client side rendering
1.0.0
このプロジェクトはCSRのケーススタディであり、サーバー側のレンダリングと比較して、クライアント側のレンダリングされたアプリの可能性を調査します。
すべてのレンダリング方法の詳細な比較は、このプロジェクトの比較ページ:https://client-side-rendering.pages.dev/comparisonにあります。
クライアント側のレンダリング(CSR)とは、静的資産をWebブラウザに送信し、アプリのレンダリングプロセス全体を処理できるようにすることを指します。
サーバー側のレンダリング(SSR)には、アプリ全体(またはページ)をサーバー上にレンダリングし、事前にレンダリングされたHTMLドキュメントを表示する準備ができています。
静的サイト生成(SSG)は、静的資産としてHTMLページを事前に生成するプロセスであり、ブラウザによって送信および表示されます。
一般的な信念に反して、 React 、 Angular 、 Vue 、 Svelteのような最新のフレームワークのSSRプロセスは、アプリの結果を2回レンダリングします。サーバー上、ブラウザでは1回(これは「水分補給」と呼ばれます)。この2番目のレンダリングがなければ、アプリは静的で相性が良く、本質的に「活気のない」Webページのように動作します。
興味深いことに、水和プロセスは、典型的なレンダリングよりも高速ではないように見えます(もちろん、塗装段階を除く)。
また、SSGアプリも水分補給を受ける必要があることに注意することも重要です。
SSRとSSGの両方で、HTMLドキュメントは完全に構築されており、次の利点を提供します。
一方、CSRアプリは次の利点を提供します。
このケーススタディでは、CSRに焦点を当て、その強さをピークに活用しながら、その明らかな制限を克服する方法を探ります。
すべての最適化は、展開されたアプリに組み込まれます。これは、https://client-side-rendering.pages.devにあります。
「最近、SSR(サーバーサイドレンダリング)はJavaScriptのフロントエンドの世界を席巻しました。クライアントに送信する前にサーバーにサイトやアプリをレンダリングできるという事実は絶対に革新的なアイデアです(そして、JSクライアント側のアプリが最初に人気を得る前に誰もがしていたことではありません...)。
ただし、PHP、ASP、JSP、(およびそのような)サイトに有効な同じ批判は、今日のサーバー側のレンダリングに有効です。遅く、かなり簡単に壊れ、適切に実装することは困難です。
物事は、誰もがあなたに言っているかもしれないにもかかわらず、おそらくSSRを必要としないでしょう。プレレンダリングを使用することにより、ほとんどすべての利点(欠点なしで)を得ることができます。」
〜プレレンダースパプラグイン
近年、サーバー側のレンダリングは、 next.jsやリミックスなどのフレームワークの形で非常に人気を博し、開発者がSEOを必要としないアプリ(例えば、ログイン要件を持つもの)でも、それらの制限を完全に理解せずに使用することが多いことが多いポイントまでです。
SSRには利点がありますが、これらのフレームワークは速度(「デフォルトとしてのパフォーマンス」)を強調し続け、クライアント側のレンダリング(CSR)が本質的に遅いことを示唆しています。
さらに、Perfect SEOはSSRでのみ達成でき、CSRアプリを検索エンジンクローラー用に最適化できないという広範な誤解があります。
SSRのもう1つの一般的な議論は、Webアプリが大きくなるにつれて、読み込み時間が増え続け、CSRアプリのFCPパフォーマンスが低下することです。
アプリの機能が豊富になっていることは事実ですが、単一のページのサイズは実際に時間とともに減少するはずです。
これは、 Zustand 、 day.js 、 Head-less-UI 、 React-Router V6など、より小さく、より効率的なバージョンのライブラリとフレームワークを作成する傾向によるものです。
また、角度(74.1kb)、反応(44.5kb)、vue(34kb)、ソリッド(7.6kb)、およびSvelte(1.7kb)など、時間の経過に伴うフレームワークのサイズの減少を観察することもできます。
これらのライブラリは、Webページのスクリプトの全体的な重みに大きく貢献しています。
適切なコードスプリッティングにより、ページの初期読み込み時間は時間とともに減少する可能性があります。
このプロジェクトは、コードスプリッティングやプリロードなどの最適化を備えた基本的なCSRアプリを実装しています。目標は、個々のページの読み込み時間がアプリが拡大するにつれて安定したままであることです。
目的は、Production-Gradeアプリのパッケージ構造をシミュレートし、並列化された要求を介して読み込み時間を最小限に抑えることです。
パフォーマンスの向上は、開発者の経験を犠牲にしてはならないことに注意することが重要です。したがって、このプロジェクトのアーキテクチャは、典型的な反応セットアップからわずかに変更され、next.jsのようなフレームワークの剛性のある意見の構造、または一般的なSSRの制限を回避します。
このケーススタディでは、パフォーマンスとSEOの2つの主な側面に焦点を当てます。両方の領域でトップスコアを達成する方法を探ります。
このプロジェクトはReactを使用して実装されていますが、ほとんどの最適化はフレームワークに依存しており、純粋にバンドラーとWebブラウザーに基づいていることに注意してください。
標準のWebpack(RSPACK)のセットアップを想定し、進行中に必要なカスタマイズを追加します。
最初の経験則は、依存関係を最小限に抑え、その中で、ファイルサイズが最小のものを選択することです。
例えば:
Redux Toolkitなどの代わりに、瞬間の代わりにday.jsを使用できます。
これは、CSRアプリだけでなく、SSR(およびSSG)アプリにとっても重要です。バンドルが大きくなると、読み込み時間が長くなり、ページが表示されたりインタラクティブになったときに遅延します。
理想的には、すべてのハッシュされたファイルをキャッシュする必要があり、 index.htmlキャッシュされないでください。
これは、ブラウザが最初にmain.[hash].jsをキャッシュすることを意味します。

ただし、 main.jsにはバンドル全体が含まれているため、コードのわずかな変更によりキャッシュが失効します。つまり、ブラウザは再度ダウンロードする必要があります。
さて、私たちのバンドルのどの部分がその重量のほとんどを構成していますか?答えは、ベンダーとも呼ばれる依存関係です。
したがって、ベンダーを独自のハッシュチャンクに分割できる場合、コードとベンダーコードの分離が可能になり、キャッシュの無効化が少なくなります。
構成ファイルに次の最適化を追加しましょう。
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
}これによりvendors.[hash].jsファイル:

これは大幅な改善ですが、非常に小さな依存関係を更新した場合はどうなりますか?
