client side rendering
1.0.0
Этот проект является тематическим исследованием CSR, он исследует потенциал приложений, отображаемых на стороне клиента по сравнению с рендерингом на стороне сервера.
Углубленное сравнение всех методов рендеринга можно найти на странице сравнения этого проекта: https://client-side-rendering.pages.dev/comparison
Рендеринг на стороне клиента (CSR) относится к отправке статических активов в веб-браузер и позволяет ему обрабатывать весь процесс рендеринга приложения.
Рендеринг на стороне сервера (SSR) включает в себя рендеринг всего приложения (или страницы) на сервере и предоставление предварительно Рендерного HTML-документа, готового для отображения.
Статическое генерация сайта (SSG) -это процесс предварительного генерации HTML-страниц в качестве статических активов, которые затем отправляются и отображаются браузером.
Вопреки общему убеждению, процесс SSR в современных структурах, таких как React , Angular , Vue и Svelte, приводит к приложению дважды: один раз на сервере и снова в браузере (это известно как «гидратация»). Без этого второго рендера приложение было бы статичным и невнимательным, по сути, ведет себя как «безжизненная» веб -страница.
Интересно, что процесс гидратации, по -видимому, не является быстрее, чем типичный рендеринг (конечно, исключая фазу живописи).
Также важно отметить, что приложения SSG также должны подвергаться гидратации.
Как в SSR, так и в SSG документ HTML полностью построен, предоставляя следующие преимущества:
С другой стороны, приложения CSR предлагают следующие преимущества:
В этом случае мы сосредоточимся на КСО и изучим способы преодоления его кажущихся ограничений, используя его сильные стороны на пик.
Все оптимизации будут включены в развернутое приложение, которое можно найти здесь: https://client-side-rendering.pages.dev.
«В последнее время SSR (рендеринг на стороне сервера) штурмовал фронтальный мир.
Однако те же критические замечания, которые были действительны для PHP, ASP, JSP, (и таких) сайтов, действительны для рендеринга на стороне сервера. Это медленно, ломается довольно легко, и его трудно реализовать должным образом.
Дело в том, что, несмотря на то, что все могут вам сказать, вам, вероятно, не нужен SSR. Вы можете получить практически все преимущества (без недостатков), используя презринг ».
~ Prerender Spa Plugin
В последние годы рендеринг на стороне сервера приобрел значительную популярность в форме структур, таких как Next.js и Remix, до такой степени, что разработчики часто по умолчанию используют их без полного понимания их ограничений, даже в приложениях, которые не нуждаются в SEO (например, предложениях с требованиями входа в систему).
В то время как SSR имеет свои преимущества, эти рамки продолжают подчеркивать свою скорость («производительность как по умолчанию»), предполагая, что рендеринг на стороне клиента (CSR) по своей сути медленная.
Кроме того, существует широкое заблуждение, что идеальное SEO может быть достигнуто только с помощью SSR, и что приложения CSR не могут быть оптимизированы для сканеров поисковых систем.
Другим распространенным аргументом для SSR является то, что по мере того, как веб -приложения растут больше, время загрузки будет продолжаться, что приведет к плохой производительности FCP для приложений CSR.
Хотя это правда, что приложения становятся все более богатыми функциями, размер одной страницы должен фактически уменьшаться с течением времени.
Это связано с тенденцией создания меньших и более эффективных версий библиотек и рамок, таких как Zustand , day.js , без головы-UI и React-Router V6 .
Мы также можем наблюдать уменьшение размера рамков с течением времени: угловой (74,1 КБ), реагирования (44,5 КБ), VUE (34KB), твердого (7,6 КБ) и сластка (1,7 КБ).
Эти библиотеки вносят значительный вклад в общий вес сценариев веб -страницы.
При правильном расщеплении кода начальное время загрузки страницы может уменьшаться с течением времени.
Этот проект реализует базовое приложение CSR с оптимизацией, такими как распределение кода и предварительная загрузка. Цель состоит в том, чтобы время загрузки отдельных страниц оставалось стабильным, поскольку приложение масштабирует.
Цель состоит в том, чтобы моделировать структуру пакета приложения производственного класса и минимизировать время загрузки с помощью параллельных запросов.
Важно отметить, что повышение производительности не должно быть за счет опыта разработчиков. Следовательно, архитектура этого проекта будет лишь слегка изменена из типичной настройки React, избегая жесткой, самоуверенной структуры структур, таких как next.js, или ограничения SSR в целом.
Это тематическое исследование будет посвящено двум основным аспектам: производительности и SEO. Мы рассмотрим, как достичь лучших результатов в обеих областях.
Обратите внимание, что, хотя этот проект реализован с использованием ReAct, большинство оптимизаций являются фреймворками-агентами и основаны исключительно на бундлере и веб-браузере.
Мы возьмем на себя стандартную настройку WebPack (RSPACK) и добавим необходимые настройки по мере продвижения.
Первое эмпирическое правило - минимизировать зависимости и, среди которых выбирают те, с наименьшими размерами файлов.
Например:
Мы можем использовать Day.js вместо момента , Zustand вместо Redux Toolkit и т. Д.
Это важно не только для приложений CSR, но и для приложений SSR (и SSG), поскольку более крупные пакеты приводят к более длительному времени загрузки, задерживаясь, когда страница становится видимой или интерактивной.
В идеале, каждый хешированный файл должен быть кэширован, а index.html никогда не должен кэшироваться.
Это означает, что браузер изначально будет кэшировать main.[hash].js

Однако, поскольку main.js включает в себя весь пакет, малейшее изменение кода приведет к истечению его кэша, что означает, что браузер должен будет загрузить его снова.
Теперь, какая часть нашего пакета содержит большую часть его веса? Ответ - зависимости , также называемые поставщиками .
Так что, если бы мы могли разделить поставщиков на их собственный хэшированный кусок, это позволило бы разделение между нашим кодом и кодом поставщиков, что приведет к меньшему количеству недействительности кэша.
Давайте добавим следующую оптимизацию в наш файл конфигурации:
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
} Это создаст vendors.[hash].js файл:

Хотя это значительное улучшение, что произойдет, если мы обновим очень небольшую зависимость?
В таком случае весь кэш поставщиков Chunk будет недействительным.
Таким образом, чтобы улучшить его еще дальше, мы разделяем каждую зависимость на его собственный хэшированный кусок:
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ } Это создаст файлы [id].[hash].js такие как react-dom.[hash].js
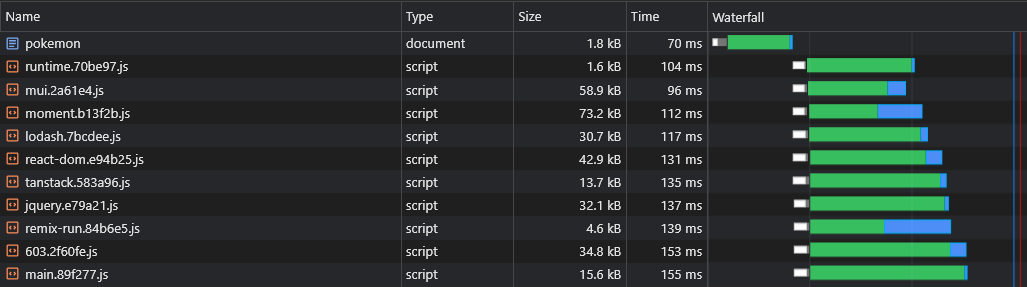
Больше информации о конфигурациях по умолчанию (например, размер расщепления порога) можно найти здесь:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
Многие функции, которые мы пишем, в конечном итоге используются только на некоторых из наших страниц, поэтому мы хотели бы, чтобы они были загружены только тогда, когда пользователь посещает страницу, на которой они используются.
