intertext
0.1.0
Этот проект был разработан под предыдущей фазой Йельской цифровой гуманитарной лаборатории. Теперь часть вычислительной библиотеки Йельской библиотеки, лаборатория, больше не включает этот проект в свой объем работы. Таким образом, он не получит дальнейших обновлений.
Обнаружение и визуализацию повторного использования текста в коллекциях простого текста или документов XML.
Intertext использует машинное обучение и интерактивные визуализации для идентификации и отображения интертекстуальных шаблонов в текстовых коллекциях. Обработка текста основана на векторизованных строках Minhashing, а веб -просмотрщик основан на интерактивных компонентах React. [Демо]
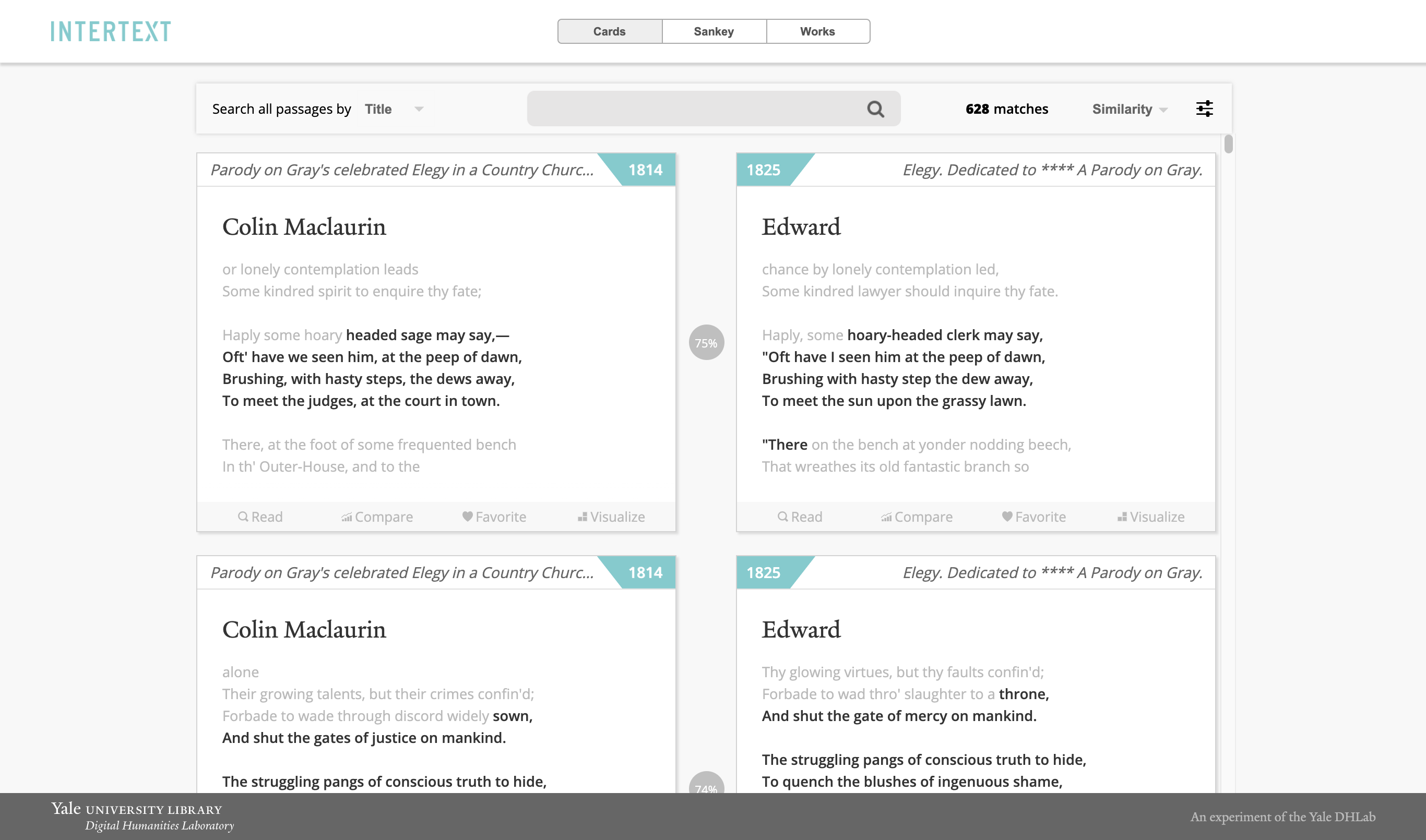
Чтобы установить интертекст, запустите шаги ниже:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000 Затем откройте веб -браузер на http://localhost:8000/output , и вы увидите любую интертекстуальность, которую обнаружил двигатель!
Чтобы включить ускорение CUDA, мы рекомендуем использовать следующие шаги при установке модуля:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip Чтобы указать автора и название соответствующих текстов, следует передать флаг в файл метаданных в команду intertext , например,
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "Файлы метаданных должны быть файлами json со следующим форматом:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
} Если ваши текстовые документы можно прочитать на другом веб -сайте, вы можете добавить атрибут url в каждый из ваших файлов в вашем файле JSON Metadata (см. Пример выше).
Если ваши документы являются файлами XML, и вы хотите DeepLink на определенные страницы в среде чтения, вы можете использовать флаг --xml_page_tag для обозначения тега, в котором идентифицируются разрывы страницы. Кроме того, вы должны включить $PAGE_ID в атрибут url для данного файла в вашем файле метаданных, например,
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
} Если идентификаторы вашей страницы указаны в атрибуте в теге --xml_page_tag , вы можете указать соответствующий атрибут, используя флаг --xml_page_attr .


