MAX Image Caption Generator Web App
Patch Release
根据IBM的研究,每天都会创建2.5亿亿千亿个字节。许多数据是非结构化的数据,例如大型文本,录音和图像。为了对数据有用,我们必须首先将其转换为结构化数据。
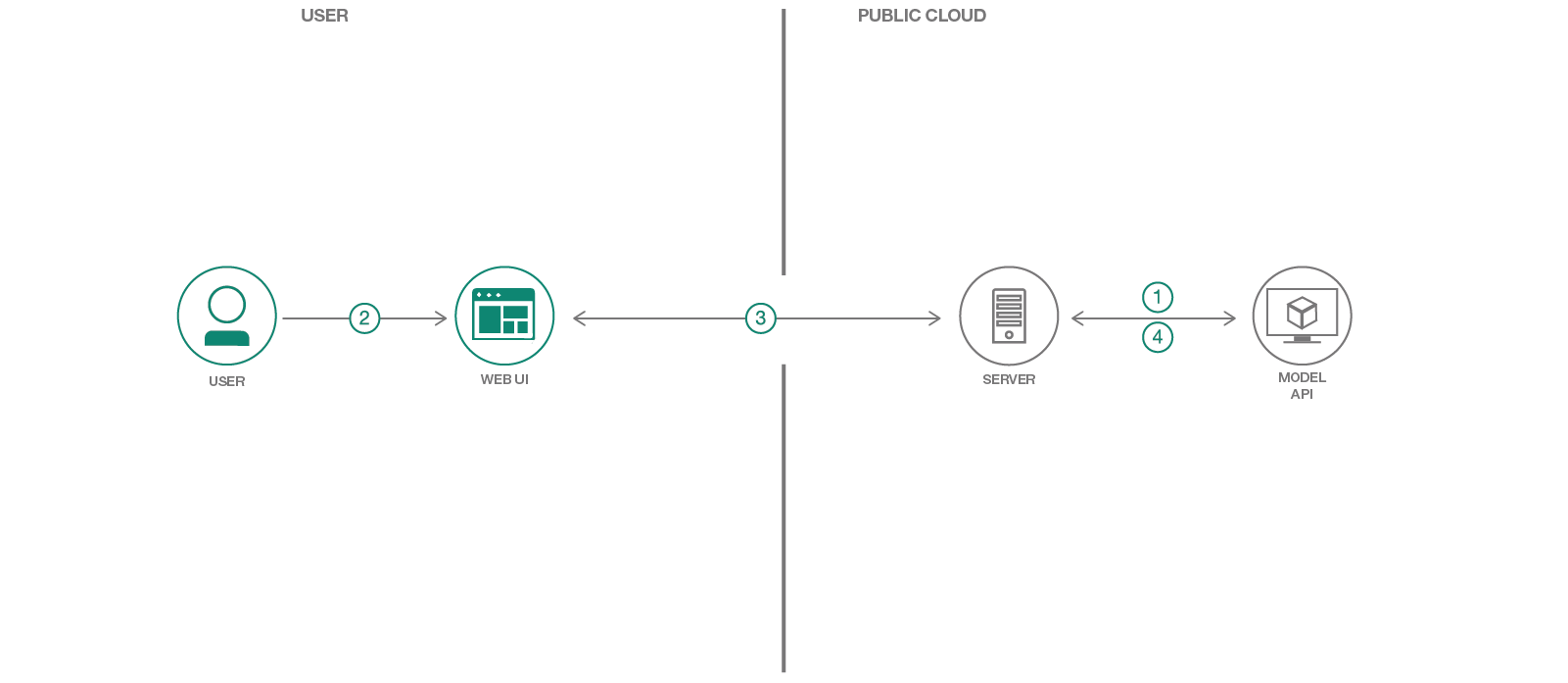
在此代码模式中,我们将使用模型资产交换(MAX)中的一种模型,该模型可以在开发人员可以找到并尝试开源深度学习模型的交换。具体来说,我们将使用图像字幕生成器创建一个Web应用程序,该应用程序将标题为图像并允许用户通过基于图像的图像内容过滤。 Web应用程序提供了使用Tornado轻巧的Python服务器支持的交互式用户界面。该服务器通过UI拍摄图像,并将它们发送到模型的休息点,并在UI上显示生成的字幕。使用Max上提供的Docker映像设置模型的休息端点。 Web UI显示每个图像的生成字幕以及一个交互式字云,以根据其标题过滤图像。
读者完成此代码模式后,他们将了解如何:
以下是Spark+AI Summit 2018上关于Max的演讲,其中包括Web应用程序的简短演示。
运行代码模式的方法:
按照部署模型文档将图像字幕生成器模型部署到IBM云。如果您已经有一个模型API端点,则可以跳过此过程。
注意:部署模型可能需要时间,为了更快地进行,您可以在本地尝试运行。
按Deploy to IBM Cloud按钮。如果您还没有IBM云帐户,则需要创建一个。