Например, мы не хотим, чтобы пользователи приходилось ждать, пока пакет React-Big-Calendar не будет загружен, анализируется и выполняется, если они просто загружат домашнюю страницу. Мы хотели бы, чтобы это произошло только при посещении страницы календаря .
То, как мы можем достичь этого, (предпочтительно) по расщеплению кода на основе маршрута:
App.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) ) Поэтому, когда пользователи посещают страницу Pokemon , они загружают только основные кусок сценарии (которые включают все общие зависимости, такие как Framework) и pokemon.[hash].js Chunk.
Примечание: рекомендуется загрузить все приложение, чтобы пользователи были испытывают мгновенные, похожие на приложения, навигации. Но это плохая идея - составить все активы в один сценарий, откладывая первое визуализацию страницы.
Эти активы должны быть загружены асинхронно, и только после того, как запрашиваемая пользователем страница завершена и полностью заметна.
Кодовое расщепление имеет один серьезный недостаток - среда выполнения не знает, какие асинхронные куски нужны до тех пор, пока основной сценарий не выполнит, что приводит к тому, что они будут извлечены в значительную задержку (поскольку они совершают еще одну поездку в CDN):

То, как мы можем решить эту проблему, - это написание пользовательского плагина, который внедрит сценарий в документ, который будет отвечать за предварительные активы:
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}Scripts/Inject-Assets-plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginScripts/Preload-Assets.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( ) Файл Imported pages.js можно найти здесь.
Таким образом, браузер может принести специфическую сценарию сценарию параллельно с активами, критичными для рендеринга:
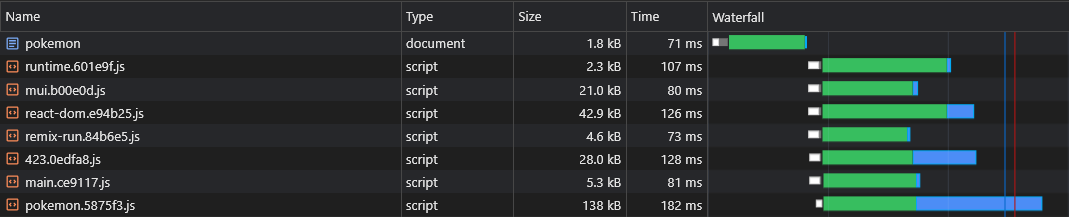
Расщепление кода представляет другую проблему: дублирование асинхронного поставщика.
Скажем, у нас есть две асинхронные куски: lorem-ipsum.[hash].js и pokemon.[hash].js . Если они оба включают одинаковую зависимость, которая не является частью основной части, это означает, что пользователь будет загружать эту зависимость дважды .
Поэтому, если это сказано, что зависимость - это moment , и она весит 72 КБ Minzipped, то оба размера Async Chunk будут не менее 72 КБ.
Нам нужно отделить эту зависимость от этих асинхронных кусков, чтобы между ними ее можно было поделиться:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
} Теперь оба lorem-ipsum.[hash].js moment.[hash].js pokemon.[hash].js
Тем не менее, у нас нет возможности сказать, какие асинхронные куски поставщиков будут разделены до того, как мы создадим приложение, поэтому мы не узнаем, какие асинхровые куски нам нужно для предварительной загрузки (см. «Предварительные асинхровые куски»):
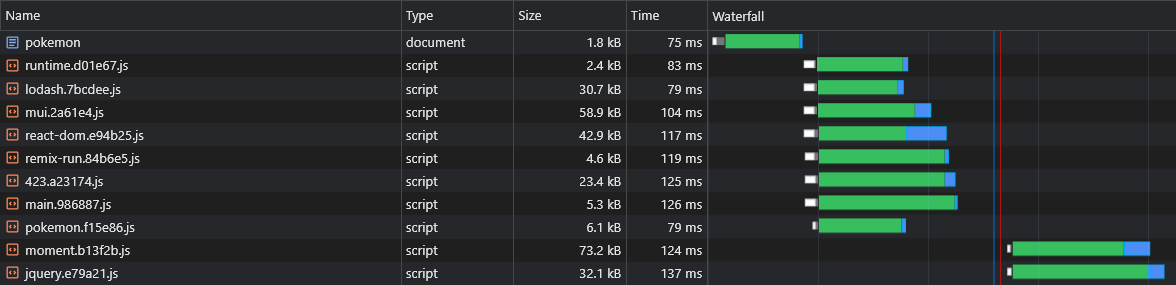
Вот почему мы добавим имена кусочек на имя асинхрового поставщика:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}Scripts/Inject-Assets-plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}Scripts/Preload-Assets.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ })Теперь все асинхронные кусочки поставщика будут получены параллельно с их родительским асинхронным куском:
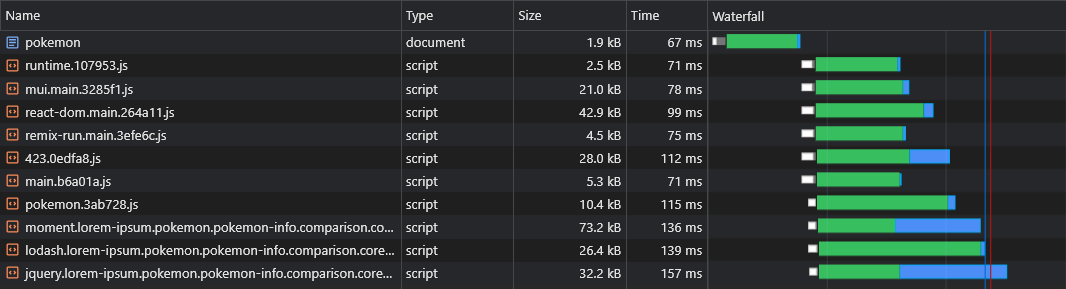
Одним из предполагаемых недостатков CSR по сравнению с SSR является то, что данные страницы (запросы на выборочные запросы) будут запущены только после того, как JS будет загружен, анализируется и выполняется в браузере:
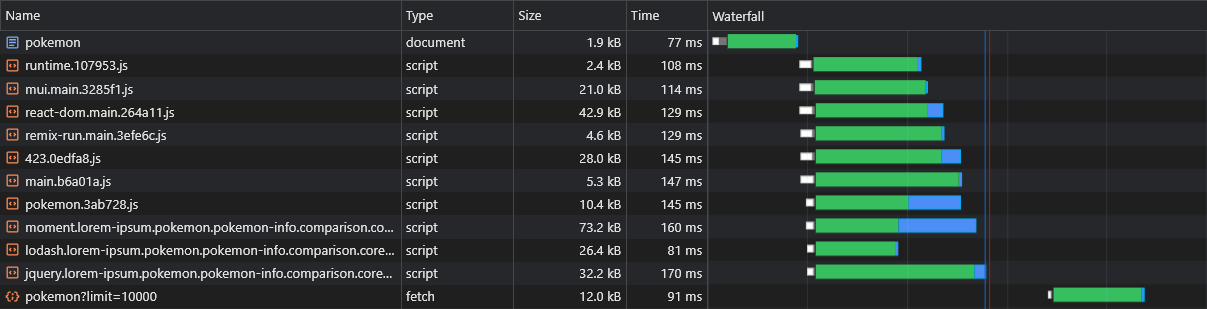
Чтобы преодолеть это, мы будем использовать предварительную загрузку еще раз, на этот раз для самого данных, исправляя API fetch :
Scripts/Inject-Assets-plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})Scripts/Preload-Assets.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets() Напоминание: файл pages.js можно найти здесь.
