MAX Image Caption Generator Web App
Patch Release
Todos os dias 2.5 Quintilhões de dados de dados são criados, com base em um estudo da IBM. Muitos desses dados são dados não estruturados, como textos grandes, gravações de áudio e imagens. Para fazer algo útil com os dados, devemos primeiro convertê -los em dados estruturados.
Nesse padrão de código, usaremos um dos modelos da troca de ativos de modelo (MAX), uma troca em que os desenvolvedores podem encontrar e experimentar modelos de aprendizado profundo de código aberto. Especificamente, usaremos o gerador de legenda da imagem para criar um aplicativo da Web que permitirá que o usuário seja filtrado através do conteúdo da imagem baseado em imagens. O aplicativo da Web fornece uma interface de usuário interativa apoiada por um servidor Python leve usando o Tornado. O servidor recebe imagens pela interface do usuário e as envia para um ponto final para o modelo e exibe as legendas geradas na interface do usuário. O terminal de descanso do modelo é configurado usando a imagem do Docker fornecida no máximo. A interface do usuário da web exibe as legendas geradas para cada imagem, bem como uma nuvem de palavras interativa para filtrar as imagens com base em sua legenda.
Quando o leitor concluir esse padrão de código, eles entenderão como:
A seguir, é apresentada uma palestra no Spark+AI Summit 2018 sobre Max, que inclui uma demonstração curta do aplicativo da web.
Maneiras de executar o padrão de código:
Siga a implantação do Model Doc para implantar o modelo do gerador de legenda da imagem na IBM Cloud. Se você já possui um ponto de extremidade da API do modelo disponível, pode pular esse processo.
NOTA: A implantação do modelo pode levar tempo, para continuar mais rápido, você pode tentar executar localmente.
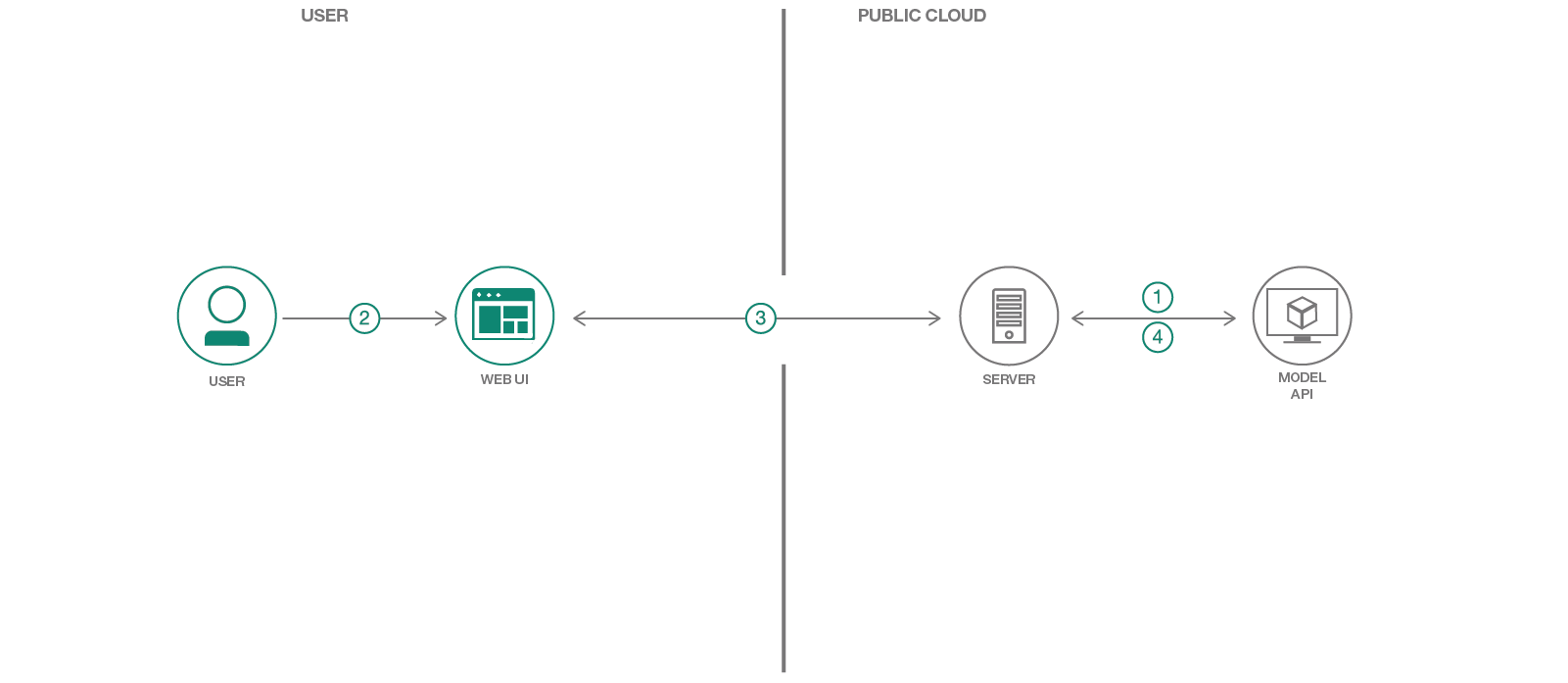
Pressione a Deploy to IBM Cloud . Se você ainda não possui uma conta do IBM Cloud, precisará criar uma.