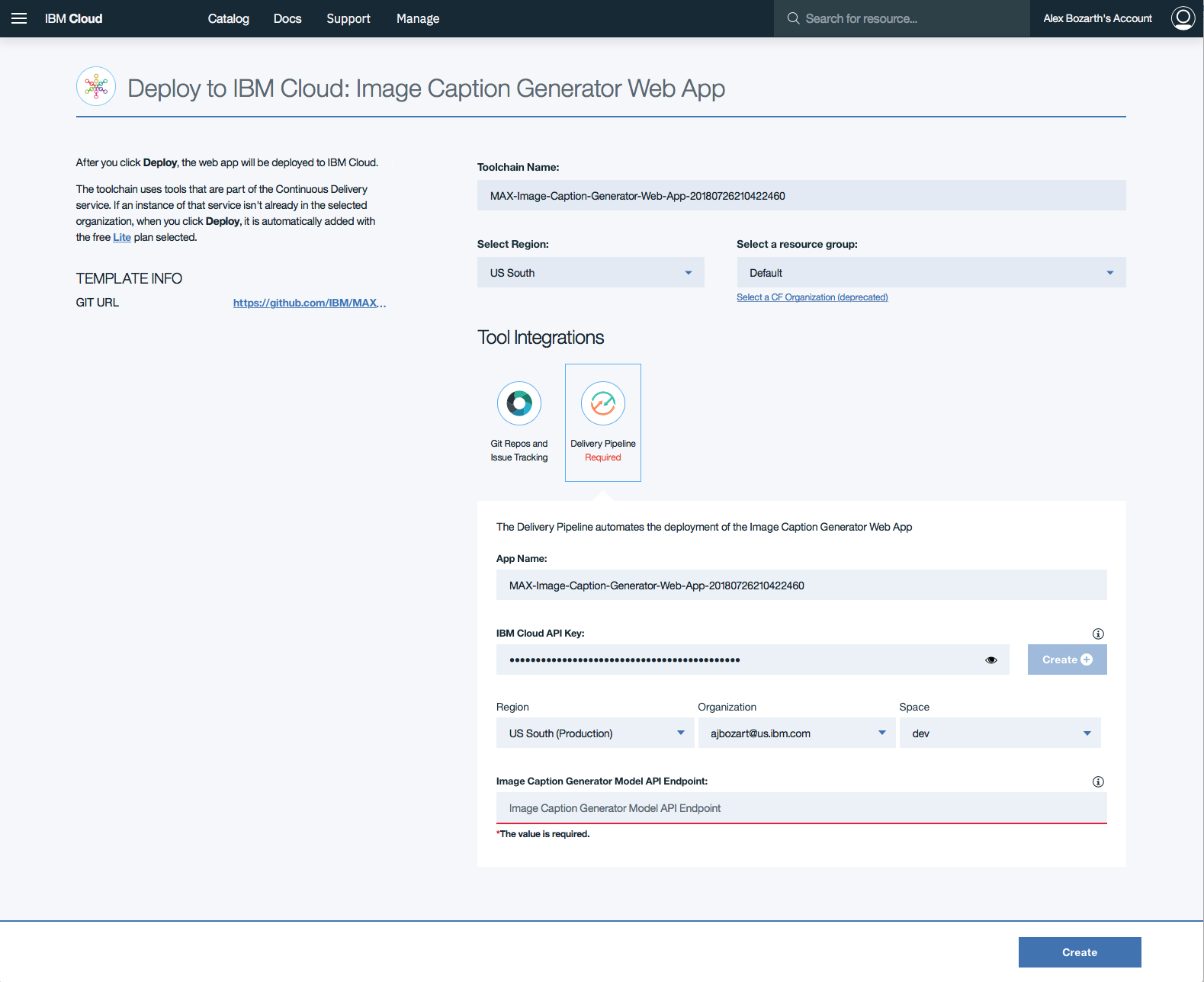
单击Delivery Pipeline ,然后单击表单中的Create +按钮,以生成Web应用程序的IBM Cloud API Key 。
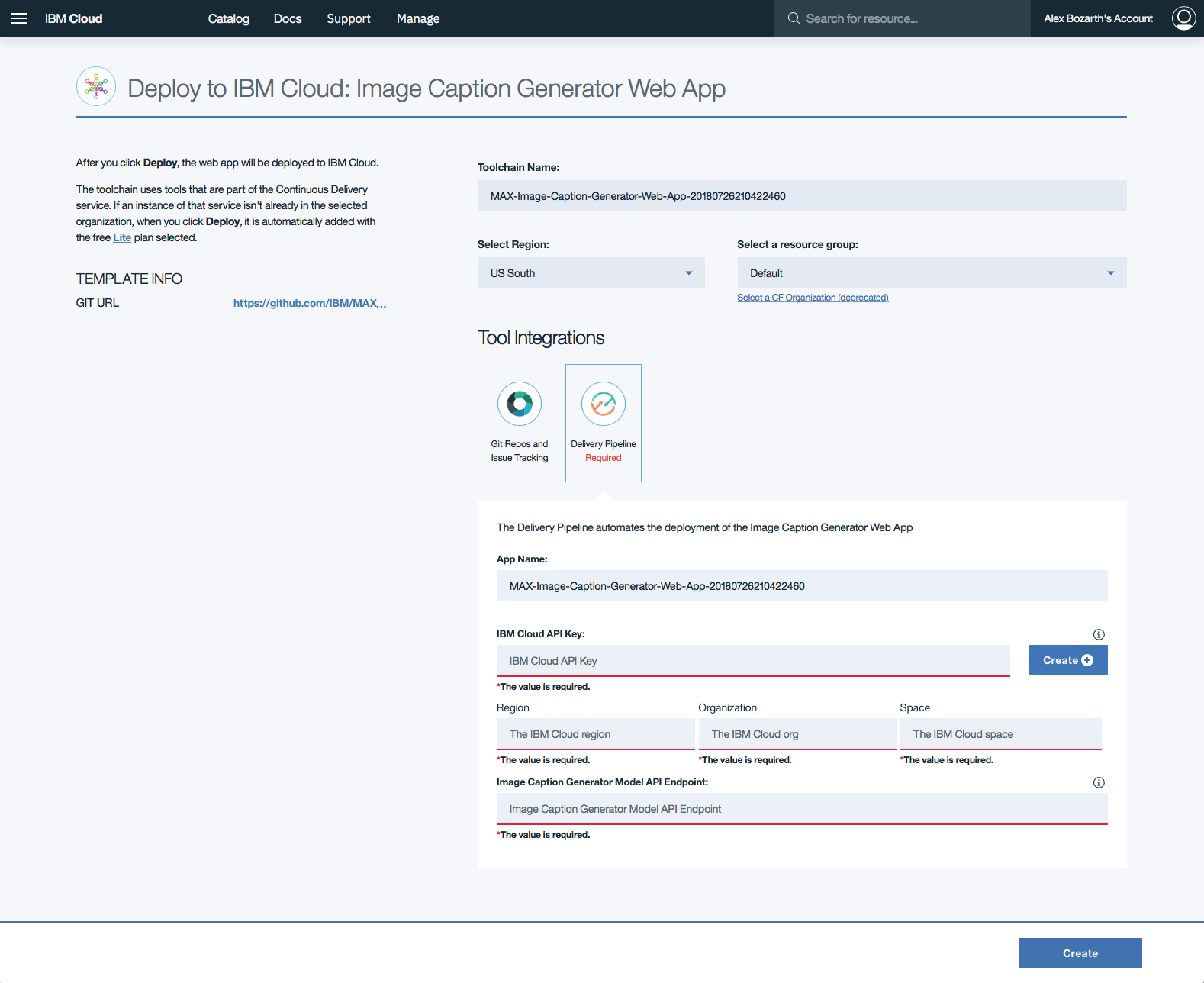
生成API密钥后,将填充Region , Organization和Space形式部分。填写Image Caption Generator Model API Endpoint部分,并使用上面部署的端点,然后单击Create 。
此条目的格式应为
http://170.0.0.1:5000
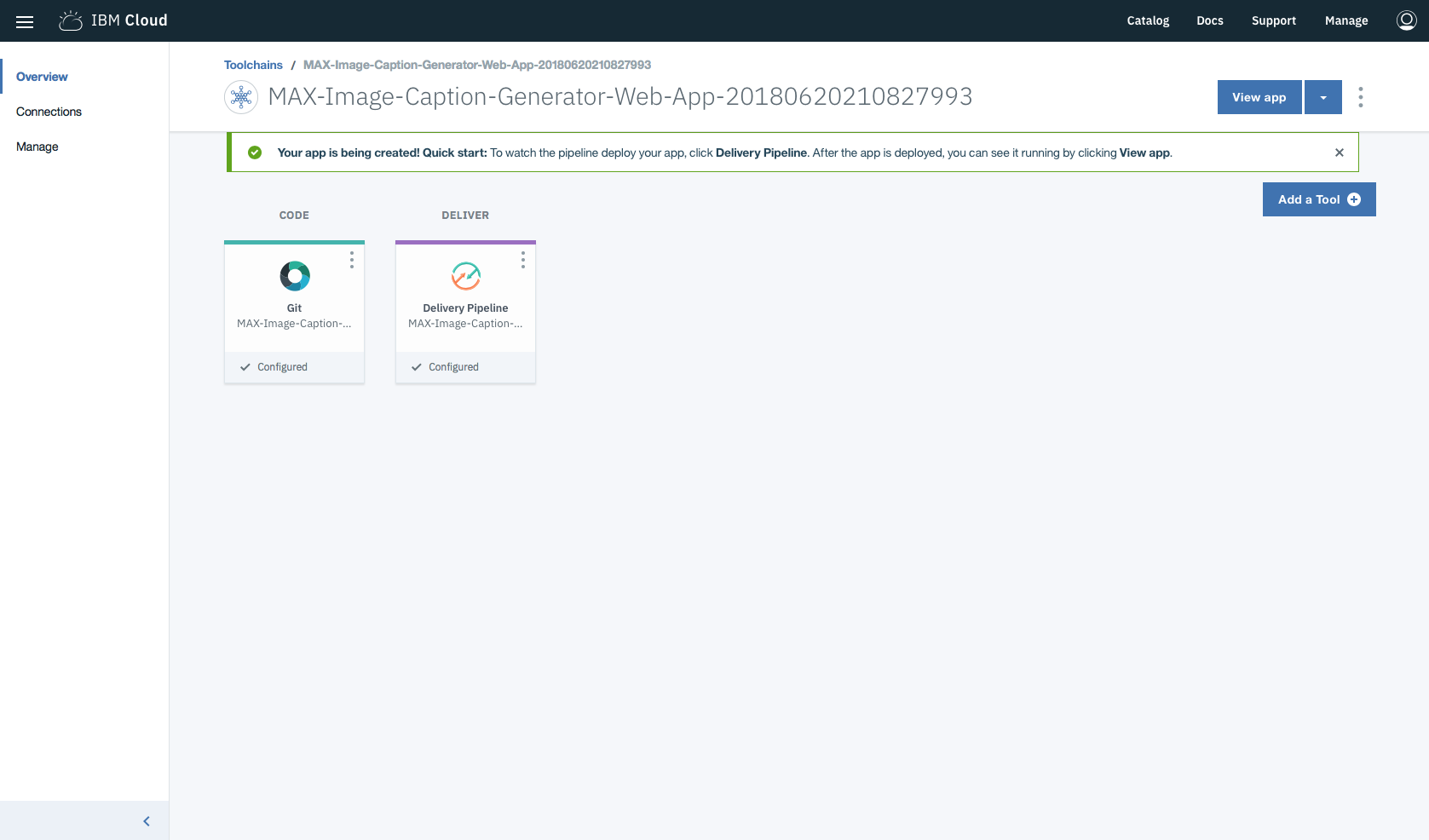
在工具链中,在部署应用程序时,单击Delivery Pipeline以观看。部署后,可以通过单击View app查看该应用程序。
您还可以使用码头上的最新码头图像在Kubernetes上部署模型和Web应用程序。
在您的kubernetes群集上,运行以下命令:
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator/master/max-image-caption-generator.yaml