Теперь мы видим, что данные сразу же извлекаются:
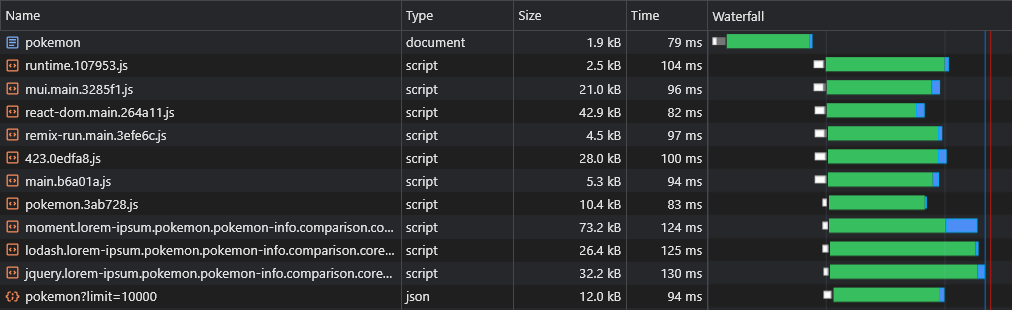
С помощью приведенного выше скрипта мы можем даже предварительно загружать данные динамических маршрутов (например, Pokemon/: name ).
Пользователи должны иметь плавный опыт навигации в нашем приложении.
Тем не менее, разделение каждой страницы вызывает заметную задержку на навигации, поскольку каждая страница должна быть загружена (по требованию), прежде чем ее можно будет отображать на экране.
Мы хотели бы заранее заранее и кэшировать все страницы.
Мы можем сделать это, написав простого обслуживания:
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}SRC/UTILS/Service-Worker-REGISTRATION.TS
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}Public/Service-Worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Теперь все страницы будут предварительно перебранные и кэшированы еще до того, как пользователь пытается перейти к ним.
Этот подход также будет генерировать полный кодовой кэш .
При осмотре нашего файла react-dom.js 43 КБ мы видим, что время, которое потребовалось для возврата, составило 60 мс, в то время как время, которое потребовалось для загрузки файла, составило 3 мс:

Это демонстрирует хорошо известный факт, что RTT оказывает огромное влияние на время загрузки веб-страниц, иногда даже больше, чем скорость загрузки, и даже когда активы обслуживаются из близлежащего края CDN, как в нашем случае.
Кроме того, и что еще более важно, мы видим, что после загрузки файла HTML у нас есть большой разрыв времени, где браузер остается бездействующим и просто ждет прибытия сценариев:
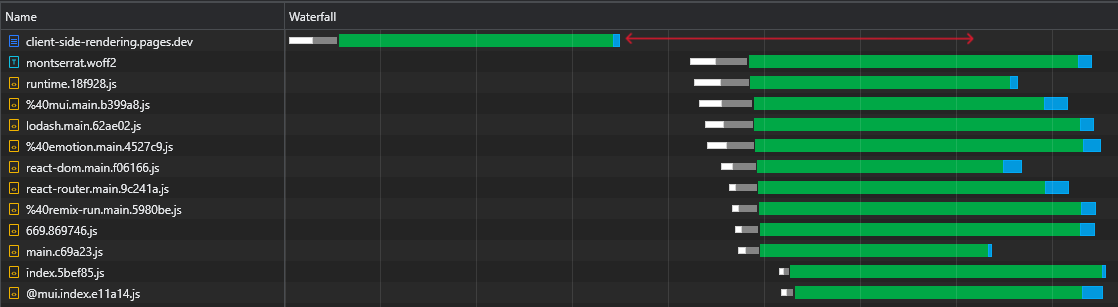
Это много драгоценного времени (помеченное красным), которое браузер мог использовать для загрузки, разбора и даже выполнения сценариев, ускоряя видимость и интерактивность страницы.
Эта неэффективность будет повторяться каждый раз, когда изменения активов (частичный кэш). Это не то, что происходит только при первом визите.
Итак, как мы можем устранить это время простоя?
Мы могли бы внедрить все начальные (критические) сценарии в документе, чтобы они начнут загружать, разрабатывать и выполнять до тех пор, пока активы Async Page не появятся:

Мы видим, что браузер теперь получает свои первоначальные сценарии без необходимости отправлять еще один запрос в CDN.
Таким образом, браузер сначала отправит запросы на асинхронные куски и предварительно загруженные данные, и, хотя они находятся на рассмотрении, он будет продолжать загружать и выполнять основные сценарии.
Мы видим, что асинхронные куски начинают загружать (помечены синим цветом) сразу после того, как файл HTML завершает загрузку, анализ и выполнение, что экономит много времени.
Хотя это изменение имеет существенное значение для быстрых сетей, оно еще более важно для более медленных сетей, где задержка больше, а RTT гораздо более эффективен.
Тем не менее, это решение имеет 2 основных вопроса:
Чтобы преодолеть эти проблемы, мы больше не можем придерживаться статического HTML -файла, и поэтому мы будем распространяться на мощность сервера. Или, точнее, мощность работника CloudFlare без сервера.
Этот работник должен перехватывать каждый запрос на документ HTML и адаптировать ответ, который идеально подходит.
Весь поток должен быть описан следующим образом:
X-Cached в запросе. Если такой заголовок существует, он будет повторять свои значения и встроить только соответствующие* активы, которые отсутствуют в нем в ответе. Если такого заголовка не существует, он внедрит все соответствующие* активы в ответе.X-Cached указывающим все его кэшированные активы.* Как начальные, так и специфичные для страницы активы.
Это гарантирует, что браузер получает именно те активы, которые ему нужны (не более, не меньше), чтобы отобразить текущую страницу в одной обратном обработке !
Scripts/Inject-Assets-plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpublic/_worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src/utils/extract-inline-scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptsSRC/UTILS/Service-Worker-REGISTRATION.TS
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}Public/Service-Worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Результаты для свежей (полностью непреднамеренной) нагрузки являются исключительными:

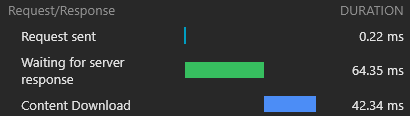

При следующей нагрузке работник CloudFlare отвечает минимальным (1,8 КБ) HTML -документом, и все активы немедленно обслуживаются из кэша.
Эта оптимизация приводит нас к другому - разделить куски к даже более мелким кускам.
Как правило, разделение пакета на слишком много кусков может повредить производительности. Это связано с тем, что страница не будет отображена до тех пор, пока все его файлы не будут загружены, и чем больше их кусочков, тем больше вероятность того, что один из них будет отсрочен (поскольку аппаратное и сеть нелинейно).
