client side rendering
1.0.0
Este projeto é um estudo de caso de RSE, explora o potencial dos aplicativos renderizados do lado do cliente em comparação com a renderização do lado do servidor.
Uma comparação detalhada de todos os métodos de renderização pode ser encontrada na página de comparação deste projeto: https://client-side-rendering.pages.dev/comparison
A renderização do lado do cliente (RSE) refere-se ao envio de ativos estáticos para o navegador da Web e permitindo que ele lide com todo o processo de renderização do aplicativo.
A renderização do lado do servidor (SSR) envolve renderizar todo o aplicativo (ou página) no servidor e entregar um documento HTML pré-renderizado pronto para exibição.
A geração estática do local (SSG) é o processo de pré-geração de páginas HTML como ativos estáticos, que são enviados e exibidos pelo navegador.
Ao contrário da crença comum, o processo SSR em estruturas modernas como React , Angular , Vue e Sieve resulta na renderização de aplicativos duas vezes: uma vez no servidor e novamente no navegador (isso é conhecido como "hidratação"). Sem essa segunda renderização, o aplicativo seria estático e desinterativo, se comportando essencialmente como uma página da web "sem vida".
Curiosamente, o processo de hidratação não parece ser mais rápido que uma renderização típica (excluindo a fase de pintura, é claro).
Também é importante observar que os aplicativos SSG também devem passar por hidratação.
Tanto no SSR quanto no SSG, o documento HTML é totalmente construído, fornecendo os seguintes benefícios:
Por outro lado, os aplicativos de RSE oferecem as seguintes vantagens:
Neste estudo de caso, focaremos na RSE e exploraremos maneiras de superar suas aparentes limitações, alavancando seus pontos fortes no pico.
Todas as otimizações serão incorporadas ao aplicativo implantado, que pode ser encontrado aqui: https://client-side-rendering.pages.dev.
"Recentemente, a SSR (renderização do lado do servidor) conquistou o mundo do front-end JavaScript. O fato de você agora poder renderizar seus sites e aplicativos no servidor antes de enviá-los para seus clientes é uma idéia absolutamente revolucionária (e não o que todo mundo estava fazendo antes que os aplicativos do lado do cliente JS fiquem populares em primeiro lugar ...).
No entanto, as mesmas críticas válidas para sites PHP, ASP, JSP, e outros) são válidas para a renderização do lado do servidor hoje. É lento, quebra com bastante facilidade e é difícil de implementar adequadamente.
A coisa é que, apesar do que todos podem estar lhe dizendo, você provavelmente não precisa de SSR. Você pode obter quase todas as vantagens disso (sem as desvantagens) usando a pré -alerta ".
~ Plugin de spa de pré -render
Nos últimos anos, a renderização do lado do servidor ganhou popularidade significativa na forma de estruturas como Next.js e Remix a ponto de os desenvolvedores frequentemente o padrão de usá-los sem entender completamente suas limitações, mesmo em aplicativos que não precisam de SEO (por exemplo, aqueles com requisitos de login).
Embora o SSR tenha suas vantagens, essas estruturas continuam enfatizando sua velocidade ("desempenho como padrão"), sugerindo que a renderização do lado do cliente (RSE) é inerentemente lenta.
Além disso, existe um equívoco generalizado de que o SEO perfeito só pode ser alcançado com SSR e que os aplicativos de CSR não podem ser otimizados para os rastreadores de mecanismos de pesquisa.
Outro argumento comum para o SSR é que, à medida que os aplicativos da Web aumentam, seus tempos de carregamento continuarão aumentando, levando a um desempenho ruim do FCP para aplicativos de CSR.
Embora seja verdade que os aplicativos estejam se tornando mais ricos em recursos, o tamanho de uma única página deve realmente diminuir com o tempo.
Isso se deve à tendência de criar versões menores e mais eficientes de bibliotecas e estruturas, como Zustand , Day.js , Headless-Ui e React-Router V6 .
Também podemos observar uma redução no tamanho das estruturas ao longo do tempo: angular (74,1kb), react (44,5kb), vue (34kb), sólido (7,6kb) e suja (1,7kb).
Essas bibliotecas contribuem significativamente para o peso geral dos scripts de uma página da web.
Com a divisão adequada do código, o tempo de carregamento inicial de uma página pode diminuir com o tempo.
Este projeto implementa um aplicativo básico de CSR com otimizações como divisão de código e pré-carregamento. O objetivo é que o tempo de carregamento das páginas individuais permaneça estável à medida que o aplicativo escala.
O objetivo é simular a estrutura do pacote de um aplicativo de grau de produção e minimizar os tempos de carregamento por meio de solicitações paralelas.
É importante observar que melhorar o desempenho não deve ter o custo da experiência do desenvolvedor. Portanto, a arquitetura deste projeto será apenas ligeiramente modificada a partir de uma configuração típica de reação, evitando a estrutura rígida e opinativa das estruturas como o Next.js ou as limitações do SSR em geral.
Este estudo de caso se concentrará em dois aspectos principais: desempenho e SEO. Exploraremos como alcançar as principais pontuações nas duas áreas.
Observe que, embora este projeto seja implementado usando o React, a maioria das otimizações é agnóstico da estrutura e é puramente baseada no pacote e no navegador da web.
Assumiremos uma configuração padrão do WebPack (RSPACK) e adicionaremos as personalizações necessárias à medida que progredimos.
A primeira regra geral é minimizar as dependências e, entre elas, escolher as com os menores tamanhos de arquivo.
Por exemplo:
Podemos usar o Day.js em vez de momento , Zustand em vez de Redux Toolkit , etc.
Isso é importante não apenas para aplicativos de CSR, mas também para aplicativos SSR (e SSG), pois pacotes maiores resultam em tempos de carga mais longos, atrasando quando a página se torna visível ou interativa.
Idealmente, todo arquivo hashed deve ser armazenado em cache e index.html nunca deve ser armazenado em cache.
Isso significa que o navegador abrigaria inicialmente main.[hash].js

No entanto, como main.js inclui todo o pacote, a menor alteração no código faria com que seu cache expire, o que significa que o navegador teria que baixá -lo novamente.
Agora, que parte do nosso pacote compreende a maior parte do seu peso? A resposta são as dependências , também chamadas de fornecedores .
Portanto, se pudéssemos dividir os fornecedores em seu próprio pedaço de hash, isso permitiria uma separação entre nosso código e o código dos fornecedores, levando a menos invalidações de cache.
Vamos adicionar a seguinte otimização ao nosso arquivo de configuração:
rspack.config.js
export default ( ) => {
return {
optimization : {
runtimeChunk : 'single' ,
splitChunks : {
chunks : 'initial' ,
cacheGroups : {
vendors : {
test : / [\/]node_modules[\/] / ,
name : 'vendors'
}
}
}
}
}
} Isso criará um vendors.[hash].js Arquivo:

Embora isso seja uma melhoria substancial, o que aconteceria se atualizássemos uma dependência muito pequena?
Nesse caso, todo o cache do Chunk de fornecedores invalidará.
Portanto, para melhorá -lo ainda mais, dividiremos cada dependência ao seu próprio hash de hash:
rspack.config.js
- name: 'vendors'
+ name: module => {
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+
+ return moduleName.replace('@', '')
+ } Isso criará arquivos como react-dom.[hash].js que contêm um único grande fornecedor e um [id].[hash].js Arquivo que contém todos os fornecedores restantes (pequenos):
Mais informações sobre as configurações padrão (como o tamanho do limite de divisão) podem ser encontradas aqui:
https://webpack.js.org/plugins/split-chunks-plugin/#defaults
Muitos dos recursos que escrevemos acabam sendo usados apenas em algumas de nossas páginas, por isso gostaríamos que elas fossem carregadas apenas quando o usuário visitar a página em que estiver sendo usada.
Por exemplo, não gostaríamos que os usuários tenham que esperar até que o pacote React-Big-Calendar seja baixado, analisado e executado se apenas carregasse a página inicial . Só queremos que isso acontecesse quando eles visitarem a página do calendário .
A maneira como podemos conseguir isso é (de preferência) pela divisão de código baseada em rotas:
App.tsx
const Home = lazy ( ( ) => import ( /* webpackChunkName: 'home' */ 'pages/Home' ) )
const LoremIpsum = lazy ( ( ) => import ( /* webpackChunkName: 'lorem-ipsum' */ 'pages/LoremIpsum' ) )
const Pokemon = lazy ( ( ) => import ( /* webpackChunkName: 'pokemon' */ 'pages/Pokemon' ) ) Então, quando os usuários visitam a página Pokemon , eles baixam apenas os scripts principais (que incluem todas as dependências compartilhadas, como a estrutura) e o pokemon.[hash].js Chunk.
Nota: é incentivado a baixar o aplicativo inteiro para que os usuários experimentem navegações instantâneas, semelhantes a aplicativos. Mas é uma má idéia em lote de todos os ativos em um único script, atrasando a primeira renderização da página.
Esses ativos devem ser baixados de forma assíncrona e somente depois que a página solicitada pelo usuário terminou de renderizar e ficar totalmente visível.