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator-Web-App/master/max-image-caption-generator-web-app.yaml Web应用程序将在您的集群的端口8088上找到。该模型只能在内部提供,但可以通过NodePort在外部访问。
注意:对于在IBM云上部署Web应用程序,建议按照上述IBM云指令进行部署,而不是使用IBM Cloud Kubernetes服务部署。
注意:仅当在本地运行而不是将
Deploy to IBM Cloud按钮时,才需要这些步骤。
注意:本节中的一组指令是图像字幕生成器项目页面上找到的一个修改版本
要运行自动启动Serving API模型的Docker Image,请运行:
docker run -it -p 5000:5000 quay.io/codait/max-image-caption-generator
这将从Quay中汲取预先构建的图像(或使用现有的图像,如果已经在本地缓存)并运行它。如果您想在本地构建模型,则可以按照模型读数中的步骤进行操作。
请注意,当前此Docker映像仅是CPU(我们将稍后添加对GPU图像的支持)。
API服务器会自动生成一个交互式摇摇欲坠的文档页面。转到http://localhost:5000加载它。您可以从那里探索API并创建测试请求。
使用model/predict端点加载测试文件并从API获取图像的标题。
模型示例文件夹包含一些您可以用来测试API的图像,也可以使用自己的图像。
您也可以在命令行上进行测试,例如:
