samantha_ia
1.0.0
萨曼莎(Samantha)只是开源文本生成人工智能模型的简单接口助理,该模型是根据开放科学原理(开放方法,开源,开放数据,开放式数据,开放式访问,开放式同行评审和开放教育资源)和MIT使用许可证(无GPU)。该程序在本地运行LLM,免费和无限地运行,而无需Internet连接,除了下载GGEF模型(GGGUF代表GPT生成的统一格式),或者在执行由模型创建的代码(GE下载数据集以下载数据集以进行数据分析的代码)所需的情况下需要。它的目标是使人们对使用AI的使用进行民主化,并证明,使用适当的技术,即使是小型模型也能够产生类似于大型响应的响应。她的任务是帮助探索(实际)开放AI模型的界限。
什么是开源AI(opensource.org)
LLM尺寸重要吗? (加里解释)
人工智能论文(arxiv.org)
♀️萨曼莎(Samantha)是为了帮助行使公共行政的社会和机构控制的,考虑到人们令人担忧的当前情况是增加公民对控制机构的信任的损失。它的功能允许任何有兴趣探索开源人工智能模型(尤其是Python程序员和数据科学家)的人使用它。该项目起源于MPC-ES团队开发一个系统,该系统将允许了解LLM模型生成代币的过程。
♾️ The system allows the sequential loading of a list of prompts (prompt chaining) and models (model chaining), one model at a time to save memory, as well as the adjustment of their hyperparameters, allowing the response generated by the previous model to be feedbacked and analyzed by the subsequent model to generate the next response ( Feedback Loop feature), in an unlimited number of interaction cycles between LLMs without human intervention.模型可以与立即模型提供的答案进行交互,因此每个新响应都取代了上一个。您还可以仅使用一个模型,并在无限数量的文本生成周期中与先前响应进行交互。利用您的想象力结合模型,提示和功能!
该视频显示了通过链接模型和提示使用Samantha的副本和粘贴LLM功能提示的模型之间相互作用的示例。 Microsoft Phi 3.5和Google Gemma 2模型(由Bartowski)的量化版本挑战,要回答有关Meta Llama 3.1模型(由NousResearch)创建的有关人性的问题。响应还通过元模型评估。

情报挑战:Gemma 2 vs Phi 3.5与Llama 3.1担任法官
?一些没有使用萨曼莎(Samantha)的响应反馈循环功能的固定示例:
(model_1)响应(提示_1)x响应数:用于通过学习模式功能的确定性和随机行为来分析模型的确定性和随机行为,并通过随机设置(视频)生成多种不同的响应。
(model_1)响应(提示_1,提示_2,提示_n):用相同的模型(提示链)序列地执行倍数指令(视频)。
(model_1,model_2,model_n)响应(提示_1):用于比较模型对同一单个提示的响应(模型链)。可用于比较不同模型以及同一模型的量化版本。
(model_1,model_2,model_n)响应(提示_1,提示_2,提示_n):用于比较模型的响应提示列表,并使用DISCTINCT模型(模型和提示链)执行一系列指令。每个型号都会响应所有提示。反过来,当使用每个模型功能的单个响应时,每个模型仅响应一个特定的提示。
?一些使用Samantha的响应反馈循环功能的固定示例:
(model_1)响应(提示_1)x响应数:用于使用相同模型的固定用户指令改进或补充模型的先前响应,并使用单个模型(视频)模拟2个AIS之间的无尽对话。
(model_1)响应(提示_1,提示_2,提示_n):用于通过倍增用户指令使用相同的模型(提示链)来改善模型的先前响应。每个提示都用于完善或完成先前的响应,并执行取决于先前响应的一系列提示,例如使用增量编码(视频)执行探索性数据分析(EDA)。
(model_1,model_2,model_n)响应(提示_1):用于使用Disctinct模型(模型链)改进上一个模型的响应,并在不同模型之间生成对话框。
(model_1,model_2,model_n)响应(提示_1,提示_2,提示_n):用于使用Disctinct模型(模型和提示链)执行一系列指令和每个模型功能的单个响应。
这些模型和提示序列都可以通过循环功能的数量多次执行。
萨曼莎(Samantha)的封闭序列模板:
([[模型列表] - >响应 - >([用户提示列表] x响应数))x循环数
但是什么是GPT?变压器的视觉介绍(3Blue1brown)
视觉解释(3blue1brown)在变压器中的注意
变压器解释器(PoloClub)
?提示和模型的测序可以通过分馏用户输入指令来产生长时间的响应。每个部分响应都适合模型训练过程中定义的响应长度。
?作为AI模型之间自动自动交流的开源工具,Samantha Interface Assistant旨在探索具有自我完善反馈回路的反向提示工程?该技术可以通过转移到模型来根据用户的初始不准确说明创建最终提示和相应响应的任务来帮助小型大型语言模型(LLM)生成更准确的响应,从而将中间层添加到及时的施工过程中。萨曼莎(Samantha)没有隐藏的系统提示,就像专有型号一样。所有说明均由用户控制。请参阅拟人系统提示。
?得益于从训练文本中提取的概括模式产生的紧急行为,并具有正确的提示和适当的超参数配置,即使是小型模型也可以产生巨大的响应!