A divisão de código tem uma falha importante - o tempo de execução não sabe quais pedaços assíncronos são necessários até que o script principal seja executado, levando -os a ser buscados em um atraso significativo (já que eles fazem outra viagem de ida e volta para a CDN):

A maneira como podemos resolver esse problema é escrever um plug -in personalizado que incorporará um script no documento que será responsável por pré -carregar ativos relevantes:
rspack.config.js
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [ new InjectAssetsPlugin ( ) ]
}
}scripts/inject-assets-plugin.js
import { join } from 'node:path'
import { readFileSync } from 'node:fs'
import HtmlPlugin from 'html-webpack-plugin'
import pagesManifest from '../src/pages.js'
const __dirname = import . meta . dirname
const getPages = rawAssets => {
const pages = Object . entries ( pagesManifest ) . map ( ( [ chunk , { path , title } ] ) => {
const script = rawAssets . find ( name => name . includes ( `/ ${ chunk } .` ) && name . endsWith ( '.js' ) )
return { path , script , title }
} )
return pages
}
class InjectAssetsPlugin {
apply ( compiler ) {
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
HtmlPlugin . getCompilationHooks ( compilation ) . beforeEmit . tapAsync ( 'InjectAssetsPlugin' , ( data , callback ) => {
const preloadAssets = readFileSync ( join ( __dirname , '..' , 'scripts' , 'preload-assets.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
let { html } = data
html = html . replace (
'</title>' ,
( ) => `</title><script id="preload-data">const pages= ${ stringifiedPages } n ${ preloadAssets } </script>`
)
callback ( null , { ... data , html } )
} )
} )
}
}
export default InjectAssetsPluginscripts/pré -ad-assets.js
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
const preloadAssets = ( ) => {
let { pathname } = window . location
if ( pathname !== '/' ) pathname = pathname . replace ( / /$ / , '' )
const matchingPages = pages . map ( page => ( { ... isMatch ( pathname , page . path ) , ... page } ) ) . filter ( ( { match } ) => match )
if ( ! matchingPages . length ) return
const { path , title , script } = matchingPages . find ( ( { exact } ) => exact ) || matchingPages [ 0 ]
document . head . appendChild (
Object . assign ( document . createElement ( 'link' ) , { rel : 'preload' , href : '/' + script , as : 'script' } )
)
if ( title ) document . title = title
}
preloadAssets ( ) O arquivo pages.js importado pode ser encontrado aqui.
Dessa forma, o navegador é capaz de buscar o pedaço de script específico da página em paralelo com ativos críticos de renderização:
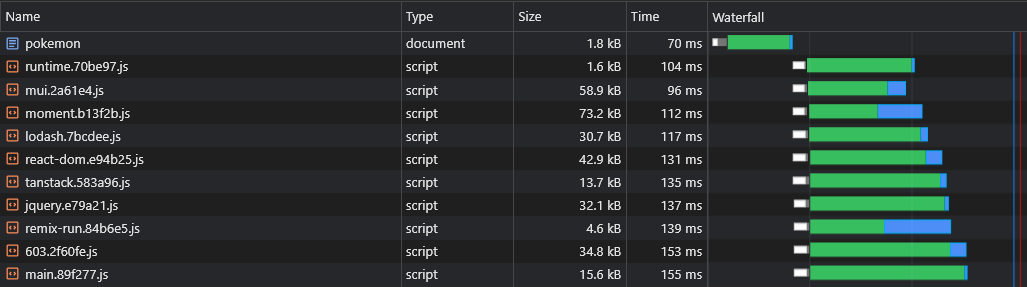
A divisão de código introduz outro problema: duplicação do fornecedor assíncrono.
Digamos que temos dois pedaços assíncronos: lorem-ipsum.[hash].js e pokemon.[hash].js . Se ambos incluirem a mesma dependência que não faz parte do pedaço principal, isso significa que o usuário baixará essa dependência duas vezes .
Portanto, se isso dito dependência é moment e pesa 72kb minziPsped, o tamanho de ambos os chunks de assíncronos será de pelo menos 72kb.
Precisamos dividir essa dependência desses pedaços assíncronos para que ela possa ser compartilhada entre eles:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
+ chunks: 'all',
name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
}
}
}
} Agora, ambos lorem-ipsum.[hash].js e pokemon.[hash].js usará o moment.[hash].js
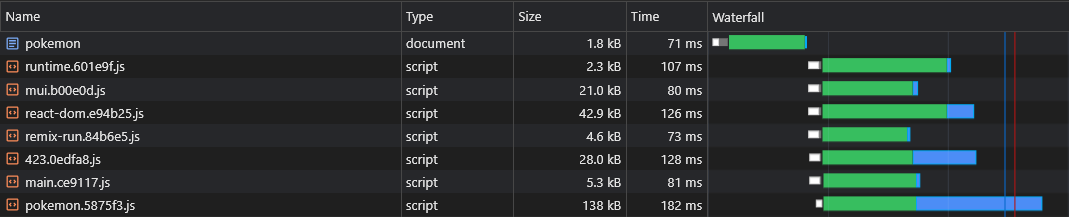
No entanto, não temos como dizer quais pedaços de fornecedores assíncicos serão divididos antes de construirmos o aplicativo, para que não soubéssemos quais pedaços de fornecedores assíncronos precisamos pré -carregar (consulte a seção "PRELAGELING ASYNC PHUXCS"):
É por isso que anexaremos os nomes dos pedaços ao nome do fornecedor assíncrono:
rspack.config.js
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
test: /[\/]node_modules[\/]/,
chunks: 'all',
- name: ({ context }) => (context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1].replace('@', '')
+ name: (module, chunks) => {
+ const allChunksNames = chunks.map(({ name }) => name).join('.')
+ const moduleName = (module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/) || [])[1]
+ return `${moduleName}.${allChunksNames}`.replace('@', '')
}
}
}
}
}scripts/inject-assets-plugin.js
const getPages = rawAssets => {
const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
- const script = rawAssets.find(name => name.includes(`/${chunk}.`) && name.endsWith('.js'))
+ const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts }
})
return pages
}scripts/pré -ad-assets.js
- const { path, title, script } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ scripts.forEach(script => {
document.head.appendChild(
Object.assign(document.createElement('link'), { rel: 'preload', href: '/' + script, as: 'script' })
)
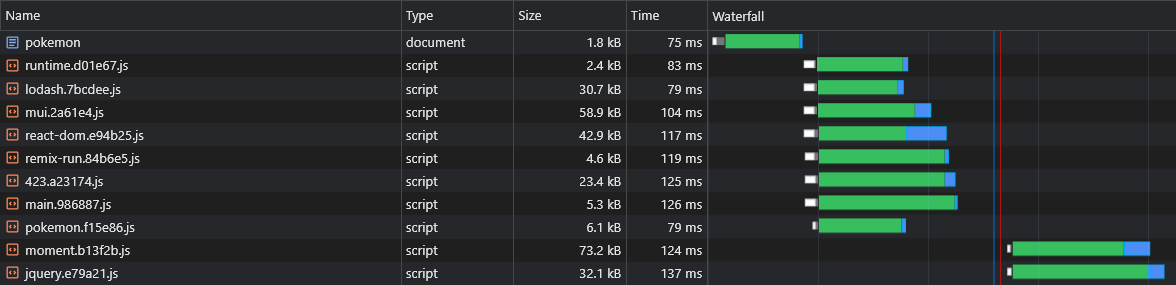
+ })Agora, todos os pedaços de vendedores assíncronos serão buscados em paralelo com seus pais assíncronos:
Uma das presumidas desvantagens da RSE sobre a SSR é que os dados da página (solicitações de busca) serão disparados somente após o download do JS, analisado e executado no navegador:
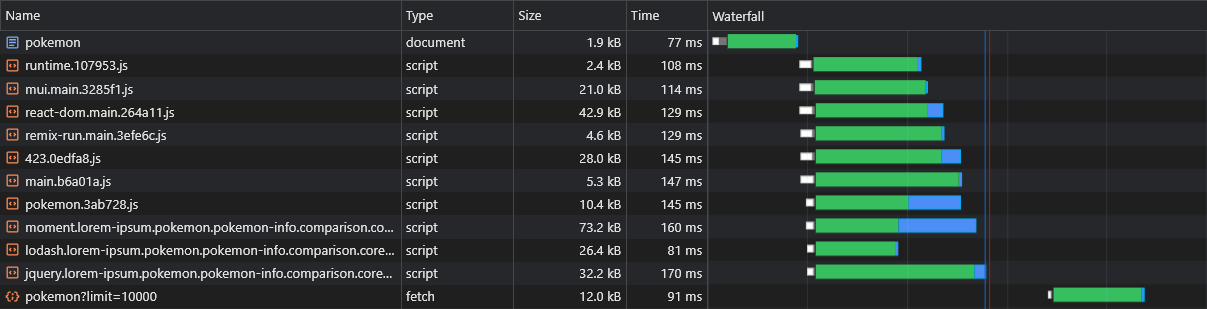
Para superar isso, usaremos a pré -carga mais uma vez, desta vez para os próprios dados, corrigindo a API fetch :
scripts/inject-assets-plugin.js
const getPages = rawAssets => {
- const pages = Object.entries(pagesManifest).map(([chunk, { path, title }]) => {
+ const pages = Object.entries(pagesManifest).map(([chunk, { path, title, data, preconnect }]) => {
const scripts = rawAssets.filter(name => new RegExp(`[/.]${chunk}\.(.+)\.js$`).test(name))
- return { path, title, script }
+ return { path, title, scripts, data, preconnect }
})
return pages
}
HtmlPlugin.getCompilationHooks(compilation).beforeEmit.tapAsync('InjectAssetsPlugin', (data, callback) => {
const preloadAssets = readFileSync(join(__dirname, '..', 'scripts', 'preload-assets.js'), 'utf-8')
const rawAssets = compilation.getAssets()
const pages = getPages(rawAssets)
+ const stringifiedPages = JSON.stringify(pages, (_, value) => {
+ return typeof value === 'function' ? `func:${value.toString()}` : value
+ })
let { html } = data
html = html.replace(
'</title>',
- () => `</title><script id="preload-data">const pages=${JSON.stringify(pages)}n${preloadAssets}</script>`
+ () => `</title><script id="preload-data">const pages=${stringifiedPages}n${preloadAssets}</script>`
)
callback(null, { ...data, html })
})scripts/pré -ad-assets.js
const preloadResponses = {}
const originalFetch = window.fetch
window.fetch = async (input, options) => {
const requestID = `${input.toString()}${options?.body?.toString() || ''}`
const preloadResponse = preloadResponses[requestID]
if (preloadResponse) {
if (!options?.preload) delete preloadResponses[requestID]
return preloadResponse
}
const response = originalFetch(input, options)
if (options?.preload) preloadResponses[requestID] = response
return response
}
.
.
.
const getDynamicProperties = (pathname, path) => {
const pathParts = path.split('/')
const pathnameParts = pathname.split('/')
const dynamicProperties = {}
for (let i = 0; i < pathParts.length; i++) {
if (pathParts[i].startsWith(':')) dynamicProperties[pathParts[i].slice(1)] = pathnameParts[i]
}
return dynamicProperties
}
const preloadAssets = () => {
- const { path, title, scripts } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
+ const { path, title, scripts, data, preconnect } = matchingPages.find(({ exact }) => exact) || matchingPages[0]
.