Clique em Delivery Pipeline e clique no botão Create + no formulário para gerar uma IBM Cloud API Key para o aplicativo da Web.
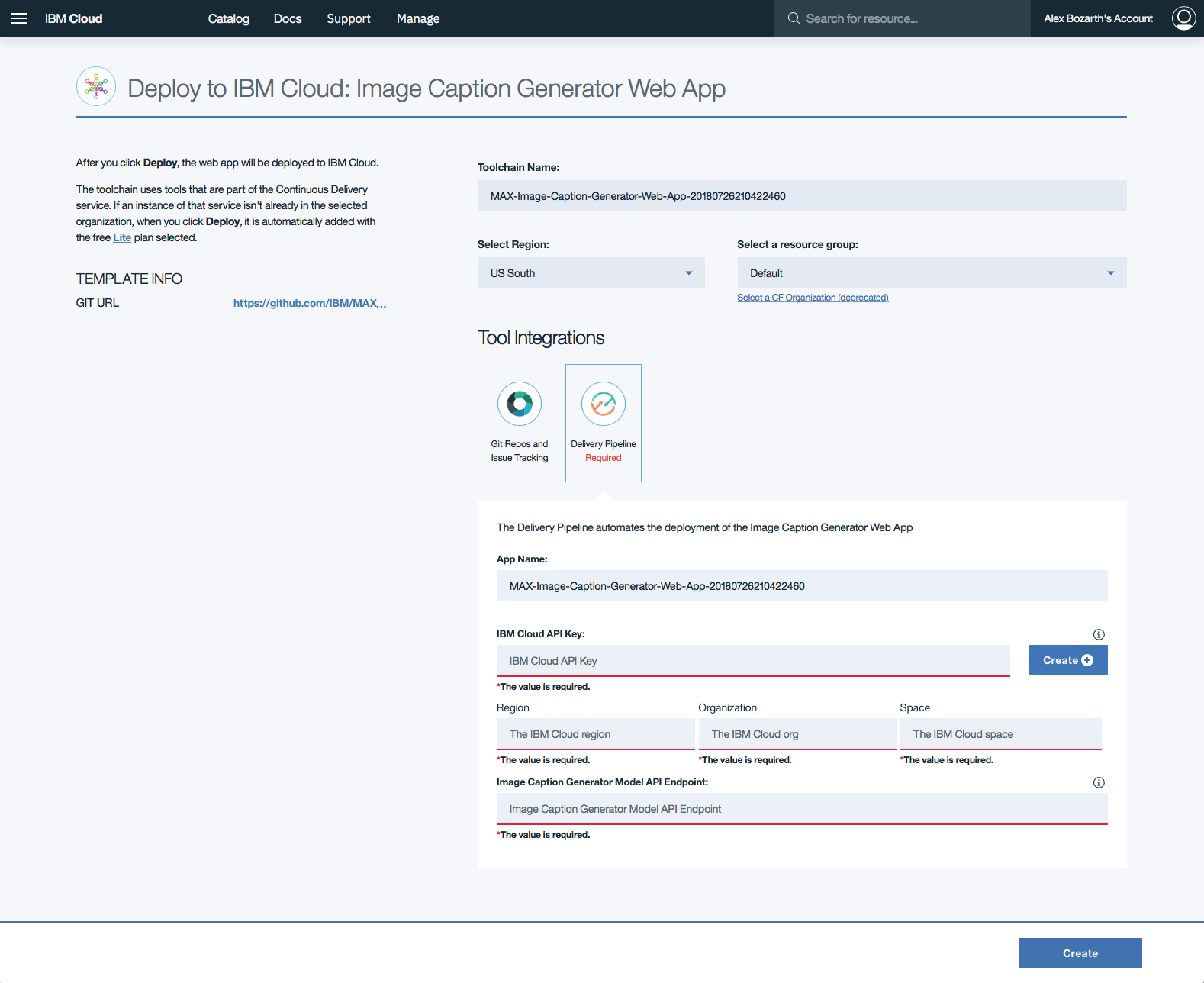
Depois que a chave da API for gerada, as seções de Region , Organization e formulário Space preencherão. Preencha a seção Image Caption Generator Model API Endpoint com o ponto final implantado acima e, em seguida, clique em Create .