curl -F " image=@path/to/image.jpg " -X POST http://localhost:5000/model/predict{
"status" : " ok " ,
"predictions" : [
{
"index" : " 0 " ,
"caption" : " a man riding a wave on top of a surfboard . " ,
"probability" : 0.038827644239537
},
{
"index" : " 1 " ,
"caption" : " a person riding a surf board on a wave " ,
"probability" : 0.017933410519265
},
{
"index" : " 2 " ,
"caption" : " a man riding a wave on a surfboard in the ocean . " ,
"probability" : 0.0056628732021868
}
]
}通过运行以下命令在本地克隆图像字幕生成器Web应用程序存储库:
git clone https://github.com/IBM/MAX-Image-Caption-Generator-Web-App
注意:您可能需要
cd ..首先超出最大图像捕获生成器目录
然后将目录更改为本地存储库
cd MAX-Image-Caption-Generator-Web-App
在运行此Web应用程序之前,您必须安装其依赖项:
pip install -r requirements.txt
然后,您可以通过运行启动Web应用程序:
python app.py
完成处理默认图像(<1分钟)后,您可以访问网络应用程序: http://localhost:8088
图像字幕生成器端点必须在http://localhost:5000中可用,以获取Web应用程序才能成功启动。
如果要使用其他端口或在其他位置运行ML端点,则可以使用命令行选项更改它们:
python app.py --port=[new port] --ml-endpoint=[endpoint url including protocol and port]
要使用Docker运行Web应用程序,运行Web服务器的容器,其余端点需要共享同一网络堆栈。这是通过以下步骤完成的:
修改运行图像字幕生成器休息端点的命令,以将容器中的附加端口映射到主机计算机上的端口。在下面的示例中,它映射到主机上的端口8088 ,但也可以使用其他端口。
docker run -it -p 5000:5000 -p 8088:8088 --name max-image-caption-generator quay.io/codait/max-image-caption-generator
通过运行构建Web应用程序映像:
docker build -t max-image-caption-generator-web-app .