.
.
data?.forEach(({ url, ...request }) => {
if (url.startsWith('func:')) url = eval(url.replace('func:', ''))
const constructedURL = typeof url === 'string' ? url : url(getDynamicProperties(pathname, path))
fetch(constructedURL, { ...request, preload: true })
})
preconnect?.forEach(url => {
document.head.appendChild(Object.assign(document.createElement('link'), { rel: 'preconnect', href: url }))
})
}
preloadAssets() Lembrete: o arquivo pages.js pode ser encontrado aqui.
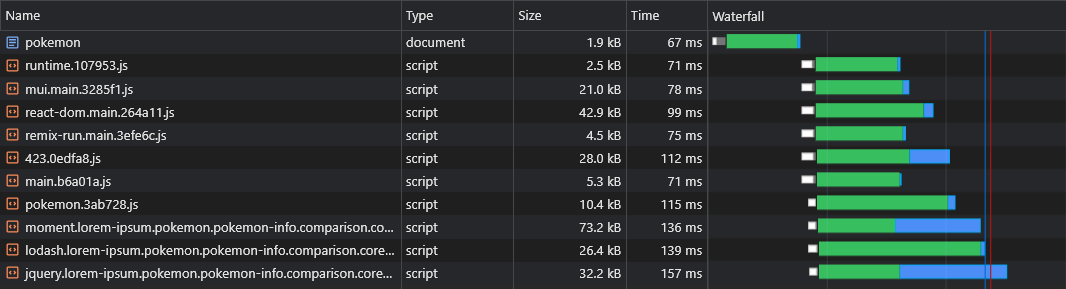
Agora podemos ver que os dados estão sendo buscados imediatamente:
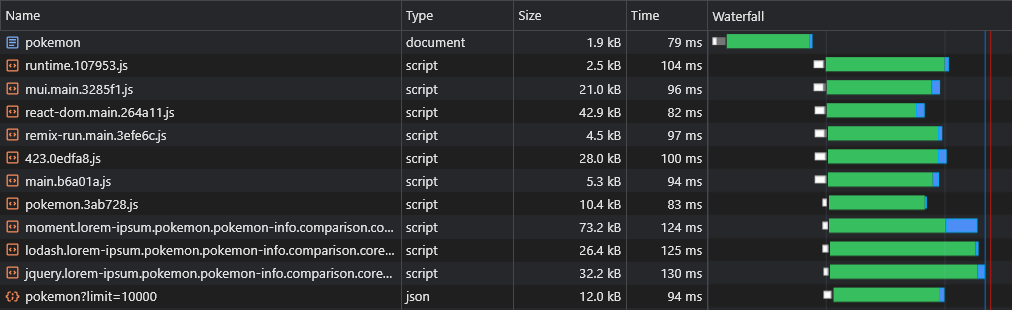
Com o script acima, podemos até pré -carregar dados de rotas dinâmicas (como Pokemon/: Name ).
Os usuários devem ter uma experiência de navegação suave em nosso aplicativo.
No entanto, a divisão de todas as páginas causa um atraso notável na navegação, pois cada página deve ser baixada (sob demanda) antes que ela possa ser renderizada na tela.
Gostaríamos de pré -procurar e armazenar em cache todas as páginas com antecedência.
Podemos fazer isso escrevendo um funcionário de serviço simples:
rspack.config.js
import { InjectManifestPlugin } from 'inject-manifest-plugin'
import InjectAssetsPlugin from './scripts/inject-assets-plugin.js'
export default ( ) => {
return {
plugins : [
new InjectManifest ( {
include : [ / fonts/ / , / scripts/.+.js$ / ] ,
swSrc : join ( __dirname , 'public' , 'service-worker.js' ) ,
compileSrc : false ,
maximumFileSizeToCacheInBytes : 10000000
} ) ,
new InjectAssetsPlugin ( )
]
}
}src/utils/serviço-worker-registration.ts
const register = ( ) => {
window . addEventListener ( 'load' , async ( ) => {
try {
await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
} catch ( err ) {
console . error ( err )
}
} )
}
const unregister = async ( ) => {
try {
const registration = await navigator . serviceWorker . ready
await registration . unregister ( )
console . log ( 'Service worker unregistered!' )
} catch ( err ) {
console . error ( err )
}
}
if ( 'serviceWorker' in navigator ) {
const shouldRegister = process . env . NODE_ENV !== 'development'
if ( shouldRegister ) register ( )
else unregister ( )
}Public/Service-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const precacheAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssets ( ) )
self . skipWaiting ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Agora, todas as páginas serão pré -buscadas e armazenadas em cache antes mesmo de o usuário tentar navegar para elas.
Essa abordagem também gerará um cache de código completo.
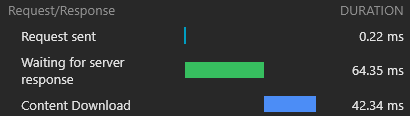
Ao inspecionar nosso arquivo react-dom.js de 43kb, podemos ver que o tempo que levou para o pedido de retorno foi de 60ms, enquanto o tempo necessário para baixar o arquivo era 3ms:

Isso demonstra o fato bem conhecido de que a RTT tem um enorme impacto nos tempos de carregamento das páginas da web, às vezes até mais do que a velocidade de download, e mesmo quando os ativos são servidos de uma borda CDN próxima, como no nosso caso.
Além disso, mais importante, podemos ver que, depois que o arquivo HTML é baixado, temos um grande tempo onde o navegador permanece ocioso e apenas aguarda a chegada dos scripts:
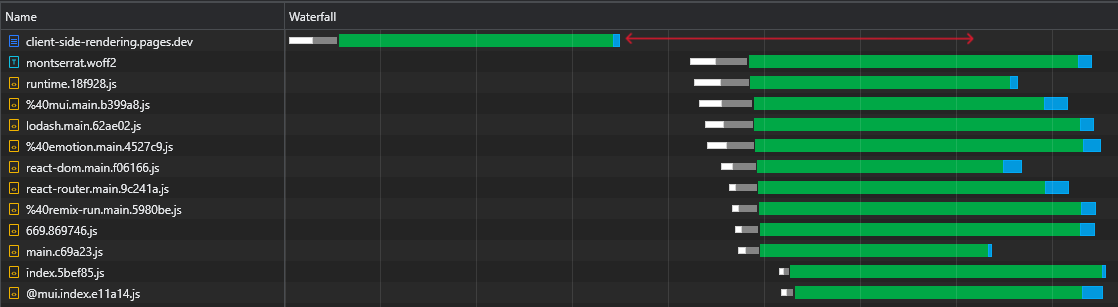
Isso é muito tempo precioso (marcado em vermelho) que o navegador poderia usar para baixar, analisar e até executar scripts, acelerando a visibilidade e a interatividade da página.
Essa ineficiência será reincidida sempre que os ativos mudam (cache parcial). Isso não é algo que só acontece na primeira visita.
Então, como podemos eliminar esse tempo ocioso?
Poderíamos incluir todos os scripts iniciais (críticos) do documento, para que eles comecem a baixar, analisar e executar até que os ativos da página assíncrona cheguem:

Podemos ver que o navegador agora recebe seus scripts iniciais sem ter que enviar outra solicitação para a CDN.
Portanto, o navegador enviará primeiro solicitações para os pedaços assíncronos e os dados pré -carregados e, embora estejam pendentes, continuará baixando e executando os scripts principais.
Podemos ver que os pedaços assíncronos começam a baixar (marcado em azul) logo após o término do arquivo html download, analisar e executar, o que economiza muito tempo.
Embora essa mudança esteja fazendo uma diferença significativa nas redes rápidas, é ainda mais crucial para redes mais lentas, onde o atraso é maior e a RTT é muito mais impactante.
No entanto, esta solução tem 2 grandes problemas:
Para superar esses problemas, não podemos mais seguir um arquivo HTML estático e, portanto, deixaremos o poder de um servidor. Ou, mais precisamente, o poder de um trabalhador sem servidor CloudFlare.
Esse trabalhador deve interceptar todas as solicitações de documentos HTML e adaptar uma resposta que a encaixe perfeitamente.
Todo o fluxo deve ser descrito da seguinte maneira:
X-Cached na solicitação. Se esse cabeçalho existir, ele iterará sobre seus valores e incluirá apenas os ativos relevantes* que estão ausentes dele na resposta. Se esse cabeçalho não existir, incluirá todos os ativos relevantes da resposta.X-Cached especificando todos os seus ativos em cache.* Ativos iniciais e específicos da página.
Isso garante que o navegador receba exatamente os ativos de que precisa (não mais, nada menos) para exibir a página atual em uma única ida e volta !
scripts/inject-assets-plugin.js
class InjectAssetsPlugin {
apply ( compiler ) {
const production = compiler . options . mode === 'production'
compiler . hooks . compilation . tap ( 'InjectAssetsPlugin' , compilation => {
.
.
.