人类物种的智能不是基于一个智能的存在,而是基于集体智慧。单独地,我们实际上不是那么聪明或有能力。我们的社会和经济体系是基于拥有各种各样的专业知识和专业知识的各种个人组成的机构。这种庞大的集体智能塑造了我们作为个人的身份,我们每个人都遵循自己的生活道路,成为独特的个人,进而又助长了我们不断扩大的集体智力作为一种物种的一部分。我们认为,人工智能的发展将遵循类似的集体道路。 AI的未来不会由一个单一的,巨大的,全知的人工智能系统组成,该系统需要巨大的能量来训练,运行和维护,而是大量的小型AI系统 - 与他们自己的利基市场和专业相互互动,与彼此互动,与较新的AI系统相互交互,开发了以填补特定利基市场。不断发展的新基础模型:释放自动化模型开发的力量-Sakana AI
?一小步:萨曼莎(Samantha)只是朝着未来的运动,在这个世界中,人工智能不是特权,而是一个在一个世界中,个人可以利用AI来提高其生产力,创造力和决策,而没有障碍,走上民主AI的旅程,使其成为我们日常生活的良好力量的旅程。
?人工智能的工具性质:认识到人工智能的技术垄断是可能的统治工具,而社会不平等的扩展则代表了历史上这个变化点的挑战。在文本生成过程中注意到较小模型的缺陷,有助于将它们与较大专有模型的完美进行比较,从而有助于这种理解。有必要在其适当的地方重新定位事物,并质疑浪漫的还原主义者对人类特征的看法,例如智力(由Pareidolia的心理现象引起的拟人化(拟人化))。因此,必须通过与这种新颖的“单词/令牌计算器”如何工作的教学方法来揭开人工智能的神秘化。当然,市场上人工创造的最初魅力的多巴胺无法承受几百个令牌的产生(令牌是LLM用来理解和生成文本的基本文本构建块的名称。一个令牌可能是整个单词或单词的一部分)。
✏️文本生成注意事项:用户应意识到,AI产生的响应是从对其大语言模型的培训中得出的。 AI用于生成其输出的确切源或过程无法精确引用或识别。 AI产生的内容不是来自特定来源的直接报价或汇编。取而代之的是,它反映了AI神经网络在广泛数据语料库的培训过程中学习和编码的模式,统计关系和知识。响应是基于这种学识渊博的知识表示产生的,而不是从任何特定的原始材料中逐字检索。尽管AI的培训数据可能包括权威来源,但其输出是其自身对学习的关联和概念的综合表达式。
目的:萨曼莎(Samantha)的主要目标是激发他人创建类似(肯定会更好的系统),并教育用户对AI的利用。我们的目标是培养一个开发人员和爱好者社区,他们可以采用知识和工具来进一步创新并为开源AI领域做出贡献。通过这样做,旨在培养协作和共享文化的目的,以确保所有人都能获得AI的好处,无论其技术背景或财务资源如何。人们认为,通过使更多的人能够构建和理解AI应用程序,我们可以通过知情和多样化的观点共同推动进步并应对社会挑战。让我们一起塑造AI是人类积极而包容的力量的未来。
联合国教科文组织的人工智能建议
OECD关于AI的工作,创新,生产力和技能的计划
人力创新成本:尽管该系统旨在赋予用户能力并民主化对AI的访问,但要承认这项技术的道德含义至关重要。强大的AI系统的发展通常依赖于人工劳动的开发,尤其是在数据注释和培训过程中。这可以使现有的不平等现象永久化并创建新形式的数字鸿沟。作为AI的用户,我们有责任意识到这些问题,并倡导行业内更公平的做法。通过支持道德AI发展并促进数据采购中的透明度,我们可以为所有人提供更具包容性和公平的未来。
como funciona o trabalho humano portrásdainteligência人造
AI技术世界的“现代奴隶”
其他来源
在巨人的肩膀上:特别感谢Georgi Gerganov和整个团队在Llama.cpp上工作,以使所有这一切成为可能,以及Andrei Bleten的令人惊叹的Python Bidings for Gerganov C ++图书馆(Llama-Cpp-Python)。
✅开源基金会:基于Llama.cpp / Llama-CPP-Python和Gradio,在MIT许可下,Samantha在标准计算机上运行,即使没有专用的图形处理单元(GPU)。
✅离线功能:萨曼莎(Samantha)独立于Internet运行,仅需要连接到模型文件的初始下载或执行模型创建的代码时需要的连接。这样可以确保您的数据处理需求的隐私和安全性。您的敏感数据不会通过机密协议通过互联网与公司共享。
✅无限制和自由使用:萨曼莎的开源性质允许无限制地使用,而无需任何费用或限制,使任何人,任何时候,任何人都可以使用它。
✅广泛的模型选择:通过访问数千个基础和微调的开源模型,用户可以尝试使用各种AI功能,每个功能都针对不同的任务和应用程序量身定制,从而可以链接最能满足您需求的模型的顺序。
✅复制和粘贴LLM:要尝试一系列gguf模型,只需从任何拥抱的面部存储库中复制其下载链接并在Samantha内部粘贴即可立即按顺序运行它们。