Но в нашем случае это не имеет значения, поскольку мы внедряем все соответствующие куски, и поэтому они извлекаются одновременно.
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},Это экстремальное расщепление приведет к лучшей устойчивости кэша и, в свою очередь, к более быстрому времени загрузки с частичным кешем.
Когда статический актив извлекается из CDN, он включает в себя заголовок ETag , который является хэшем контента ресурса. По последующим запросам браузер проверяет, имеет ли он хранимый ETAG. Если это так, он отправляет ETAG в заголовке If-None-Match . Затем CDN сравнивает полученный ETAG с текущим: если они соответствуют, он возвращает 304 Not Modified статус, указывая, что браузер может использовать кэшированный актив; Если нет, он возвращает новый актив со статусом 200 .
В традиционном приложении CSR перезагрузка страницы приводит к тому, что HTML получает 304 Not Modified , а другие активы, обслуживаемые кэшем. Каждый маршрут имеет уникальный ETAG, SO /lorem-ipsum и /pokemon имеют разные записи кэша, даже если их ETAG идентичны.
В спа -салоне CSR, поскольку есть только один HTML -файл, один и тот же ETAG используется для каждого запроса страницы. Однако, поскольку ETAG хранится по маршруту, браузер не будет отправлять заголовок If-None-Match для необычных страниц, что приводит к статусу 200 и Redownload HTML, даже если это тот же файл.
Тем не менее, мы можем легко создать свою собственную (улучшенную) реализацию такого поведения посредством сотрудничества между работниками:
Scripts/Inject-Assets-plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}public/_worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}Public/Service-Worker.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} Обратите внимание, что пользовательский X-ETag включен в ситуации, когда CDN не отправляет ETag .
Теперь наш работник без сервера всегда будет отвечать 304 Not Modified кодом состояния, когда нет изменений, даже для необычных страниц.
Когда используется обслуживающий работник, браузер задерживает отправку исходного запроса на документ HTML до тех пор, пока работник службы не будет загружен, что может вызвать небольшую или умеренную задержку страницы в зависимости от оборудования.
Нативное решение этой проблемы называется навигационной предварительной нагрузкой . Мы реализуем это, чтобы убедиться, что запрос на документ будет отправлен немедленно, не дожидаясь загрузки обслуживания:
SRC/UTILS/Service-Worker-REGISTRATION.TS
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}Public/Service-Worker.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )С помощью этой реализации запрос на документ будет отправлен немедленно, независимо от работника службы.
Примечание. Требуется React (v18), Svelte или Solid.js
Когда мы разделяем страницу от основного приложения, мы разделяем его этап рендеринга, что означает, что приложение будет рендеринг до рендеринга.
Поэтому, когда мы переходим от одной асинхронной страницы на другую, мы видим пустое пространство, которое остается до тех пор, пока страница не будет отображена:
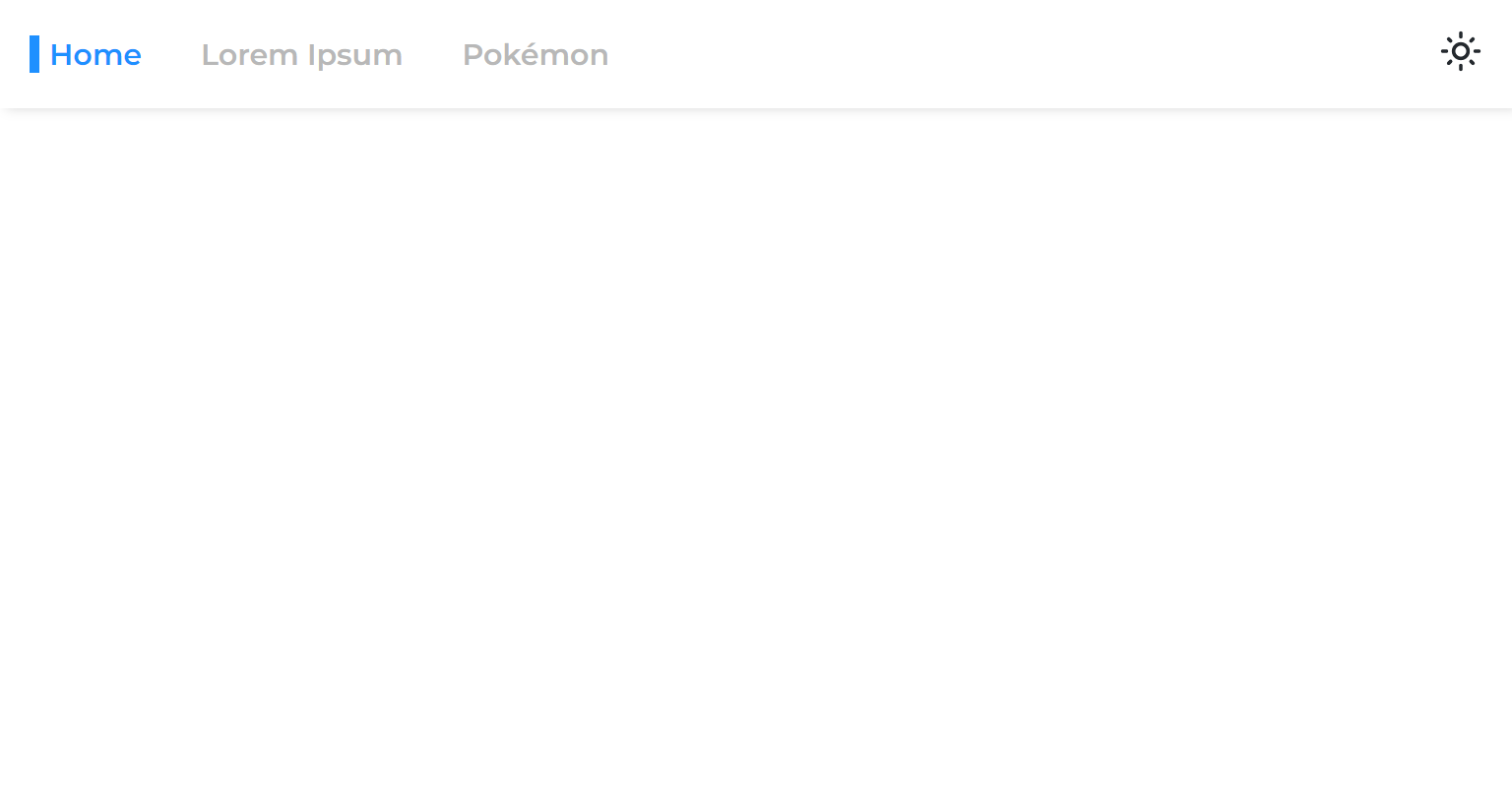
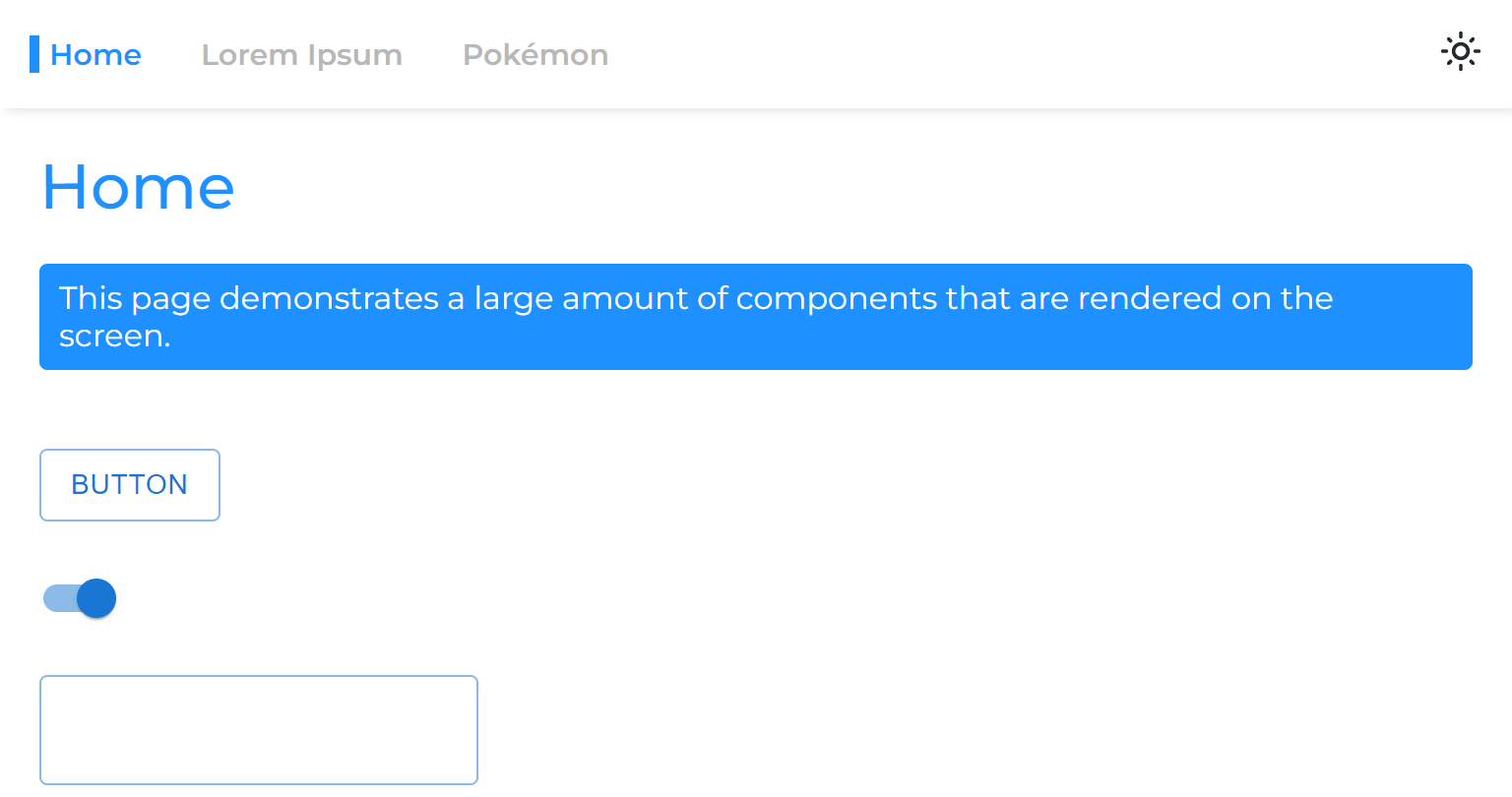
Это происходит из -за общего подхода к упаковке только маршрутов с ожиданием:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18 познакомил нас с крючком useTransition , который позволяет нам отложить рендеринг до тех пор, пока не будут выполнены некоторые критерии.