そのような場合、ベンダー全体のChunkのキャッシュが無効になります。
したがって、さらに改善するために、各依存関係を独自のハッシュドチャンクに分割します。
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ }これにより[id].[hash].js react-dom.[hash].js
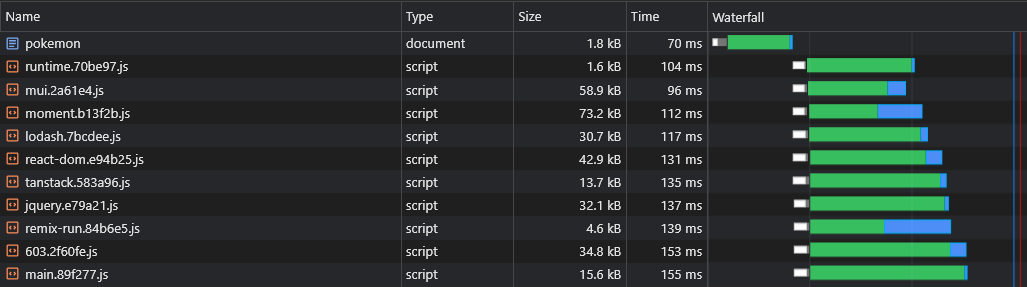
デフォルトの構成(スプリットしきい値サイズなど)の詳細については、こちらをご覧ください。
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
私たちが書く機能の多くは、最終的にいくつかのページでのみ使用されているため、ユーザーが使用されているページにアクセスしたときにのみロードされたいと思います。
たとえば、ホームページを単にロードした場合は、 React-Big-Calendarパッケージがダウンロードされ、解析され、実行されるまでユーザーが待たなければならないことを望んでいません。彼らがカレンダーページにアクセスしたときにのみそれが起こることを望むでしょう。
これを達成できる方法は、(できれば)ルートベースのコード分割によるものです。
app.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) )したがって、ユーザーがポケモンページにアクセスすると、メインチャンクスクリプト(フレームワークなどのすべての共有依存関係を含む)とpokemon.[hash].jsチャンク。
注:アプリ全体をダウンロードして、ユーザーがアプリのようなナビゲーションを即座に体験できるようにすることをお勧めします。しかし、すべての資産を単一のスクリプトにバッチし、ページの最初のレンダリングを遅らせることは悪い考えです。
これらの資産は非同期にダウンロードする必要があり、ユーザーが要求したページがレンダリングを終了し、完全に目に見えるようになった後にのみです。
コードスプリットには1つの大きな欠陥があります。ランタイムは、メインスクリプトが実行されるまでどのユニのチャンクが必要かを知りません。

この問題を解決できる方法は、関連資産のプリロードを担当するスクリプトをドキュメントに埋め込むカスタムプラグインを作成することです。
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}スクリプト/Inject-Assets-Plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginスクリプト/Preload-Assets.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( )インポートされたpages.jsファイルはここにあります。
このようにして、ブラウザは、レンダークリティカルなアセットと並行して、ページ固有のスクリプトチャンクを取得できます。
コード分割では、別の問題を紹介します:Asyncベンダーの複製。
2つの非同期チャンクがあるとします: lorem-ipsum.[hash].js pokemon.[hash].js 。どちらもメインチャンクの一部ではないのと同じ依存関係を含める場合、ユーザーはその依存関係を2回ダウンロードします。
したがって、その依存関係がmomentであり、重量が72kbの刻まれている場合、Async Chunkの両方のサイズは少なくとも72kbになります。
これらの依存関係をこれらの非同期チャンクから分割する必要があります。
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
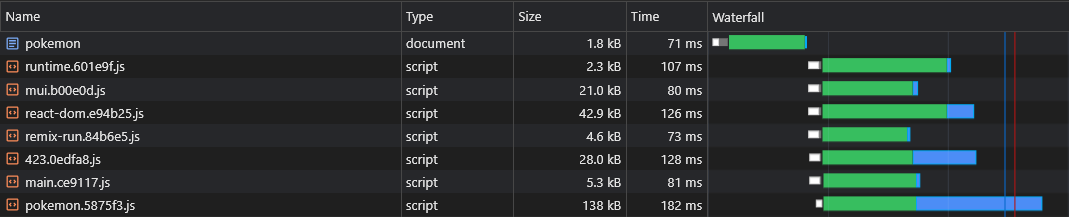
}現在moment.[hash].js lorem-ipsum.[hash].jsとpokemon.[hash].js
ただし、アプリケーションを構築する前にどのAsyncベンダーのチャンクが分割されるかを伝える方法はないため、どのアシングベンダーチャンクがプリロードする必要があるかわかりません(「非偏見のチャンク」セクションを参照):
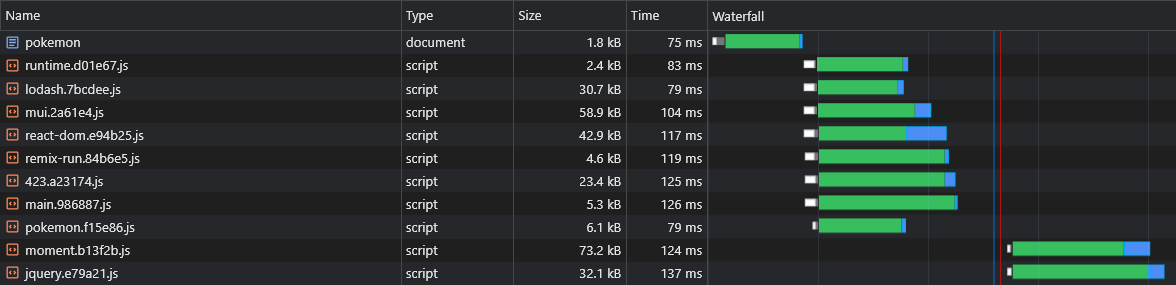
そのため、チャンクス名をAsyncベンダーの名前に追加します。
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}スクリプト/Inject-Assets-Plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}スクリプト/Preload-Assets.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
+ })これで、すべてのASYNCベンダーのチャンクは、親のアシュナクチャンクと並行してフェッチされます。
SSRを介したCSRの推定の欠点の1つは、JSがダウンロード、解析、実行された後にページのデータ(フェッチリクエスト)が起動されることです。