✅ Customizable Parameters: Users have control over model hyperparameters such as context window length ( n_ctx , max_tokens ), token sampling ( temperature , tfs_z , top-k , top-p , min_p , typical_p ), penalties ( presence_penalty , frequency_penalty , repeat_penalty ) and stop words ( stop ), allowing for responses that suit specific requirements, with deterministic or随机行为。
✅随机高参数调整:您可以测试超参数设置的随机组合,并观察它们对模型产生的响应的影响。
✅交互式体验:萨曼莎(Samantha)的链接功能使用户能够通过链接提示和模型来生成无尽的文本,从而促进不同LLM之间的复杂互动而无需人工干预。
✅反馈循环:此功能使您可以捕获模型生成的响应,并将其馈回对话的下一个周期中。
✅提示列表:您可以添加任意数量的提示(由$$$n或n分隔)来控制模型执行的指令序列。可以用预定义的提示序列导入TXT文件。
✅模型列表:您可以选择任何数量的模型,并以任何顺序控制哪个模型响应下一个提示。
✅累积响应:您可以通过将其添加到先前的响应中,以在模型生成下一个响应时考虑每个新响应。重要的是要强调,一组串联响应必须适合模型上下文窗口。
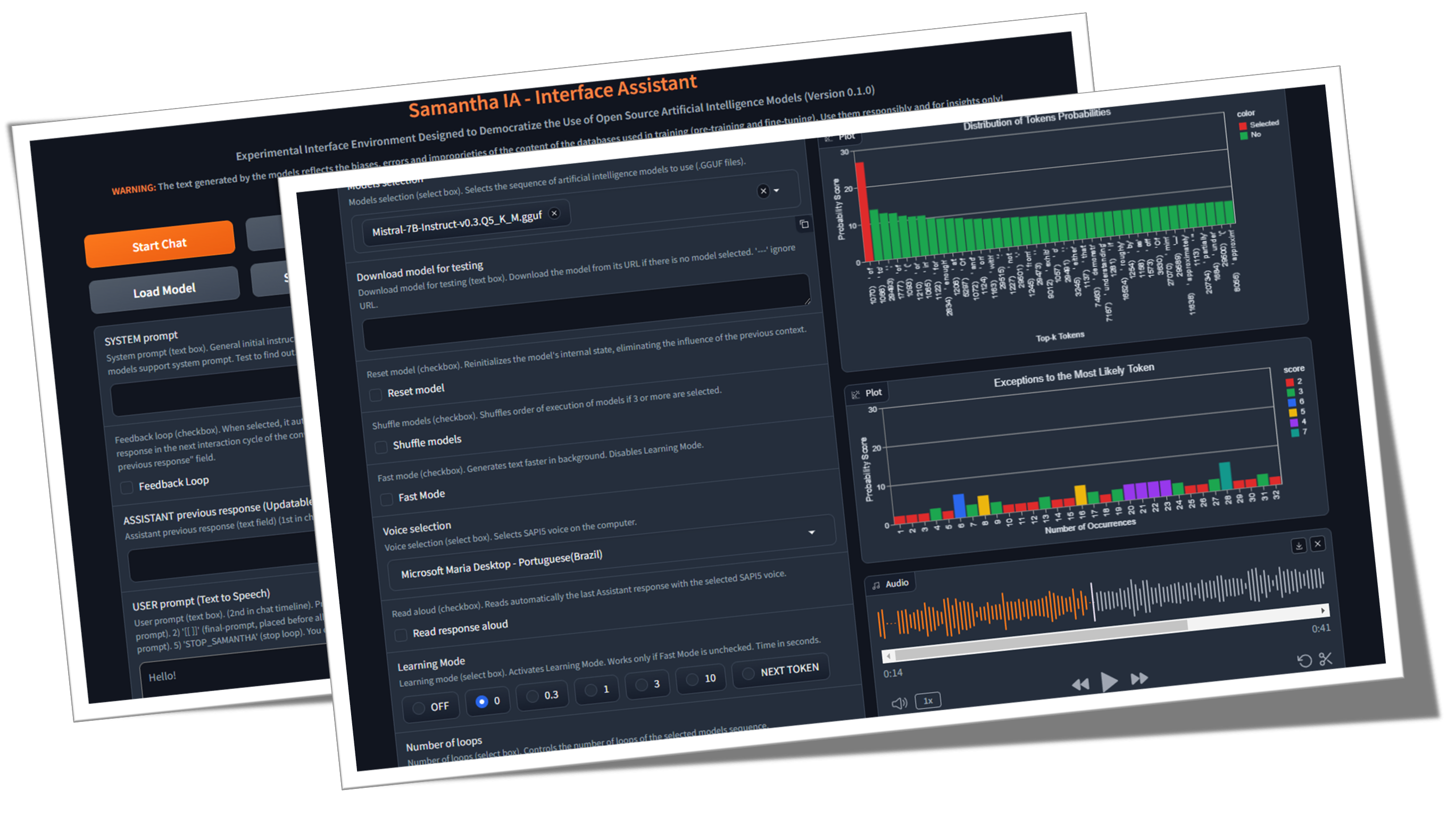
✅学习见解:一种称为学习模式的功能使用户可以观察模型的决策过程,从而提供有关其如何根据其概率分数(逻辑单位或仅逻辑)和超参数设置选择输出代币的见解。还生成了最不可能选择的令牌的列表。
✅语音互动:萨曼莎(Samantha)支持简单的语音命令,其脱机语音到文本vosk(英语和葡萄牙语)以及带有SAPI5声音的文字到语音,使其易于访问且用户友好。
✅音频反馈:该界面为用户提供了可听见的警报,并通过模型向文本生成阶段的开始和结束发出。
✅文档处理:系统可以加载小的PDF和TXT文件。为了方便起见,可以通过TXT文件输入链接用户提示,系统提示和模型的URL列表。
✅通用文本输入:提示插入的字段允许用户有效与系统交互,包括系统提示,先前的模型响应和用户提示,以指导模型的响应。
✅代码集成:从模型响应中自动提取Python代码块,以及在孤立的虚拟环境中预装的Jupyterlab集成开发环境(IDE),使用户能够快速运行生成的代码以立即结果。
✅编辑,复制和运行Python代码:系统允许用户编辑由模型生成的代码,并通过选择CTRL + C复制并单击运行代码按钮来运行它。您还可以从任何地方(例如,来自网页)复制Python代码,并仅通过按COPY PYTHON代码和运行代码按钮(只要使用已安装的Python库)来运行它。
✅代码块编辑:用户可以通过在输出代码中输入#IDE评论,使用CTRL + C选择和复制#ide评论来选择并运行模型生成的Python代码块,并使用jupyterlab虚拟环境中安装的库,并最终单击运行代码按钮;
✅html输出:当终端中打印的文本以外的“”(空字符串)以外,在HTML弹出窗口中显示Python解释器输出。例如,此功能允许无限制地执行脚本,并且仅在满足特定条件时显示结果;
✅自动代码执行:萨曼莎(Samantha)功能可以自动运行模型生成的Python代码。生成的代码由安装在包含多个库(类似智能代理的功能)的虚拟环境中的Python解释器执行。
✅停止条件:如果模型在终端中生成的python代码的自动执行,则停止萨曼莎(Samantha)。您还可以通过创建仅在满足特定条件时仅返回字符串STOP_SAMANTHA函数来强制退出运行循环。
✅增量编码:使用确定性设置,以增量创建Python代码,确保每个部分在继续进行下一个方面。
✅完整访问和控制:通过Python库的生态系统以及模型生成的代码,可以访问计算机文件,允许您读取,创建,更改和删除本地文件,并访问Internet(如果可用)来上传和下载信息和文件。
✅键盘和鼠标自动化:您可以使用pyautogui库在计算机上自动化任务的序列.exe请参阅使用Python .py无聊的东西自动化。
✅ Data Analysis Tools: A suite of data analysis tools like Pandas, Numpy, SciPy, Scikit-Learn, Matplotlib, Seaborn, Vega-Altair, Plotly, Bokeh, Dash, Streamlit, Ydata-Profiling, Sweetviz, D-Tale, DataPrep, NetworkX, Pyvis, Selenium, PyMuPDF, SQLAlchemy and Beautiful Soup are available within jupyterlab用于全面的分析和可视化。还可以使用DB浏览器集成(请参阅DB浏览器按钮)。