Мы будем использовать этот крюк, чтобы отложить навигацию страницы, пока он не будет готов:
USETRANSITIONNAVIGE.TS
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkТеперь асинхронные страницы будут чувствовать, что они никогда не были разделены от основного приложения.
Мы можем предварительно загружать данные других страниц при падении по ссылкам (настольный компьютер) или когда ссылки входят в порт View (Mobile):
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >Обратите внимание, что это может излишне загрузить сервер API.
Некоторые пользователи оставляют приложение открытым в течение продолжительных периодов времени, поэтому еще одна вещь, которую мы можем сделать, это переоценка (загрузка новых активов) приложения во время работы:
Служба-работник-регистрация.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}Код выше переоценивает приложение каждый час.
Процесс повторной переоценки чрезвычайно дешев, поскольку он включает в себя переиздание работника службы (который вернет 304, не измененный код состояния, если не будет изменен).
Когда работник службы действительно меняется, это означает, что новые активы доступны, и поэтому они будут выборочно загружены и кэшируются.
Мы разделили наш пакет на множество небольших кусков, значительно улучшая способности кэширования нашего приложения.
Мы разделили каждую страницу, чтобы при загрузке ее, только то, что имеет отношение, загружается сразу же.
Нам удалось сделать начальную (бесцветную) нагрузку нашего приложения чрезвычайно быстрой, все, что требуется для загрузки для загрузки, динамически вводится в него.
Мы даже предварительно загружаем данные страницы, исключая знаменитый данные, извлекающий водопад, который, как известно, есть приложения CSR.
Кроме того, мы предварительно пропадаем все страницы, что делает казалось, что они никогда не были разделены от основного кода пакета.
Все это было достигнуто без ущерба для опыта разработчика и без диктов, какую структуру JS выбрать.
Самым большим преимуществом статического приложения является то, что его можно полностью подавать из CDN.
CDN имеет много всплесков (точек присутствия), также называемого «Edge Networks». Эти POP распространяются по всему миру и, следовательно, могут обслуживать файлы в каждый регион, намного быстрее, чем удаленный сервер.
Самым быстрым CDN на сегодняшний день является CloudFlare, который имеет более 250 POPS (и подсчет):
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-edge-network-performance
Мы можем легко развернуть наше приложение, используя страницы CloudFlare:
https://pages.cloudflare.com
В заключение этого раздела мы выполним контрольный показатель нашего приложения по сравнению с сайтом документации Next.js , который является полностью SSG .
Мы сравним страницу минималистичной доступности с нашей страницей Lorem Ipsum . Обе страницы включают в себя ~ 246 КБ JS в их критические куски (предварительные нагрузки и предварительные предварительные вычинки, не имеют значения).
Вы можете нажать на каждую ссылку, чтобы выполнить живой тест.
Доступность | Next.js
Lorem ipsum | Рендеринг на стороне клиента
Я выполнил эталон Google PageSpeed Insights (моделирование медленной сети 4G) примерно 20 раз для каждой страницы и выбрал самый высокий балл.