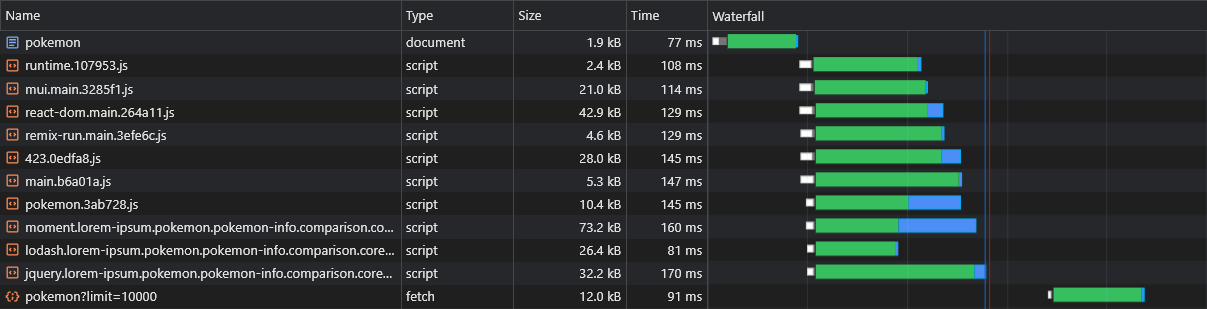
これを克服するために、 fetch APIにパッチを当てることにより、今回はデータ自体のプリロードを再度使用します。
スクリプト/Inject-Assets-Plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})スクリプト/Preload-Assets.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets()リマインダー: pages.jsファイルはこちらにあります。
これで、データがすぐにフェッチされていることがわかります。
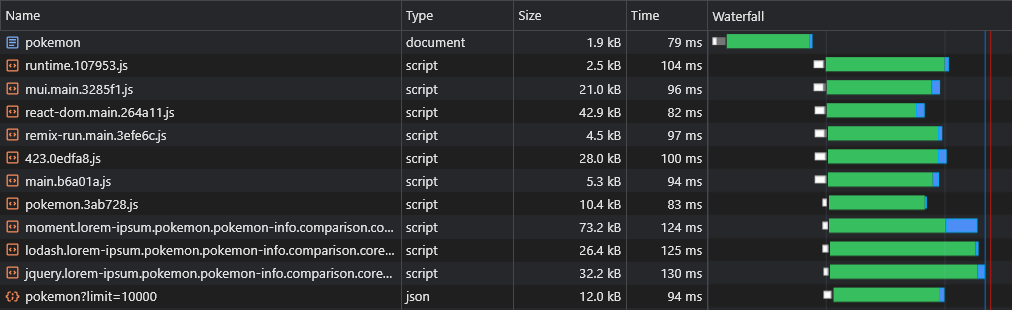
上記のスクリプトを使用すると、Dynamic Routesデータ(ポケモン/:名前など)をプリロードすることもできます。
ユーザーは、アプリでスムーズなナビゲーションエクスペリエンスをする必要があります。
ただし、すべてのページを分割すると、すべてのページを画面上でレンダリングする前に(オンデマンド)ダウンロードする必要があるため、ナビゲーションが顕著に遅延します。
すべてのページを事前にプリフェッチおよびキャッシュしたいと思います。
簡単なサービスワーカーを書くことでこれを行うことができます。
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}src/utils/service-worker-registration.ts
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}public/service-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )これで、ユーザーがそれらに移動しようとする前であっても、すべてのページがプリフェッチされ、キャッシュされます。
このアプローチは、完全なコードキャッシュも生成します。
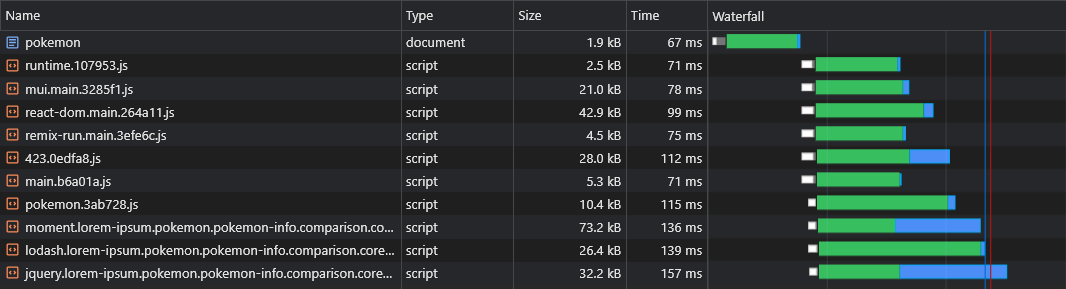
43kbのreact-dom.jsファイルを検査すると、ファイルをダウンロードするのにかかった時間が3msであった間、返品のリクエストにかかった時間が60ミリ秒であることがわかります。

これは、RTTがWebページの読み込み時間に大きな影響を与えるというよく知られている事実を示しています。時には、ダウンロード速度よりもさらに多く、そして私たちの場合のように近くのCDNエッジから資産が提供された場合でも、
さらに、さらに重要なことに、HTMLファイルがダウンロードされた後、ブラウザがアイドル状態を維持し、スクリプトが到着するのを待っている大きなタイムパンがあることがわかります。
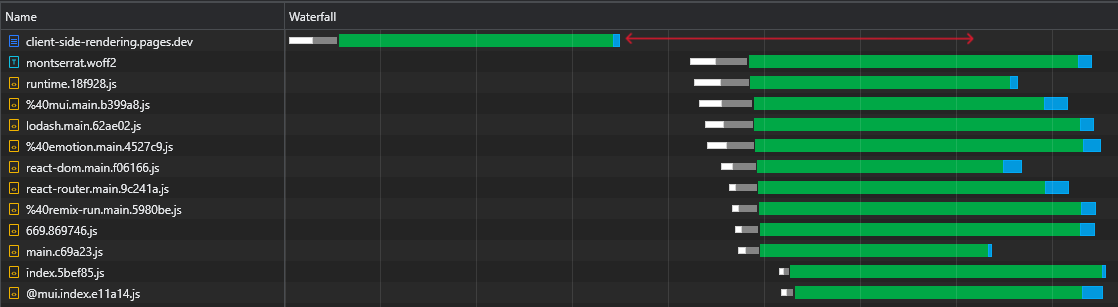
これは、ブラウザがスクリプトのダウンロード、解析、さらには実行に使用できる多くの貴重な時間(赤でマーク)であり、ページの可視性とインタラクティブ性を高速化します。
この非効率性は、資産が変更されるたびに再発します(部分キャッシュ)。これは、最初の訪問でのみ起こることではありません。
それでは、このアイドル時間をどのように排除できますか?
ドキュメント内のすべての最初の(重要な)スクリプトをインライン化することができます。そのため、Async Pageアセットが到着するまでダウンロード、解析、実行を開始できます。

ブラウザは、CDNに別のリクエストを送信することなく、最初のスクリプトを取得することがわかります。
そのため、ブラウザは最初にAsyncチャンクとプリロードされたデータのリクエストを送信し、これらは保留中ですが、メインスクリプトのダウンロードと実行を継続します。
HTMLファイルがダウンロード、解析、実行が終了した直後に、Asyncチャンクがダウンロードし始めていることがわかります。これにより、時間がかかります。
この変更は高速ネットワークで大きな違いをもたらしていますが、遅延が大きく、RTTがはるかにインパクトがある遅いネットワークにとってはさらに重要です。
ただし、このソリューションには2つの主要な問題があります。
これらの問題を克服するために、静的HTMLファイルに固執することはできません。したがって、サーバーのパワーをリーバリングします。または、より正確には、CloudFlareサーバーレスワーカーのパワー。
このワーカーは、すべてのHTMLドキュメントリクエストを傍受し、完全に適合する応答を調整する必要があります。
フロー全体を次のように説明する必要があります。
X-Cachedヘッダーの存在をチェックします。そのようなヘッダーが存在する場合、その値を反復し、応答に存在しない関連*資産のみをインラインにします。そのようなヘッダーが存在しない場合、応答に関連するすべての*資産がインラインになります。X-CachedヘッダーとともにHTMLドキュメントを送信します。*初期およびページ固有の資産の両方。
これにより、ブラウザが単一の往復に現在のページを表示するために必要な資産を正確に受信することが保証されます(これ以上、それ以下ではありません)!