O formato para esta entrada deve ser
http://170.0.0.1:5000
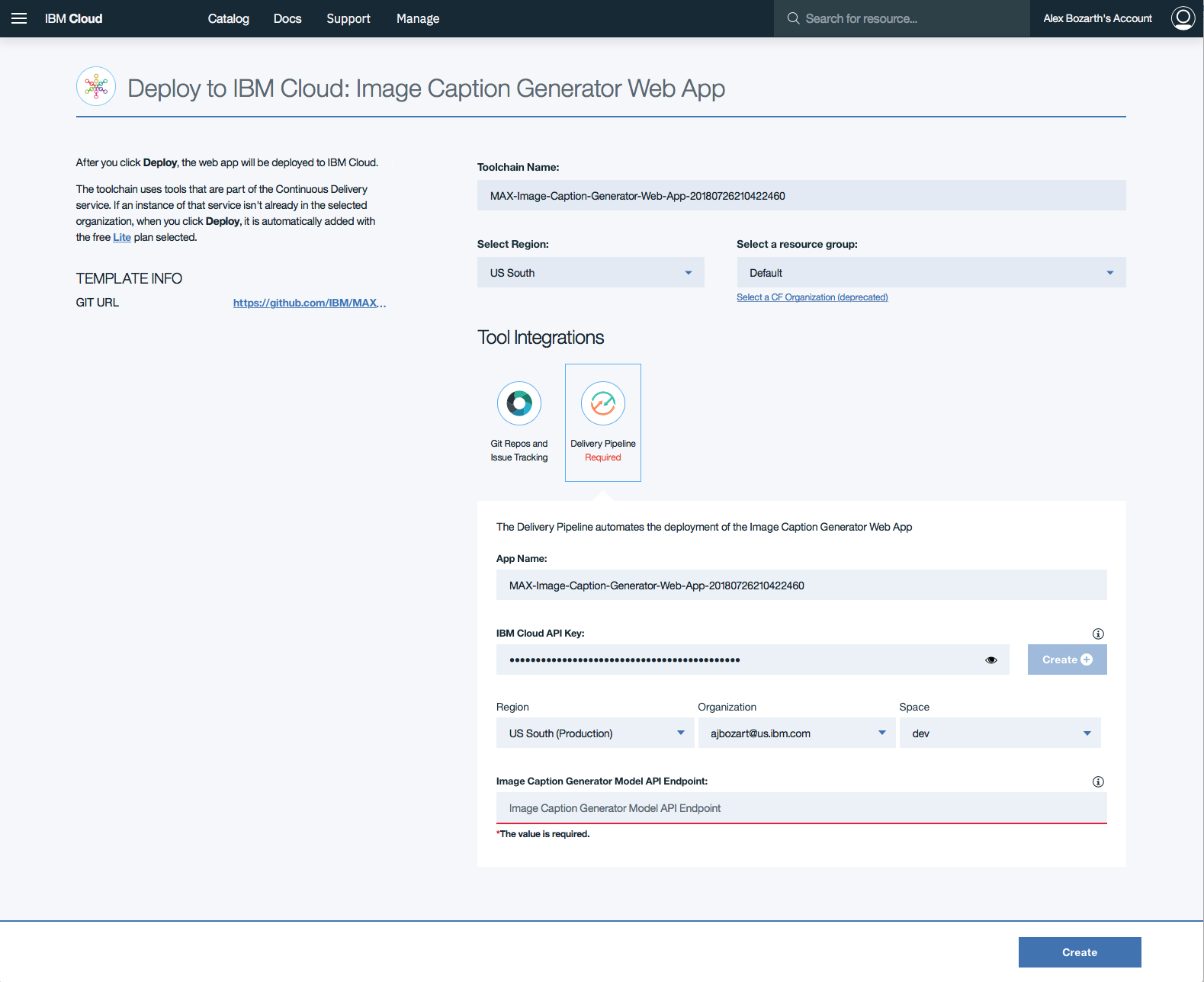
Nas cadeias de ferramentas, clique no Delivery Pipeline para assistir enquanto o aplicativo é implantado. Depois de implantado, o aplicativo pode ser visualizado clicando em View app .
