MAX Image Caption Generator Web App
Patch Release
根據IBM的研究,每天都會創建2.5億億千億個字節。許多數據是非結構化的數據,例如大型文本,錄音和圖像。為了對數據有用,我們必須首先將其轉換為結構化數據。
在此代碼模式中,我們將使用模型資產交換(MAX)中的一種模型,該模型可以在開發人員可以找到並嘗試開源深度學習模型的交換。具體來說,我們將使用圖像字幕生成器創建一個Web應用程序,該應用程序將標題為圖像並允許用戶通過基於圖像的圖像內容過濾。 Web應用程序提供了使用Tornado輕巧的Python服務器支持的交互式用戶界面。該服務器通過UI拍攝圖像,並將它們發送到模型的休息點,並在UI上顯示生成的字幕。使用Max上提供的Docker映像設置模型的休息端點。 Web UI顯示每個圖像的生成字幕以及一個交互式字云,以根據其標題過濾圖像。
讀者完成此代碼模式後,他們將了解如何:
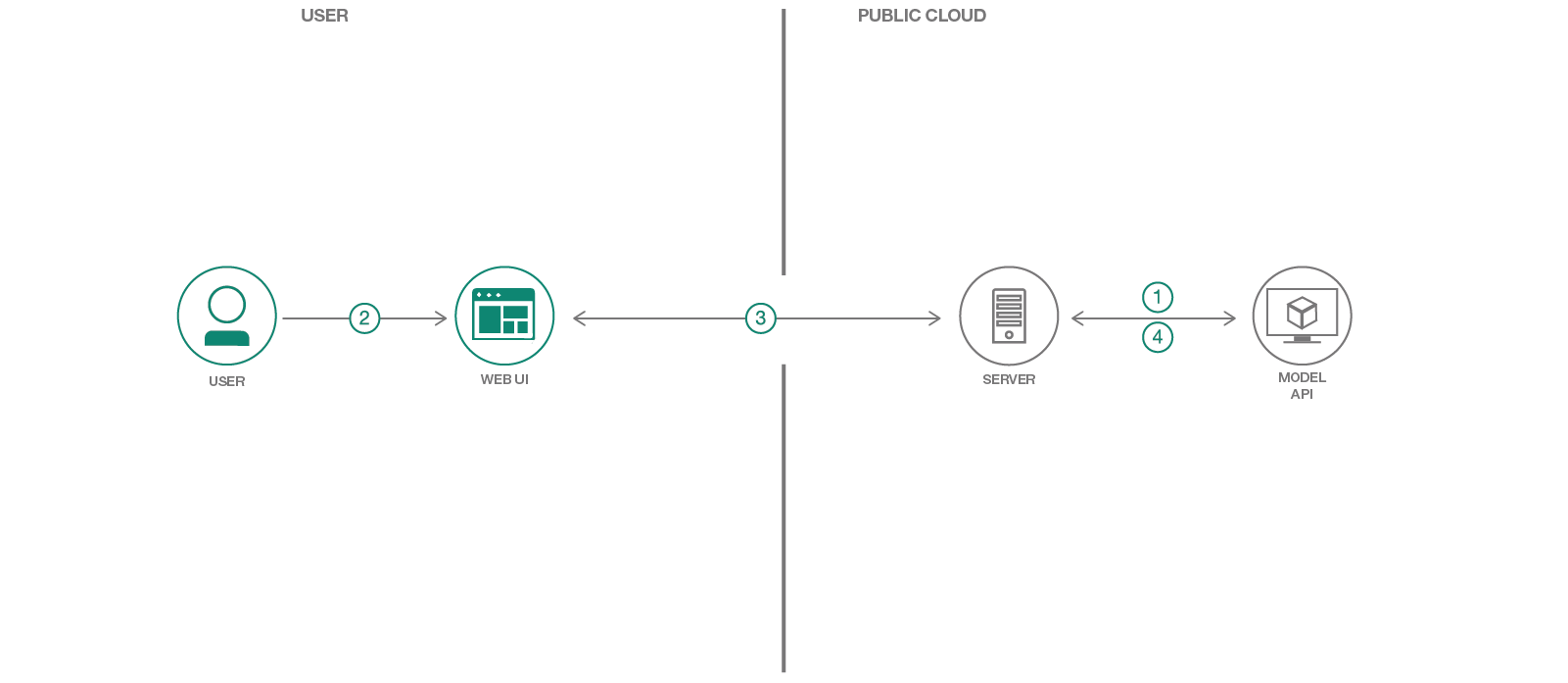
以下是Spark+AI Summit 2018上關於Max的演講,其中包括Web應用程序的簡短演示。
運行代碼模式的方法:
按照部署模型文檔將圖像字幕生成器模型部署到IBM雲。如果您已經有一個模型API端點,則可以跳過此過程。
注意:部署模型可能需要時間,為了更快地進行,您可以在本地嘗試運行。
按Deploy to IBM Cloud按鈕。如果您還沒有IBM雲帳戶,則需要創建一個。