スクリプト/Inject-Assets-Plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpublic/_worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src/utils/extract-inline-scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptssrc/utils/service-worker-registration.ts
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}public/service-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )新鮮な(まったく未確認の)負荷の結果は例外的です。

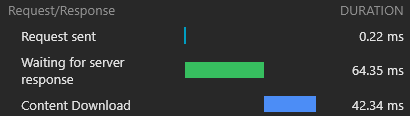

次の負荷で、CloudFlareワーカーは最小(1.8kb)HTMLドキュメントで応答し、すべての資産はすぐにキャッシュから提供されます。
この最適化により、私たちは別のものにつながります - 塊をさらに小さな部分に分割します。
経験則として、バンドルをあまりにも多くのチャンクに分割すると、パフォーマンスが損なわれる可能性があります。これは、すべてのファイルがダウンロードされるまでページがレンダリングされず、チャンクが多いほど、その1つが遅延する可能性が大きくなるためです(ハードウェアとネットワーク速度は非線形であるため)。
しかし、私たちの場合は、関連するすべてのチャンクをインラインでインラインにしているため、一度にフェッチされているためです。
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},この極端な分割により、キャッシュの持続性が向上し、部分的なキャッシュを使用すると、荷重時間が速くなります。
静的資産がCDNから取得されると、リソースのコンテンツハッシュであるETagヘッダーが含まれます。その後のリクエストで、ブラウザは保存されたETAGがあるかどうかを確認します。もしそうなら、それはIf-None-MatchヘッダーでETAGを送信します。次に、CDNは受信したETAGを現在のETAGと比較します。一致する場合、 304 Not Modifiedステータスを返し、ブラウザがキャッシュされた資産を使用できることを示します。そうでない場合は、 200ステータスで新しい資産を返します。
従来のCSRアプリでは、ページをリロードすると、HTMLが304 Not Modifiedを取得し、他の資産がキャッシュから提供されます。各ルートにはユニークなETAGがあるため、 /lorem-ipsumおよび/pokemon 、たとえETAGが同一であっても、異なるキャッシュエントリを持っています。
CSRスパでは、HTMLファイルが1つしかないため、すべてのページリクエストに同じETAGが使用されます。ただし、ETAGはルートごとに保存されているため、ブラウザはVisitedページのIf-None-Matchヘッダーを送信しません。同じファイルであっても、 200ステータスとHTMLの再ダウンロードになります。
ただし、労働者間のコラボレーションを通じて、この行動の独自の(改善された)実装を簡単に作成できます。
スクリプト/Inject-Assets-Plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}public/_worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}public/service-worker.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} CDNがETag自動的に送信しない状況には、カスタムX-ETagが含まれていることに注意してください。
これで、サーバーレスワーカーは、変更されていないページであっても、変更がない場合は常に304 Not Modifiedステータスコードで常に応答します。
サービスワーカーを使用すると、ブラウザはサービスワーカーがロードされるまで最初のHTMLドキュメント要求を送信します。