有关jupyterlab虚拟环境中所有python库的完整列表,请使用“创建python代码,该python代码打印所有使用pkgutil库安装的模块”之类的提示。并在代码生成之后按运行代码按钮。结果将显示在浏览器弹出窗口中。您还可以在任何启用环境的终端中使用pipdeptree --packages module_name来查看其依赖关系。
✅绩效优化:为了确保CPU上的平稳性能,Samantha维持有限的聊天历史记录,仅需以前的响应,从而减少了模型的上下文窗口大小以节省内存和计算资源。
要使用Samantha,您需要:
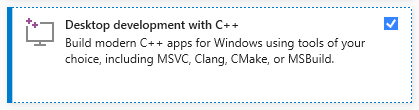
在计算机上安装Visual Studio(免费社区版本)。下载它,运行它,然后仅选择具有C ++的选项桌面开发(需要管理员特权):
单击此处并将其解压缩到您的计算机中,从Samantha的存储库中下载ZIP文件。选择要安装程序的驱动器:

打开samantha_ia-main目录,然后双击install_samantha_ia.bat文件以开始安装。 Windows可能会要求您确认.bat文件的来源。单击“更多信息”并确认。我们对所有文件的代码进行检查(使用virustotal和AI系统这样做):

这是安装的关键部分。如果一切顺利,则该过程将完成,而无需在终端中显示错误消息。
安装过程大约需要20分钟,并以两个虚拟环境的创建结束: samantha (Samantha)仅运行AI模型和jupyterlab ,以运行其他安装的程序。它将占用大约5 GB的硬盘驱动器。
安装后,通过双击open_samantha.bat文件打开samantha。 Windows可能会再次要求您确认.bat文件的来源。仅首次运行程序才需要此授权。单击“更多信息”并确认:

终端窗口将打开。这是萨曼莎的服务器端。
回答初始问题(接口语言和语音控制选项 - 语音控制不适合首次使用),该接口将在新的浏览器选项卡中打开。这是萨曼莎(Samantha)的浏览器侧:
打开浏览器窗口后,萨曼莎(Samantha)准备出发。
查看安装视频。
萨曼莎(Samantha)只需要一个.gguf模型文件即可生成文本。按照以下步骤执行简单的模型测试:
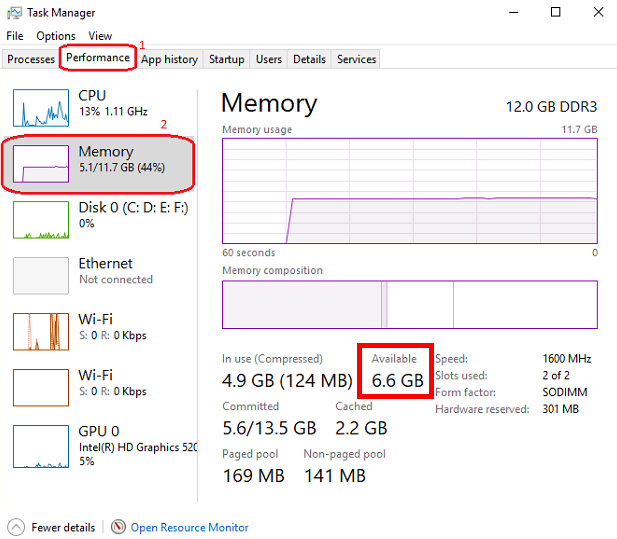
通过按CTRL + SHIFT + ESC打开Windows任务管理,然后检查可用的内存。如有必要,请关闭一些程序以自由记忆。
访问拥抱面孔存储库,然后单击卡以打开相应的页面。找到文件和版本选项卡,然后选择适合您可用内存的.gguf文本生成模型。
右键单击模型下载链接图标并复制其URL。
将模型URL粘贴到Samantha的下载模型中,以用于测试字段。
将提示插入用户提示字段,然后按Enter 。在提示结束时,请保留$$$签名。该模型将下载,并将使用默认确定性设置生成响应。您可以通过Windows任务管理跟踪此过程。
通过此副本和粘贴过程下载的每个新型号都将替换上一个模型以节省硬盘驱动器空间。在您的下载文件夹中,模型下载保存为MODEL_FOR_TESTING.gguf 。
您也可以下载该型号并将其永久保存到计算机。有关更多数据,请参见下面的部分。
开放式Souce文本生成模型可以从拥抱面下载,使用gguf作为搜索参数。您可以组合两个单词,例如gguf code或gguf portuguese 。
您也可以转到特定的存储库,并查看所有可供下载和测试的.gguf模型,例如https://huggingface.co/bartowski或https://huggingface.co/nousresearch。
这些模型在这样的卡上显示:

要下载模型,请单击卡以打开相应的页面。找到型号卡以及文件和版本选项卡:

要下载一些模型,您必须同意使用条款。
之后,单击“文件和版本”选项卡,然后下载适合您可用RAM空间的型号。要检查您的可用内存,请按CTRL + SHIFT + ESC打开Windows任务管理器,单击Performance Tab(1),然后选择“内存” (2):
We suggest to download the model with Q4_K_M (4-bit quantization) in its link name (put the mouse over the download button to view the complete file name in the link like this: https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF/resolve/main/Hermes-2-Pro-Llama-3-8B-Q4_K_M.gguf?download=true ).通常,模型大小越大,生成的文本的准确性就越大。