單擊Delivery Pipeline ,然後單擊表單中的Create +按鈕,以生成Web應用程序的IBM Cloud API Key 。
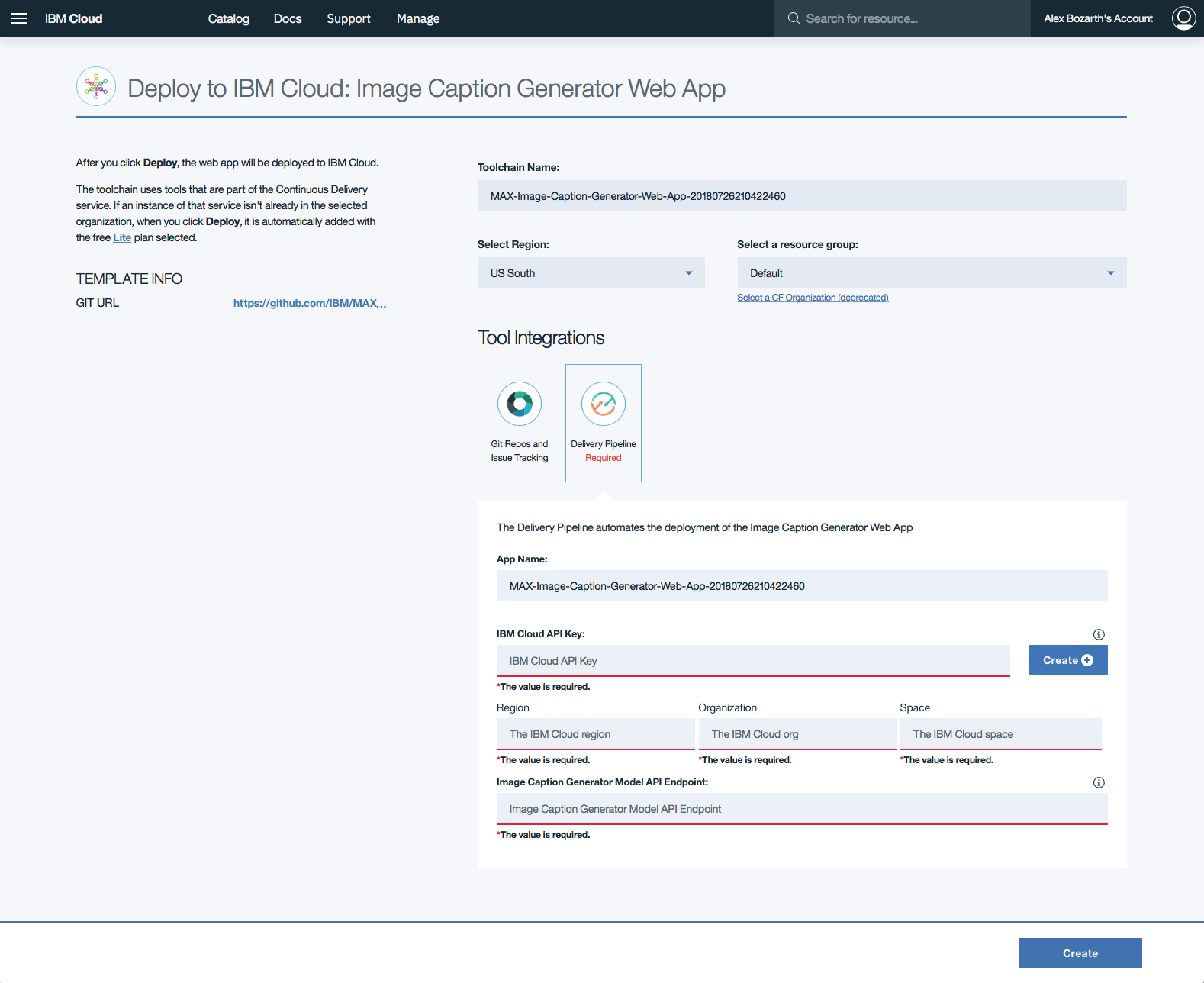
生成API密鑰後,將填充Region , Organization和Space形式部分。填寫Image Caption Generator Model API Endpoint部分,並使用上面部署的端點,然後單擊Create 。
此條目的格式應為
http://170.0.0.1:5000
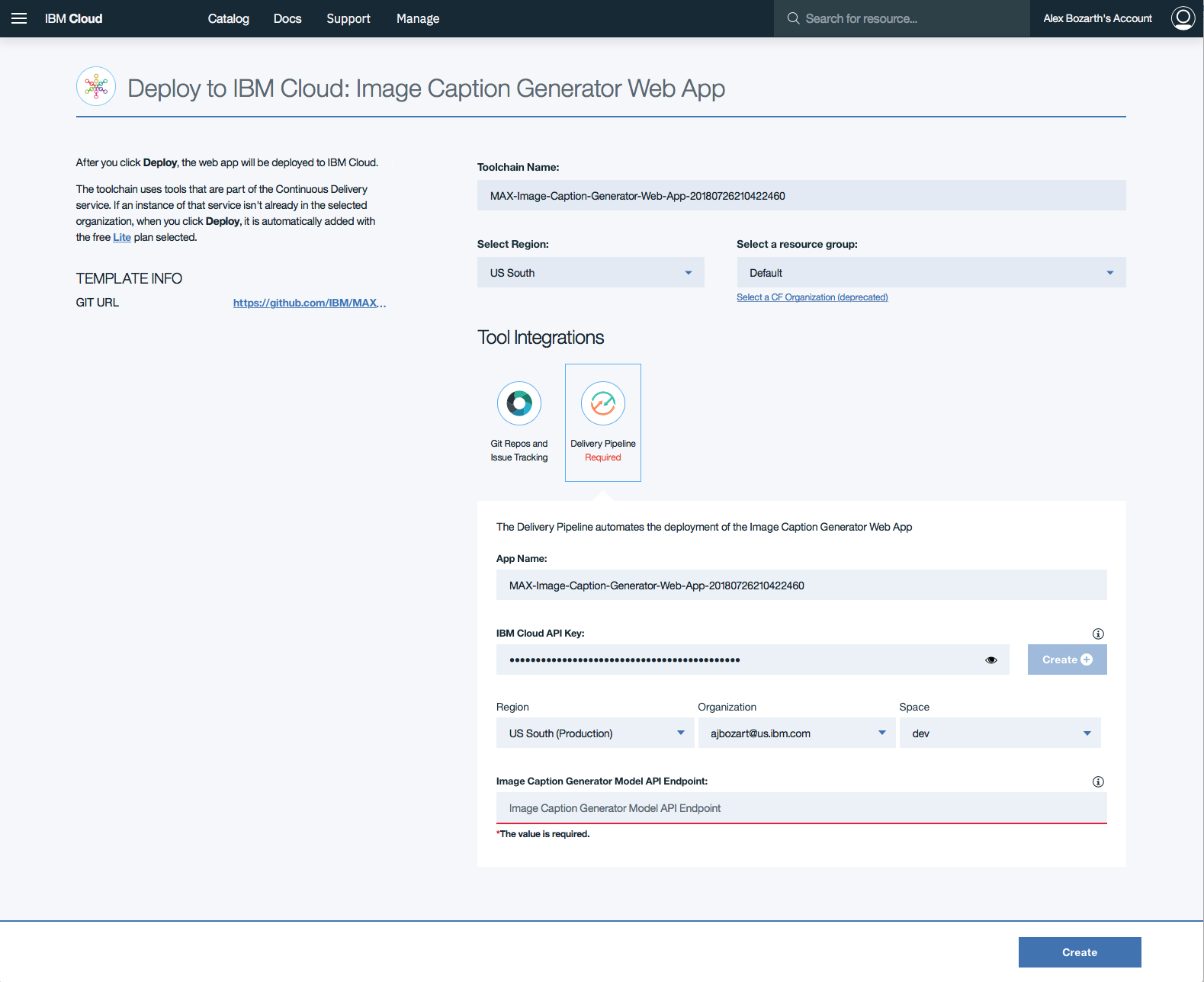
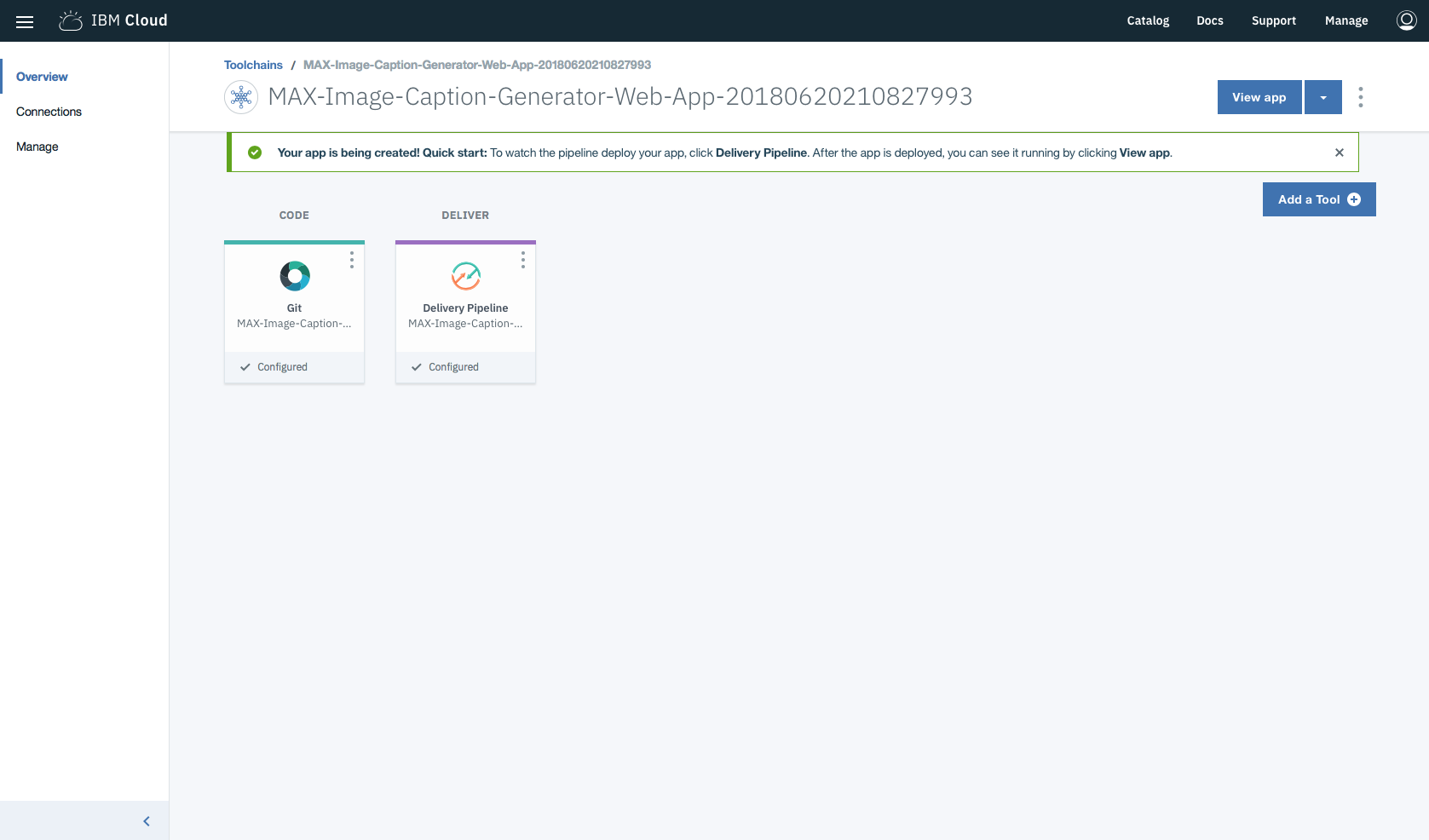
在工具鏈中,在部署應用程序時,單擊Delivery Pipeline以觀看。部署後,可以通過單擊View app查看該應用程序。
您還可以使用碼頭上的最新碼頭圖像在Kubernetes上部署模型和Web應用程序。
在您的kubernetes群集上,運行以下命令:
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator/master/max-image-caption-generator.yaml