この問題のネイティブソリューションは、ナビゲーションプリロードと呼ばれます。これを実装して、サービスワーカーがロードするのを待つことなく、ドキュメントリクエストがすぐに送信されるようにします。
src/utils/service-worker-registration.ts
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}public/service-worker.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )この実装により、ドキュメントリクエストは、サービスワーカーとは無関係に、すぐに送信されます。
注:React(V18)、SvelteまたはSolid.jsが必要です
ページをメインアプリから分割すると、レンダリングフェーズを分離します。つまり、ページがレンダリングする前にアプリがレンダリングされます。
したがって、1つの非同期ページから別のページに移動すると、ページがレンダリングされるまで残る空白のスペースが表示されます。
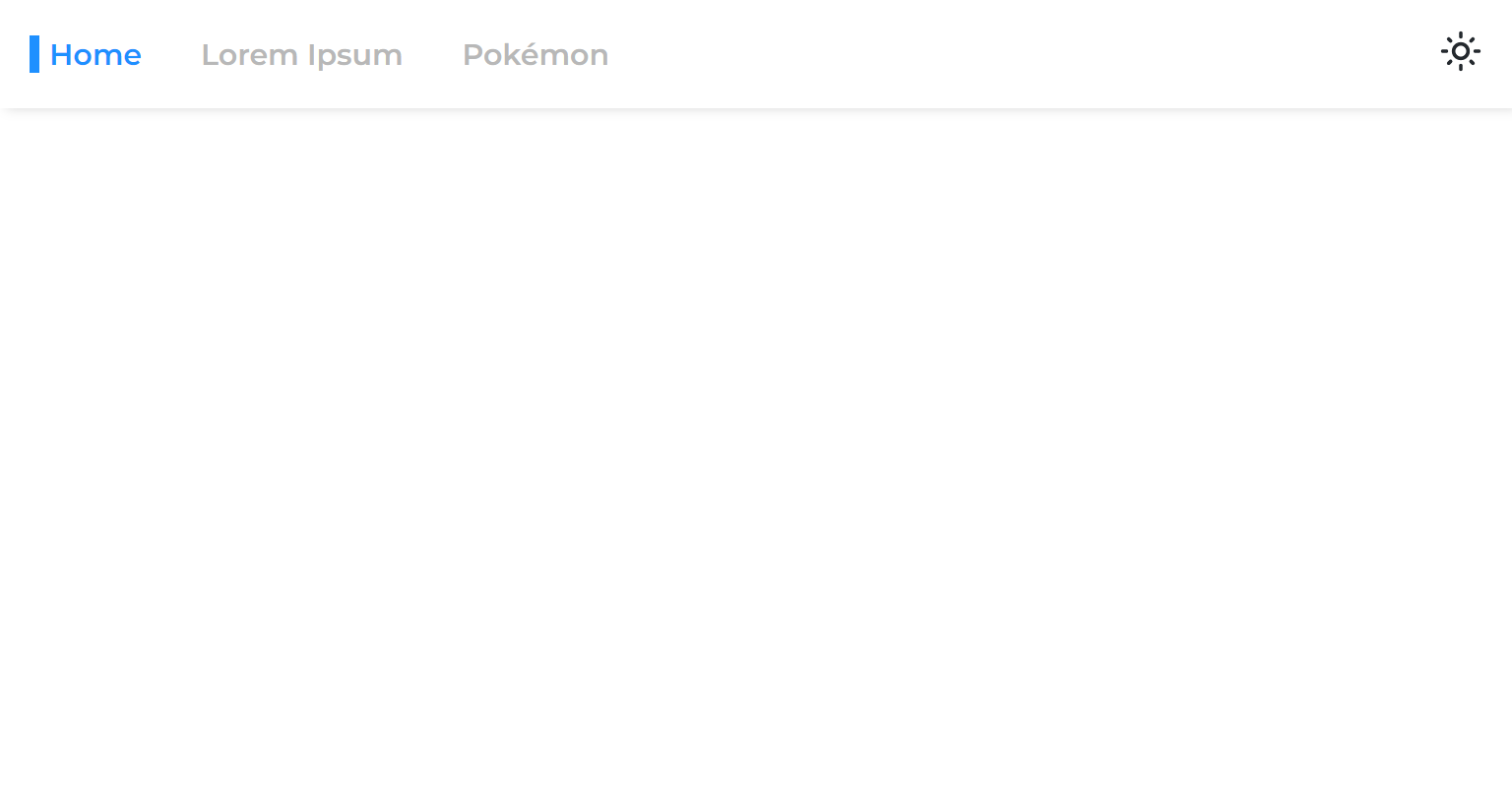
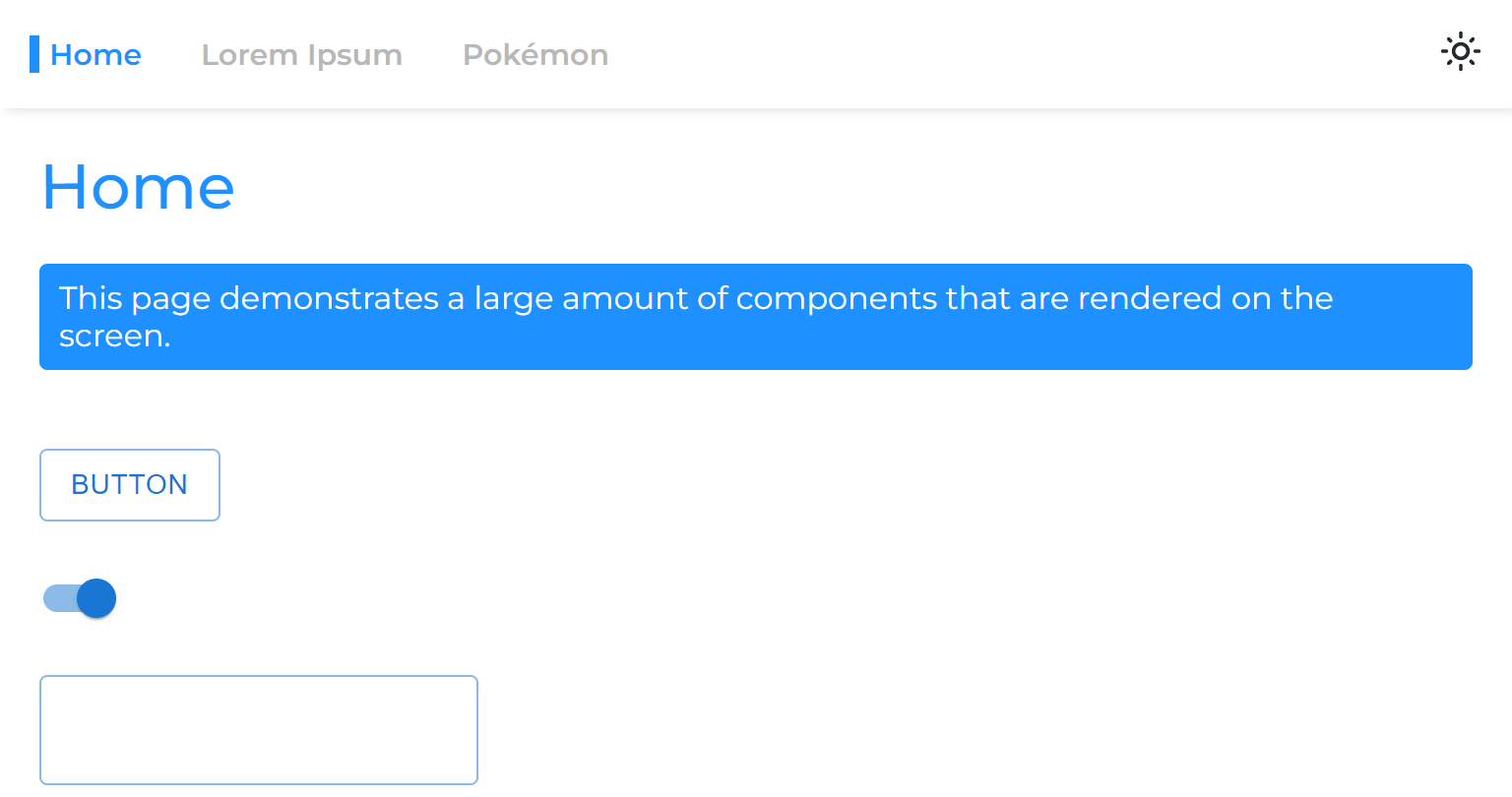
これは、サスペンスでルートのみを包むという一般的なアプローチのために発生します。
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} React 18がuseTransitionフックを紹介しました。これにより、いくつかの基準が満たされるまでレンダリングを遅らせることができます。
このフックを使用して、準備が整うまでページのナビゲーションを遅らせます。
UsetransitionNavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigatenavigationlink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkこれで、Asyncページはメインアプリから分割されたことがないと感じるでしょう。
リンク上(デスクトップ)をホバリングするとき、またはリンクがビューポート(モバイル)を入力するときに、他のページデータをプリロードできます。
navigationlink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >これにより、APIサーバーが不必要にロードされる可能性があることに注意してください。
一部のユーザーは、アプリを長時間開いたままにしているため、実行中にアプリを再検証(新しい資産をダウンロード)することです。
Service-Worker-Registration.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}上記のコードは、1時間ごとにアプリを再確認します。
再検証プロセスは非常に安価です。これは、サービスワーカーのみを模索することを含むためです(変更されない場合は304変更されていないステータスコードを返します)。
サービスワーカーが変更されると、新しい資産が利用可能であることを意味し、選択的にダウンロードされてキャッシュされます。
バンドルを多くの小さなチャンクに分割し、アプリのキャッシュ能力を大幅に改善しました。
すべてのページを分割して、1つをロードすると、関連性があることだけがすぐにダウンロードされることです。
アプリの最初の(キャッシュレス)ロードを非常に高速にすることができました。ページがロードするために必要なものはすべて動的に注入されます。
ページのデータをプリロードして、CSRアプリが知っている滝を取得する有名なデータを排除します。
さらに、すべてのページをPrecacheするため、メインバンドルコードから分割されていないように見えます。
これらはすべて、開発者エクスペリエンスを妥協せずに達成し、どのJSフレームワークを選択するかを決定することなく達成されました。
静的アプリの最大の利点は、完全にCDNから提供できることです。
CDNには、「エッジネットワーク」とも呼ばれる多くのポップ(存在ポイント)があります。これらのポップは世界中に配布されているため、リモートサーバーよりもはるかに高速なすべての地域にファイルを提供できます。
これまでで最速のCDNはCloudFlareで、250を超えるポップ(およびカウント)があります。