} )
if ( ! production ) return
compiler . hooks . afterEmit . tapAsync ( 'InjectAssetsPlugin' , ( compilation , callback ) => {
let html = readFileSync ( join ( __dirname , '..' , 'build' , 'index.html' ) , 'utf-8' )
let worker = readFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , 'utf-8' )
const rawAssets = compilation . getAssets ( )
const pages = getPages ( rawAssets )
const assets = rawAssets
. filter ( ( { name } ) => / ^scripts/.+.js$ / . test ( name ) )
. map ( ( { name , source } ) => ( {
url : `/ ${ name } ` ,
source : source . source ( ) ,
parentPaths : pages . filter ( ( { scripts } ) => scripts . includes ( name ) ) . map ( ( { path } ) => path )
} ) )
const initialModuleScriptsString = html . match ( / <scripts+type="module"[^>]*>([sS]*?)(?=</head>) / ) [ 0 ]
const initialModuleScripts = initialModuleScriptsString . split ( '</script>' )
const initialScripts = assets
. filter ( ( { url } ) => initialModuleScriptsString . includes ( url ) )
. map ( asset => ( { ... asset , order : initialModuleScripts . findIndex ( script => script . includes ( asset . url ) ) } ) )
. sort ( ( a , b ) => a . order - b . order )
const asyncScripts = assets . filter ( asset => ! initialScripts . includes ( asset ) )
html = html
. replace ( / ,"scripts":s*[(.*?)] / g , ( ) => '' )
. replace ( / scripts.forEach[sS]*?data?.s*forEach / , ( ) => 'data?.forEach' )
. replace ( / preloadAssets / g , ( ) => 'preloadData' )
worker = worker
. replace ( 'INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE' , ( ) => JSON . stringify ( initialModuleScriptsString ) )
. replace ( 'INJECT_INITIAL_SCRIPTS_HERE' , ( ) => JSON . stringify ( initialScripts ) )
. replace ( 'INJECT_ASYNC_SCRIPTS_HERE' , ( ) => JSON . stringify ( asyncScripts ) )
. replace ( 'INJECT_HTML_HERE' , ( ) => JSON . stringify ( html ) )
writeFileSync ( join ( __dirname , '..' , 'build' , '_worker.js' ) , worker )
callback ( )
} )
}
}
export default InjectAssetsPluginpublic/_worker.js
const initialModuleScriptsString = INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE
const initialScripts = INJECT_INITIAL_SCRIPTS_HERE
const asyncScripts = INJECT_ASYNC_SCRIPTS_HERE
const html = INJECT_HTML_HERE
const documentHeaders = { 'Cache-Control' : 'public, max-age=0' , 'Content-Type' : 'text/html; charset=utf-8' }
const isMatch = ( pathname , path ) => {
if ( pathname === path ) return { exact : true , match : true }
if ( ! path . includes ( ':' ) ) return { match : false }
const pathnameParts = pathname . split ( '/' )
const pathParts = path . split ( '/' )
const match = pathnameParts . every ( ( part , ind ) => part === pathParts [ ind ] || pathParts [ ind ] ?. startsWith ( ':' ) )
return {
exact : match && pathnameParts . length === pathParts . length ,
match
}
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
const bypassWorker = [ 'prerender' , 'googlebot' ] . includes ( userAgent ) || pathname . includes ( '.' )
if ( bypassWorker ) return env . ASSETS . fetch ( request )
const cachedScripts = request . headers . get ( 'X-Cached' ) ?. split ( ', ' ) . filter ( Boolean ) || [ ]
const uncachedScripts = [ ... initialScripts , ... asyncScripts ] . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
if ( ! uncachedScripts . length ) {
return new Response ( html , { headers : documentHeaders } )
}
let body = html . replace ( initialModuleScriptsString , ( ) => '' )
const injectedInitialScriptsString = initialScripts
. map ( ( { url , source } ) =>
cachedScripts . includes ( url ) ? `<script src=" ${ url } "></script>` : `<script id=" ${ url } "> ${ source } </script>`
)
. join ( 'n' )
body = body . replace ( '</body>' , ( ) => `<!-- INJECT_ASYNC_SCRIPTS_HERE --> ${ injectedInitialScriptsString } n</body>` )
const matchingPageScripts = asyncScripts
. map ( asset => {
const parentsPaths = asset . parentPaths . map ( path => ( { path , ... isMatch ( pathname , path ) } ) )
const parentPathsExactMatch = parentsPaths . some ( ( { exact } ) => exact )
const parentPathsMatch = parentsPaths . some ( ( { match } ) => match )
return { ... asset , exact : parentPathsExactMatch , match : parentPathsMatch }
} )
. filter ( ( { match } ) => match )
const exactMatchingPageScripts = matchingPageScripts . filter ( ( { exact } ) => exact )
const pageScripts = exactMatchingPageScripts . length ? exactMatchingPageScripts : matchingPageScripts
const uncachedPageScripts = pageScripts . filter ( ( { url } ) => ! cachedScripts . includes ( url ) )
const injectedAsyncScriptsString = uncachedPageScripts . reduce (
( str , { url , source } ) => ` ${ str } n<script id=" ${ url } "> ${ source } </script>` ,
''
)
body = body . replace ( '<!-- INJECT_ASYNC_SCRIPTS_HERE -->' , ( ) => injectedAsyncScriptsString )
return new Response ( body , { headers : documentHeaders } )
}
}src/utils/extract-inline scripts.ts
const extractInlineScripts = ( ) => {
const inlineScripts = [ ... document . body . querySelectorAll ( 'script[id]:not([src])' ) ] . map ( ( { id , textContent } ) => ( {
url : id ,
source : textContent
} ) )
return inlineScripts
}
export default extractInlineScriptssrc/utils/serviço-worker-registration.ts
import extractInlineScripts from './extract-inline-scripts'
const register = ( ) => {
window . addEventListener (
'load' ,
async ( ) => {
try {
const registration = await navigator . serviceWorker . register ( '/service-worker.js' )
console . log ( 'Service worker registered!' )
registration . addEventListener ( 'updatefound' , ( ) => {
registration . installing ?. postMessage ( { inlineAssets : extractInlineScripts ( ) } )
} )
} catch ( err ) {
console . error ( err )
}
} ,
{ once : true }
)
}Public/Service-worker.js
const CACHE_NAME = 'my-csr-app'
const allAssets = self . __WB_MANIFEST . map ( ( { url } ) => url )
const createPromiseResolve = ( ) => {
let resolve
const promise = new Promise ( res => ( resolve = res ) )
return [ promise , resolve ]
}
const [ precacheAssetsPromise , precacheAssetsResolve ] = createPromiseResolve ( )
const getCache = ( ) => caches . open ( CACHE_NAME )
const getCachedAssets = async cache => {
const keys = await cache . keys ( )
return keys . map ( ( { url } ) => `/ ${ url . replace ( self . registration . scope , '' ) } ` )
}
const cacheInlineAssets = async assets => {
const cache = await getCache ( )
assets . forEach ( ( { url , source } ) => {
const response = new Response ( source , {
headers : {
'Cache-Control' : 'public, max-age=31536000, immutable' ,
'Content-Type' : 'application/javascript'
}
} )
cache . put ( url , response )
console . log ( `Cached %c ${ url } ` , 'color: yellow; font-style: italic;' )
} )
}
const precacheAssets = async ( { ignoreAssets } ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const assetsToPrecache = allAssets . filter ( asset => ! cachedAssets . includes ( asset ) && ! ignoreAssets . includes ( asset ) )
await cache . addAll ( assetsToPrecache )
await removeUnusedAssets ( )
await fetchDocument ( '/' )
}
const removeUnusedAssets = async ( ) => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
cachedAssets . forEach ( asset => {
if ( ! allAssets . includes ( asset ) ) cache . delete ( asset )
} )
}
const fetchDocument = async url => {
const cache = await getCache ( )
const cachedAssets = await getCachedAssets ( cache )
const cachedDocument = await cache . match ( '/' )
try {
const response = await fetch ( url , {
headers : { 'X-Cached' : cachedAssets . join ( ', ' ) }
} )
return response
} catch ( err ) {
return cachedDocument
}
}
const fetchAsset = async request => {
const cache = await getCache ( )
const cachedResponse = await cache . match ( request )
return cachedResponse || fetch ( request )
}
self . addEventListener ( 'install' , event => {
event . waitUntil ( precacheAssetsPromise )
self . skipWaiting ( )
} )
self . addEventListener ( 'message' , async event => {
const { inlineAssets } = event . data
await cacheInlineAssets ( inlineAssets )
await precacheAssets ( { ignoreAssets : inlineAssets . map ( ( { url } ) => url ) } )
precacheAssetsResolve ( )
} )
self . addEventListener ( 'fetch' , event => {
const { request } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( request . url ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Os resultados para uma carga fresca (totalmente não pouco) são excepcionais:


Na próxima carga, o CloudFlare Worker responde com um documento HTML mínimo (1,8kb) e todos os ativos são imediatamente servidos do cache.
Essa otimização nos leva a outro - dividindo pedaços para peças ainda menores.
Como regra geral, dividir o pacote em muitos pedaços pode prejudicar o desempenho. Isso ocorre porque a página não será renderizada até que todos os seus arquivos sejam baixados, e quanto mais pedaços houver, maior a probabilidade de que um deles seja adiado (pois o hardware e a velocidade da rede não são lineares).
Mas, no nosso caso, é irrelevante, já que embrulhamos todos os pedaços relevantes e, portanto, eles são buscados de uma só vez.
rspack.config.js
optimization: {
splitChunks: {
chunks: 'initial',
cacheGroups: {
vendors: {
+ minSize: 10000,
}
}
}
},Essa divisão extrema levará a uma melhor persistência do cache e, por sua vez, a tempos de carregamento mais rápidos com cache parcial.
Quando um ativo estático é obtido a partir de um CDN, ele inclui um cabeçalho ETag , que é um hash de conteúdo do recurso. Em solicitações subsequentes, o navegador verifica se possui um ETAG armazenado. Se isso acontecer, ele envia o ETAG em um cabeçalho If-None-Match . O CDN compara o ETAG recebido com o atual: se eles corresponderem, retorna um status 304 Not Modified , indicando que o navegador pode usar o ativo em cache; Caso contrário, ele retorna o novo ativo com um status 200 .
Em um aplicativo tradicional de CSR, recarregar uma página resulta no HTML obter um 304 Not Modified , com outros ativos servidos no cache. Cada rota possui um ETAG exclusivo, SO /lorem-ipsum e /pokemon têm entradas de cache diferentes, mesmo que seus ETAGs sejam idênticos.
Em um spa de CSR, como existe apenas um arquivo HTML, o mesmo ETAG é usado para cada solicitação de página. No entanto, como o ETAG é armazenado por rota, o navegador não enviará um cabeçalho If-None-Match para páginas não visitadas, levando a um status 200 e uma carga reduzida do HTML, mesmo que seja o mesmo arquivo.
No entanto, podemos criar facilmente nossa própria implementação (aprimorada) desse comportamento através da colaboração entre os trabalhadores:
scripts/inject-assets-plugin.js
+ import { createHash } from 'node:crypto'
class InjectAssetsPlugin {
apply(compiler) {
.