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator-Web-App/master/max-image-caption-generator-web-app.yaml Web應用程序將在您的集群的端口8088上找到。該模型只能在內部提供,但可以通過NodePort在外部訪問。
注意:對於在IBM雲上部署Web應用程序,建議按照上述IBM雲指令進行部署,而不是使用IBM Cloud Kubernetes服務部署。
注意:僅當在本地運行而不是將
Deploy to IBM Cloud按鈕時,才需要這些步驟。
注意:本節中的一組指令是圖像字幕生成器項目頁面上找到的一個修改版本
要運行自動啟動Serving API模型的Docker Image,請運行:
docker run -it -p 5000:5000 quay.io/codait/max-image-caption-generator
這將從Quay中汲取預先構建的圖像(或使用現有的圖像,如果已經在本地緩存)並運行它。如果您想在本地構建模型,則可以按照模型讀數中的步驟進行操作。
請注意,當前此Docker映像僅是CPU(我們將稍後添加對GPU圖像的支持)。
API服務器會自動生成一個交互式搖搖欲墜的文檔頁面。轉到http://localhost:5000加載它。您可以從那裡探索API並創建測試請求。
使用model/predict端點加載測試文件並從API獲取圖像的標題。
模型示例文件夾包含一些您可以用來測試API的圖像,也可以使用自己的圖像。
您也可以在命令行上進行測試,例如:
curl -F " image=@path/to/image.jpg " -X POST http://localhost:5000/model/predict{
"status" : " ok " ,
"predictions" : [
{
"index" : " 0 " ,
"caption" : " a man riding a wave on top of a surfboard . " ,
"probability" : 0.038827644239537
},
{
"index" : " 1 " ,
"caption" : " a person riding a surf board on a wave " ,
"probability" : 0.017933410519265
},
{
"index" : " 2 " ,
"caption" : " a man riding a wave on a surfboard in the ocean . " ,
"probability" : 0.0056628732021868
}
]
}通過運行以下命令在本地克隆圖像字幕生成器Web應用程序存儲庫:
git clone https://github.com/IBM/MAX-Image-Caption-Generator-Web-App
注意:您可能需要
cd ..首先超出最大圖像捕獲生成器目錄
然後將目錄更改為本地存儲庫
cd MAX-Image-Caption-Generator-Web-App
在運行此Web應用程序之前,您必須安裝其依賴項:
pip install -r requirements.txt
然後,您可以通過運行啟動Web應用程序:
python app.py
完成處理默認圖像(<1分鐘)後,您可以訪問網絡應用程序: http://localhost:8088
圖像字幕生成器端點必須在http://localhost:5000中可用,以獲取Web應用程序才能成功啟動。
如果要使用其他端口或在其他位置運行ML端點,則可以使用命令行選項更改它們:
python app.py --port=[new port] --ml-endpoint=[endpoint url including protocol and port]
要使用Docker運行Web應用程序,運行Web服務器的容器,其餘端點需要共享同一網絡堆棧。這是通過以下步驟完成的:
修改運行圖像字幕生成器休息端點的命令,以將容器中的附加端口映射到主機計算機上的端口。在下面的示例中,它映射到主機上的端口8088 ,但也可以使用其他端口。
docker run -it -p 5000:5000 -p 8088:8088 --name max-image-caption-generator quay.io/codait/max-image-caption-generator
通過運行構建Web應用程序映像:
docker build -t max-image-caption-generator-web-app .
