MAX Image Caption Generator Web App
Patch Release
Todos los días se crean 2.5 quintillones de datos de datos, basados en un estudio de IBM. Muchos de esos datos son datos no estructurados, como textos grandes, grabaciones de audio e imágenes. Para hacer algo útil con los datos, primero debemos convertirlo en datos estructurados.
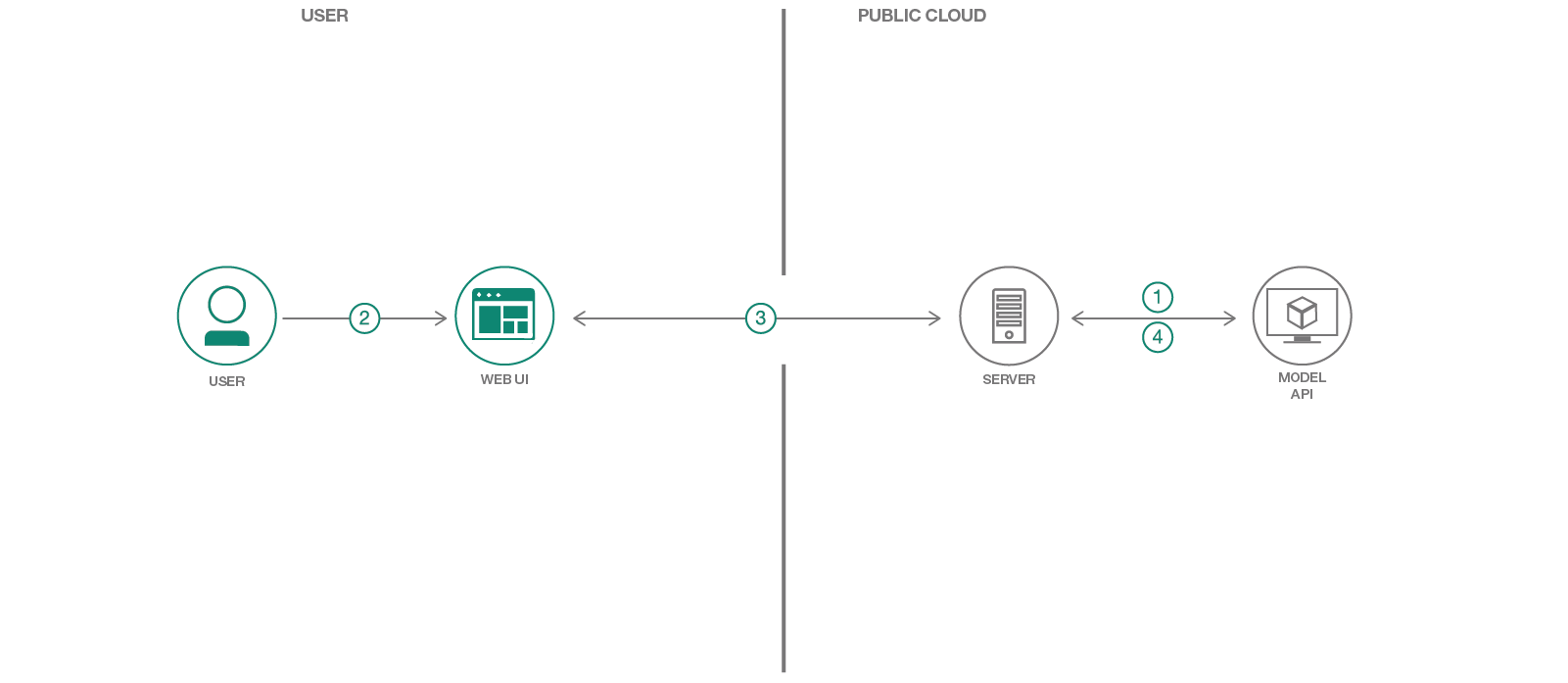
En este patrón de código utilizaremos uno de los modelos del Model Asset Exchange (Max), un intercambio donde los desarrolladores pueden encontrar y experimentar con modelos de aprendizaje profundo de código abierto. Específicamente, utilizaremos el generador de título de imagen para crear una aplicación web que subtitule las imágenes y permitirá al usuario filtrar a través del contenido de imagen basado en imágenes. La aplicación web proporciona una interfaz de usuario interactiva respaldada por un servidor Python ligero que usa Tornado. El servidor toma imágenes a través de la interfaz de usuario y las envía a un punto de descanso para el modelo y muestra los subtítulos generados en la interfaz de usuario. El punto final REST del modelo se configura utilizando la imagen Docker proporcionada en Max. La interfaz de usuario web muestra los subtítulos generados para cada imagen, así como una nube de palabras interactiva para filtrar imágenes en función de su leyenda.