Это результаты:
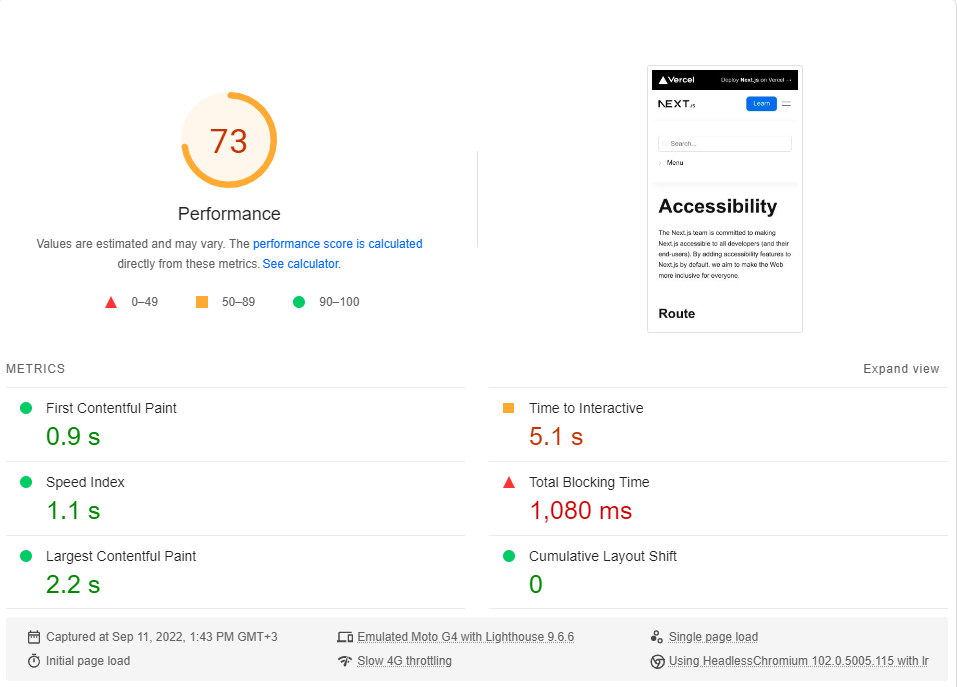
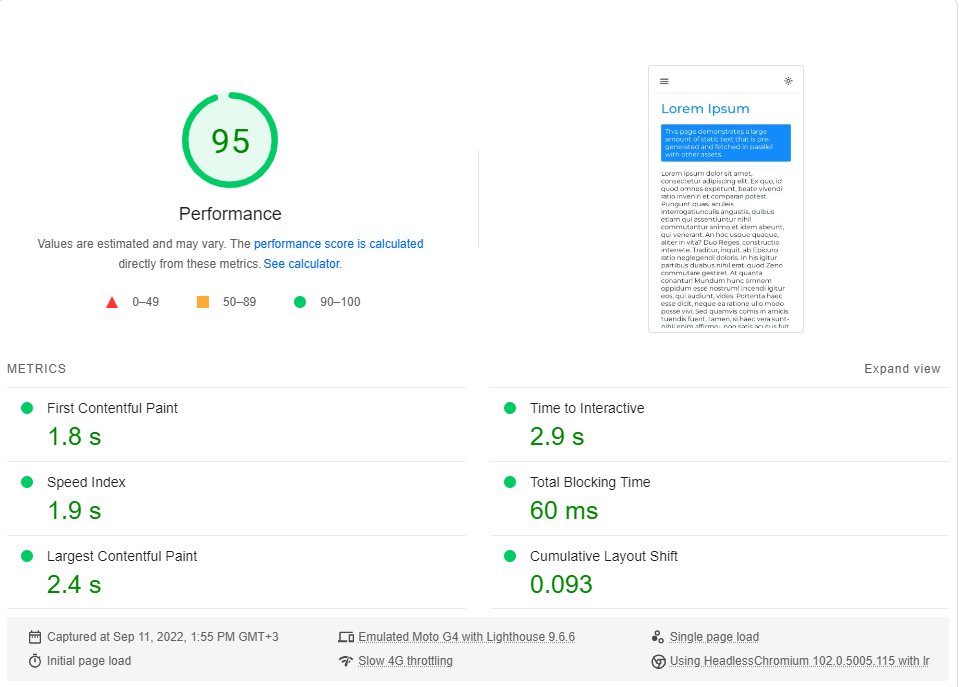
Как выясняется, производительность не является дефолтом в next.js.
Обратите внимание, что этот эталон только проверяет первую нагрузку на странице, даже не рассматривая, как работает приложение, когда оно полностью кэшируется (где CSR действительно сияет).
Это обычное мнение, что у Google возникают проблемы с правильной индексацией приложений CSR (JS).
Это могло быть в 2017 году, но на сегодняшний день: Google индексирует приложения CSR в основном безупречно.
Индексированные страницы будут иметь заголовок, описание, контент и все другие атрибуты, связанные с SEO, если мы не забываем динамически установить их (либо вручную, либо используя пакет, такой как React-Helmet ).
https://www.google.com/search?q=site:https://client-side-rendering.pages.dev
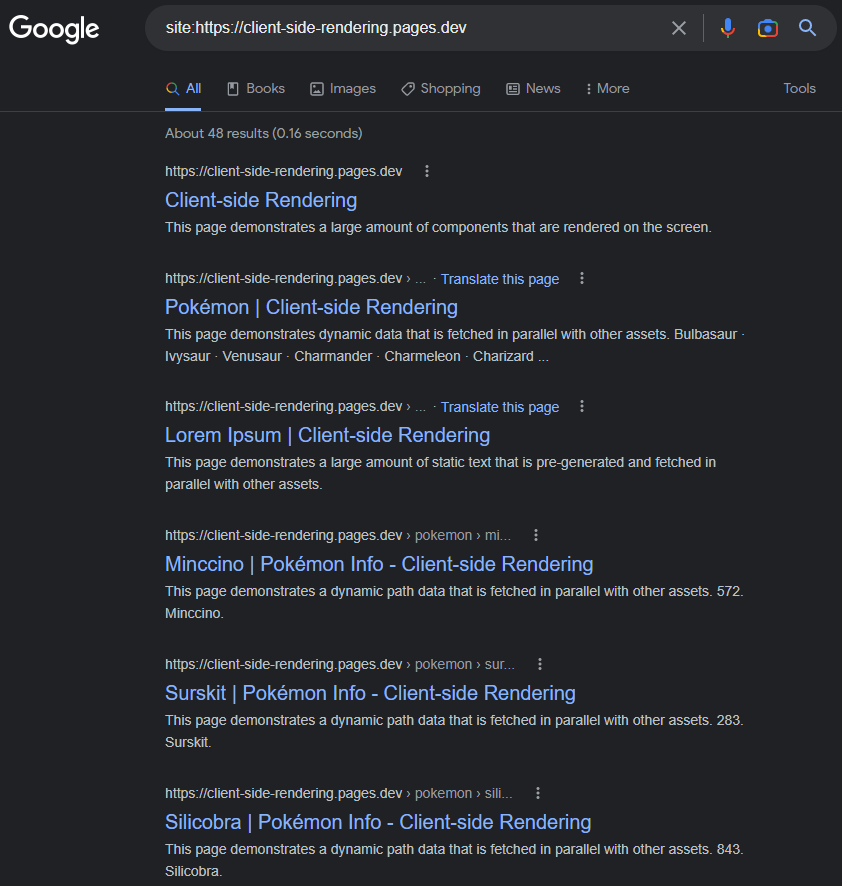
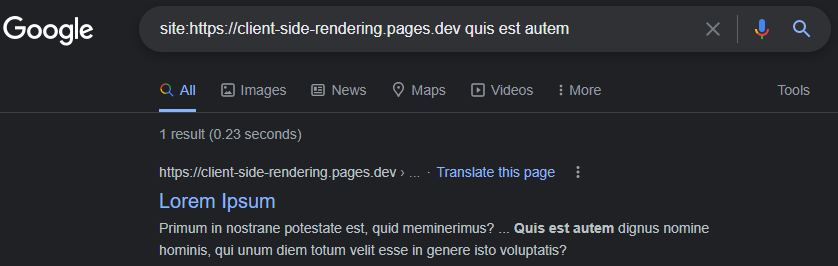
Способность Googlebot. Рендеринг JS может быть легко продемонстрирован, выполнив живой URL -тест нашего приложения в консоли поиска Google :
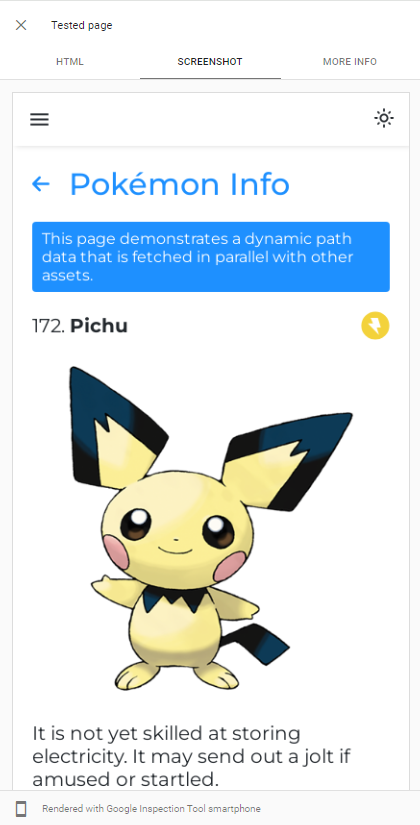
Googlebot использует последнюю версию приложений Chromium to Crawl, поэтому единственное, что мы должны сделать, это убедиться, что наше приложение быстро загружается и быстро извлекая данные.