Você também pode implantar o modelo e o aplicativo da Web no Kubernetes usando as mais recentes imagens do Docker no Quay.
Em seu cluster Kubernetes, execute os seguintes comandos:
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator/master/max-image-caption-generator.yaml
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator-Web-App/master/max-image-caption-generator-web-app.yaml O aplicativo da web estará disponível na porta 8088 do seu cluster. O modelo só estará disponível internamente, mas pode ser acessado externamente através do NodePort .
Nota: Para implantar o aplicativo da Web na IBM Cloud, é recomendável seguir as instruções de implantação da IBM em nuvem acima, em vez de implantar com o serviço IBM Cloud Kubernetes.
NOTA: Essas etapas são necessárias apenas ao executar localmente, em vez de usar o botão
Deploy to IBM Cloud.
NOTA: O conjunto de instruções nesta seção é uma versão modificada do encontrado na página do projeto do gerador de legenda da imagem
Para executar a imagem do Docker, que inicia automaticamente a API de servir o modelo, execute:
docker run -it -p 5000:5000 quay.io/codait/max-image-caption-generator
Isso extrairá uma imagem pré-construída do Quay (ou usará uma imagem existente se já em cache localmente) e executá-la. Se você preferir construir o modelo localmente, poderá seguir as etapas do modelo ReadMe.
Observe que atualmente essa imagem do Docker é apenas a CPU (adicionaremos suporte para imagens de GPU posteriormente).
O servidor da API gera automaticamente uma página de documentação de arrogância interativa. Vá para http://localhost:5000 para carregá -lo. A partir daí, você pode explorar a API e também criar solicitações de teste.
Use o model/predict o terminal para carregar um arquivo de teste e obter legendas para a imagem da API.
A pasta de amostras de modelo contém algumas imagens que você pode usar para testar a API, ou você pode usar o seu.
Você também pode testá -lo na linha de comando, por exemplo:
curl -F " image=@path/to/image.jpg " -X POST http://localhost:5000/model/predict{
"status" : " ok " ,
"predictions" : [
{
"index" : " 0 " ,
"caption" : " a man riding a wave on top of a surfboard . " ,
"probability" : 0.038827644239537
},
{
"index" : " 1 " ,
"caption" : " a person riding a surf board on a wave " ,
"probability" : 0.017933410519265
},
{
"index" : " 2 " ,
"caption" : " a man riding a wave on a surfboard in the ocean . " ,
"probability" : 0.0056628732021868
}
]
}Clone o repositório de aplicativos da web gerador de legenda da imagem localmente, executando o seguinte comando:
git clone https://github.com/IBM/MAX-Image-Caption-Generator-Web-App
Nota: Você pode precisar de
cd ..fora do diretório Max-Image-Caption-Generator First
Em seguida, altere o diretório para o repositório local
cd MAX-Image-Caption-Generator-Web-App
Antes de executar este aplicativo da web, você deve instalar suas dependências:
pip install -r requirements.txt
Você então inicia o aplicativo da web executando:
python app.py
Quando terminar de processar as imagens padrão (<1 minuto), você pode acessar o aplicativo da web em: http://localhost:8088
O terminal do gerador de legenda da imagem deve estar disponível em http://localhost:5000 para o aplicativo da web iniciar com êxito.
Se você deseja usar uma porta diferente ou estiver executando o terminal ML em um local diferente, você pode alterá-los com as opções da linha de comando:
python app.py --port=[new port] --ml-endpoint=[endpoint url including protocol and port]
Para executar o aplicativo da web com o Docker, os contêineres executando o servidor da Web e o endpoint REST precisam compartilhar a mesma pilha de rede. Isso é feito nas etapas seguintes:
Modifique o comando que executa o terminal de restos do gerador de legenda da imagem para mapear uma porta adicional no contêiner em uma porta na máquina host. No exemplo abaixo, ele é mapeado para a porta 8088 no host, mas outras portas também podem ser usadas.
docker run -it -p 5000:5000 -p 8088:8088 --name max-image-caption-generator quay.io/codait/max-image-caption-generator
Crie a imagem do aplicativo da web executando:
docker build -t max-image-caption-generator-web-app .