Cuando el lector haya completado este patrón de código, comprenderá cómo:
La siguiente es una charla en Spark+AI Summit 2018 sobre Max que incluye una breve demostración de la aplicación web.
Formas de ejecutar el patrón de código:
Siga el Doc de implementación del modelo para implementar el modelo de generador de título de imagen en IBM Cloud. Si ya tiene un punto final de API de modelo disponible, puede omitir este proceso.
Nota: Implementar el modelo puede tomar tiempo, para ponerse en marcha más rápido, puede intentar ejecutar localmente.
Presione el botón Deploy to IBM Cloud . Si aún no tiene una cuenta de IBM Cloud, deberá crear una.
Haga clic en Delivery Pipeline y haga clic en el botón Create + en el formulario para generar una IBM Cloud API Key para la aplicación web.
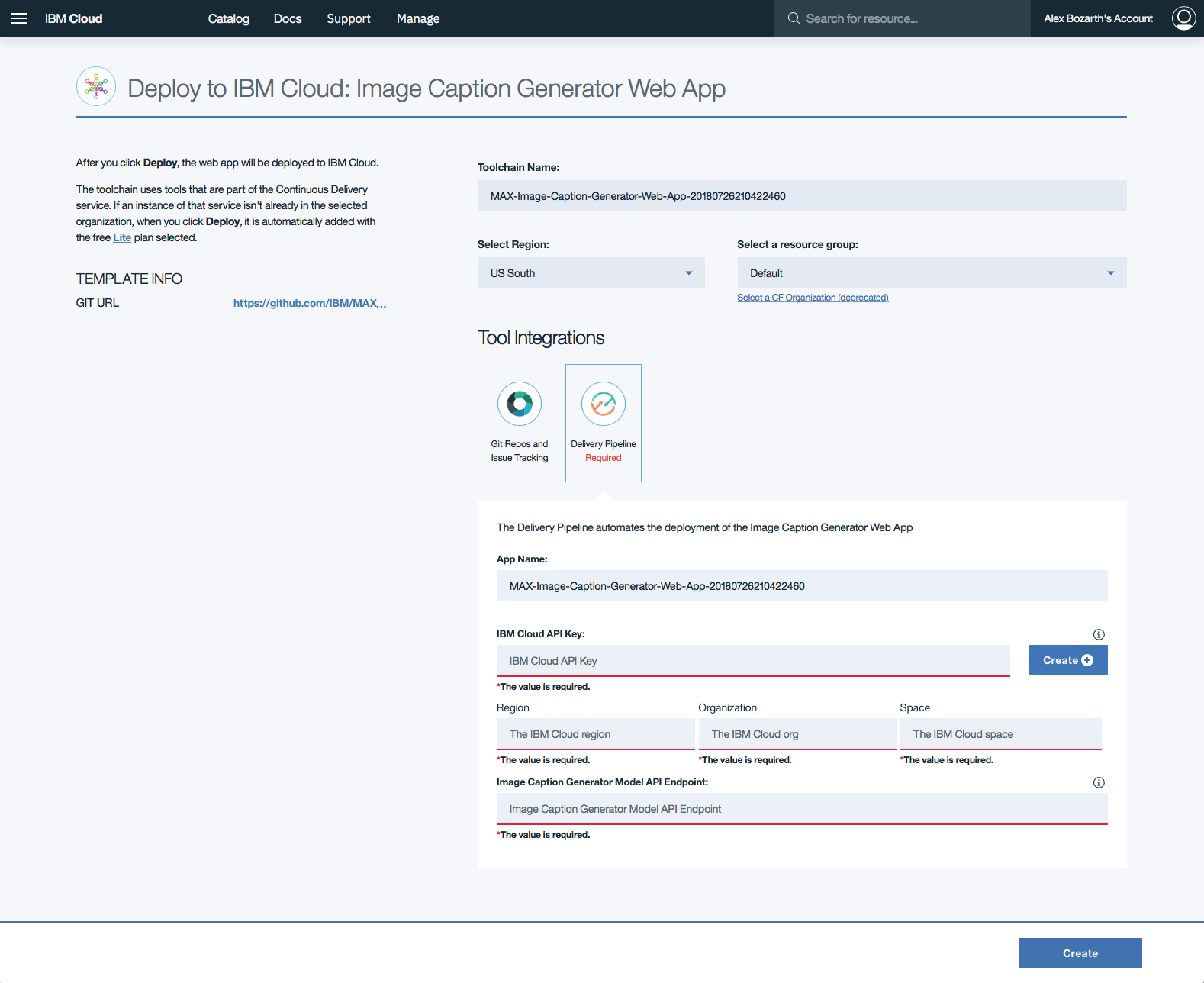
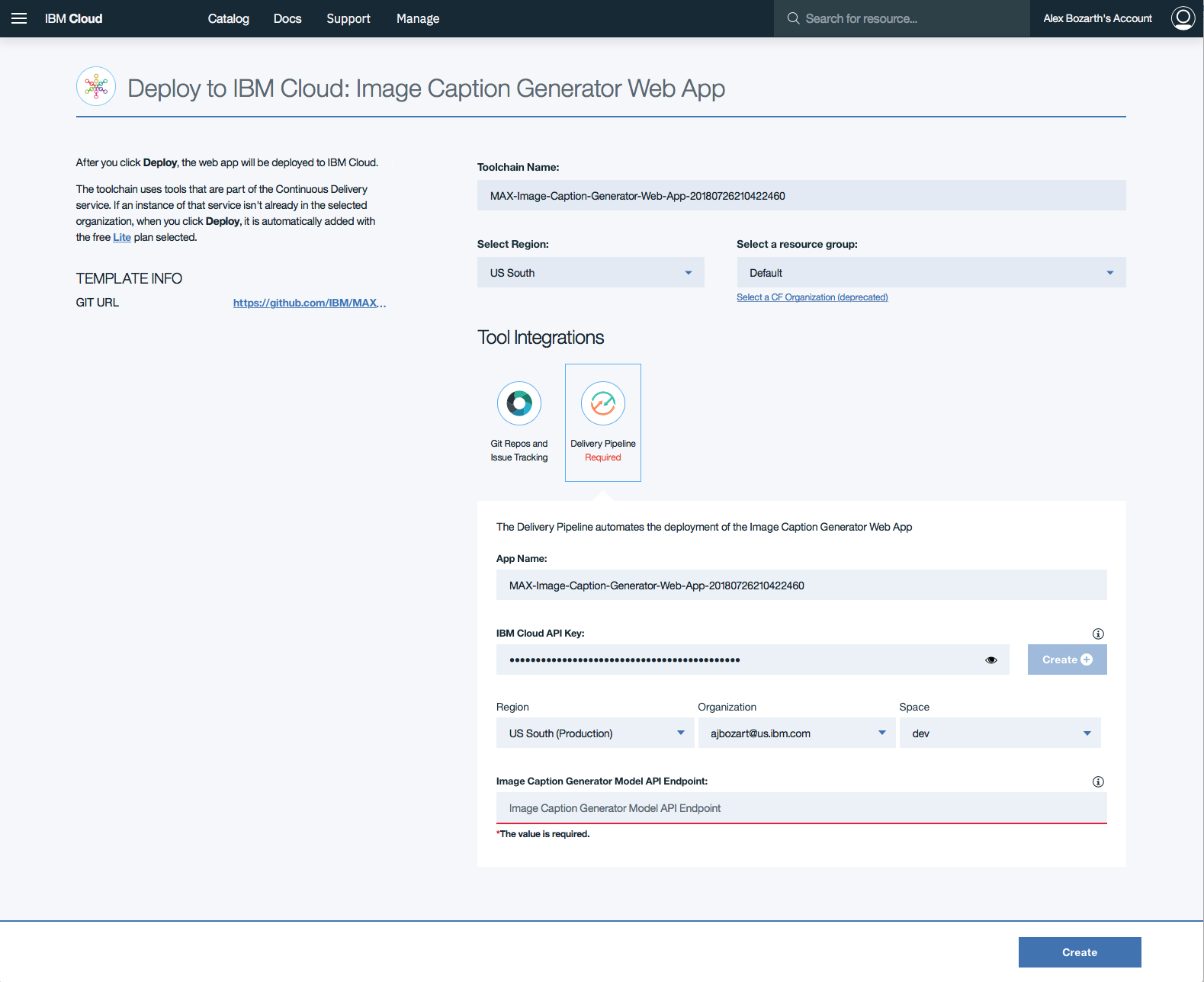
Una vez que se genera la clave API, las secciones de la Region , Organization y el formulario de Space poblarán. Complete la sección Image Caption Generator Model API Endpoint con el punto final implementado arriba, luego haga clic en Create .