.
.
compiler.hooks.afterEmit.tapAsync('InjectAssetsPlugin', (compilation, callback) => {
let html = readFileSync(join(__dirname, '..', 'build', 'index.html'), 'utf-8')
let worker = readFileSync(join(__dirname, '..', 'build', '_worker.js'), 'utf-8')
.
.
.
+ const documentEtag = createHash('sha256').update(html).digest('hex').slice(0, 16)
.
.
.
worker = worker
.replace('INJECT_INITIAL_MODULE_SCRIPTS_STRING_HERE', () => JSON.stringify(initialModuleScriptsString))
.replace('INJECT_INITIAL_SCRIPTS_HERE', () => JSON.stringify(initialScripts))
.replace('INJECT_ASYNC_SCRIPTS_HERE', () => JSON.stringify(asyncScripts))
.replace('INJECT_HTML_HERE', () => JSON.stringify(html))
+ .replace('INJECT_DOCUMENT_ETAG_HERE', () => JSON.stringify(documentEtag))
writeFileSync(join(__dirname, '..', 'build', '_worker.js'), worker)
callback()
})
}
}public/_worker.js
+ const documentEtag = INJECT_DOCUMENT_ETAG_HERE
.
.
.
export default {
fetch(request, env) {
+ if (request.headers.get('If-None-Match') === documentEtag) {
+ return new Response(null, { status: 304, headers: documentHeaders })
+ }
.
.
.
}
}Public/Service-worker.js
.
.
.
const getRequestHeaders = responseHeaders => ({
'If-None-Match': responseHeaders?.get('ETag') || responseHeaders?.get('X-ETag'),
'X-Cached': JSON.stringify(allAssets)
})
.
.
.
const precacheAssets = async ({ ignoreAssets }) => {
.
.
.
+ await fetchDocument('/')
}
const fetchDocument = async url => {
const cache = await getCache()
const cachedDocument = await cache.match('/')
const requestHeaders = getRequestHeaders(cachedDocument?.headers)
try {
const response = await fetch(url, { headers: requestHeaders })
if (response.status === 304) return cachedDocument
cache.put('/', response.clone())
return response
} catch (err) {
return cachedDocument
}
} Observe que um X-ETag personalizado está incluído para situações em que o CDN não envia automaticamente um ETag .
Agora, nosso trabalhador sem servidor sempre responderá com um código de status 304 Not Modified sempre que não houver alterações, mesmo para páginas não visitadas.
Quando um trabalhador de serviço é usado, o navegador atrasa o envio da solicitação inicial de documento HTML até que o trabalhador do serviço seja carregado, o que pode causar um atraso de página leve a moderado, dependendo do hardware.
A solução nativa para esse problema é chamada de pré -carga de navegação . Implementaremos isso para garantir que a solicitação do documento seja enviada imediatamente, sem esperar que o trabalhador do serviço carregue:
src/utils/serviço-worker-registration.ts
const register = ( ) => {
.
.
.
navigator . serviceWorker ?. addEventListener ( 'message' , async event => {
const { navigationPreloadHeader } = event . data
const registration = await navigator . serviceWorker . ready
registration . navigationPreload . setHeaderValue ( navigationPreloadHeader )
} )
}Public/Service-worker.js
.
.
.
const fetchDocument = async ( { url , preloadResponse } ) => {
const cache = await getCache ( )
const cachedDocument = await cache . match ( '/' )
const requestHeaders = getRequestHeaders ( cachedDocument ?. headers )
try {
const response = await ( preloadResponse && cachedDocument
? preloadResponse
: fetch ( url , { headers : requestHeaders } ) )
if ( response . status === 304 ) return cachedDocument
cache . put ( '/' , response . clone ( ) )
self . clients . matchAll ( { includeUncontrolled : true } ) . then ( ( [ client ] ) => {
client ?. postMessage ( { navigationPreloadHeader : JSON . stringify ( getRequestHeaders ( response . headers ) ) } )
} )
return response
} catch ( err ) {
return cachedDocument
}
}
.
.
.
self . addEventListener ( 'activate' , event => event . waitUntil ( self . registration . navigationPreload ?. enable ( ) ) )
.
.
.
self . addEventListener ( 'fetch' , event => {
const { request , preloadResponse } = event
if ( request . destination === 'document' ) return event . respondWith ( fetchDocument ( { url : request . url , preloadResponse } ) )
if ( [ 'font' , 'script' ] . includes ( request . destination ) ) event . respondWith ( fetchAsset ( request ) )
} )Com esta implementação, a solicitação de documento será enviada imediatamente, independente do funcionário do serviço.
Nota: requer react (v18), esbelto ou sólido.js
Quando dividimos uma página do aplicativo principal, separamos sua fase de renderização, o que significa que o aplicativo renderizará antes que a página renderize.
Então, quando passamos de uma página assíncrona para outra, vemos um espaço em branco que permanece até que a página seja renderizada:
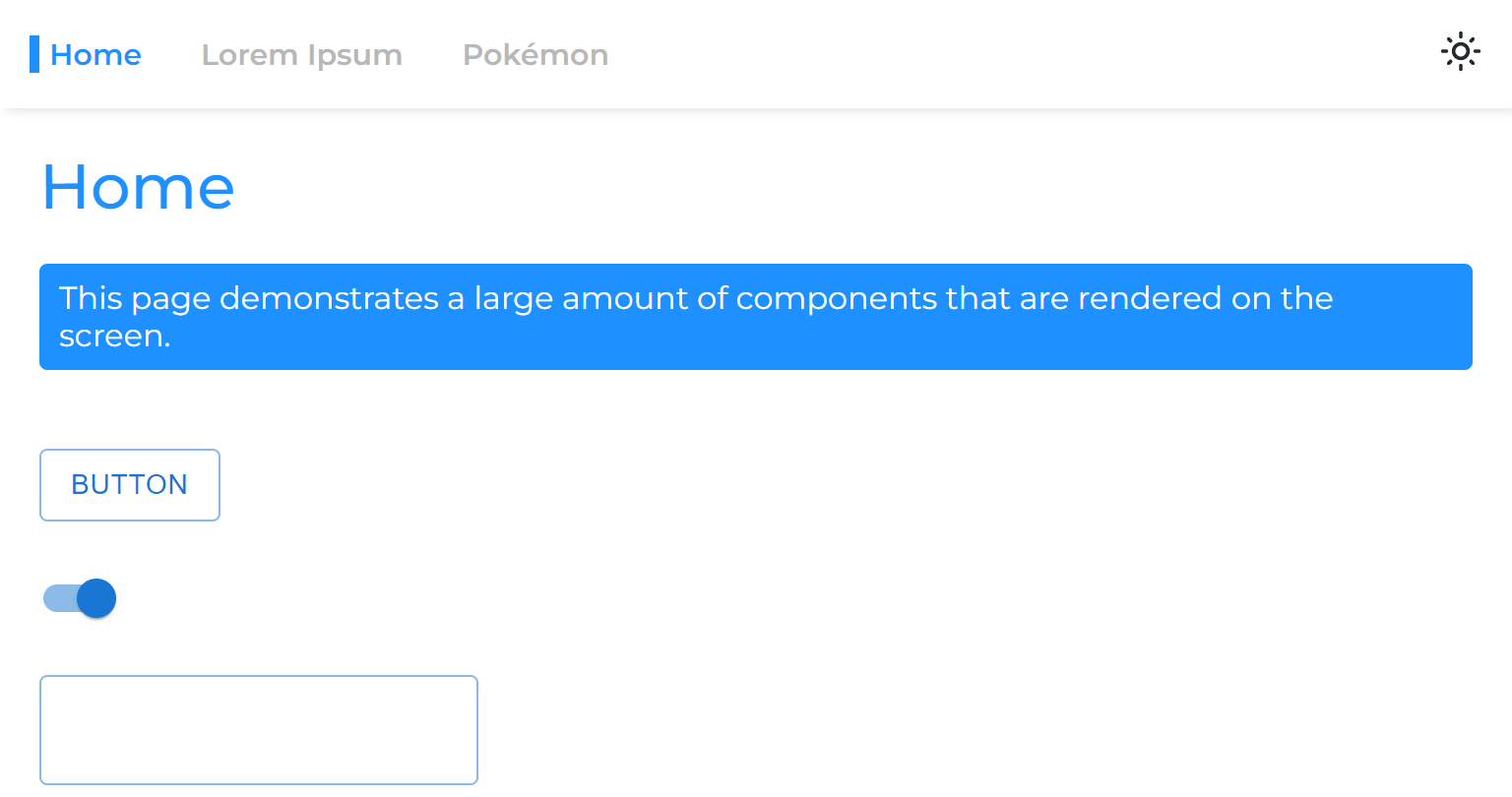
Isso acontece devido à abordagem comum de envolver apenas as rotas com suspense:
const App = ( ) => {
return (
< >
< Navigation />
< Suspense >
< Routes > { routes } </ Routes >
</ Suspense >
</ >
)
} O React 18 nos apresentou o gancho useTransition , que nos permite atrasar uma renderização até que alguns critérios sejam atendidos.
Usaremos este gancho para adiar a navegação da página até que esteja pronta:
usetransitionNavigate.ts
import { useTransition } from 'react'
import { useNavigate } from 'react-router-dom'
const useTransitionNavigate = ( ) => {
const [ , startTransition ] = useTransition ( )
const navigate = useNavigate ( )
return ( to , options ) => startTransition ( ( ) => navigate ( to , options ) )
}
export default useTransitionNavigateNavigationLink.tsx
const NavigationLink = ( { to , onClick , children } ) => {
const navigate = useTransitionNavigate ( )
const onLinkClick = event => {
event . preventDefault ( )
navigate ( to )
onClick ?. ( )
}
return (
< NavLink to = { to } onClick = { onLinkClick } >
{ children }
</ NavLink >
)
}
export default NavigationLinkAgora, as páginas assíncronas parecerão que nunca foram divididas no aplicativo principal.