Даже когда данные требуют много времени, чтобы получить, Googlebot, в большинстве случаев, будет ждать их, прежде чем сделать снимок страницы:
https://support.google.com/webmasters/thread/202552760/for-how-long-does-googlebot-wait-for-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
Подробное объяснение процесса ползания Googlebot JS можно найти здесь:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
Если Googlebot не сможет отображать некоторые страницы, в основном из -за нежелания Google потратить необходимые ресурсы на ползулку веб -сайта, что означает, что он имеет низкий бюджет .
Это может быть подтверждено, осмотрев страницу ползания (нажав на страницу Crawled в консоли поиска) и убедившись, что все неудачные запросы имеют другое предупреждение об ошибках (что означает, что эти запросы были намеренно прерваны Googlebot):
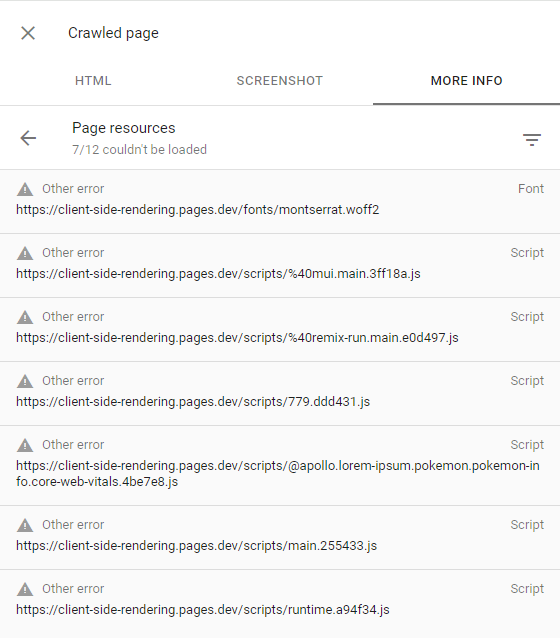
Это должно происходить только с веб -сайтами, которые Google считает, что не имеет интересного контента или имеет очень низкий трафик (например, наше демонстрационное приложение).
Более подробную информацию можно найти здесь: https://support.google.com/webmasters/thread/44252544?hl=en&msgid=4426601
Другие поисковые системы, такие как Bing, не могут отображать JS, поэтому для того, чтобы они правильно забрали наше приложение, нам нужно обслуживать им предварительную версию наших страниц.
Презрендеринг - это акт ползания веб -приложений в производстве (с использованием безголостного хрома) и генерации полного HTML -файла (с данными) для каждой страницы.
У нас есть два варианта, когда дело доходит до презринг:
Без сервера предварительно предназначенное подход, поскольку он может быть очень дешевым, особенно на GCP .
Затем мы перенаправляем веб-сканеры (идентифицированные по их строке заголовка User-Agent ) на нашем Prerenderer, используя CloudFlare Worker (например,):
public/_worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
} Вот актуальный список всех бот-агнетов (веб-сканеры): https://docs.perender.io/docs/how-to-add-additional-bots#cloudflare. Не забудьте исключить googlebot из списка.
Microsoft , также называемый Dynamic Rendering , также называется Dynamic Rendering, и широко используется многими популярными веб -сайтами, включая Twitter.
Результаты, как и ожидалось:
https://www.bing.com/search?q=site%3Ahttps%3A%2F%2FClient-Side-rendering.pages.dev
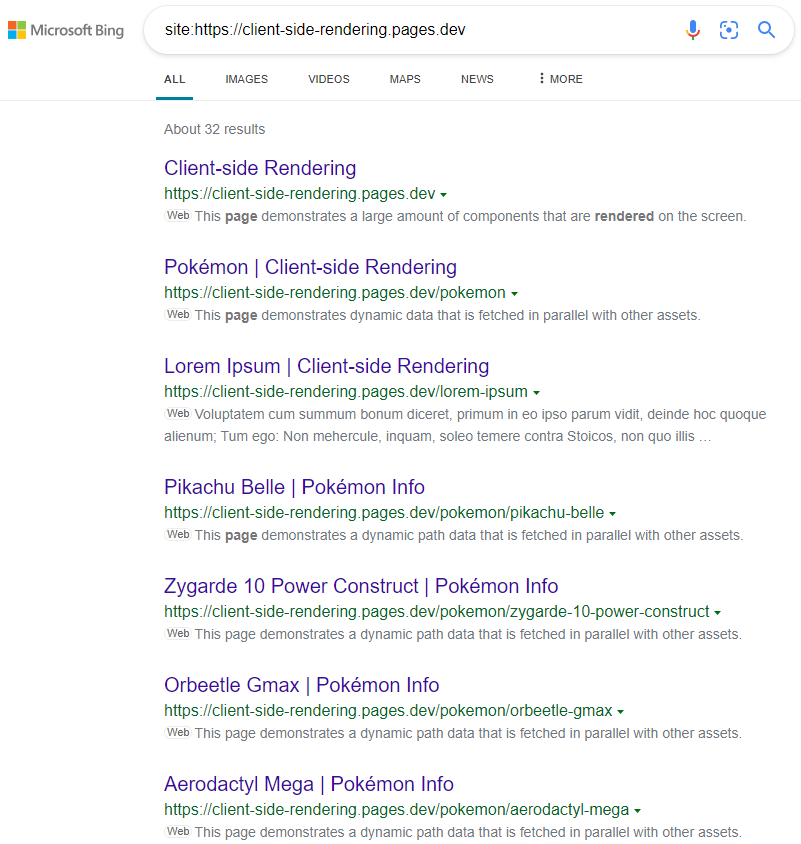
Обратите внимание, что при использовании CSS-in-JS мы можем отключить быструю оптимизацию во время презриринга, если мы хотим, чтобы наши стили опущены в DOM.
