MAX Image Caption Generator Web App
Patch Release
Chaque jour 2,5, des obtets de données de données sont créés, sur la base d'une étude IBM. Une grande partie de ces données sont des données non structurées, telles que de grands textes, des enregistrements audio et des images. Afin de faire quelque chose d'utile avec les données, nous devons d'abord les convertir en données structurées.
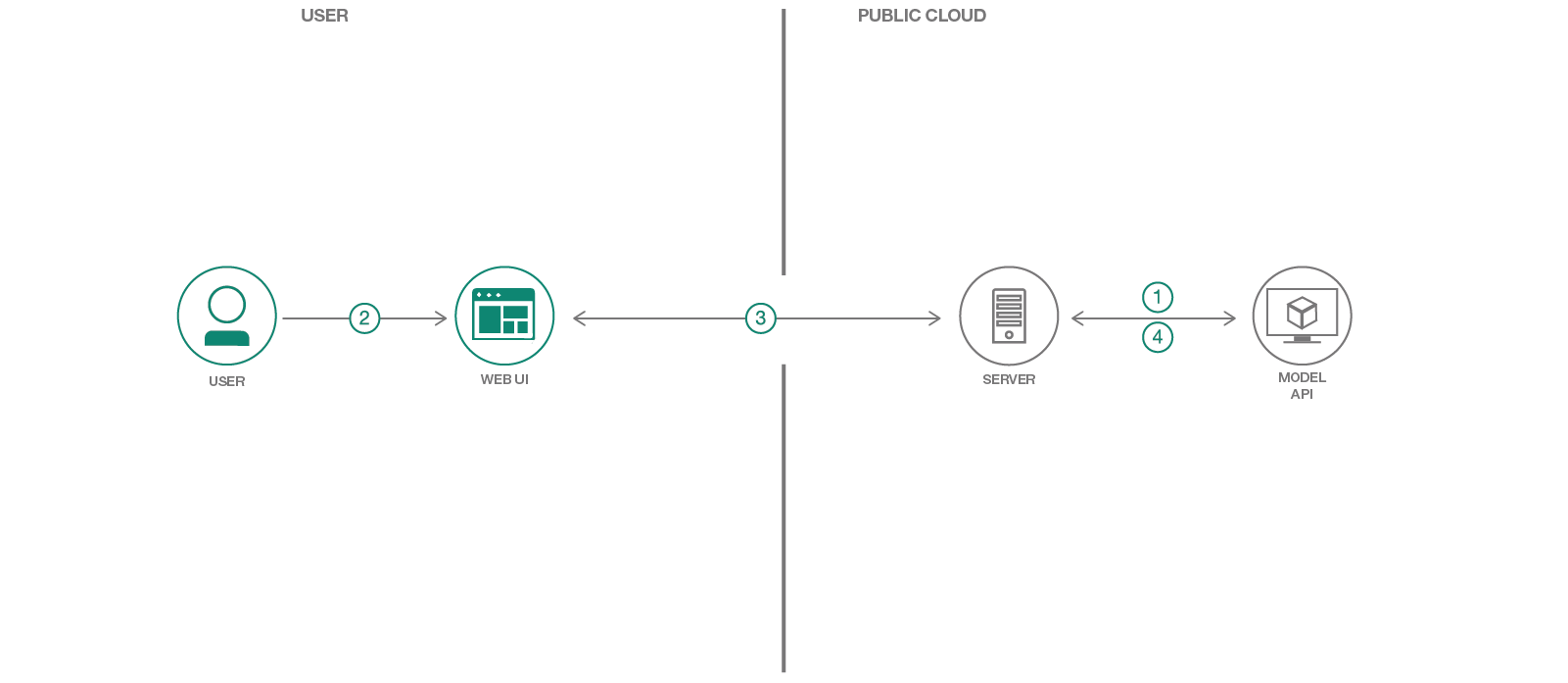
Dans ce modèle de code, nous utiliserons l'un des modèles du modèle Asset Exchange (MAX), un échange où les développeurs peuvent trouver et expérimenter avec des modèles d'apprentissage en profondeur open source. Plus précisément, nous utiliserons le générateur de légende d'image pour créer une application Web qui sous-légera les images et permettra à l'utilisateur de filtrer le contenu d'image basé sur des images. L'application Web fournit une interface utilisateur interactive soutenue par un serveur Python léger à l'aide de Tornado. Le serveur prend des images via l'interface utilisateur et les envoie à un point d'extrémité de repos pour le modèle et affiche les légendes générées sur l'interface utilisateur. Le point de terminaison de repos du modèle est configuré à l'aide de l'image docker fournie sur Max. L'interface utilisateur Web affiche les légendes générées pour chaque image ainsi qu'un cloud de mots interactif pour filtrer les images en fonction de leur légende.
