intertext
0.1.0
Este projeto foi desenvolvido sob uma fase anterior do Yale Digital Humanities Lab. Agora, parte do departamento de dados e do Departamento de Dados da Biblioteca de Yale, o laboratório não inclui mais esse projeto em seu escopo de trabalho. Como tal, não receberá mais atualizações.
Detecte e visualize a reutilização de texto dentro de coleções de documentos de texto simples ou XML.
A Intertext usa o aprendizado de máquina e as visualizações interativas para identificar e exibir padrões intertextuais nas coleções de texto. O processamento de texto é baseado em seqüências vetorizadas da mina e o visualizador da web é baseado em componentes de reação interativa. [Demo]
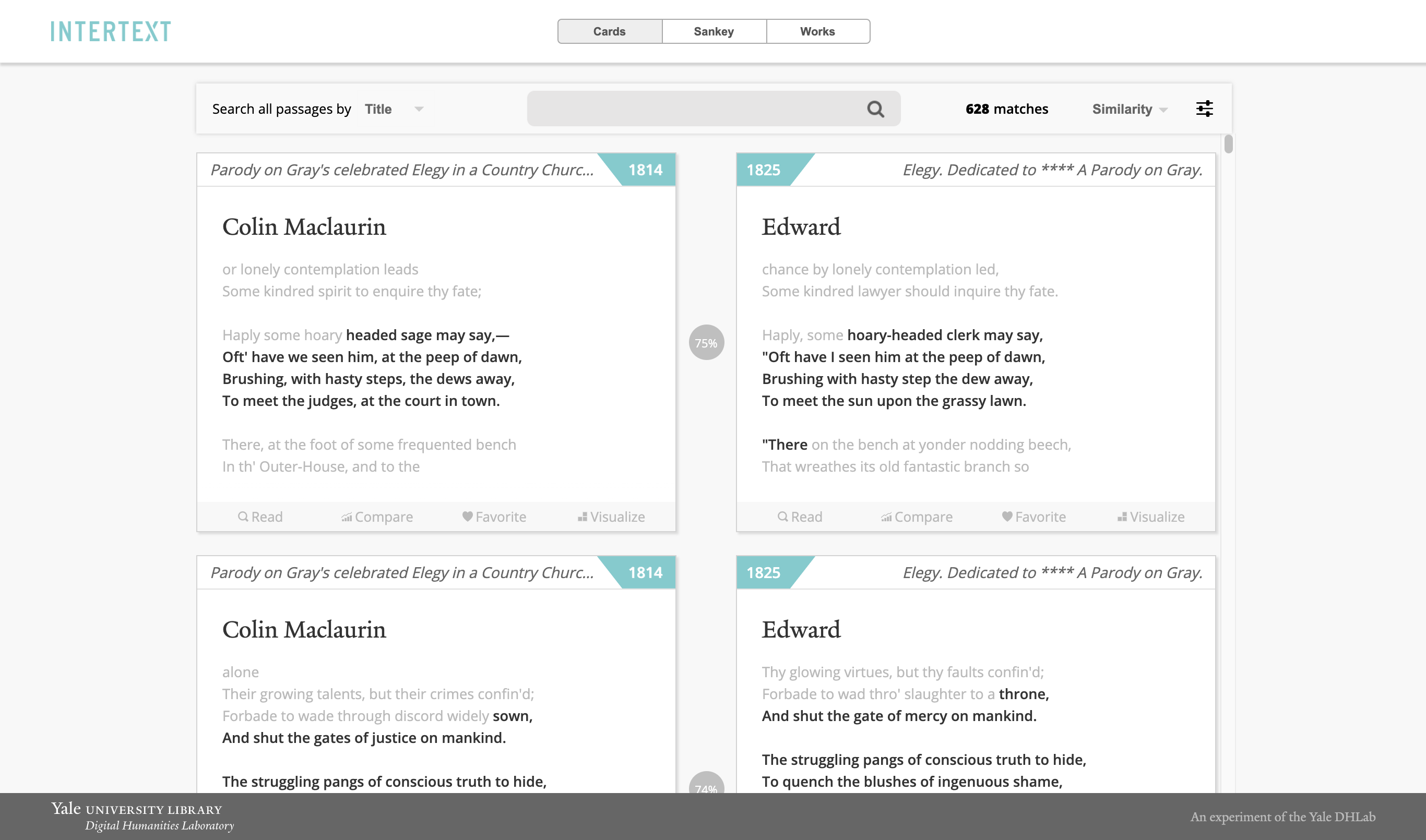
Para instalar o Intertext, execute as etapas abaixo:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000 Em seguida, abra um navegador da web para http://localhost:8000/output e você verá quaisquer intertextualidades que o mecanismo seja descoberto!
Para ativar a aceleração do CUDA, recomendamos o uso das etapas a seguir ao instalar o módulo:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip Para indicar o autor e o título de textos correspondentes, deve -se passar a bandeira para um arquivo de metadados para o comando intertext , por exemplo
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "Os arquivos de metadados devem ser arquivos JSON com o seguinte formato:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
} Se seus documentos de texto puderem ser lidos em outro site, você poderá adicionar um atributo url a cada um de seus arquivos no seu arquivo JSON de metadados (veja o exemplo acima).
Se seus documentos forem arquivos XML e você gostaria de deeplink para páginas específicas em um ambiente de leitura, você pode usar o sinalizador --xml_page_tag para designar a tag dentro da qual as quebras de página são identificadas. Além disso, você deve incluir $PAGE_ID no atributo url para o arquivo especificado em seu arquivo de metadados, por exemplo
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
} Se os IDs da sua página estiverem especificados em um atributo na tag --xml_page_tag , você poderá especificar o atributo relevante usando o sinalizador --xml_page_attr .