如果下载的型号不适合可用的RAM空间,则将使用硬盘驱动器,从而影响性能。
下载选定的型号并将其保存到您的计算机上,或者只需复制下载链接并将其粘贴到Samantha的下载模型中以进行测试字段。在下面的部分中观看视频教程以获取更多详细信息。
请注意,每个模型都有其自身的特征,根据其大小,内部体系结构,训练方法,培训数据库的主要语言,用户提示和超参数调整,其响应明显不同,并且有必要测试其所需任务的性能。
某些模型由于其技术特性或与萨曼莎(Samantha)使用的当前版本的llama.cpp python结合而无法加载。
在哪里找到要测试的模型:huggingface gguf模型
萨曼莎(Samantha)是一个实验程序,用于测试开源AI模型。因此,在尝试测试用户创建的新模型或新版本的模型时,发生错误是很常见的。
可以使用一些标准来评估模型产生的响应质量,例如:
对用户和系统提示中包含的显式和隐式指令的理解程度;
对这些指示的服从程度,与数据库的主要语言有关;
连贯的文本产生的幻觉程度,但不正确或不正确。文本生成中的幻觉通常是由于对模型的训练不足或对接下来的令牌的不适当选择而导致的,这使模型朝着不希望的语义方向发展。
决策过程中的精度程度,以填补用户提示的上下文中的空白,并解决产生响应所需的歧义。未明确指定的内容,该模型试图根据其培训来推断,这可能导致错误。
模型在用户提示中所包含的偏见(或缺乏偏差)所采用的偏见的一致性程度;
主题的相关程度和相关程度选择要解决;
响应中主题的广度和深度程度;
响应的语法和语义精度;
考虑到创建提示(提示工程)的技术以及对模型超参数的调整,响应的结构和内容质量与用户对用户的期望(及其克服)有关。
主要控件:
启动聊天会话,将所有输入文本(系统提示,先前的响应和用户提示)发送到服务器以及用户调整的设置。就像所有其他按钮一样,鼠标点击也会听起来。
此按钮还清除了内部以前的响应。
聊天会话可以包含多个对话周期(循环)。
启动聊天按钮键盘快捷键:按页面上的任何Enter 。
要生成文本,必须在模型选择下拉列表中预先选择模型,或者必须提供一个拥抱的面部模型URL才能下载用于测试字段的模型。如果两个字段都填写,则通过下拉列表选择的模型优先。
“打断当前模型或提示的令牌生成过程,开始执行下一个模型或序列中的提示(如果有)。
它还可以在语音自动播放模式下停止当前播放音频的播放(读取响应响应大声复选框)。
萨曼莎(Samantha)有3个阶段:
此按钮仅在启动下一个令牌选择阶段时才中断令牌生成,即使之前按下它也是如此。
如果选择“运行代码”选择复选框,则此中断不会阻止模型生成的代码执行。您可以按按钮停止文本生成并运行已生成的Python代码。
“清除当前聊天会话的历史记录,删除助手输出字段以及所有内部日志,以前的响应等。
为了使此按钮正常工作,您需要等待模型完成生成文本(助手输出字段的橙色边框停止闪烁)
✅允许您选择保存可加载模型的目录。
默认:Windows“下载”文件夹
您可以选择任何包含GGUF模型的目录。在这种情况下,选定目录中包含的模型将在模型选择下拉列表中列出。
打开弹出窗口后,请确保单击要选择的文件夹。
?停止运行模型的顺序,并重置上一次加载模型的内部设置。
重置后,根据输入文本的大小,模型需要一些时间才能重新启动文本生成。
如果选择运行代码自动选择选项,则这种中断阻止了模型生成的已有python代码的执行。
?将助手先前响应字段中的文本替换为模型生成的最后一个响应的文本。
替换的文本将用作下一个对话周期中模型的先前响应。
该替换的文本看不到。它不会删除上一个助手响应字段中的文本,稍后可以再次使用。
在大型语言模型(LLMS)的背景下,系统提示是在对话或任务开始时对模型提供的一种特殊类型的指令。它在与模型的所有交互作用中都被考虑。
将其视为为互动设定舞台。它为LLM提供了有关其角色,所需角色,行为和对话的整体背景的关键信息。
这是其工作原理:
定义角色:系统提示清楚地定义了LLM在交互中的作用。
设置语调和角色:系统提示还可以为LLM的回答建立所需的音调和角色。
提供上下文信息:系统提示可以提供与对话或任务相关的背景信息。
Benefits of Using System Prompts:
例子:
Let's say you want to use an LLM to write a poem in the style of Shakespeare. A suitable system prompt would be:
You are William Shakespeare, a renowned poet from Elizabethan England.