Lorsque le lecteur aura terminé ce modèle de code, il comprendra comment:
Ce qui suit est une conférence à Spark + AI Summit 2018 sur Max qui comprend une courte démo de l'application Web.
Moyens d'exécuter le modèle de code:
Suivez le déploiement du modèle Doc pour déployer le modèle de générateur d'image sur IBM Cloud. Si vous avez déjà un point de terminaison API disponible, vous pouvez ignorer ce processus.
Remarque: le déploiement du modèle peut prendre du temps, pour aller plus vite, vous pouvez essayer de fonctionner localement.
Appuyez Deploy to IBM Cloud . Si vous n'avez pas encore de compte IBM Cloud, vous devrez en créer un.
Cliquez sur Delivery Pipeline et cliquez sur le bouton Create + dans le formulaire pour générer une IBM Cloud API Key pour l'application Web.
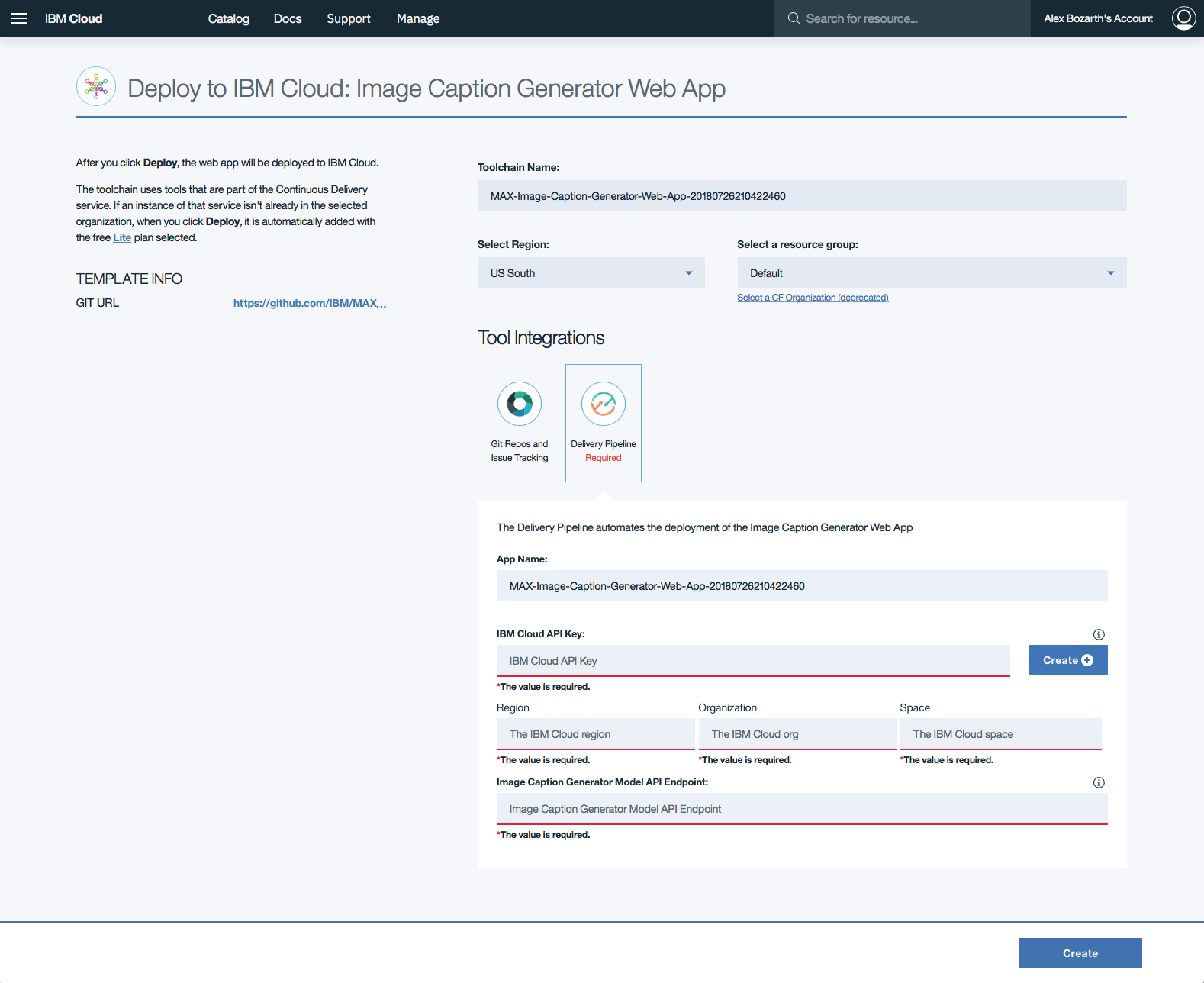
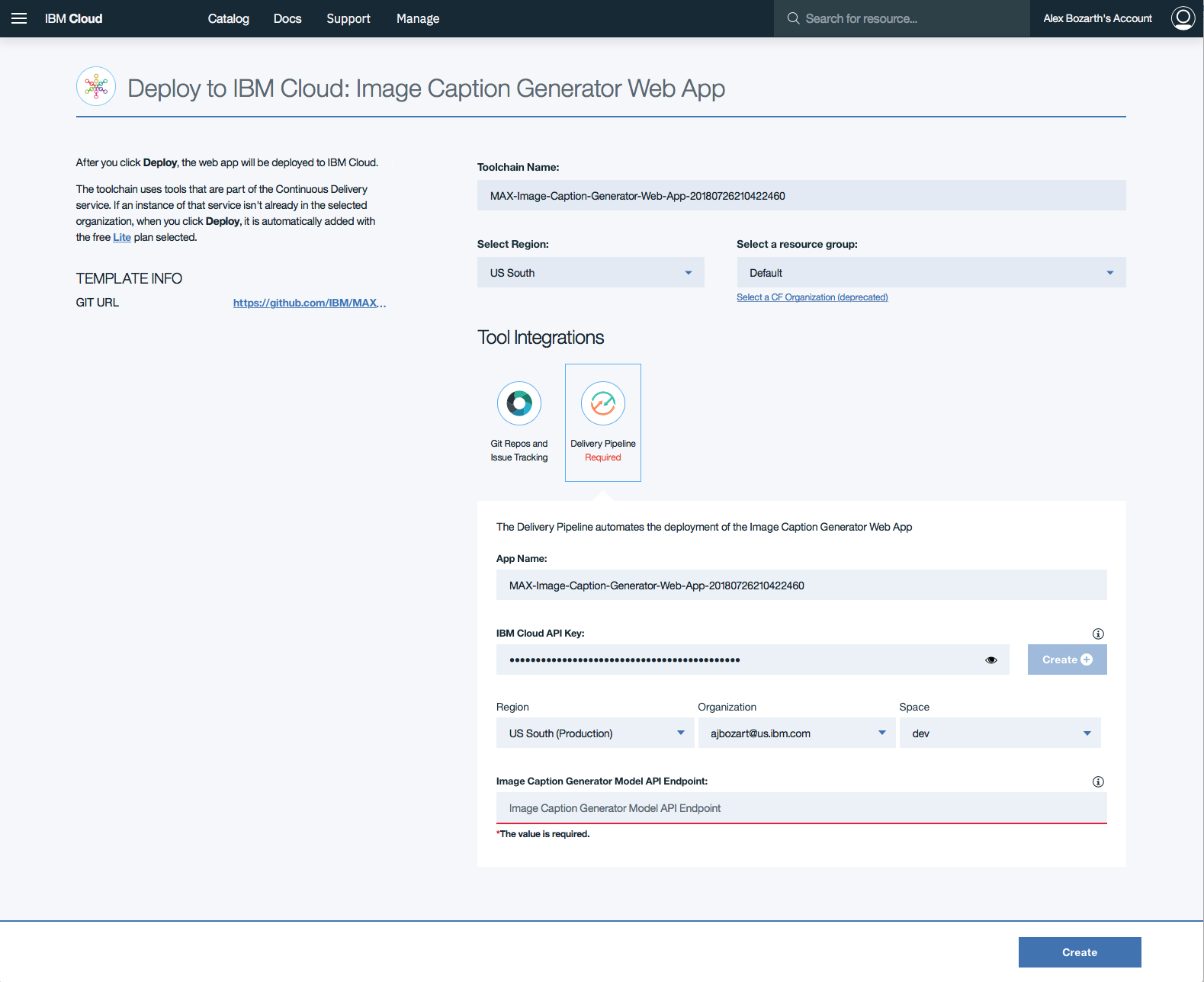
Une fois la touche API générée, la Region , Organization et les sections de formulaires Space remporteront. Remplissez la section Image Caption Generator Model API Endpoint avec le point de terminaison déployé ci-dessus, puis cliquez sur Create .
Le format de cette entrée doit être
http://170.0.0.1:5000
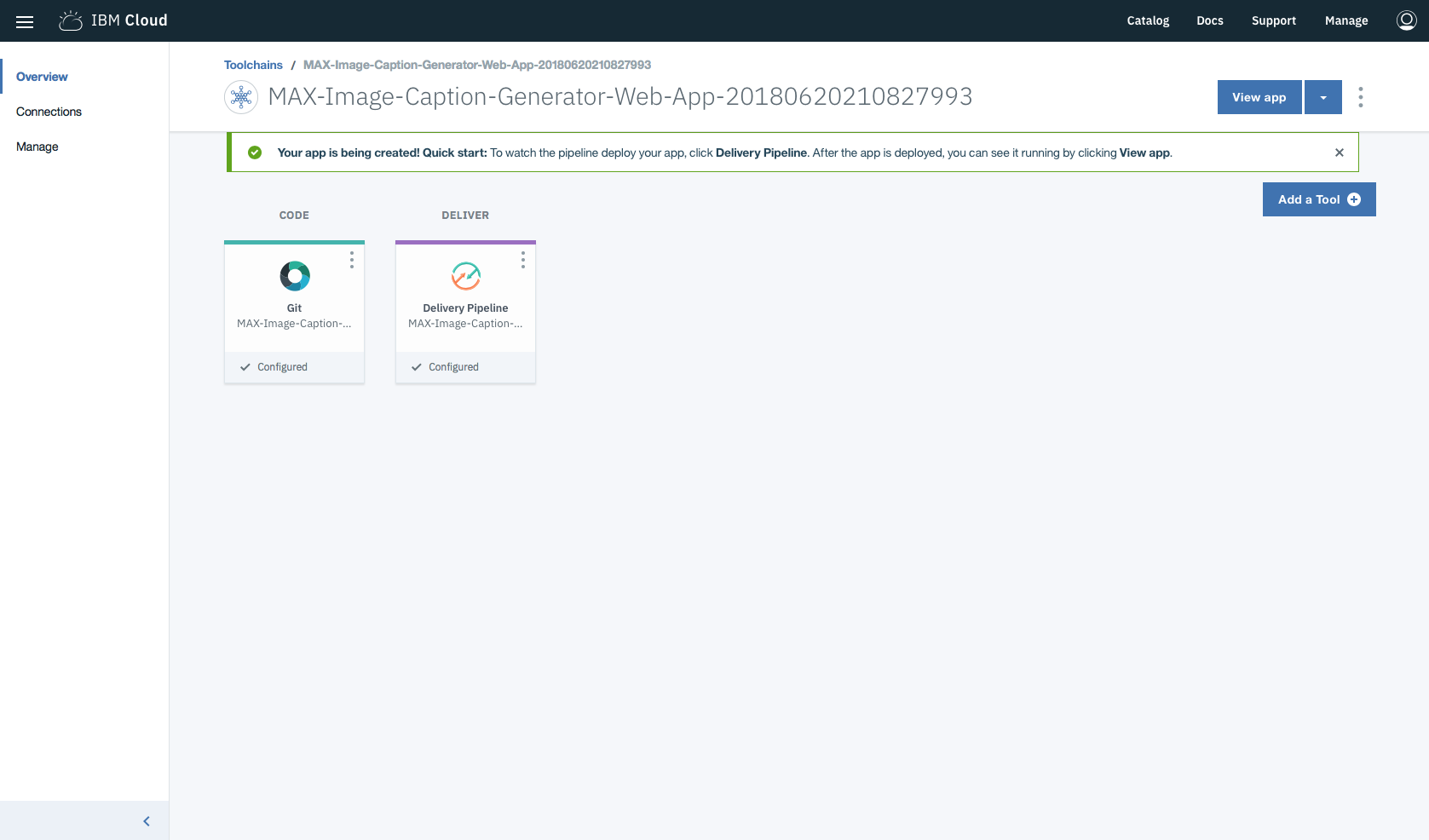
Dans les chaînes d'outils, cliquez sur Delivery Pipeline pour regarder pendant que l'application est déployée. Une fois déployé, l'application peut être affichée en cliquant sur View app .
Vous pouvez également déployer le modèle et l'application Web sur Kubernetes à l'aide des dernières images Docker sur Quay.