El formato para esta entrada debe ser
http://170.0.0.1:5000
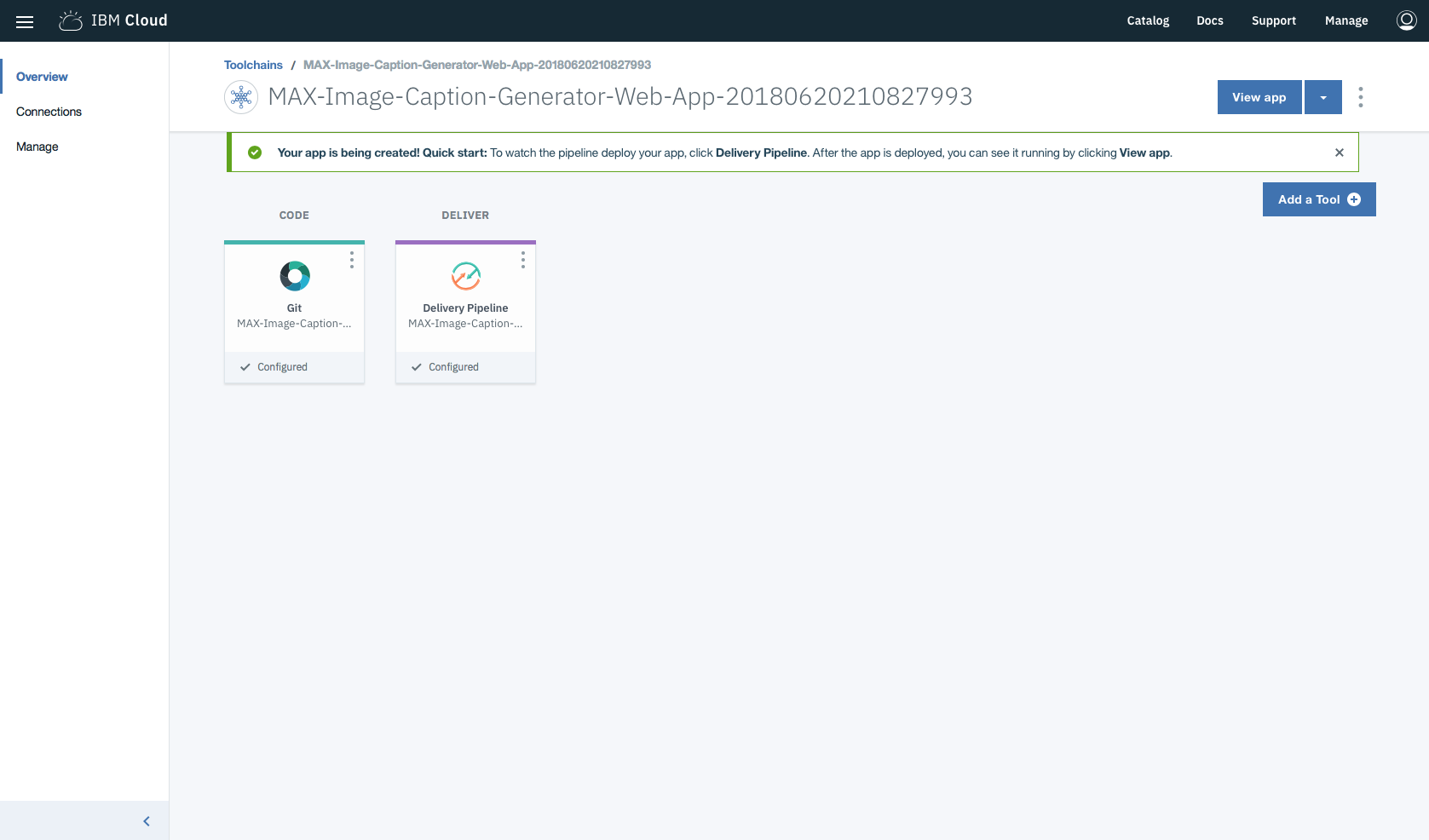
En las cadenas de herramientas, haga clic en Delivery Pipeline para ver mientras se implementa la aplicación. Una vez implementado, la aplicación se puede ver haciendo clic en View app .
También puede implementar el modelo y la aplicación web en Kubernetes utilizando las últimas imágenes de Docker en Quay.