Podemos pré -carregar outras páginas de dados ao passar o mouseiro sobre os links (desktop) ou quando os links entram no viewport (celular):
NavigationLink.tsx
< NavLink onMouseEnter = { ( ) => fetch ( url , { ... request , preload : true } ) } > { children } </ NavLink >Observe que isso pode carregar desnecessariamente o servidor API.
Alguns usuários deixam o aplicativo aberto por longos períodos de tempo, então outra coisa que podemos fazer é revalidar (baixar novos ativos) o aplicativo enquanto estiver em execução:
Serviço-trabalhador-registro.ts
+ const REVALIDATION_INTERVAL_HOURS = 1
const register = () => {
window.addEventListener(
'load',
async () => {
try {
const registration = await navigator.serviceWorker.register('/service-worker.js')
console.log('Service worker registered!')
registration.addEventListener('updatefound', () => {
registration.installing?.postMessage({ inlineAssets: extractInlineScripts() })
})
+ setInterval(() => registration.update(), REVALIDATION_INTERVAL_HOURS * 3600 * 1000)
} catch (err) {
console.error(err)
}
},
{ once: true }
)
}O código acima revalida o aplicativo a cada hora.
O processo de revalidação é extremamente barato, pois envolve apenas o reembolso do funcionário do serviço (que retornará um código de status 304 não modificado se não for alterado).
Quando o trabalhador do serviço muda , isso significa que novos ativos estão disponíveis e, portanto, serão baixados e cache seletivamente.
Dividimos nosso pacote em muitos pequenos pedaços, melhorando bastante as habilidades de cache do nosso aplicativo.
Dividimos todas as páginas para que, ao carregar uma, apenas o que é relevante esteja sendo baixado imediatamente.
Conseguimos tornar extremamente rápido a carga inicial (sem cache) do nosso aplicativo, tudo o que uma página exige para carregar é injetada dinamicamente.
Até pré -carregamos os dados da página, eliminando a famosa cachoeira que busca os aplicativos de CSR.
Além disso, precedemos todas as páginas, o que faz parecer que elas nunca foram divididas no código principal do pacote.
Tudo isso foi alcançado sem comprometer a experiência do desenvolvedor e sem ditar qual estrutura JS escolher.
A maior vantagem de um aplicativo estático é que ele pode ser servido inteiramente a partir de uma CDN.
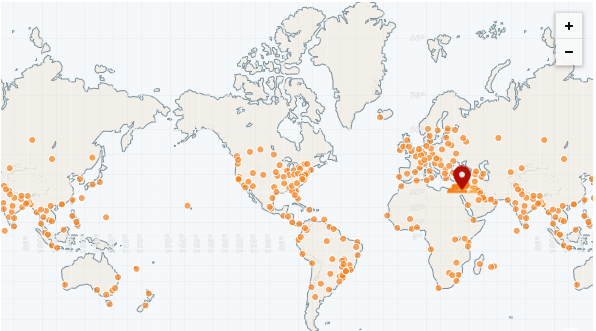
Um CDN possui muitos pops (pontos de presença), também chamados de "redes de borda". Esses pops são distribuídos em todo o mundo e, portanto, são capazes de servir arquivos a todas as regiões muito mais rápido que um servidor remoto.
O CDN mais rápido até o momento é o CloudFlare, que tem mais de 250 pops (e contando):
https://speed.cloudflare.com
https://blog.cloudflare.com/benchmarking-edge-network-performance
Podemos implantar facilmente nosso aplicativo usando o CloudFlare Pages:
https://pages.cloudflare.com
Para concluir esta seção, realizaremos uma referência do nosso aplicativo em comparação com o site de documentação do Next.JS , que é inteiramente SSG .
Compararemos a página de acessibilidade minimalista com a nossa página Lorem ipsum . Ambas as páginas incluem ~ 246kb de JS em seus pedaços críticos de renderização (pré-cargas e pré-acessos que vêm depois são irrelevantes).
Você pode clicar em cada link para executar uma referência ao vivo.
Acessibilidade | Next.js
Lorem ipsum | Renderização do lado do cliente
Eu executei o benchmark do Google PageSpeed Insights (simulando uma rede 4G lenta) cerca de 20 vezes para cada página e escolhi a pontuação mais alta.
Estes são os resultados:
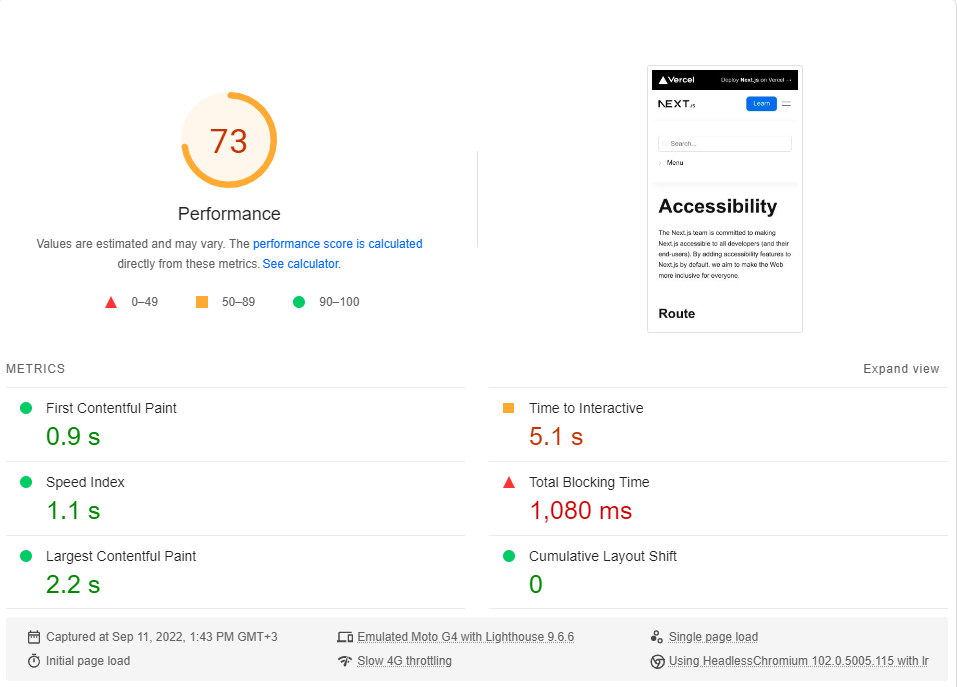
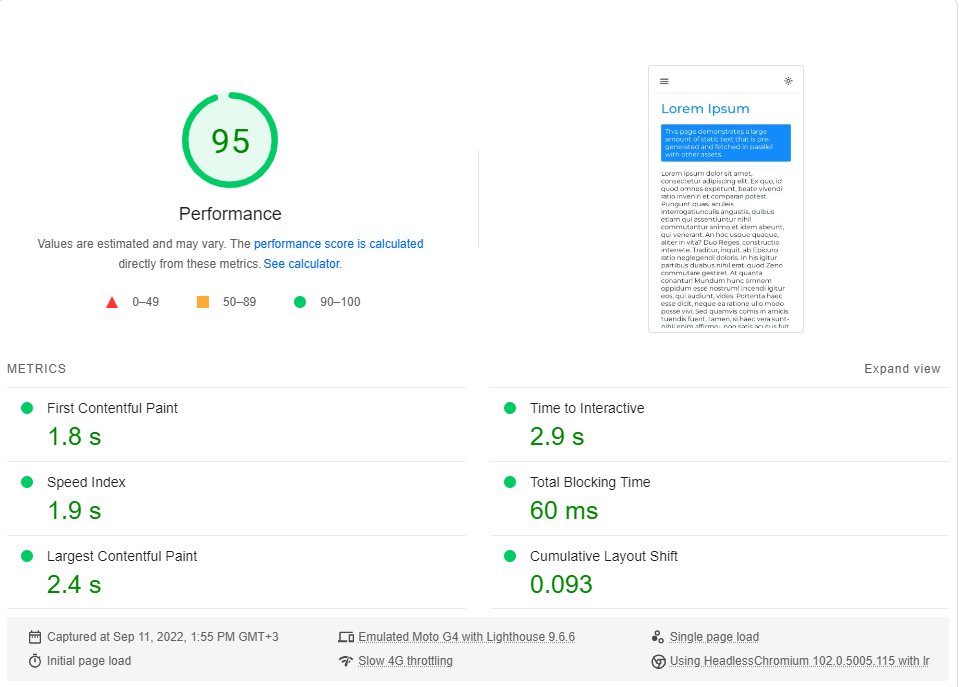
Como se vê, o desempenho não é um padrão no próximo.js.
Observe que esse benchmark apenas testa a primeira carga da página, sem considerar o desempenho do aplicativo quando está totalmente em cache (onde a RSE realmente brilha).
É um minConcept comum que o Google esteja tendo problemas de indexação adequada de aplicativos de CSR (JS).
Esse pode ter sido o caso em 2017, mas a partir de hoje: o Google indexa os aplicativos de CSR principalmente na perfeição.