使用以下方式运行Web应用程序容器:
docker run --net='container:max-image-caption-generator' -it max-image-caption-generator-web-app
您还可以通过运行:
docker run --net='container:max-image-caption-generator' -it quay.io/codait/max-image-caption-generator-web-app
这将使用在上方运行的模型Docker容器,并且可以在无需克隆Web应用程序存储库的情况下运行。
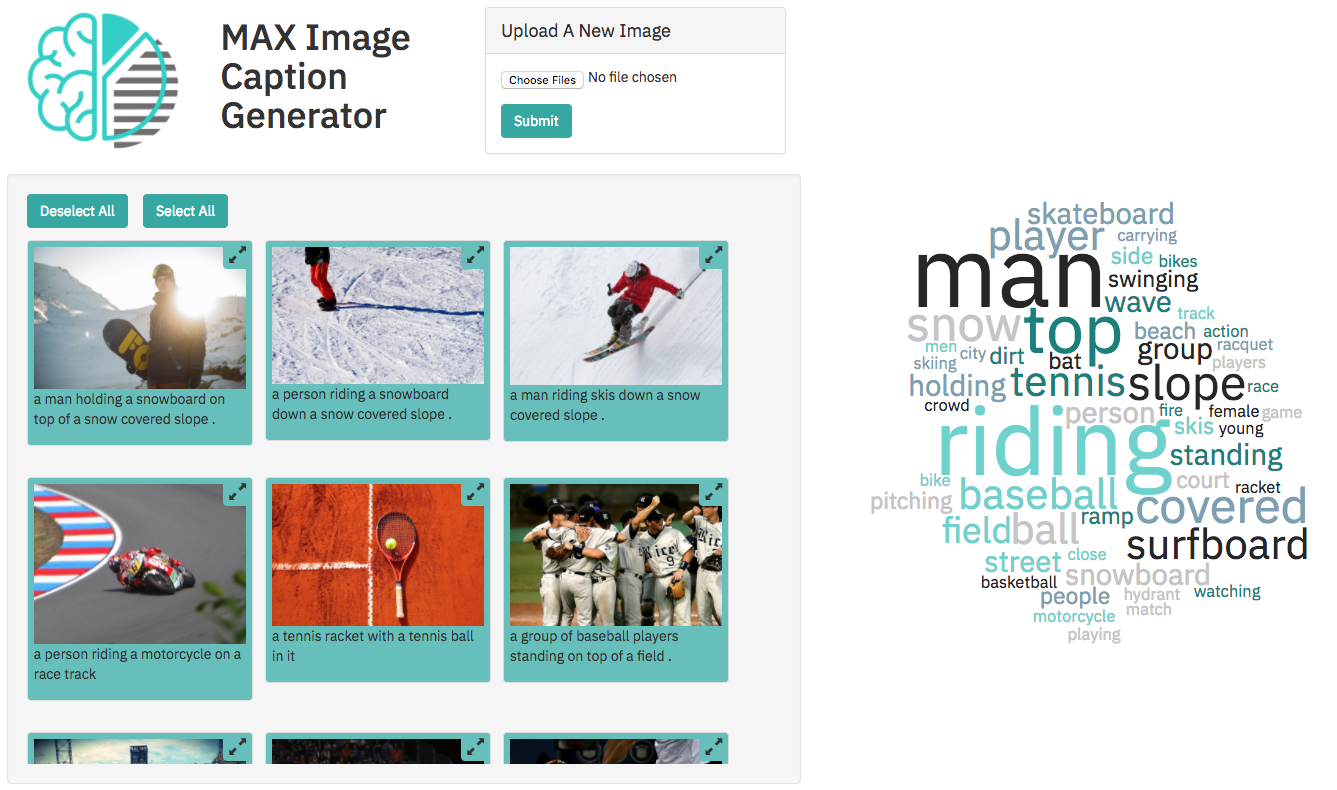
在长期运行的Web应用程序中,有大量用户上传的图像
在
http://localhost:8088运行Web应用程序时,请通过http://localhost:8088/cleanup提供一个管理页面,该页面允许用户从服务器删除所有用户上传文件。[注意:这将删除所有用户上传的图像]
此代码模式是根据Apache软件许可证(版本2版)许可的。此代码模式中调用的单独的第三方代码对象由其各自的提供商根据自己的单独许可而获得许可。贡献受开发人员的原始证书(DCO)和Apache软件许可证版本2的约束。
Apache软件许可证(ASL)常见问题


