intertext
0.1.0
Este proyecto fue desarrollado bajo una fase anterior del Laboratorio de Humanidades Digitales de Yale. Ahora parte del departamento de métodos y datos de computación de la Biblioteca de Yale, el laboratorio ya no incluye este proyecto en su alcance de trabajo. Como tal, no recibirá más actualizaciones.
Detectar y visualizar la reutilización del texto dentro de las colecciones de texto sin formato o documentos XML.
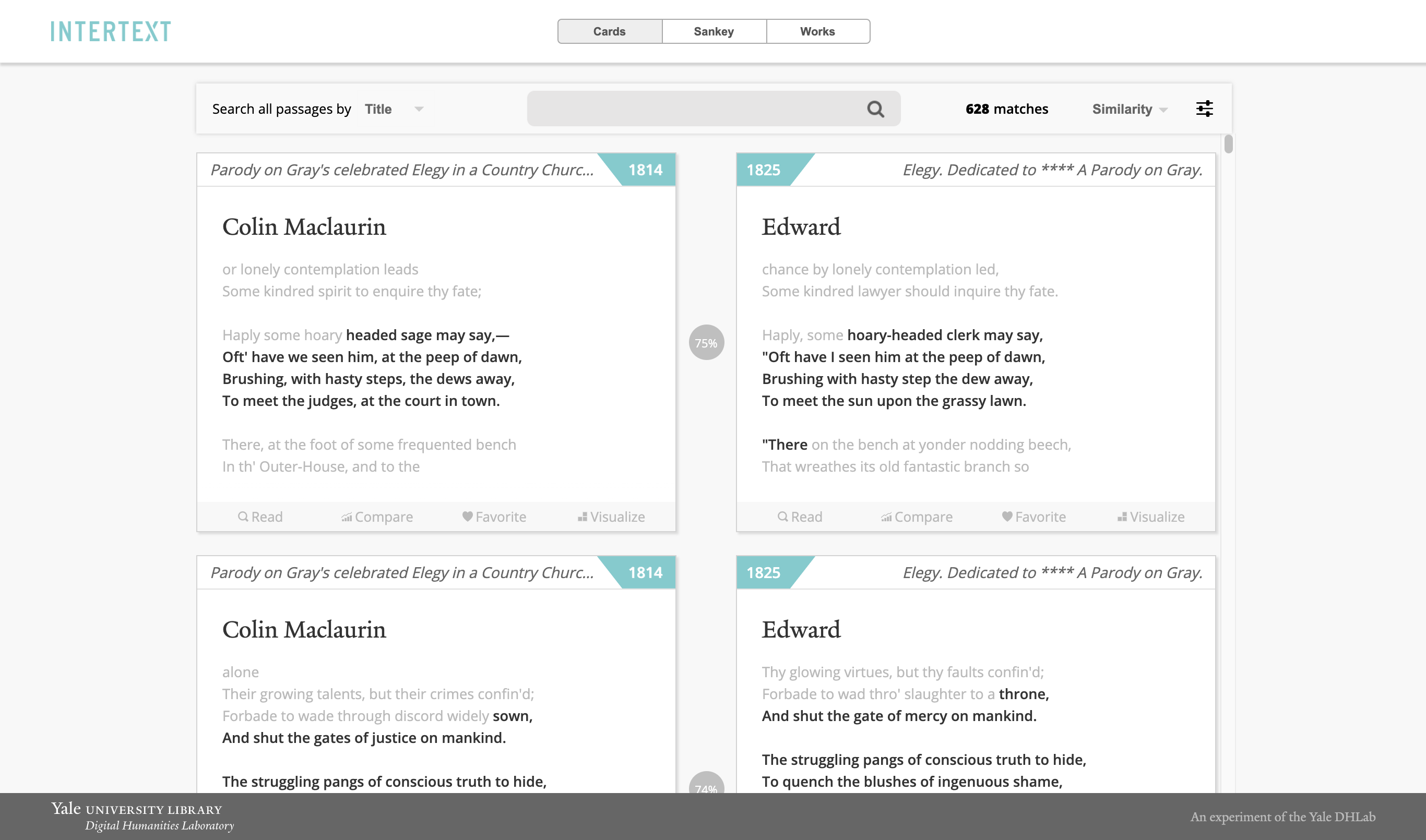
Intertext utiliza aprendizaje automático y visualizaciones interactivas para identificar y mostrar patrones intertextuales en las colecciones de texto. El procesamiento de texto se basa en cadenas vectorizadas de minhashing y el visor web se basa en componentes reactos interactivos. [Manifestación]
Para instalar intertext, ejecute los pasos a continuación:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000 Luego abra un navegador web a http://localhost:8000/output y verá cualquier intertextualidad que el motor descubrió.
Para habilitar la aceleración de CUDA, recomendamos usar los siguientes pasos al instalar el módulo:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip Para indicar el autor y el título de textos coincidentes, uno debe pasar la bandera a un archivo de metadatos al comando intertext , por ejemplo
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "Los archivos de metadatos deben ser archivos JSON con el siguiente formato:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
} Si sus documentos de texto se pueden leer en otro sitio web, puede agregar un atributo url a cada uno de sus archivos dentro de su archivo JSON de metadatos (consulte el ejemplo anterior).
Si sus documentos son archivos XML y desea obtener un enlace profundo en páginas específicas dentro de un entorno de lectura, puede usar el indicador --xml_page_tag para designar la etiqueta dentro de la cual se identifican los saltos de página. Además, debe incluir $PAGE_ID en el atributo url para el archivo dado dentro de su archivo de metadatos, por ejemplo,
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
} Si sus ID de página se especifican dentro de un atributo en la etiqueta --xml_page_tag , puede especificar el atributo relevante usando el indicador --xml_page_attr .