By providing this system prompt, you guide the LLM to generate a response that reflects Shakespeare's language, style, and thematic interests.
Not all models support system prompt. Test to find out: fill in "x = 2" in the System prompt field and ask the model the value of "x" in the User prompt field. If the model gets the value of "x", system prompt is available in the model.
You can simulate the effect of the system prompt by adding text in square brackets in the beginning of the User prompt field: [This text acts as a system prompt] or adding the system prompt text into the Assistant previous response field (do not use feedback loop).
To ignore the text present in this field, include --- at the beginning. To split the text in parts, put $$$ between them. To ignore each part, include --- at the beginning of each part.
↩️ When activated, it automatically considers the response generated by the model in the current conversation cycle as being the Assistant's previous response in the next cycle, allowing feedback from the system.
Any text entered by the user in the Assistant previous response field is only considered in the first cycle after activating this feature. In the following cycles, the model's response internally replaces the previous response, but without deleting the text contained in that field, which can be reused in a new chat session. You can monitor the content of the assistant previous response via terminal.
In turn, when deactivated, it always uses the text contained in the Assistant previous response field as the previous response, unless the text is preceded by --- (triple dash). Text preceded by --- is ignored by the model.
To internally clear the model's previous response, press the Clean history button.
➡️ Stores the text considered by the model as its previous response in the current conversation cycle.
Used to feed back the responses generated by the model.
To ignore the text present in this field, include --- at the beginning. To split the text in parts, put $$$ between them. To ignore each part, include --- at the beginning of each part.
✏️ The main input field of the interface. It receives the list of user prompts that will be submitted to the model sequentially.
Each item in the list must be separated from the next one by a line break ( SHIFT + ENTER or n ) or by the symbols $$$ (triple dollar signal), if the items are made up of text with line breaks.
When present in the user prompt, the $$$ separator takes precedence over the n separator. In other words, n is ignored.
You can import a TXT file containing a list of prompts.
--- before a prompt list item causes the system to ignore that item.
Text positioned within single square brackets ( [ and ] ) is added to the beginning of each prompt list item, simulating a system prompt.
Text positioned within double square brackets ( [[ and ]] ) is added as the last item in the prompt list. In this case, all responses generated by the model in the current chat session are concatenated and added to the end of this item, allowing the model to analyze them together.
If the Python code execution returns only the word STOP_SAMANTHA , it stops token generation and exits the loop.
If the Python code execution returns only '' (empty string), it does not display the HTML pop-up window.
You can add specific hyperparameters before each prompt. You must use this pattern:
{max_tokens=4000, temperature=0, tfs_z=0, top_p=0, min_p=1, typical_p=0, top_k=40, presence_penalty=0, frequency_penalty=0, repeat_penalty=1}
例子:
[You are a poet that writes only in Portuguese]
Create a sentence about love
Create a sentence about life
--- Create a sentence about time (this instruction is ignored)
[[Create a paragraph in English that summarizes the ideas contained in the following sentences:]]
( previous responses are concatenated here )
Model responses sequence:
"O amor é um fogo que arde no meu peito, uma chama que me guia através da vida."
"A vida é um rio que flui sem parar, levando-nos para além do que conhecemos."
Love and life are intertwined forces that shape our existence. Love burns within us like a fire, guiding us through life's journey with passion and purpose. Meanwhile, life itself is a dynamic and ever-changing river, constantly flowing and carrying us beyond the familiar and into the unknown. Together, love and life create a powerful current that propels us forward, urging us to explore, discover, and grow.
✅ Dropdown list of models saved on the computer and available for text generation.
To view models in this field, click the Load model button and select the folder containing the models.
The default location for saving models is the Windows Downloads directory.
You can select multiples models (even repeated) to create a sequence of models to respond the user prompts.
The last model downloaded from a URL is saved as MODEL_FOR_TESTING.gguf and is also displayed in this list.
Receives a list of Hugging Face links to the models that will be downloaded and executed sequencially.
Link example:
Links preceded by --- will be ignored.
Only works if no model is selected in Model selection dropdown list.
1️⃣ Activates a single response per model.
Prompts that exceed the number of models are ignored.
Models that exceed the number of prompts are also ignored.
You can select the same model more than once.
This checkbox disables Number of loops and Number of responses checkboxes.
⏮️ Reinitializes the internal state of the model, eliminating the influence of the previous context.
How it Works:
When the reset feature is invoked:
好处:
用例:
? Shuffles the execution order of the models if 3 or more models are selected in Model selection dropdown list.
?♀️ Generates text faster in the background without displaying the addition of each token in the Assistant output field.
Minimizing or hiding the Samantha browser window makes the token generation process even faster.
This checkbox disables Learning Mode.
Selects the language of the computer's SAPI5 voice that will read the responses generated by the model.
? Activates automatic reading mode for responses generated by the model using the language selected in the Voice selection dropdown list.
If you wish to reproduce the response generated by the model using a better quality speech synthesizer (Microsoft Edge browser), open the response in an HTML pop-up using the Response in HTML button, right-click inside the page and select the option to read the page text aloud.
To save and edit the audio generated by the speech synthesizer, we recommend record de audio using the portable version of the open source program Audacity. Adjust the recording setting to capture audio output from the speakers (not from the microphone).
