >Podemos enviar manualmente nuestro mapa del sitio a Google Search Console y Bing Webmaster Tools .
Como se mencionó anteriormente, se puede encontrar una comparación en profundidad de todos los métodos de renderizado aquí: https://client-side-rendering.pages.dev/comparison
Hemos visto las ventajas de los archivos estáticos: se pueden almacenar en caché y se pueden servir desde un CDN cercano sin requerir un servidor.
Esto podría llevarnos a creer que SSG combina los beneficios de CSR y SSR: hace que nuestra aplicación se cargue visualmente muy rápido ( FCP ) e independientemente de los tiempos de respuesta de nuestro servidor API.
Sin embargo, en realidad, SSG tiene una gran limitación:
Dado que JS no está activo durante los momentos iniciales, todo lo que se basa en JS para presentarse simplemente no será visible o se mostrará incorrectamente (como los componentes que dependen de la window.matchMedia .
Se puede ver un ejemplo clásico de este problema en el siguiente sitio web:
https://death-to-ie11.com
¿Observe cómo el temporizador no es visible de inmediato? Esto se debe a que es generado por JS, que lleva tiempo descargar y ejecutar.
También vemos un problema similar al actualizar la página 'Guías' de Verconcel con algunos filtros aplicados:
https://vercel.com/guides?topics=analytics
Esto sucede porque hay 65536 (2^16) posibles combinaciones de filtros, y almacenar cada combinación como un archivo HTML separado requeriría mucho almacenamiento del servidor.
Por lo tanto, generan un solo archivo guides.html que contiene todos los datos, pero este archivo estático no sabe qué filtros se aplican hasta que se carga JS, causando un cambio de diseño.
Es importante tener en cuenta que incluso con una regeneración estática incremental , los usuarios aún tendrán que esperar una respuesta del servidor cuando visiten páginas que aún no se han almacenado en caché (al igual que en la SSR).
Otro ejemplo de este problema son las animaciones JS: pueden parecer estáticas inicialmente y solo comienzan a animar una vez que JS está cargado.
Hay muchos casos en los que esta funcionalidad retrasada perjudica la experiencia del usuario, como cuando los sitios web solo muestran la barra de navegación después de que JS está cargada (ya que confían en el almacenamiento local para verificar si existe una entrada de información del usuario).
Otro problema crítico, especialmente para los sitios web de comercio electrónico, es que las páginas SSG pueden mostrar datos obsoletos (como el precio o la disponibilidad de un producto).
Esta es precisamente la razón por la cual ningún sitio web importante de comercio electrónico utiliza SSG.
Es un hecho que bajo una conexión rápida a Internet, tanto la RSE como la SSR funcionan muy bien (siempre que ambos estén optimizados), y cuanto mayor sea la velocidad de conexión, más cerca se acercan en términos de tiempos de carga.
Sin embargo, cuando se trata de conexiones lentas (como las redes móviles), parece que la SSR tiene una ventaja sobre la RSE con respecto a los tiempos de carga.
Dado que las aplicaciones SSR se representan en el servidor, el navegador recibe el archivo HTML totalmente construido, por lo que puede mostrar la página al usuario sin esperar a que JS se descargue. Cuando JS finalmente se descarga y analiza, el marco puede "hidratar" el DOM con la funcionalidad (sin tener que reconstruirlo).
Aunque parece una gran ventaja, este comportamiento introduce un efecto secundario no deseado, especialmente en conexiones más lentas:
Hasta que se cargue JS, los usuarios pueden hacer clic en cualquiera que deseen, pero la aplicación no reacciona a ninguno de sus eventos basados en JS.
Es una mala experiencia del usuario cuando los botones no responden a las interacciones del usuario, pero se convierte en un problema mucho mayor cuando los eventos predeterminados no se evitan.