Sur votre cluster Kubernetes, exécutez les commandes suivantes:
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator/master/max-image-caption-generator.yaml
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator-Web-App/master/max-image-caption-generator-web-app.yaml L'application Web sera disponible au port 8088 de votre cluster. Le modèle ne sera disponible qu'en interne, mais est accessible en externe via le NodePort .
Remarque: Pour déployer l'application Web sur IBM Cloud, il est recommandé de suivre les instructions de déploiement vers IBM Cloud ci-dessus plutôt que de déployer avec le service IBM Cloud Kubernetes.
Remarque: ces étapes ne sont nécessaires que lors de l'exécution localement au lieu d'utiliser le bouton
Deploy to IBM Cloud.
Remarque: L'ensemble d'instructions dans cette section est une version modifiée de celle trouvée sur la page du projet Générateur de légendes de l'image
Pour exécuter l'image Docker, qui démarre automatiquement l'API de service modèle, exécutez:
docker run -it -p 5000:5000 quay.io/codait/max-image-caption-generator
Cela tirera une image prédéfinie de Quay (ou utilisera une image existante si elle est déjà mise en cache localement) et l'exécutera. Si vous préférez construire le modèle localement, vous pouvez suivre les étapes du modèle Readme.
Notez qu'actuellement, cette image Docker est uniquement CPU (nous ajouterons la prise en charge des images GPU plus tard).
