intertext
0.1.0
โครงการนี้ได้รับการพัฒนาภายใต้ขั้นตอนก่อนหน้าของห้องปฏิบัติการ Humanities Yale Digital ตอนนี้เป็นส่วนหนึ่งของวิธีการคำนวณและแผนกข้อมูลของ Library Library ห้องปฏิบัติการไม่รวมโครงการนี้ไว้ในขอบเขตการทำงานอีกต่อไป เช่นนี้จะไม่ได้รับการอัปเดตเพิ่มเติม
ตรวจจับและแสดงภาพการใช้ข้อความซ้ำภายในคอลเลกชันของข้อความธรรมดาหรือเอกสาร XML
Intertext ใช้การเรียนรู้ของเครื่องและการสร้างภาพข้อมูลแบบโต้ตอบเพื่อระบุและแสดงรูปแบบ intertextual ในคอลเลกชันข้อความ การประมวลผลข้อความขึ้นอยู่กับสตริง minhashing vectorized และโปรแกรมดูเว็บจะขึ้นอยู่กับส่วนประกอบปฏิกิริยาแบบโต้ตอบ [สาธิต]
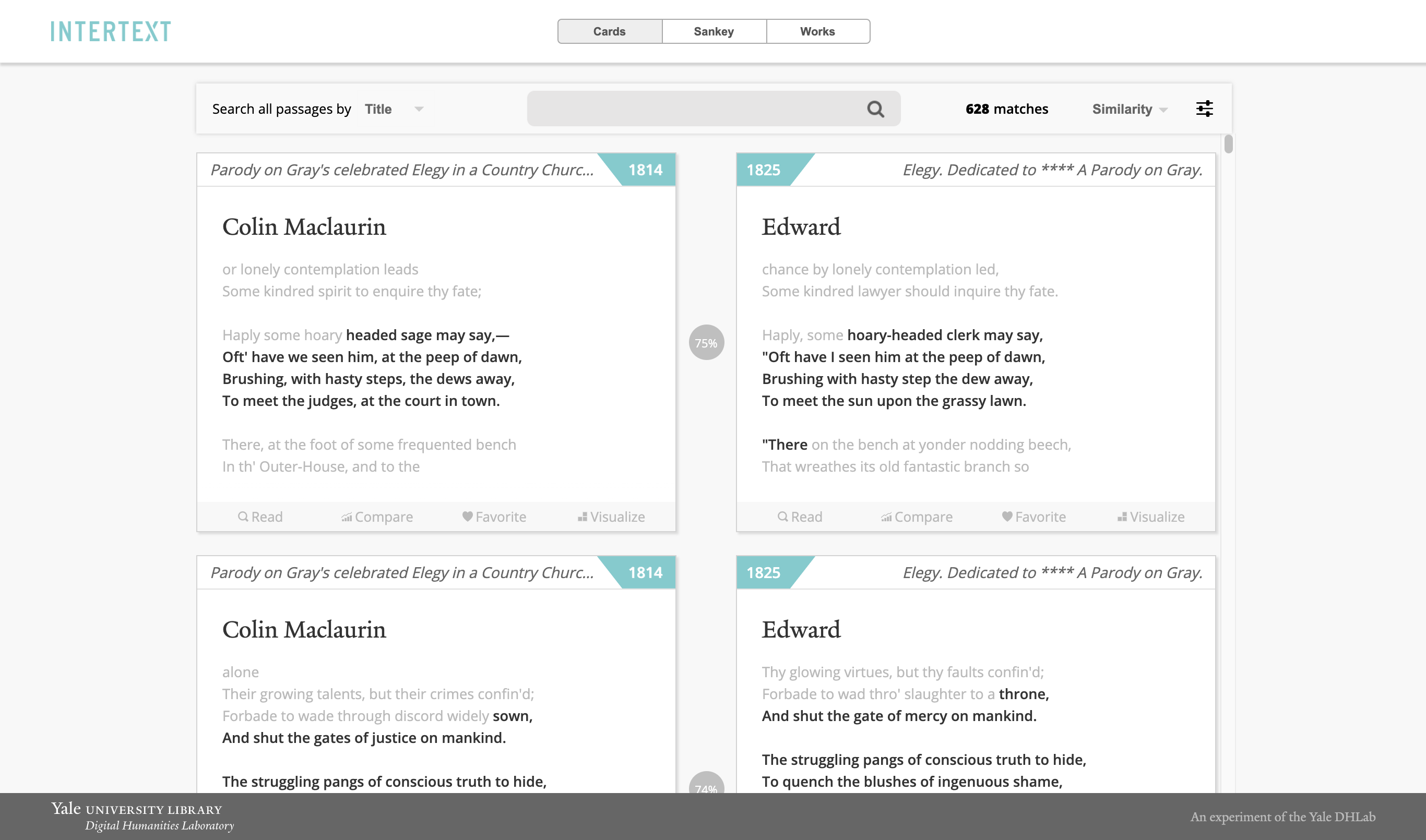
ในการติดตั้ง intertext ให้เรียกใช้ขั้นตอนด้านล่าง:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000 จากนั้นเปิดเว็บเบราว์เซอร์ไปที่ http://localhost:8000/output แล้วคุณจะเห็น intertextualities ใด ๆ ที่เครื่องยนต์ค้นพบ!
ในการเปิดใช้งานการเร่งความเร็วของ CUDA เราขอแนะนำให้ใช้ขั้นตอนต่อไปนี้เมื่อติดตั้งโมดูล:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip เพื่อระบุผู้แต่งและชื่อเรื่องของข้อความที่ตรงกันหนึ่งควรส่งธงไปยังไฟล์ข้อมูลเมตาไปยังคำสั่ง intertext เช่น
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "ไฟล์ข้อมูลเมตาควรเป็นไฟล์ JSON ที่มีรูปแบบต่อไปนี้:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
} หากเอกสารข้อความของคุณสามารถอ่านได้ในเว็บไซต์อื่นคุณสามารถเพิ่มแอตทริบิวต์ url ให้กับแต่ละไฟล์ของคุณภายในไฟล์ข้อมูลเมตาของคุณ (ดูตัวอย่างด้านบน)
หากเอกสารของคุณเป็นไฟล์ XML และคุณต้องการที่จะ deeplink ไปยังหน้าเฉพาะภายในสภาพแวดล้อมการอ่านคุณสามารถใช้ธง --xml_page_tag เพื่อกำหนดแท็กภายในที่ระบุตัวแบ่งหน้า นอกจากนี้คุณควรรวม $PAGE_ID ในแอตทริบิวต์ url สำหรับไฟล์ที่กำหนดภายในไฟล์ข้อมูลเมตาของคุณเช่น
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
} หากระบุรหัสหน้าของคุณภายในแอตทริบิวต์ในแท็ก --xml_page_tag คุณสามารถระบุแอตทริบิวต์ที่เกี่ยวข้องโดยใช้ธง --xml_page_attr


