intertext
0.1.0
Ce projet a été développé dans une phase précédente du Yale Digital Humanities Lab. Désormais partie du service de calcul et du service de données de la bibliothèque de Yale, le laboratoire n'inclut plus ce projet dans sa portée de travail. En tant que tel, il ne recevra aucune autre mise à jour.
Détecter et visualiser la réutilisation du texte dans les collections de documents de texte brut ou de XML.
Intertext utilise l'apprentissage automatique et les visualisations interactives pour identifier et afficher des modèles intertextuels dans les collections de texte. Le traitement de texte est basé sur des chaînes vectorisées de minhash et la visionneuse Web est basée sur des composants de réaction interactifs. [Démo]
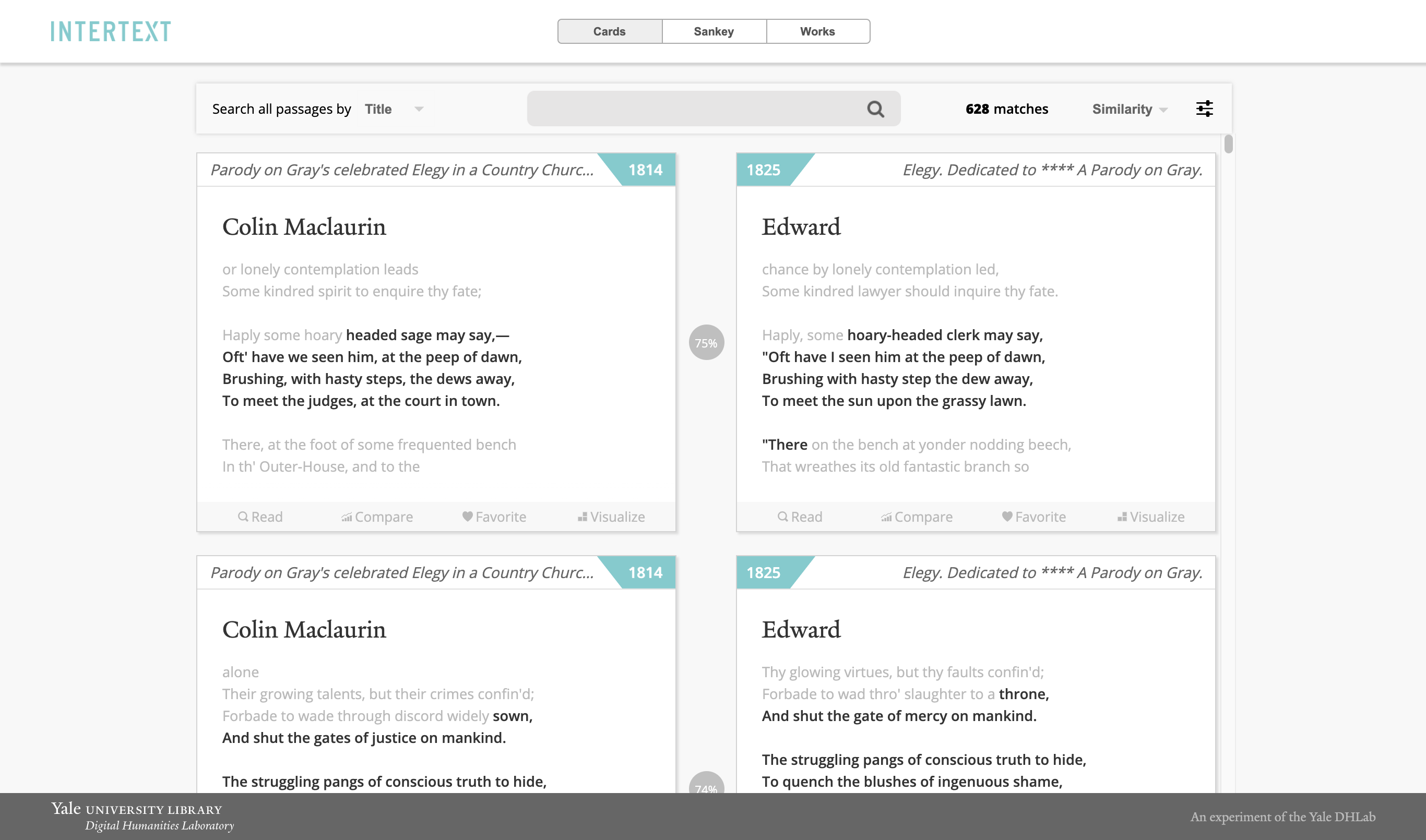
Pour installer InterText, exécutez les étapes ci-dessous:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip # search for intertextuality in some documents
python intertext/intertext.py --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json " --verbose --update_client
# serve output
python -m http.server 8000 Ouvrez ensuite un navigateur Web à http://localhost:8000/output et vous verrez toutes les intertextualités découvertes par le moteur!
Pour activer l'accélération CUDA, nous vous recommandons d'utiliser les étapes suivantes lors de l'installation du module:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip Pour indiquer l'auteur et le titre de textes correspondants, il faut transmettre le drapeau à un fichier de métadonnées à la commande intertext , par exemple
intertext --infiles " sample_data/texts/*.txt " --metadata " sample_data/metadata.json "Les fichiers de métadonnées doivent être des fichiers JSON avec le format suivant:
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml "
}
} Si vos documents texte peuvent être lus sur un autre site Web, vous pouvez ajouter un attribut url à chacun de vos fichiers dans votre fichier JSON de métadonnées (voir l'exemple ci-dessus).
Si vos documents sont des fichiers XML et que vous souhaitez DeepLink sur des pages spécifiques dans un environnement de lecture, vous pouvez utiliser l'indicateur --xml_page_tag pour désigner la balise dans laquelle les pauses de page sont identifiées. De plus, vous devez inclure $PAGE_ID dans l'attribut url pour le fichier donné dans votre fichier de métadonnées, par exemple
{
" a.xml " : {
" author " : " Author A " ,
" title " : " Title A " ,
" year " : 1751,
" url " : " https://google.com?text=a.xml&page= $PAGE_ID "
},
" b.xml " : {
" author " : " Author B " ,
" title " : " Title B " ,
" year " : 1753,
" url " : " https://google.com?text=b.xml&page= $PAGE_ID "
}
} Si vos ID de page sont spécifiés dans un attribut dans la balise --xml_page_tag , vous pouvez spécifier l'attribut pertinent à l'aide de l'indicateur --xml_page_attr .