Le serveur API génère automatiquement une page de documentation interactive Swagger. Allez sur http://localhost:5000 pour le charger. De là, vous pouvez explorer l'API et également créer des demandes de test.
Utilisez le point de terminaison model/predict pour charger un fichier de test et obtenir des légendes pour l'image de l'API.
Le dossier des échantillons de modèle contient quelques images que vous pouvez utiliser pour tester l'API, ou vous pouvez utiliser le vôtre.
Vous pouvez également le tester sur la ligne de commande, par exemple:
curl -F " image=@path/to/image.jpg " -X POST http://localhost:5000/model/predict{
"status" : " ok " ,
"predictions" : [
{
"index" : " 0 " ,
"caption" : " a man riding a wave on top of a surfboard . " ,
"probability" : 0.038827644239537
},
{
"index" : " 1 " ,
"caption" : " a person riding a surf board on a wave " ,
"probability" : 0.017933410519265
},
{
"index" : " 2 " ,
"caption" : " a man riding a wave on a surfboard in the ocean . " ,
"probability" : 0.0056628732021868
}
]
}Clone Le référentiel d'applications Web du générateur de légendes d'image localement en exécutant la commande suivante:
git clone https://github.com/IBM/MAX-Image-Caption-Generator-Web-App
Remarque: vous devrez peut-être
cd ..hors du répertoire du générateur de caption max-image d'abord d'abord
Puis changer le répertoire en référentiel local
cd MAX-Image-Caption-Generator-Web-App
Avant d'exécuter cette application Web, vous devez installer ses dépendances:
pip install -r requirements.txt
Vous démarrez ensuite l'application Web en exécutant:
python app.py
Une fois qu'il a terminé le traitement des images par défaut (<1 minute), vous pouvez ensuite accéder à l'application Web à: http://localhost:8088
Le point de terminaison du générateur d'image doit être disponible sur http://localhost:5000 pour l'application Web pour démarrer avec succès.
Si vous souhaitez utiliser un port différent ou exécutez le point de terminaison ML à un endroit différent, vous pouvez les modifier avec des options de ligne de commande:
python app.py --port=[new port] --ml-endpoint=[endpoint url including protocol and port]
Pour exécuter l'application Web avec Docker, les conteneurs exécutant le serveur Web et le point de terminaison de repos doivent partager la même pile réseau. Cela se fait dans les étapes suivantes:
Modifiez la commande qui exécute le point de terminaison de repos du générateur de légende d'image pour mapper un port supplémentaire dans le conteneur sur un port de la machine hôte. Dans l'exemple ci-dessous, il est mappé au port 8088 sur l'hôte, mais d'autres ports peuvent également être utilisés.
docker run -it -p 5000:5000 -p 8088:8088 --name max-image-caption-generator quay.io/codait/max-image-caption-generator
Créez l'image de l'application Web en exécutant:
docker build -t max-image-caption-generator-web-app .
Exécutez le conteneur de l'application Web à l'aide:
docker run --net='container:max-image-caption-generator' -it max-image-caption-generator-web-app
Vous pouvez également déployer l'application Web avec la dernière image Docker disponible sur Quay.io en exécutant:
docker run --net='container:max-image-caption-generator' -it quay.io/codait/max-image-caption-generator-web-app
Cela utilisera le conteneur Docker de modèle exécuté ci-dessus et peut être exécuté sans cloner le repo de l'application Web localement.