En su clúster Kubernetes, ejecute los siguientes comandos:
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator/master/max-image-caption-generator.yaml
kubectl apply -f https://raw.githubusercontent.com/IBM/MAX-Image-Caption-Generator-Web-App/master/max-image-caption-generator-web-app.yaml La aplicación web estará disponible en el puerto 8088 de su clúster. El modelo solo estará disponible internamente, pero se puede acceder externamente a través de NodePort .
Nota: Para implementar la aplicación web en IBM Cloud, se recomienda seguir las instrucciones de implementación en IBM Cloud anteriores en lugar de implementar con el servicio IBM Cloud Kubernetes.
NOTA: Estos pasos solo se necesitan cuando se ejecutan localmente en lugar de usar el botón
Deploy to IBM Cloud.
Nota: El conjunto de instrucciones en esta sección es una versión modificada de la que se encuentra en la página del proyecto del generador de subtítulos de imagen
Para ejecutar la imagen Docker, que inicia automáticamente la API de servicio de modelo, ejecute:
docker run -it -p 5000:5000 quay.io/codait/max-image-caption-generator
Esto extraerá una imagen preconstruida del muelle (o usará una imagen existente si ya está almacenada en caché localmente) y la ejecutará. Si prefiere construir el modelo localmente, puede seguir los pasos en el modelo ReadMe.
Tenga en cuenta que actualmente esta imagen de Docker es solo CPU (agregaremos soporte para imágenes de GPU más adelante).
El servidor API genera automáticamente una página de documentación de Swagger interactiva. Vaya a http://localhost:5000 para cargarlo. A partir de ahí, puede explorar la API y también crear solicitudes de prueba.
Use el punto final model/predict para cargar un archivo de prueba y obtener subtítulos para la imagen de la API.
La carpeta de muestras de modelo contiene algunas imágenes que puede usar para probar la API, o puede usar las suyas.
También puede probarlo en la línea de comando, por ejemplo:
curl -F " image=@path/to/image.jpg " -X POST http://localhost:5000/model/predict{
"status" : " ok " ,
"predictions" : [
{
"index" : " 0 " ,
"caption" : " a man riding a wave on top of a surfboard . " ,
"probability" : 0.038827644239537
},
{
"index" : " 1 " ,
"caption" : " a person riding a surf board on a wave " ,
"probability" : 0.017933410519265
},
{
"index" : " 2 " ,
"caption" : " a man riding a wave on a surfboard in the ocean . " ,
"probability" : 0.0056628732021868
}
]
}Clone El repositorio de aplicaciones web del generador de subtítulos de imagen localmente ejecutando el siguiente comando:
git clone https://github.com/IBM/MAX-Image-Caption-Generator-Web-App
NOTA: Es posible que deba
cd ..Fuera del directorio de Generator Max-Image-Generator primero
Luego cambie el directorio al repositorio local
cd MAX-Image-Caption-Generator-Web-App
Antes de ejecutar esta aplicación web, debe instalar sus dependencias:
pip install -r requirements.txt
Luego inicia la aplicación web ejecutando:
python app.py
Una vez que haya terminado de procesar las imágenes predeterminadas (<1 minuto), puede acceder a la aplicación web en: http://localhost:8088
El punto final del generador de título de imagen debe estar disponible en http://localhost:5000 para que la aplicación web comience correctamente.
Si desea usar un puerto diferente o está ejecutando el punto final ML en una ubicación diferente, puede cambiarlos con opciones de línea de comandos:
python app.py --port=[new port] --ml-endpoint=[endpoint url including protocol and port]
Para ejecutar la aplicación web con Docker, los contenedores que ejecutan el servidor web y el punto final REST necesita compartir la misma pila de red. Esto se hace en los siguientes pasos:
Modifique el comando que ejecuta el punto final REST del generador de subtítulos de imagen para asignar un puerto adicional en el contenedor a un puerto en la máquina host. En el ejemplo a continuación se asigna al puerto 8088 en el host, pero también se pueden usar otros puertos.
docker run -it -p 5000:5000 -p 8088:8088 --name max-image-caption-generator quay.io/codait/max-image-caption-generator
Cree la imagen de la aplicación web ejecutando:
docker build -t max-image-caption-generator-web-app .
Ejecute el contenedor de la aplicación web usando:
docker run --net='container:max-image-caption-generator' -it max-image-caption-generator-web-app
También puede implementar la aplicación web con la última imagen de Docker disponible en Quay.io ejecutando:
docker run --net='container:max-image-caption-generator' -it quay.io/codait/max-image-caption-generator-web-app
Esto utilizará el contenedor Docker modelo que se ejecuta arriba y se puede ejecutar sin clonar el repositorio de la aplicación web localmente.
