intertext
0.1.0
该项目是在耶鲁数字人文实验室的前阶段开发的。现在是耶鲁图书馆的计算方法和数据部门的一部分,该实验室不再包括该项目的工作范围。因此,它将不会收到进一步的更新。
在纯文本或XML文档的集合中检测和可视化文本重复使用。
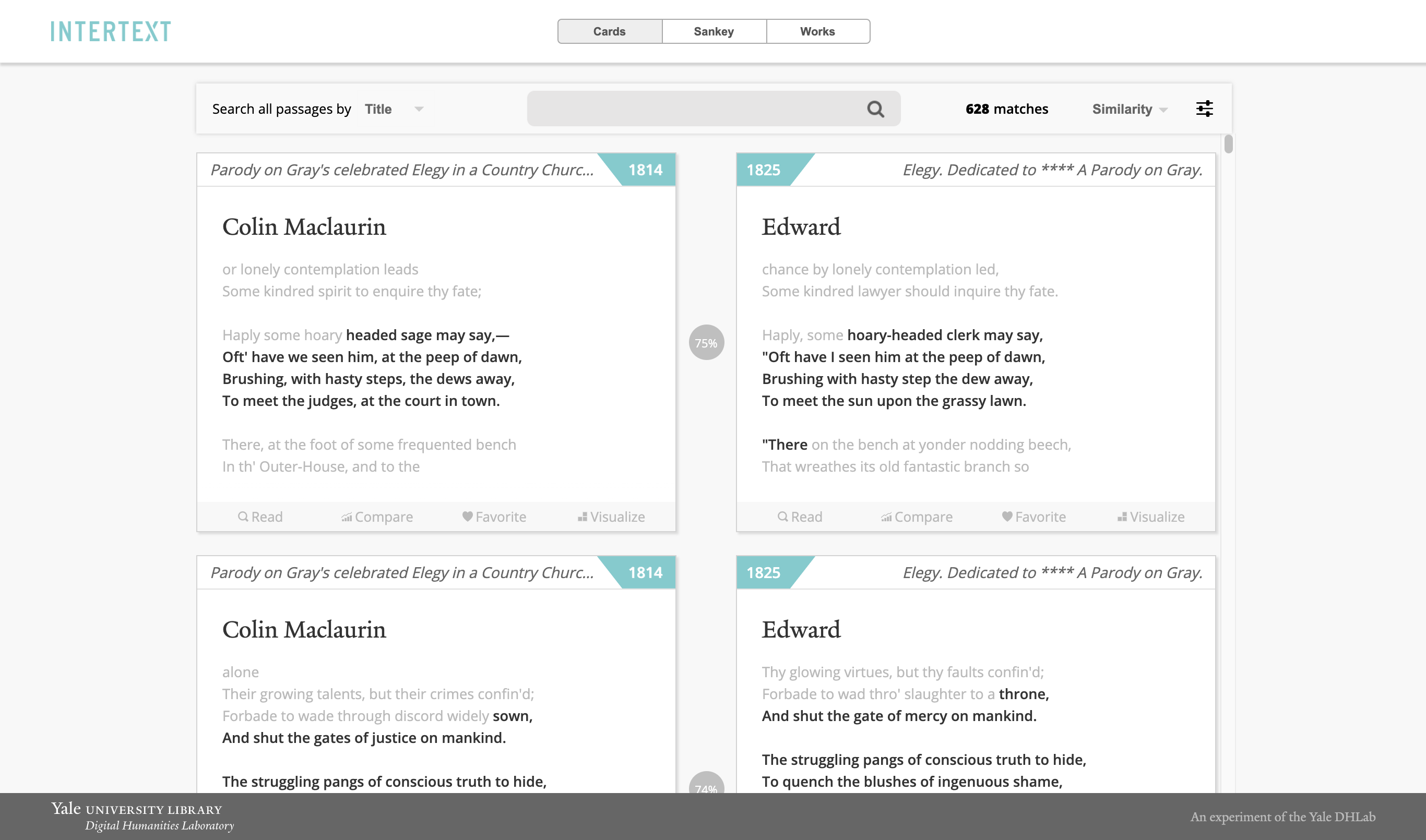
互文使用机器学习和交互式可视化来识别和显示文本集合中的互文模式。文本处理基于Minhashing矢量化字符串,Web查看器基于交互式反应组件。 [演示]
要安装互文,请在下面运行以下步骤:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000然后打开Web浏览器http://localhost:8000/output ,您会看到引擎发现的任何互文!
为了启用CUDA加速度,我们建议在安装模块时使用以下步骤:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip要指示匹配文本的作者和标题,应该将标志传递到元数据文件到intertext命令,例如
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "元数据文件应为JSON文件,具有以下格式:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
}如果您的文本文档可以在另一个网站上读取,则可以在元数据JSON文件中的每个文件中添加一个url属性(请参见上面的示例)。
如果您的文档是XML文件,并且您想在阅读环境中深入链接到特定页面,则可以使用--xml_page_tag标志来指定标签的标签,其中确定了页面断路。此外,您应该在元数据文件中的给定文件的url属性中包含$PAGE_ID ,例如
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
}如果您的页面ID在--xml_page_tag标签中的属性中指定,则可以使用--xml_page_attr标志指定相关属性。