As páginas indexadas terão um título, descrição, conteúdo e todos os outros atributos relacionados a SEO, desde que se lembremos de defini-los dinamicamente (manualmente assim ou usar um pacote como o React-Helmet ).
https://www.google.com/search?q=site:https://client-side-rendering.pages.dev
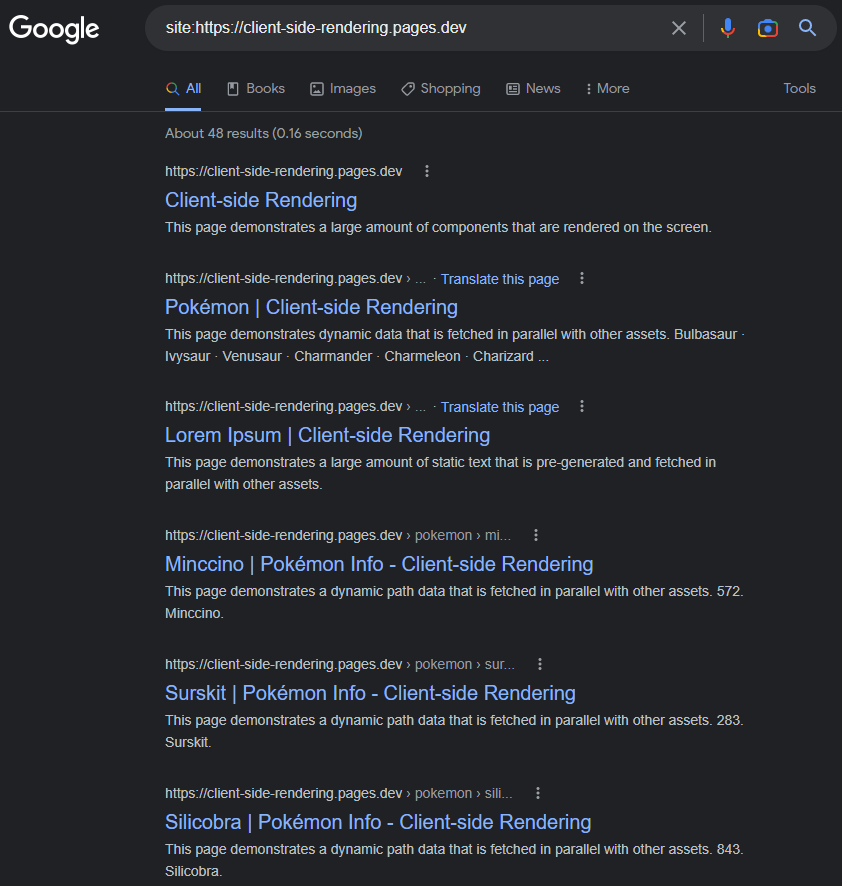
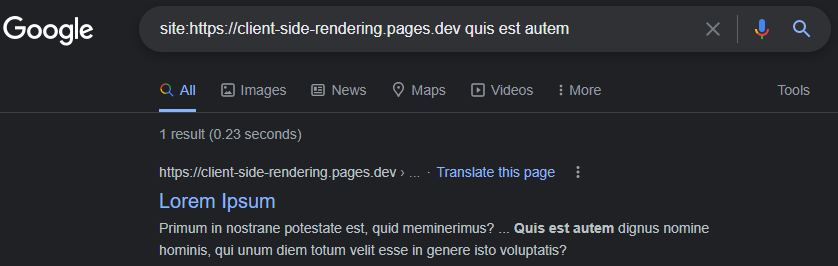
A capacidade do Googlebot que o renderizo JS pode ser facilmente demonstrado executando um teste de URL ao vivo do nosso aplicativo no console de pesquisa do Google :
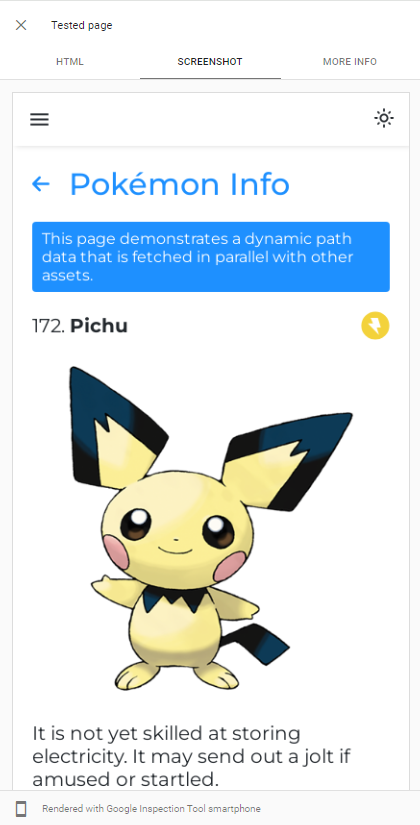
O GoogleBot usa a versão mais recente do Chromium para rastejar aplicativos, portanto, a única coisa que devemos fazer é garantir que nosso aplicativo seja carregado rapidamente e que é rápido em buscar dados.
Mesmo quando os dados demoram muito para buscar, o Googlebot, na maioria dos casos, aguarda antes de tirar um instantâneo da página:
https://support.google.com/webmasters/thread/202552760/for-how-long-does-googlebot-wait-for-last-http-request
https://support.google.com/webmasters/thread/165370285?hl=en&msgid=165510733
Uma explicação detalhada do processo de rastreamento JS do Googlebot pode ser encontrada aqui:
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
Se o Googlebot não renderizar algumas páginas, deve -se principalmente à falta de vontade do Google em gastar os recursos necessários para rastejar o site, o que significa que ele tem um orçamento de rastreamento baixo.
Isso pode ser confirmado inspecionando a página rastejada (clicando em Exibir página rastejada no console de pesquisa) e certificando -se de que todas as solicitações falhadas tenham o outro alerta de erro (o que significa que essas solicitações foram intencionalmente abortadas pelo Googlebot):
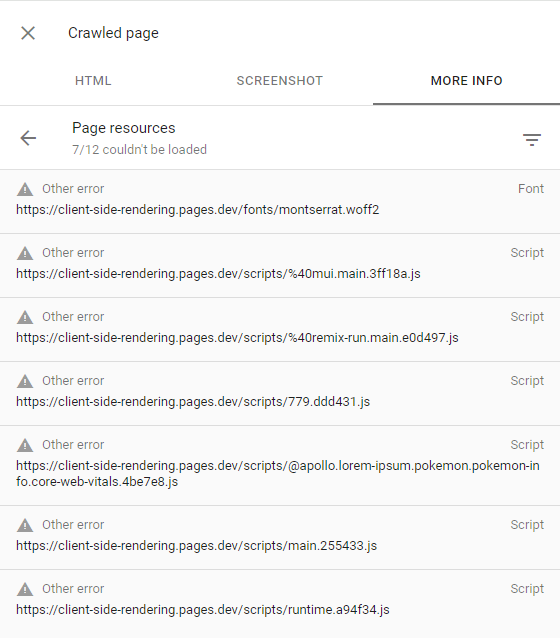
Isso só deve acontecer com sites que o Google considera não ter conteúdo interessante ou ter tráfego muito baixo (como nosso aplicativo de demonstração).
Mais informações podem ser encontradas aqui: https://support.google.com/webmasters/thread/4425254?hl=en&msgid=4426601
Outros mecanismos de pesquisa, como o Bing, não podem renderizar JS; portanto, para que eles rastejam nosso aplicativo corretamente, precisamos servir a versão pré -renderizada de nossas páginas.
A pré -alerta é o ato de rastejar aplicativos da Web em produção (usando cromo sem cabeça) e gerar um arquivo HTML completo (com dados) para cada página.
Temos duas opções quando se trata de pré -render:
A pré -reerência sem servidor é a abordagem recomendada, pois pode ser muito barata, especialmente no GCP .
Em seguida, redirecionamos os rastreadores da web (identificados por sua string de cabeçalho de User-Agent ) para o nosso pré-renderizador, usando um trabalhador do Cloudflare (por exemplo):
public/_worker.js
const BOT_AGENTS = [ 'bingbot' , 'yandex' , 'twitterbot' , 'whatsapp' , ... ]
const fetchPrerendered = async ( { url , headers } , userAgent ) => {
const headersToSend = new Headers ( headers )
/* Custom Prerenderer */
const prerenderUrl = new URL ( ` ${ YOUR_PRERENDERER_URL } ?url= ${ url } ` )
/*************/
/* OR */
/* Prerender.io */
const prerenderUrl = `https://service.prerender.io/ ${ url } `
headersToSend . set ( 'X-Prerender-Token' , YOUR_PRERENDER_IO_TOKEN )
/****************/
const prerenderRequest = new Request ( prerenderUrl , {
headers : headersToSend ,
redirect : 'manual'
} )
const { body , ... rest } = await fetch ( prerenderRequest )
return new Response ( body , rest )
}
export default {
fetch ( request , env ) {
const pathname = new URL ( request . url ) . pathname . toLowerCase ( )
const userAgent = ( request . headers . get ( 'User-Agent' ) || '' ) . toLowerCase ( )
// a crawler that requests the document
if ( BOT_AGENTS . some ( agent => userAgent . includes ( agent ) ) && ! pathname . includes ( '.' ) ) {
return fetchPrerendered ( request , userAgent )
}
return env . ASSETS . fetch ( request )
}
} Aqui está uma lista atualizada de todos os agnets de bot (rastreadores da web): https://docs.perrender.io/docs/how-to-add-additional-bots#cloudflare. Lembre -se de excluir googlebot da lista.
A pré -renda , também chamada de renderização dinâmica , é incentivada pela Microsoft e é fortemente usada por muitos sites populares, incluindo o Twitter.
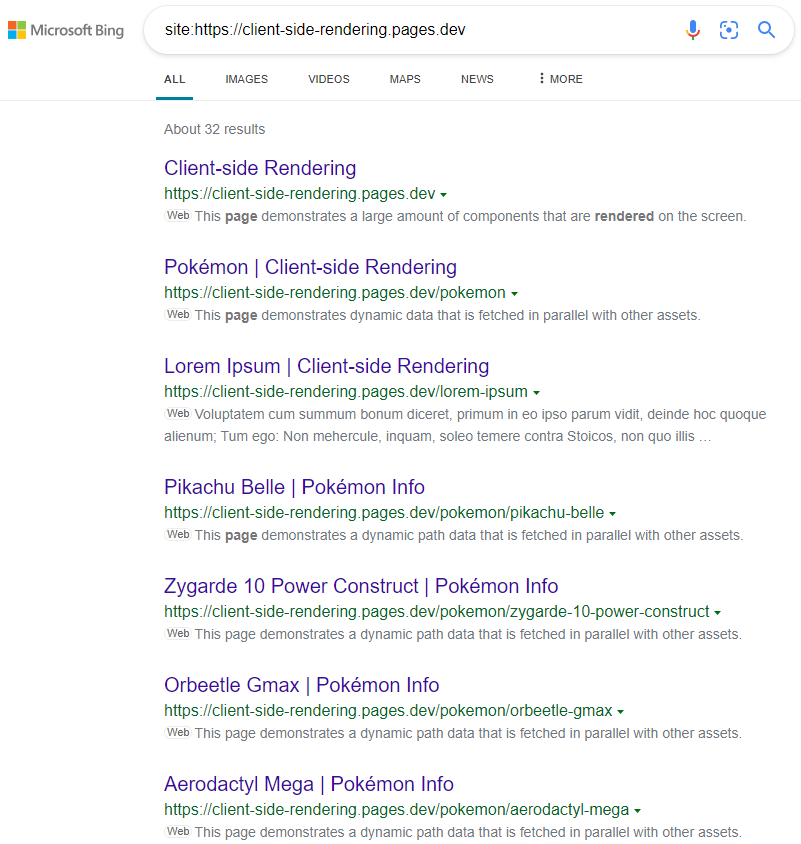
Os resultados são os esperados:
https://www.bing.com/search?q=site%3ahttps%3a%2f%2fclient-side-rendering.pages.dev
Observe que, ao usar o CSS-in-JS, podemos desativar a otimização rápida durante a pré-renda, se queremos ter nossos estilos omitidos no DOM.