Execute o contêiner do aplicativo da web usando:
docker run --net='container:max-image-caption-generator' -it max-image-caption-generator-web-app
Você também pode implantar o aplicativo da web com a imagem mais recente do Docker disponível no Quay.io em execução:
docker run --net='container:max-image-caption-generator' -it quay.io/codait/max-image-caption-generator-web-app
Isso usará o recipiente do Docker do modelo executado acima e pode ser executado sem clonar o repositório do aplicativo da web localmente.
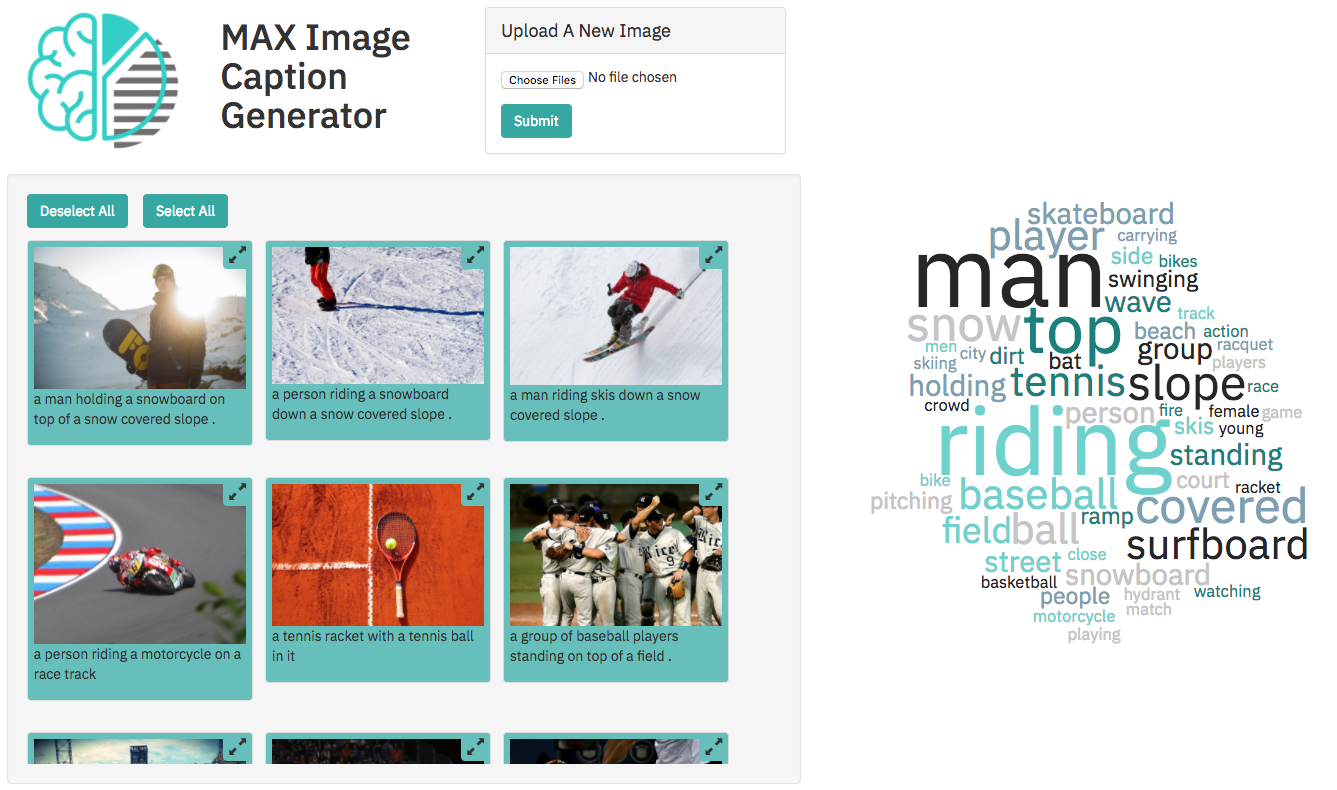
Há uma grande quantidade de imagens enviadas pelo usuário em um aplicativo da web de longa duração
Ao executar o aplicativo da web em
http://localhost:8088Uma página de administração está disponível emhttp://localhost:8088/cleanupque permite ao usuário excluir todos os arquivos carregados do usuário do servidor.[Nota: isso exclui todas as imagens carregadas do usuário]
Esse padrão de código é licenciado sob a licença do software Apache, versão 2. Objetos de código de terceiros separados invocados nesse padrão de código são licenciados por seus respectivos fornecedores de acordo com suas próprias licenças separadas. As contribuições estão sujeitas ao Certificado de Origem do Desenvolvedor, versão 1.1 (DCO) e Licença de Software Apache, versão 2.
Perguntas frequentes para licença de software Apache (ASL)