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarkingeded-edge-network-performance
CloudFlareページを使用してアプリを簡単に展開できます。
https://pages.cloudflare.com
このセクションを終了するために、 next.jsのドキュメントサイト(完全にSSG)と比較して、アプリのベンチマークを実行します。
ミニマルなアクセシビリティページをLorem Ipsumページと比較します。どちらのページも、レンダリング批判的なチャンクに〜246kbのJSを含みます(後に来るプリロードとプリフェッチは無関係です)。
各リンクをクリックして、ライブベンチマークを実行できます。
アクセシビリティ| next.js
Lorem Ipsum |クライアント側のレンダリング
GoogleのPageSpeed Insightsベンチマーク(遅い4Gネットワークをシミュレートする)を各ページで約20回実行し、最高のスコアを選択しました。
これらは結果です:
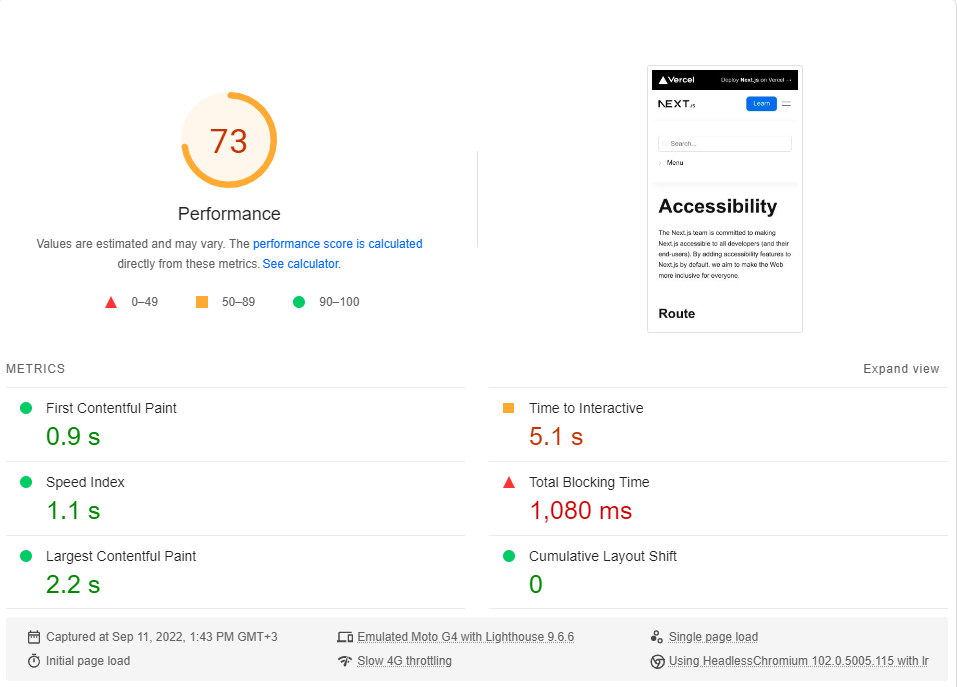
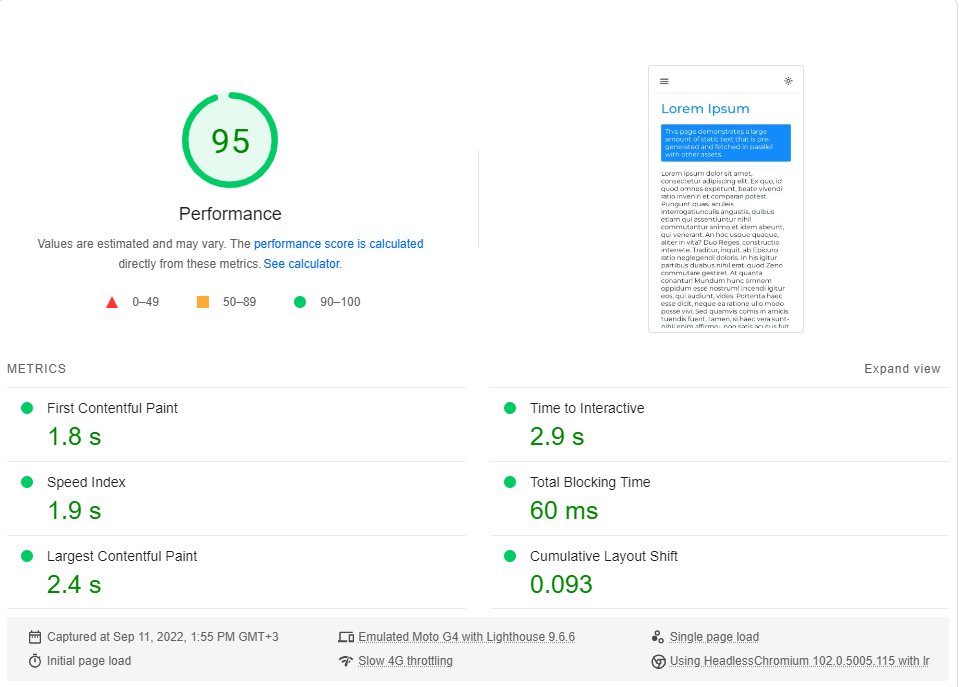
結局のところ、パフォーマンスはnext.jsではデフォルトではありません。
このベンチマークは、アプリが完全にキャッシュされたときにどのように機能するかを考慮せずに、ページの最初のロードのみをテストすることに注意してください(CSRが実際に輝く場所)。
GoogleがCSR(JS)アプリの適切なインデックスを適切にインデックス作成していることは一般的な最小限です。
それは2017年にそうだったかもしれませんが、今日の時点で:GoogleはCSRアプリをほとんど完璧にインデックスしています。
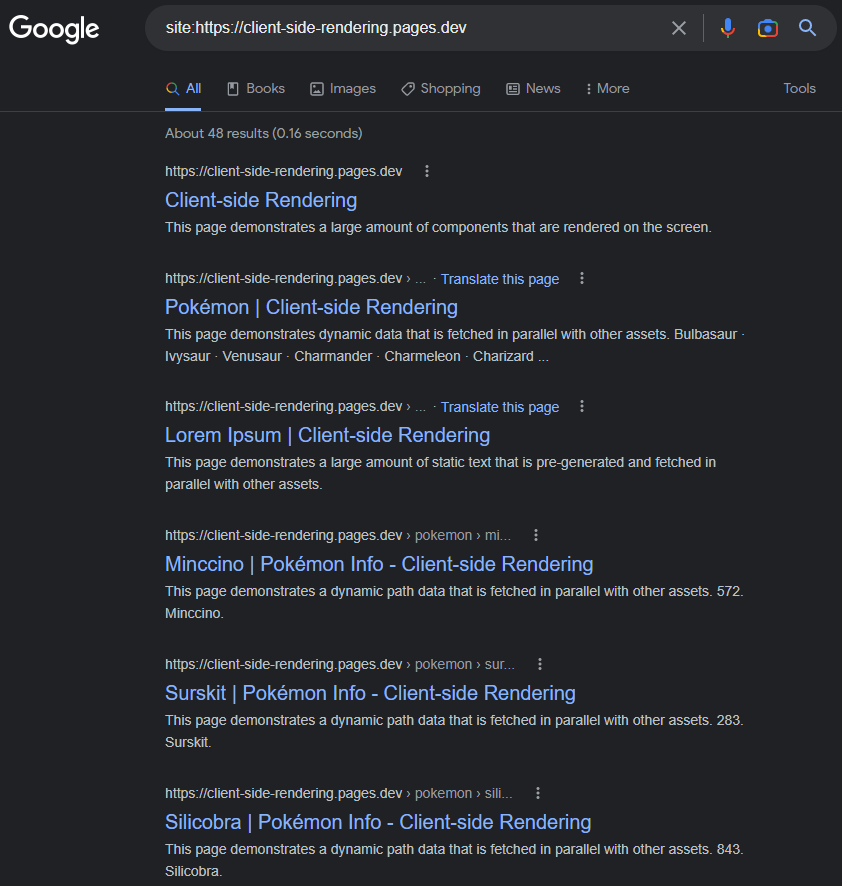
インデックス付きページには、動的に設定することを覚えている限り(このように、またはReact-Helmetなどのパッケージを使用することを覚えている限り、タイトル、説明、コンテンツ、その他すべてのSEO関連属性があります。
https://www.google.com/search?q=site:https://client-side-rendering.pages.dev
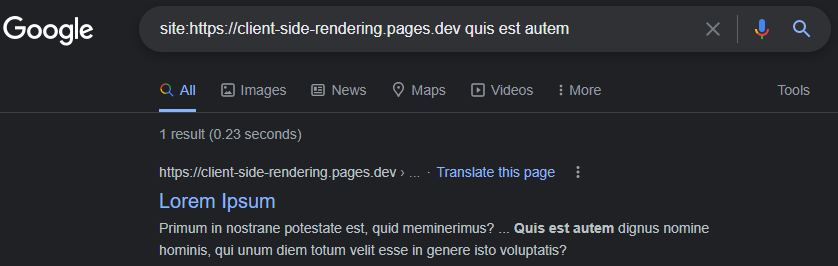
GoogleBotの能力Google検索コンソールでアプリのライブURLテストを実行することで、レンダリングJSを簡単に実証できます。
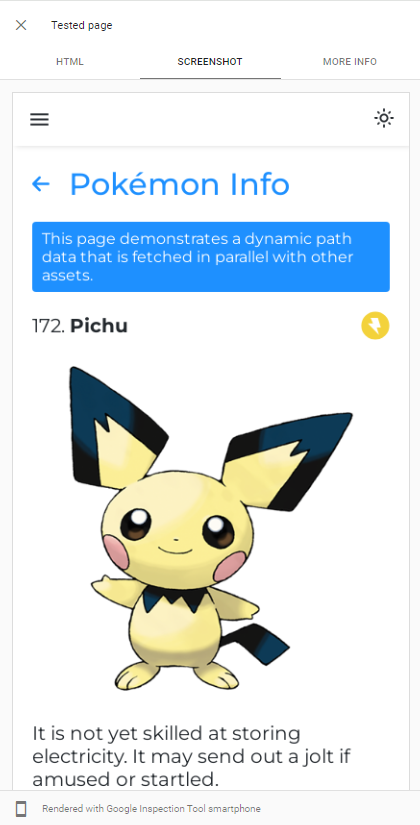
GoogleBotはChromiumの最新バージョンをクロールアプリに使用しているため、アプリが速くロードされ、データをすぐに取得することを確認することだけです。
データを取得するのに長い時間がかかる場合でも、GoogleBotは、ほとんどの場合、ページのスナップショットを取る前にそれを待ちます。
https://support.google.com/webmasters/thread/20252760/for-how-long-does-googlebot-wait-for-the-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
GoogleBotのJSクロールプロセスの詳細な説明は、こちらをご覧ください。
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
GoogleBotがいくつかのページのレンダリングに失敗した場合、それは主にGoogleが必要なリソースを費やしてWebサイトをクロールすることを嫌がるためです。つまり、クロール予算が少ないことを意味します。
これは、クロールされたページを検査することで確認できます(検索コンソールの[ビュークロール]ページをクリックして)、すべての失敗した要求に他のエラーアラートがあることを確認します(つまり、これらのリクエストはGoogleBotによって意図的に中止されました):
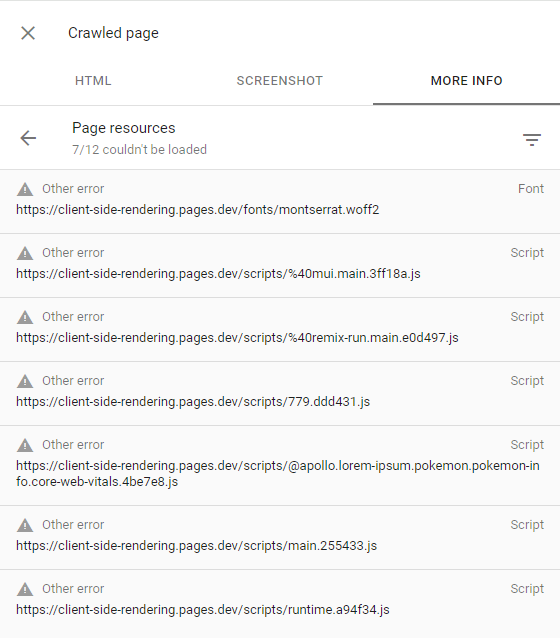
これは、Googleが興味深いコンテンツを持っていないと考えているウェブサイトや、トラフィックが非常に少ない(デモアプリなど)にのみ発生するはずです。
詳細については、https://support.google.com/webmasters/thread/4425254?hl=en&msgid=4426601をご覧ください