Когда мы делимся ссылкой на приложение CSR в социальных сетях, мы видим, что независимо от того, на какую страницу мы ссылаемся, предварительный просмотр останется прежним.
Это происходит потому, что большинство приложений CSR имеют только один HTML -файл без контента, а Clawlers в социальных сетях не рендеринг JS.
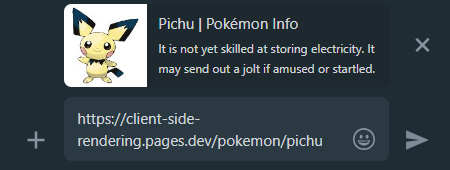
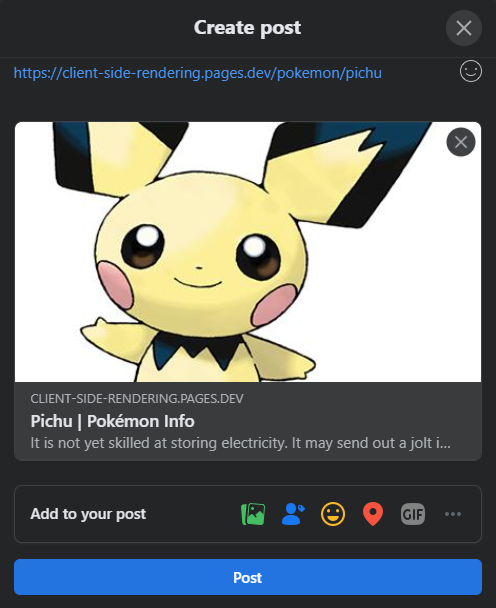
Именно здесь предварительно приходит на нашу помощь еще раз, он будет генерировать правильный предварительный просмотр для каждой страницы:
WhatsApp:
Facebook :
Чтобы все наши страницы приложений обнаруживались для поисковых систем, рекомендуется создать файл sitemap.xml , который определяет все наши маршруты веб -сайта.
Поскольку у нас уже есть централизованный файл pages.js , мы можем легко генерировать карту сайта во время сборки:
create-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )Это излучит следующую карту сайта:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >Мы можем вручную отправить нашу карту сайта в Google Search Console и инструменты Bing Webmaster .
Как упомянуто выше, углубленное сравнение всех методов рендеринга можно найти здесь: https://client-side-rendering.pages.dev/comparison
Мы видели преимущества статических файлов: они кэшируют и могут быть обслуживались из близлежащего CDN, не требуя сервера.
Это может заставить нас поверить, что SSG объединяет преимущества как CSR, так и SSR: это делает наше приложение визуальной загрузкой ( FCP ) и независимо от времени отклика нашего сервера API.
Однако на самом деле SSG имеет основное ограничение:
Поскольку JS не активен в первые моменты, все, что полагается на представленную JS, просто не будет видно или будет отображаться неправильно (например, компоненты, которые зависят от функции window.matchMedia для рендеринга).
Классический пример этого вопроса можно увидеть на следующем веб -сайте:
https://death-to-ie11.com
Обратите внимание, как таймер не виден сразу? Это потому, что он генерируется JS, который требует времени для загрузки и выполнения.
Мы также видим аналогичную проблему, когда освежает страницу «Руководства» Vercel с некоторыми фильтрами:
https://vercel.com/guides?topics=analytics
Это происходит потому, что существует 65536 (2^16) возможные комбинации фильтров, а хранение каждой комбинации в виде отдельного HTML -файла потребует большого количества серверного хранилища.
Таким образом, они генерируют один файл guides.html , который содержит все данные, но этот статический файл не знает, какие фильтры применяются до тех пор, пока JS не будет загружен, вызывая сдвиг макета.
Важно отметить, что даже при дополнительной статической регенерации пользователям все равно придется ждать ответа на сервер при посещении страниц, которые еще не были кэшированы (как в SSR).
Другим примером этой проблемы являются анимация JS - они могут показаться статичными изначально и начинать анимацию только после загрузки JS.
Существует много случаев, когда эта отложенная функциональность наносит ущерб пользователю, например, когда веб -сайты показывают только навигационную строку после загрузки JS (поскольку они полагаются на локальное хранилище, чтобы проверить, существует ли запись пользователя).
Другая критическая проблема, особенно для веб-сайтов электронной коммерции, заключается в том, что страницы SSG могут отображать устаревшие данные (например, цена или доступность продукта).
Именно поэтому ни один крупный веб-сайт электронной коммерции не использует SSG.
Это факт, что при быстром подключении к Интернету как CSR, так и SSR работают великолепно (если они оба оптимизированы), и чем выше скорость соединения - тем ближе они приближаются с точки зрения времени загрузки.
Однако при работе с медленными соединениями (например, мобильными сетями), кажется, что SSR имеет преимущество над КСО в отношении времени загрузки.
Поскольку приложения SSR отображаются на сервере, браузер получает полностью построенный файл HTML, и поэтому он может отобразить страницу пользователю, не ожидая загрузки JS. Когда JS в конечном итоге загружен и анализируется, структура способна «увлажнить» DOM с функциональностью (без необходимости его реконструирования).
Хотя это кажется большим преимуществом, это поведение представляет нежелательный побочный эффект, особенно при более медленных соединениях:
Пока JS не будет загружен, пользователи могут щелкнуть, где бы они ни желали, но приложение не будет реагировать на ни одно из их событий на основе JS.
Это плохой опыт пользователя, когда кнопки не реагируют на взаимодействие с пользователями, но это становится гораздо большей проблемой, когда события по умолчанию не предотвращаются.
Это сравнение между веб-сайтом Next.js и нашим приложением для рендеринга на стороне клиента на быстрое соединение 3G:
Что здесь случилось?
Поскольку JS еще не был загружен, веб -сайт Next.js не мог предотвратить поведение элементов якоря ( <a> ) по умолчанию (<a>) для перемещения на другую страницу, что приводит к каждому щелчке на них, запускающем полную перезагрузку страницы.
И чем медленнее соединение - тем более серьезным становится эта проблема.
Другими словами, где SSR должен был иметь преимущество производительности по сравнению с CSR, мы видим очень «опасное» поведение, которое могло бы значительно ухудшить пользовательский опыт.
В этом вопросе невозможно возникнуть в приложениях CSR, поскольку в тот момент, когда они визуализированы - JS уже полностью загружен.
Мы видели, что производительность рендеринга на стороне клиента находится на номинале, а иногда даже лучше, чем SSR с точки зрения начального времени загрузки (и намного превосходит его в время навигации).
Мы также видели, что Googlebot может отлично индексировать приложения на стороне клиента, и что мы можем легко настроить сервер Prerender для обслуживания всех других ботов и сканеров.
И самое главное, мы достигли всего этого, просто добавив несколько файлов и используя услугу Prerender, поэтому каждое существующее приложение CSR должно быть в состоянии быстро и легко реализовать эти изменения и извлечь выгоду из них.
Эти факты приводят к выводу, что нет веских причин использовать SSR. Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