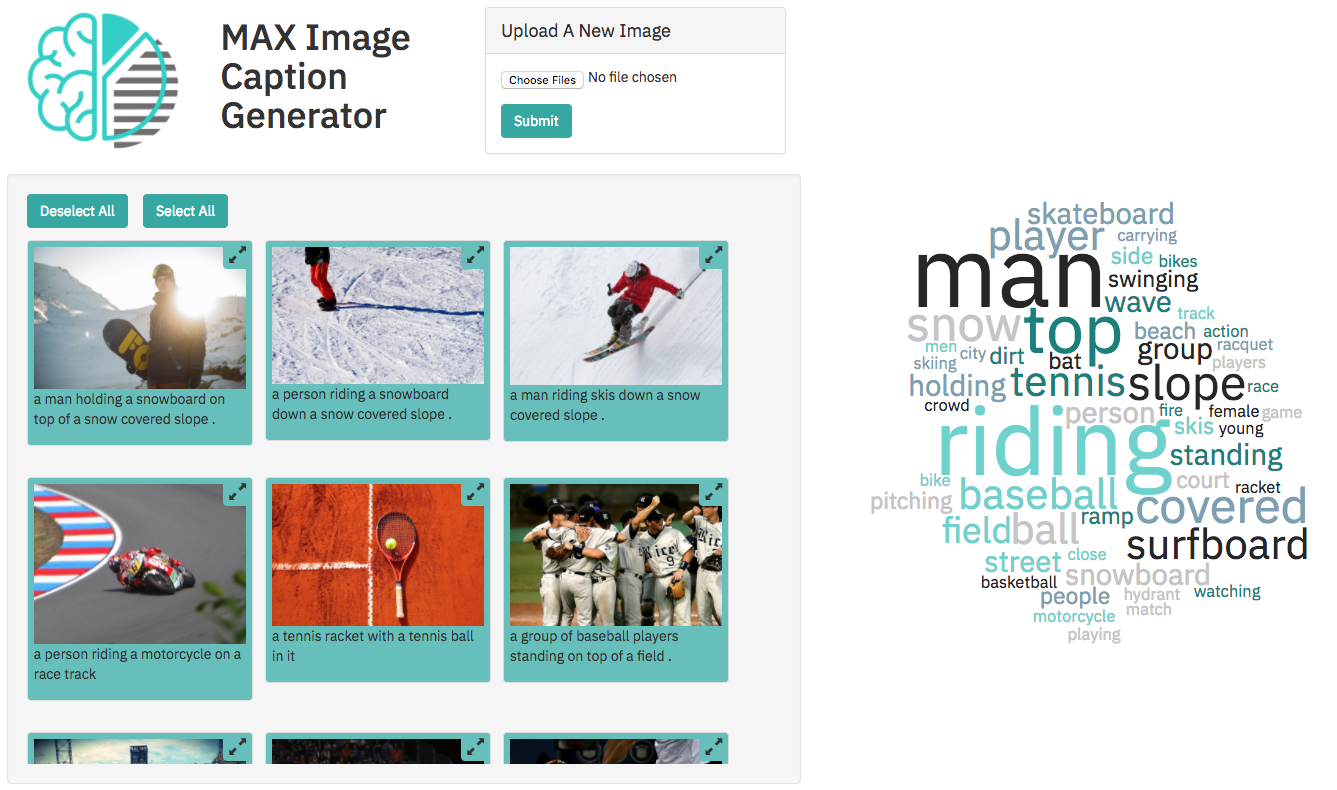
Il y a une grande quantité d'images téléchargées par l'utilisateur dans une application Web de longue date
Lors de l'exécution de l'application Web sur
http://localhost:8088une page d'administration est disponible surhttp://localhost:8088/cleanupqui permet à l'utilisateur de supprimer tous les fichiers téléchargés de l'utilisateur du serveur.[Remarque: cela supprime toutes les images téléchargées par l'utilisateur]
Ce modèle de code est concédé sous licence APAChes, version 2. Les objets de code tiers séparés invoqués dans ce modèle de code sont sous licence par leurs fournisseurs respectifs conformément à leurs propres licences distinctes. Les contributions sont soumises au certificat d'origine du développeur, version 1.1 (DCO) et à la licence logicielle Apache, version 2.
FAQ de licence de logiciel Apache (ASL)