使用以下方式運行Web應用程序容器:
docker run --net='container:max-image-caption-generator' -it max-image-caption-generator-web-app
您還可以通過運行:
docker run --net='container:max-image-caption-generator' -it quay.io/codait/max-image-caption-generator-web-app
這將使用在上方運行的模型Docker容器,並且可以在無需克隆Web應用程序存儲庫的情況下運行。
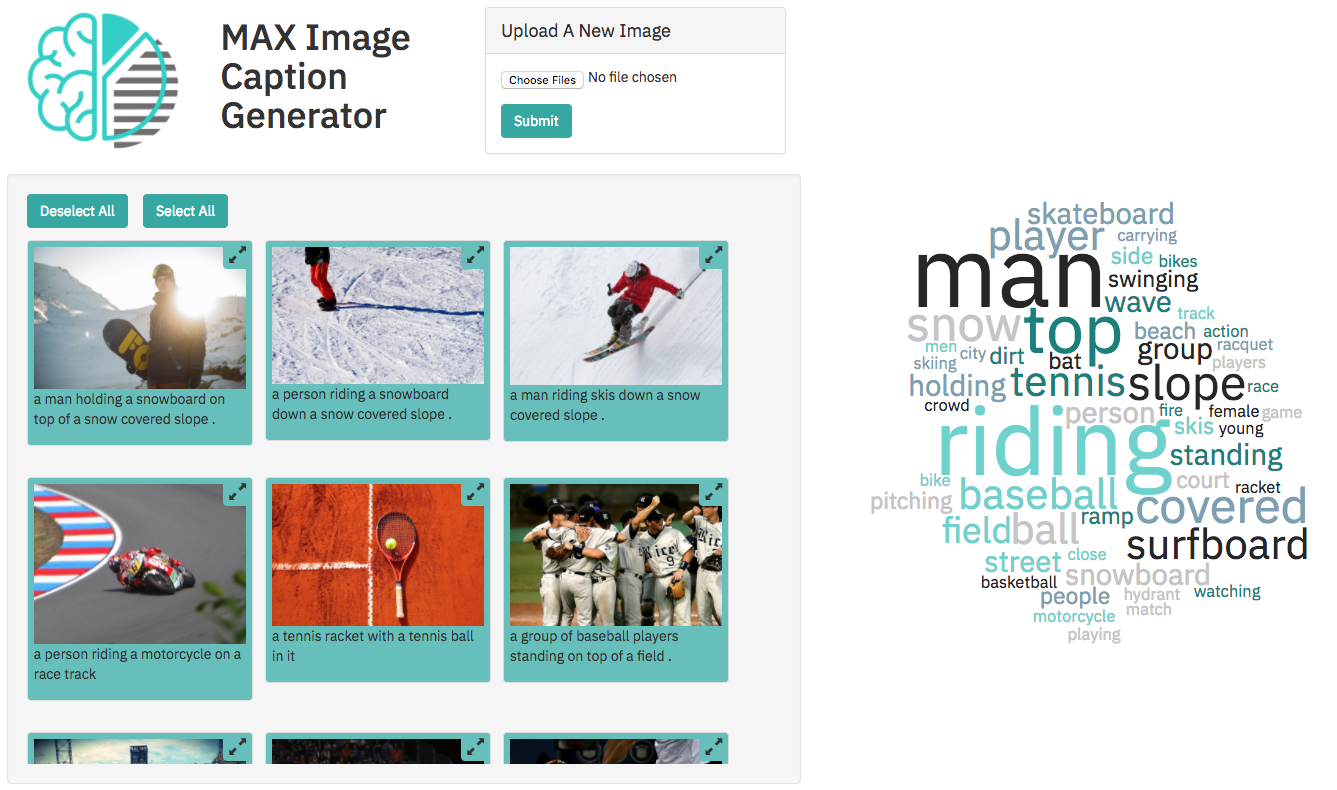
在長期運行的Web應用程序中,有大量用戶上傳的圖像
在
http://localhost:8088運行Web應用程序時,請通過http://localhost:8088/cleanup提供一個管理頁面,該頁面允許用戶從服務器刪除所有用戶上傳文件。[注意:這將刪除所有用戶上傳的圖像]
此代碼模式是根據Apache軟件許可證(版本2版)許可的。此代碼模式中調用的單獨的第三方代碼對象由其各自的提供商根據自己的單獨許可而獲得許可。貢獻受開發人員的原始證書(DCO)和Apache軟件許可證版本2的約束。
Apache軟件許可證(ASL)常見問題