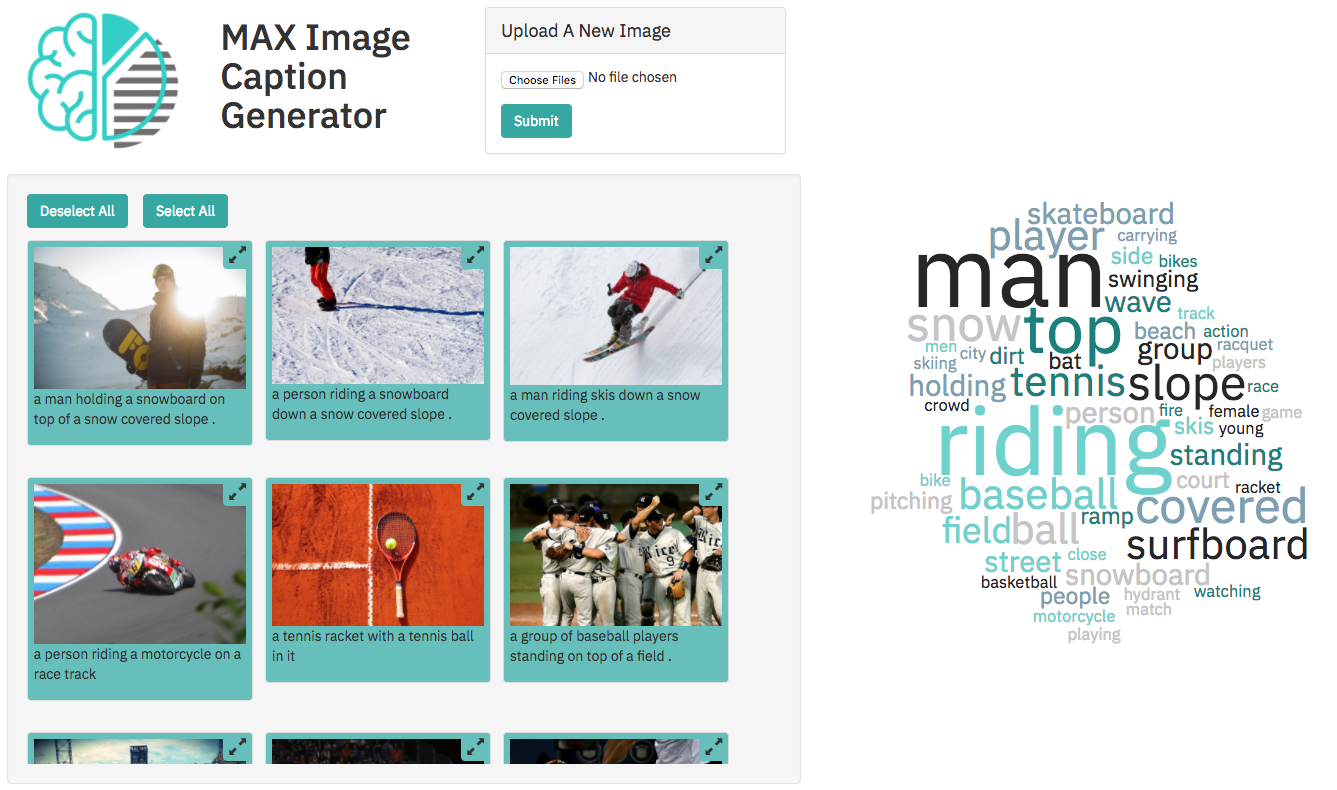
Hay una gran cantidad de imágenes cargadas de usuario en una aplicación web larga y ejecutada
Al ejecutar la aplicación web en
http://localhost:8088una página de administrador está disponible enhttp://localhost:8088/cleanupque permite al usuario eliminar todos los archivos cargados del usuario del servidor.[Nota: esto elimina todas las imágenes cargadas por el usuario]
Este patrón de código tiene licencia bajo la licencia de software Apache, versión 2. Los objetos de código de terceros separados invocados dentro de este patrón de código tienen licencia por sus respectivos proveedores de conformidad con sus propias licencias separadas. Las contribuciones están sujetas al Certificado de origen del desarrollador, la versión 1.1 (DCO) y la licencia de software Apache, versión 2.
Preguntas frecuentes de Licencia de software de Apache (ASL)