Bingなどの他の検索エンジンはJSをレンダリングできないため、アプリを適切にクロールするために、プレレンダーバージョンのページを提供する必要があります。
プレレンダーは、生産中のWebアプリをクロールする行為(ヘッドレスクロムを使用)し、各ページの完全なHTMLファイル(データを使用)を生成する行為です。
プレレンダリングに関しては、2つのオプションがあります。
特にGCPでは、非常に安価になる可能性があるため、サーバーレスのプレレンダーは推奨されるアプローチです。
次に、CloudFlareワーカーを使用して(たとえば)Web Crawlers( User-Agentヘッダー文字列によって識別)をプレレンダーにリダイレクトします。
public/_worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
}これは、すべてのBOT Agnets(Web Crawlers)の最新リストです:https://docs.prerender.io/docs/how-to-add-additional-bots#cloudflare。リストからgooglebotを除外することを忘れないでください。
ダイナミックレンダリングとも呼ばれるプレレンダリングは、 Microsoftによって奨励されており、Twitterを含む多くの人気のあるWebサイトで頻繁に使用されています。
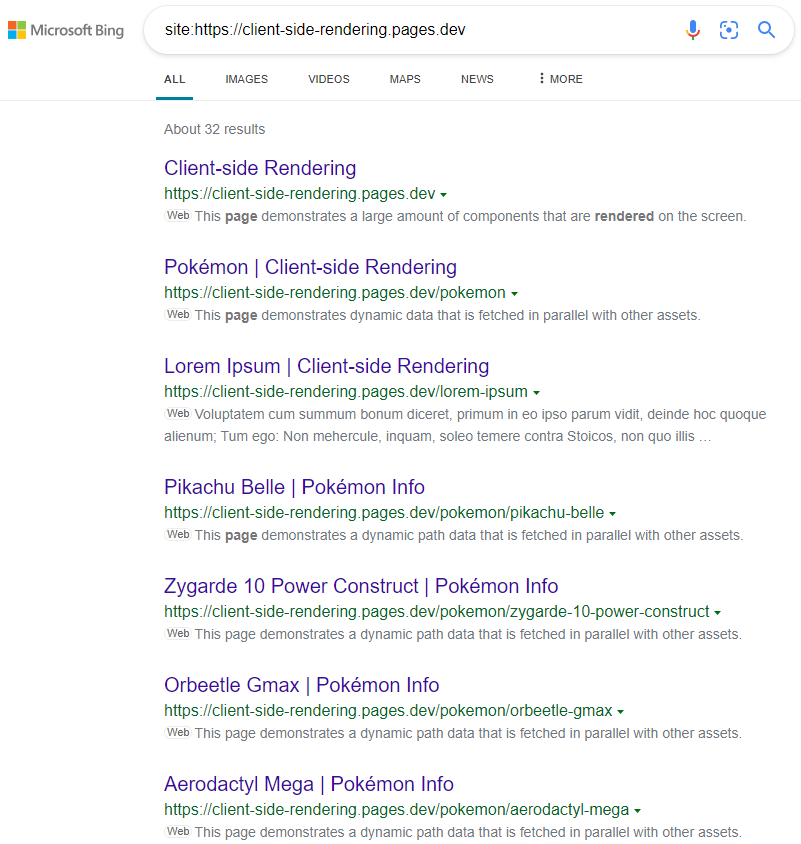
結果は予想通りです。
https://www.bing.com/search?q = site%3Ahttps%3a%2FFFFFFCLIENT-SIDERENDERING.PAGES.DEV
CSS-in-JSを使用する場合、スタイルをDOMに省略したい場合は、事前貸付中に迅速な最適化を無効にできることに注意してください。
ソーシャルメディアでCSRアプリリンクを共有すると、リンクするページに関係なく、プレビューは同じままであることがわかります。
これは、ほとんどのCSRアプリにはコンテンツレスのHTMLファイルが1つしかなく、ソーシャルメディアクローラーがJSをレンダリングしないために発生します。
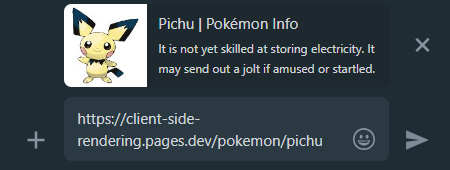
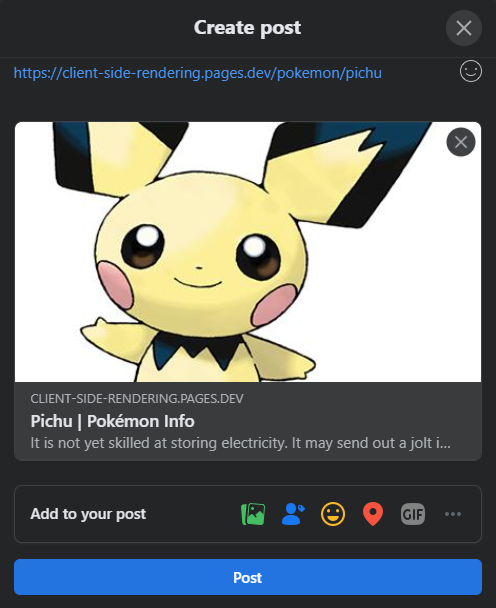
これは、プレレンダリングが再び私たちの援助に来る場所であり、各ページの適切な共有プレビューを生成します。
WhatsApp:
Facebook :
すべてのアプリページを検索エンジンに発見できるようにするには、すべてのWebサイトルートを指定するsitemap.xmlファイルを作成することをお勧めします。
既に集中ページを持っているため、ビルド時にサイトマップを簡単に生成できます。
create-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )これにより、次のサイトマップが発生します。
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >サイトマップをGoogle検索コンソールおよびBing Webmasterツールに手動で送信できます。
上記のように、すべてのレンダリング方法の詳細な比較は、https://client-side-rendering.pages.dev/comparisonで見つけることができます。
静的ファイルの利点を見てきました。それらはキャッシュ可能であり、サーバーを必要とせずに近くのCDNから提供することができます。
これにより、SSGはCSRとSSRの両方の利点を組み合わせていると信じるようになります。アプリは、APIサーバーの応答時間とは無関係に視覚的にロード( FCP )になります。
ただし、実際には、SSGには大きな制限があります。
JSは最初の瞬間にアクティブではないため、JSに依存するものはすべて表示されるだけでなく、表示されないか、誤って表示されます( window.matchMedia関数に依存するコンポーネントなど)。
この問題の典型的な例は、次のWebサイトで見ることができます。
https://death-to-ie11.com
タイマーがすぐに表示されない方法に注目してください。これは、JSによって生成され、ダウンロードと実行に時間がかかるためです。