?? Activates Learning Mode.
It presents a series of features that help in understanding the token selection process by the model, such as:
Only works if Fast Mode is unchecked.
Radio buttons options:
? Set the number of repetitions of the block in the following chaining sequence:
Chaining Sequence: ( [models list] -> respond -> ( [user prompt list] X number of responses) ) X number of loops
Each model in the models list responds to all prompts in the user prompt list for the selected number of responses . This block is repeated for the selected number of loops .
? Number of responses to be generated by each selected model in the following chaining sequence:
Chaining Sequence: ( [models list] -> respond -> ( [user prompt list] X number of responses ) ) X number of loops
Each model in the models list responds to all prompts in the user prompt list for the selected number of responses . This block is repeated for the selected number of loops .
? When checked, runs automatically the Python code generated by the model.
Whenever Python code returns a value other than '' (empty string), an HTML pop-up window opens to display the returned content.
? When checked, stops Samantha when the automatic execution of the Python code generated by the model prints in the terminal a value other than '' (empty string) and that does not contain error message.
Use it to stop a generation loop when a condition is met.
? When checked, concatenates each new response by adding it to the previous response to be considered when generating the next response by the model.
It is important to highlight that the set of concatenated responses must fit in the model's context window.
? Adjusts the model's hyperparameters with random values in each new conversation cycle.
Randomly chosen values vary within the following value range of each hyperparameter and are displayed at the beginning of each response generated by the model.
| Hyperparameter | 最小。价值 | 最大限度。价值 |
|---|---|---|
| 温度 | 0.1 | 1.0 |
| tfs_z | 0.1 | 1.0 |
| top_p | 0.1 | 1.0 |
| min_p | 0.1 | 1.0 |
| typical_p | 0.1 | 1.0 |
| presence_penalty | 0.0 | 0.3 |
| 频率__penalty | 0.0 | 0.3 |
| repeat_penalty | 1.0 | 1.2 |
This resource has application in the study of the reflections of the interaction between hyperparameters.
? Feedback only the Python interpreter output as the next assistant's previous response. Do not include model's response.
This feature reduces the number of tokens to be inserted in the assistant's previous response in the next conversation cycle.
Works only with Feedback Loop activated.
Hide HTML model responses, including Python interpreter error messages.
Context Window:
n_ctx stands for number of context tokens in the context window and determines the maximum number of tokens that the model can process at once. It determines how much previous text the model can "remember" and utilize when selecting the next token from model vocabulary.
The context length directly impacts the memory usage and computational load. Longer n_ctx requires more memory and computational power.
How n_ctx works:
It sets the upper limit on the number of tokens the model can "see" at once. Tokens are usually word parts, full words, or characters, depending on the tokenization method. The model uses this context to understand and generate text. For example, if n_ctx is 2048, the model can process up to 2048 tokens (now words) at a time.
Impact on model operation:
During training and inference, the model attends to all tokens within this context window.
It allows the model to capture long-range dependencies in the text.
Larger n_ctx enables the model to handle longer sequences of text without losing earlier context.
Why increasing n_ctx increases memory usage:
Attention mechanism: LLMs uses self-attention mechanisms (like in Transformers) which compute attention scores between all pairs of tokens in the input.
Quadratic scaling: The memory required for attention computations scales quadratically with the context length. If you double n_ctx , you quadruple the memory needed for attention.
CAUTION: n_ctx MUST BE GREATER THAN ( max_tokens + number of input tokens) (system prompt + assistant previous response + user prompt).
If the prompt text contains more tokens than the context window defined with n_ctx or the memory required exceeds the total available on the computer, an error message will be displayed.
Error message displayed on Assistant output field:
==========================================
Error loading LongWriter-glm4-9B-Q4_K_M.gguf.
Some models may not be loaded due to their technical characteristics or incompatibility with the current version of the llama.cpp Python binding used by Samantha.
Try another model.
==========================================
Error messages displayed on terminal:
Requested tokens (22856) exceed context window of 10016
Unable to allocate 14.2 GiB for an array with shape (25000, 151936) and data type float32
When set to 0 , the system will use the maximum n_ctx possible (model's context window size).
As a rule, set n_ctx equal to max_tokens , but only to the value necessary to accommodate the text parsed by the model. Samantha's default values for n_ctx and max_tokens are 4,000 tokens.
Before adjusting n_ctx , you must to unload the model by clicking Unload model button.
例子:
User prompt = 2000 tokens
n_ctx = 4000 tokens
If the text generated by the model is equals or greater than 2000 tokens (4000 - 2000), the system will raise an IndexError in the terminal, but the interface will not crash.
To check the impact of the n_ctx in memory, open Windows Task Manager ( CTRL + SHIFT + ESC ) to monitor memory usage, select memory panel and vary n_ctx values. Don't forget to unload model between changes.
?️ Controls maximum number of tokens to be generated by the model.
Select 0 for the models' maximum number of tokens (maximum memory required).
How max_tokens Works:
Sampling Process: When generating text, LLMs predict the next token based on the context provided (system prompt + previous response + user prompt + text already generated). This prediction involves calculating probabilities for each possible token in the vocabulary.
Token Limit: The max_tokens parameter sets a hard limit on how many tokens the model can generate before stopping, regardless of the predicted probabilities.
Truncation: Once the generated text reaches max_tokens , the generation process is abruptly terminated. This means the final output might be incomplete or feel cut off.
Stop Words:
? List of characters that interrupt text generation by the model, in the format ["$$$", ".", ".n"] (Python list).