Esta es una comparación entre el sitio web de Next.js y nuestra aplicación de representación del lado del cliente en una conexión 3G rápida:
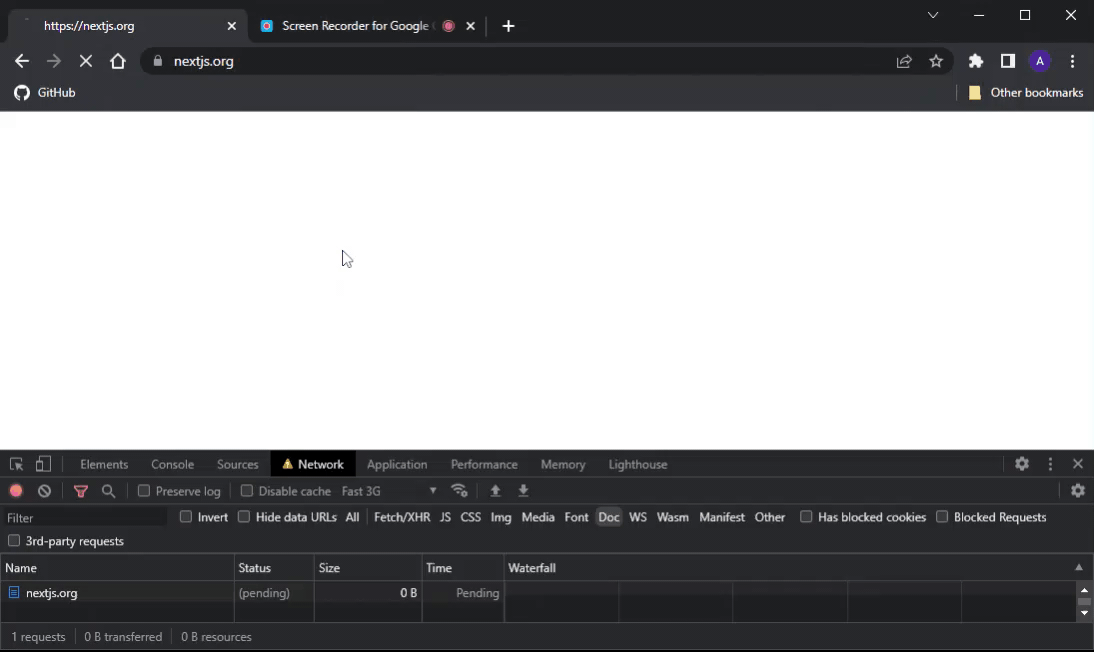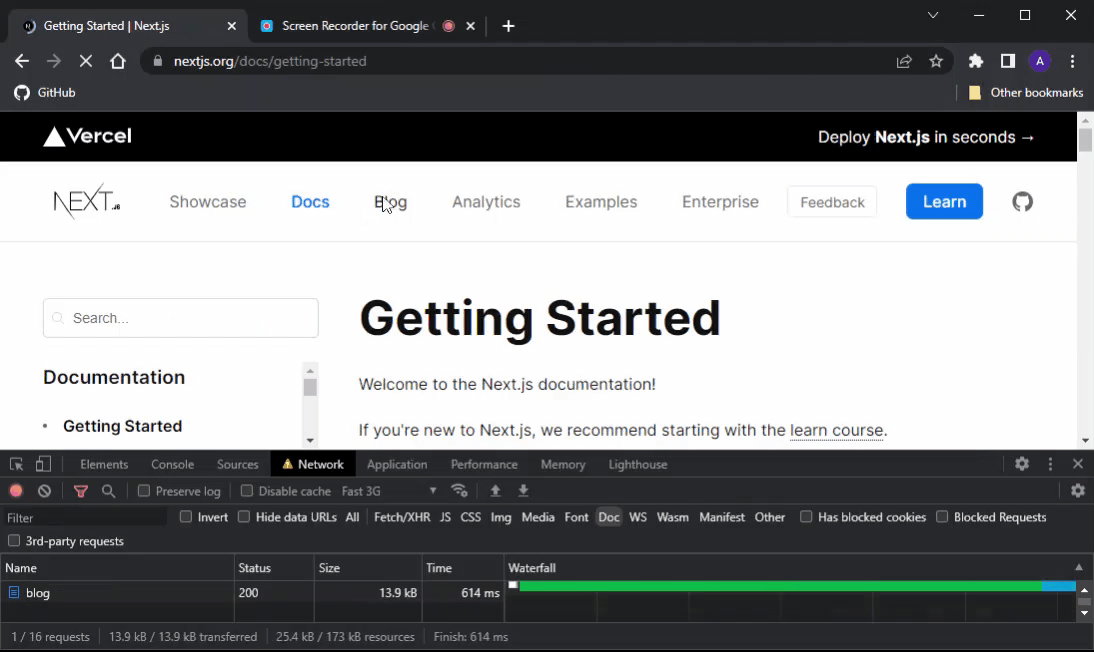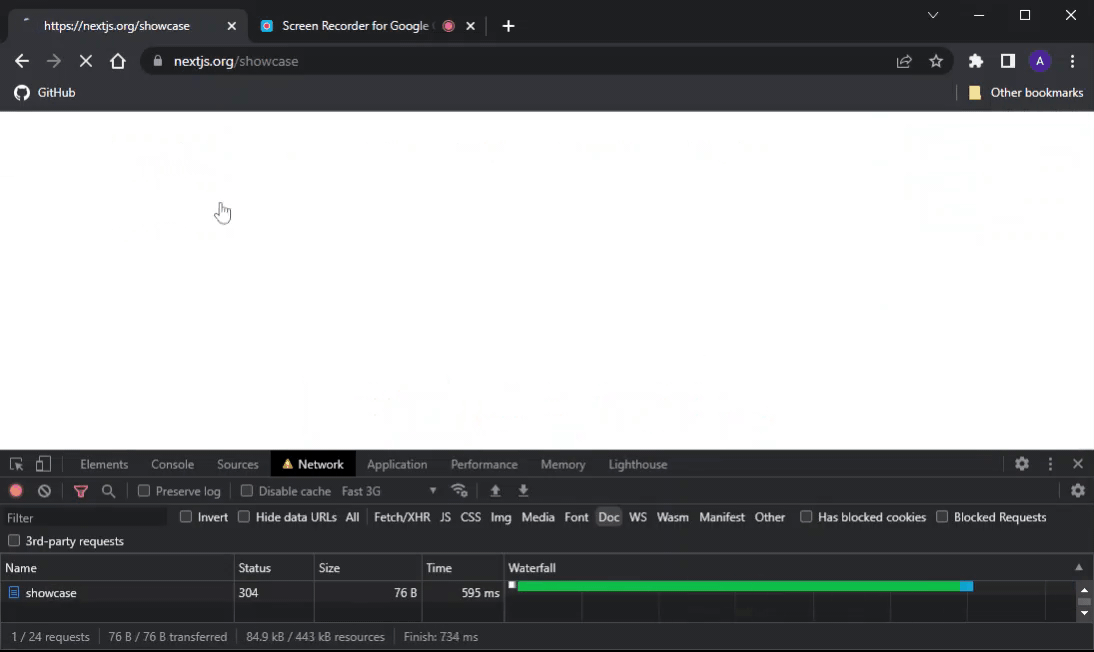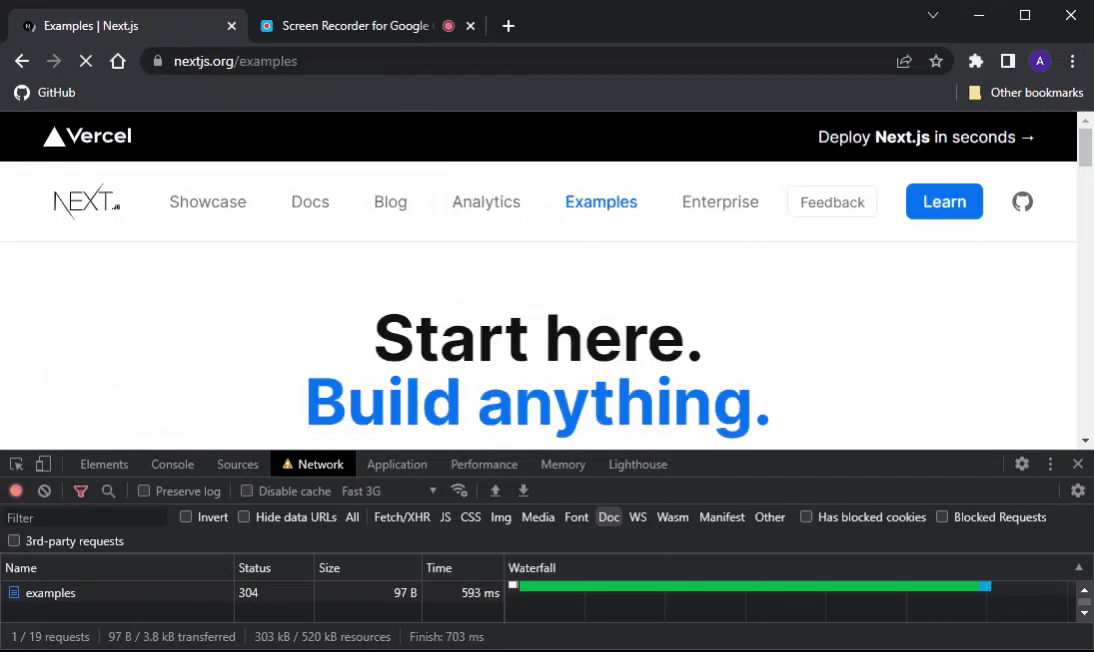
¿Qué pasó aquí?
Dado que JS aún no se ha cargado, el sitio web de Next.js no pudo evitar el comportamiento predeterminado de los elementos de la etiqueta de anclaje ( <a> ) para navegar a otra página, lo que resulta en cada clic en ellos activando una recarga de página completa.
Y cuanto más lenta es la conexión: más severo se vuelve este problema.
En otras palabras, donde la RSS debería haber tenido una ventaja de rendimiento sobre la RSE, vemos un comportamiento muy "peligroso" que podría degradar significativamente la experiencia del usuario.
Es imposible que este problema ocurra en las aplicaciones de CSR, desde el momento en que renderizan: JS ya se ha cargado por completo.
Vimos que el rendimiento de representación del lado del cliente está a la par y, a veces, incluso mejor que la SSR en términos de tiempos de carga iniciales (y lo supera con creces en los tiempos de navegación).
También hemos visto que GoogleBot puede indexar perfectamente las aplicaciones renderizadas del lado del cliente, y que podemos configurar fácilmente un servidor prerender para servir a todos los demás bots y rastreadores.
Y lo más importante, hemos logrado todo esto con solo agregar algunos archivos y usar un servicio prerender, por lo que cada aplicación CSR existente debe poder implementar estos cambios de manera rápida y fácil y beneficiarse de ellos.
Estos hechos llevan a la conclusión de que no hay una razón convincente para usar SSR. Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