また、いくつかのフィルターが適用されたVercelの「ガイド」ページを更新するときに、同様の問題があります。
https://vercel.com/guides?topics = analytics
これは65536 (2^16)の可能なフィルターの組み合わせがあり、各組み合わせを別のHTMLファイルとして保存するには、多くのサーバーストレージが必要になるために発生します。
そのため、すべてのデータを含む単一のguides.htmlファイルを生成しますが、この静的ファイルは、JSがロードされるまでどのフィルターが適用され、レイアウトシフトが発生します。
静的な再生が増加していても、ユーザーはまだキャッシュされていないページにアクセスしても(SSRのように)サーバーの応答を待つ必要があることに注意することが重要です。
この問題のもう1つの例は、JSアニメーションです。最初は静的に見え、JSがロードされたらアニメーションのみを開始する可能性があります。
この遅延した機能がユーザーエクスペリエンスに害を及ぼす多くのインスタンスがあります。たとえば、WebサイトがJSのロード後にナビゲーションバーを表示する場合など(ユーザー情報のエントリが存在するかどうかを確認するためにローカルストレージに依存するため)。
特にeコマースのWebサイトの別の重要な問題は、SSGページが古いデータを表示する可能性があることです(製品の価格や可用性など)。
これがまさに、主要なeコマースのWebサイトがSSGを使用していない理由です。
高速なインターネット接続の下で、CSRとSSRの両方が優れていること(両方とも最適化されている限り)をパフォーマンスし、接続速度が高いほど、読み込み時間の面で近づくことが事実です。
ただし、遅い接続(モバイルネットワークなど)を扱う場合、SSRは読み込み時間に関してCSRよりも優位性があるようです。
SSRアプリはサーバーでレンダリングされるため、ブラウザは完全に構成されたHTMLファイルを受信しているため、JSがダウンロードするのを待つことなくページをユーザーに表示できます。 JSが最終的にダウンロードされ、解析されると、フレームワークは機能性でDOMを「水分補給」することができます(再構築する必要はありません)。
それは大きな利点のように思えますが、この動作は、特に遅い接続で、望ましくない副作用を導入します。
JSがロードされるまで、ユーザーは希望する場所をクリックすることができますが、アプリはJSベースのイベントのいずれにも反応しません。
ボタンがユーザーインタラクションに応答しない場合、これは悪いユーザーエクスペリエンスですが、デフォルトのイベントが防止されていない場合、はるかに大きな問題になります。
これは、next.jsのWebサイトと、高速3G接続でのクライアント側のレンダリングアプリの比較です。
ここで何が起こったのですか?
JSはまだロードされていないため、次の.JSのWebサイトでは、アンカータグ要素( <a> )のデフォルトの動作が別のページに移動するのを防ぐことができなかったため、クリックするたびにページ全体のリロードがトリガーされました。
そして、接続が遅いほど、この問題はより深刻になります。
言い換えれば、SSRがCSRよりもパフォーマンスエッジを持っているはずだった場合、ユーザーエクスペリエンスを大幅に低下させる可能性のある非常に「危険な」動作が見られます。
CSRアプリでこの問題が発生することは不可能です。それらがレンダリングされた瞬間から、JSはすでに完全にロードされています。
クライアント側のレンダリングパフォーマンスは、初期の読み込み時間の観点からSSRよりもさらに優れていることがわかりました(そして、ナビゲーション時間でははるかに上回ります)。
また、GoogleBotはクライアント側のレンダリングされたアプリを完璧にインデックスできること、そして他のすべてのボットとクローラーを提供するプレレンダーサーバーを簡単にセットアップできることを確認しました。
そして最も重要なことは、いくつかのファイルを追加してプレレンダーサービスを使用するだけで、これらすべてを達成したことです。そのため、既存のCSRアプリはすべて、これらの変更を迅速かつ簡単に実装し、それらから利益を得ることができるはずです。
これらの事実は、SSRを使用する説得力のある理由はないという結論につながります。 Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


