intertext
0.1.0
Dieses Projekt wurde in einer früheren Phase des Yale Digital Humanities Labors entwickelt. Das Labor ist jetzt ein Teil der Computermethoden und Datenabteilung der Yale Library und enthält dieses Projekt nicht mehr in seinen Arbeitsumfang. Daher wird es keine weiteren Aktualisierungen erhalten.
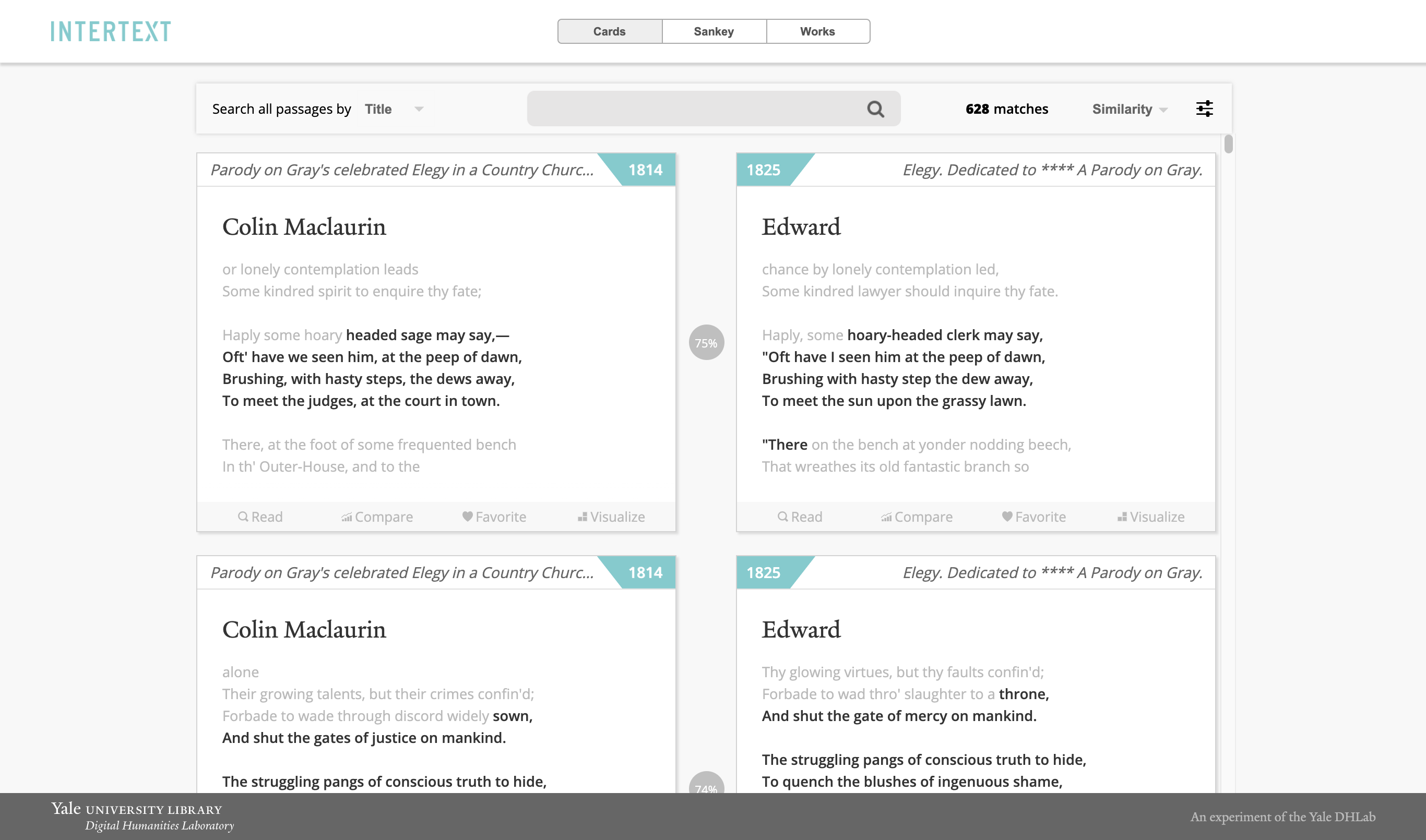
Erkennen und visualisieren Sie die Wiederverwendung von Text in Sammlungen von Klartext oder XML -Dokumenten.
Intertext verwendet maschinelles Lernen und interaktive Visualisierungen, um intertextuelle Muster in Textsammlungen zu identifizieren und anzuzeigen. Die Textverarbeitung basiert auf Minhashing -vektorisierten Zeichenfolgen und der Webbacher basiert auf interaktiven React -Komponenten. [Demo]
Führen Sie die folgenden Schritte aus: Aus: So können Sie den Intertext installieren:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000 Öffnen Sie dann einen Webbrowser für http://localhost:8000/output und Sie werden alle Intertextualität sehen, die die Engine entdeckt hat!
Um die CUDA -Beschleunigung zu aktivieren, empfehlen wir die Verwendung der folgenden Schritte bei der Installation des Moduls:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip Um den Autor und den Titel der passenden Texte anzuzeigen, sollte man das Flag an eine Metadatendatei an den Befehl intertext , z.
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "Metadatendateien sollten JSON -Dateien mit dem folgenden Format sein:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
} Wenn Ihre Textdokumente auf einer anderen Website gelesen werden können, können Sie jeder Ihrer Dateien in Ihrer Metadaten -JSON -Datei ein url -Attribut hinzufügen (siehe Beispiel oben).
Wenn es sich bei Ihren Dokumenten um XML -Dateien handelt und Sie in einer Leseumgebung bestimmte Seiten in bestimmte Seiten tief verlinken möchten, können Sie das Flag --xml_page_tag verwenden, um das Tag zu bestimmen, in dem Seitenpausen identifiziert werden. Zusätzlich sollten Sie $PAGE_ID in das url -Attribut für die angegebene Datei in Ihrer Metadatendatei z.
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
} Wenn Ihre Seiten -IDs in einem Attribut im Tag --xml_page_tag angegeben sind, können Sie das relevante Attribut mit dem Flag --xml_page_attr angeben.