Quando compartilhamos um link de aplicativo CSR nas mídias sociais, podemos ver que, independentemente da página que vincularmos, a visualização permanecerá a mesma.
Isso acontece porque a maioria dos aplicativos de CSR possui apenas um arquivo HTML sem conteúdo e os rastreadores de mídia social não renderizam JS.
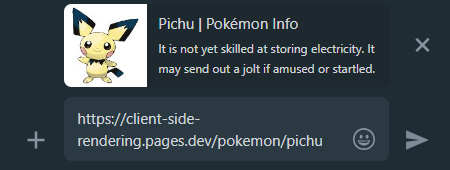
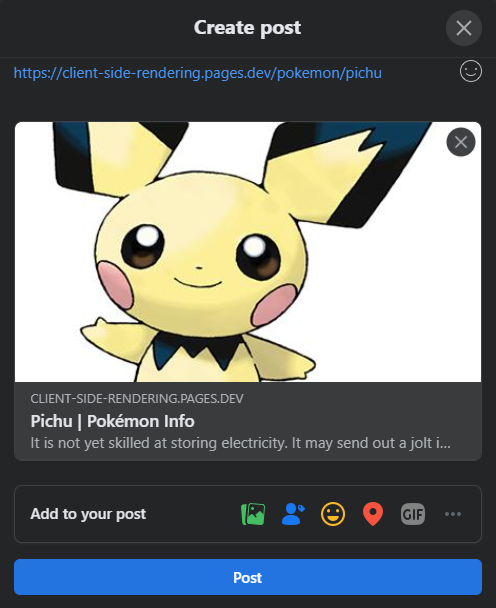
É aqui que a pré -consciência chega em nosso auxílio mais uma vez, ele gerará a visualização de compartilhamento adequada para cada página:
Whatsapp:
Facebook :
Para tornar todas as nossas páginas de aplicativos descobertas para os mecanismos de pesquisa, é recomendável criar um arquivo sitemap.xml que especifique todas as rotas do nosso site.
Como já temos um arquivo de páginas.js centralizado, podemos facilmente gerar um sitemap durante o tempo de construção:
create-sitemap.js
import { Readable } from 'stream'
import { writeFile } from 'fs/promises'
import { SitemapStream , streamToPromise } from 'sitemap'
import pages from '../src/pages.js'
const stream = new SitemapStream ( { hostname : 'https://client-side-rendering.pages.dev' } )
const links = pages . map ( ( { path } ) => ( { url : path , changefreq : 'weekly' } ) )
streamToPromise ( Readable . from ( links ) . pipe ( stream ) )
. then ( data => data . toString ( ) )
. then ( res => writeFile ( 'public/sitemap.xml' , res ) )
. catch ( console . log )Isso irá emitir o seguinte sitemap:
<? xml version = " 1.0 " encoding = " UTF-8 " ?>
< urlset xmlns = " http://www.sitemaps.org/schemas/sitemap/0.9 " xmlns : image = " http://www.google.com/schemas/sitemap-image/1.1 " xmlns : news = " http://www.google.com/schemas/sitemap-news/0.9 " xmlns : video = " http://www.google.com/schemas/sitemap-video/1.1 " xmlns : xhtml = " http://www.w3.org/1999/xhtml " >
< url >
< loc >https://client-side-rendering.pages.dev/</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/lorem-ipsum</ loc >
< changefreq >weekly</ changefreq >
</ url >
< url >
< loc >https://client-side-rendering.pages.dev/pokemon</ loc >
< changefreq >weekly</ changefreq >
</ url >
</ urlset >Podemos enviar manualmente nosso sitemap para o Google Search Console e o Bing Webmaster Tools .
Como mencionado acima, uma comparação detalhada de todos os métodos de renderização pode ser encontrada aqui: https://client-side-rendering.pages.dev/comparison
Vimos as vantagens dos arquivos estáticos: eles são em cache e podem ser servidos a partir de uma CDN próxima sem exigir um servidor.
Isso pode nos levar a acreditar que o SSG combina os benefícios da RSE e da SSR: torna nosso aplicativo carregar visualmente muito rápido ( FCP ) e independentemente dos tempos de resposta do nosso servidor de API.
No entanto, na realidade, o SSG tem uma grande limitação:
Como o JS não está ativo durante os momentos iniciais, tudo o que depende do JS a ser apresentado simplesmente não será visível ou será exibido incorretamente (como componentes que dependem da função window.matchMedia para renderizar).
Um exemplo clássico dessa edição pode ser visto no seguinte site:
https://death-to-ie11.com
Observe como o cronômetro não está visível imediatamente? Isso ocorre porque é gerado pelo JS, que leva tempo para baixar e executar.
Também vemos um problema semelhante ao refrescar a página de 'guias' da Vercel com alguns filtros aplicados:
https://vercel.com/guides?topics=Analytics
Isso acontece porque existem 65536 (2^16) possíveis combinações de filtro e armazenar cada combinação como um arquivo HTML separado exigiria muito armazenamento do servidor.
Portanto, eles geram um único arquivo guides.html que contém todos os dados, mas esse arquivo estático não sabe quais filtros são aplicados até que o JS seja carregado, causando uma mudança de layout.
É importante observar que, mesmo com a regeneração estática incremental , os usuários ainda terão que aguardar uma resposta ao servidor ao visitar páginas que ainda não foram armazenadas em cache (assim como no SSR).
Outro exemplo desse problema são as animações JS - elas podem parecer estáticas inicialmente e apenas começam a animar quando o JS é carregado.
Há muitos casos em que essa funcionalidade atrasada prejudica a experiência do usuário, como quando os sites mostram apenas a barra de navegação após o carregamento do JS (pois eles dependem do armazenamento local para verificar se existe uma entrada de informações do usuário).
Outra questão crítica, especialmente para sites de comércio eletrônico, é que as páginas do SSG podem exibir dados desatualizados (como o preço ou disponibilidade de um produto).
É exatamente por isso que nenhum site de comércio eletrônico importante usa o SSG.
É um fato que, sob a conexão rápida da Internet, a RSE e a SSR têm um ótimo desempenho (desde que sejam otimizadas) e maior a velocidade de conexão - mais próximas elas chegaram em termos de tempo de carregamento.
No entanto, ao lidar com conexões lentas (como redes móveis), parece que o SSR tem uma vantagem sobre a RSE em relação aos tempos de carregamento.
Como os aplicativos SSR são renderizados no servidor, o navegador recebe o arquivo HTML totalmente construído e, portanto, pode mostrar a página ao usuário sem esperar o download do JS. Quando o JS é baixado e analisado, a estrutura é capaz de "hidratar" o DOM com funcionalidade (sem precisar reconstruí -la).
Embora pareça uma grande vantagem, esse comportamento apresenta um efeito colateral indesejado, especialmente em conexões mais lentas:
Até que o JS seja carregado, os usuários podem clicar onde desejar, mas o aplicativo não reagirá a nenhum de seus eventos baseados em JS.
É uma experiência ruim quando os botões não respondem às interações do usuário, mas se torna um problema muito maior quando os eventos padrão não estão sendo impedidos.
Esta é uma comparação entre o site do Next.JS e nosso aplicativo de renderização do lado do cliente em uma conexão 3G rápida:
O que aconteceu aqui?
Como o JS ainda não foi carregado, o site do Next.JS não pôde impedir o comportamento padrão dos elementos da tag âncora ( <a> ) para navegar para outra página, resultando em cada clique em que eles acionem uma página inteira recarregada.
E quanto mais lenta for a conexão - mais grave esse problema se tornar.
Em outras palavras, onde a SSR deveria ter tido uma vantagem de desempenho sobre a RSE, vemos um comportamento muito "perigoso" que pode degradar significativamente a experiência do usuário.
É impossível que esse problema ocorra nos aplicativos de RSE, pois o momento em que eles renderizam - o JS já foi totalmente carregado.
Vimos que o desempenho da renderização do lado do cliente está em pé de igualdade e às vezes ainda melhor que o SSR em termos de tempos iniciais de carregamento (e o supera em muito tempo nos tempos de navegação).
Também vimos que o Googlebot pode indexar perfeitamente os aplicativos renderizados do lado do cliente e que podemos facilmente configurar um servidor Prender para servir todos os outros bots e rastreadores.
E o mais importante é que alcançamos tudo isso apenas adicionando alguns arquivos e usando um serviço de pré -renda, para que todo aplicativo de CSR existente deve ser capaz de implementar rápida e facilmente essas alterações e se beneficiar deles.
Esses fatos levam à conclusão de que não há razão convincente para usar o SSR. Doing so would only add unnecessary complexity and limitations to our app, degrading both the developer and user experience, while also incurring higher server costs.
As time passes, connection speeds are getting faster and end-user devices are becoming more powerful. As a result, the performance differences between various website rendering methods are guaranteed to diminish further (except for SSR, which still depends on API server response times).
A new SSR method called Streaming SSR (in React, this is through "Server Components") and newer frameworks like Qwik are capable of streaming responses to the browser without waiting for the API server's response. However, there are also newer and more efficient CSR frameworks like Svelte and Solid.js, which have much smaller bundle sizes and are significantly faster than React (greatly improving FCP on slow networks).
Nevertheless, it's important to note that nothing will ever outperform the instant page transitions that client-side rendering provides, nor the simple and flexible development flow it offers.