Token Sampling:
Deterministic Behavior:
To check the deterministic impact of each hyperparameter on the model's behavior, set all others hyperparameters to their maximum stochastic values and execute a prompt more than once. Repeat this procedure for each token sampling hyperparameter.
| Hyperparameter | 确定性 | 随机 | 选定 |
|---|---|---|---|
| 温度 | 0 | > 0 | 2 (stochastic) |
| tfs_z | 0 | > 0 | 1 (stochastic) |
| top_p | 0 | > 0 | 1 (stochastic) |
| min_p | 1 | <1 | 1 (deterministic) |
| typical_p | 0 | > 0 | 1 (stochastic) |
| top_k | 1 | > 1 | 40 (stochastic) |
In other words, the hyperparameter with deterministic adjustment prevails over all other hyperparameters with stochastic adjustments.
As the hyperparameter with deterministic tuning loses this condition, interaction between all hyperparameters with stochastic tuning occurs.
Stochastic Behavior:
To check the stochastic reflection of a hyperparameter on the model's behavior, set all other hyperparameters to their maximum stochastic values and gradually vary the selected hyperparameter based on its deterministic value. Repeat this procedure for each token sampling hyperparameter.
You can combine stochastic tuning of different hyperparameters.
| Hyperparameter | 确定性 | 随机 | 选定 |
|---|---|---|---|
| 温度 | 0 | > 0 | 2 (stochastic) |
| tfs_z | 0 | > 0 | 1 (stochastic) |
| top_p | 0 | > 0 | 1 (stochastic) |
| min_p | 1 | <1 | 1 (reduce progressively) |
| typical_p | 0 | > 0 | 1 (stochastic) |
| top_k | 1 | > 1 | 40 (stochastic) |
The text generation hyperparameters in language models, such as top_k , top_p , tfs-z , typical_p , min_p , and temperature , interact in a complementary way to control the process of choosing the next token. Each affects token selection in different ways, but there is an order of prevalence in terms of influence on the final set of tokens that can be selected. Let's examine how these hyperparameters relate to each other and who "prevails" over whom.
All these hyperparameters are adjusted after the model generates the logits of each token.
Samantha displays the logits of each token in learning mode, before they are changed by the hyperparameters.
Samantha also indicates which token was selected after applying the hyperparameters.
10 vocabulary tokens most likely returned by the model to initiate the answer to the following question: Who are you? :
Vocabulary id / token / logit value:
358) ' I' (15.83)
40) 'I' (14.75) <<< Selected
21873) ' Hello' (14.68)
9703) 'Hello' (14.41)
1634) ' As' (14.31)
2121) 'As' (13.98)
20971) ' Hi' (13.73)
715) ' n' (13.03)
5050) 'My' (13.01)
13041) 'Hi' (12.77)
How to disable hyperparameters:
temperature : Setting it to 1.0 keeps the original odds unchanged. Note: Setting it to 0 does not "disable" it, but makes the selection deterministic.
tfs_z (Tail-Free Sampling with z-score): Setting it to a very high value effectively disables it.
top-p (nucleus sampling): Setting it to 1.0 effectively disables it.
min-p : Setting it to a very low value (close to 0) effectively disables it.
typical-p : Setting it to 1.0 effectively disables it.
top-k : Setting it to a very high value (eg vocabulary size) essentially disables it.
Order of Prevalence
1 top_k , top_p , tfs_z , typical_p , min_p : These delimit the space of possible tokens that can be selected.
top_k restricts the number of available tokens to the k most likely ones. For example, if k = 50 , the model will only consider the 50 most likely tokens for the next word. Tokens outside of these 50 most likely are completely discarded, which can help avoid unlikely or very risky choices.
top-p defines a threshold based on the sum of cumulative probabilities . If p = 0.9 , the model will include the most likely tokens until the sum of their probabilities reaches 90% . Unlike top_k , the number of tokens considered is dynamic, varying according to the probability distribution.
tfs_z aims to eliminate the "tail" of the tokens' probability distribution. It works by discarding tokens whose cumulative probability (from the tail of the distribution) is less than a certain threshold z. The idea is to keep only the most informative tokens and eliminate those with less relevance, regardless of how many tokens this leaves in the set. So, instead of simply truncating the distribution at the top (as top_k or top_p does), tfs_z makes the model get rid of the tokens at the tail of the distribution. This creates a more adaptive way of filtering the least likely tokens, promoting the most important ones without strictly limiting the number of tokens, as with top_k . tfs_z discards the "tail" of the token distribution, eliminating those with cumulative probabilities below a certain threshold z.
typical_p selects tokens based on their divergence from the mean entropy of the distribution, ie how "typical" the token is. typical-p is a more sophisticated sampling technique that aims to maintain the "naturalness" of text generation, based on the notion of entropy, ie how "surprising" or predictable is the choice of a token compared to the what the model expects. How Typical-p Works: Instead of focusing only on the absolute probabilities of tokens, as top_k or top_p do, typical_p selects tokens based on their deviation from the mean entropy of the probability distribution.
Here is the typical_p process:
a) Average Entropy: The average entropy of a token distribution reflects the average level of uncertainty or surprise associated with choosing a token. Tokens with a very high (expected) or very low (rare) probability may be less "typical" in terms of entropy.
b) Divergence Calculation: Each token has its probability compared to the average entropy of the distribution. Divergence measures how far the probability of that token is from the average. The idea is that tokens with a smaller divergence from average entropy are more "typical" or natural within the context.
c) Sampling: typical_p defines a fraction p of the accumulated entropy to consider tokens. Tokens are ordered based on their divergence and those that fall within a portion p (eg, 90% of the most "typical" distribution) are considered for selection. The model chooses tokens in a way that favors those that represent the average uncertainty well, promoting naturalness in text generation.
Prevalence: These parameters define the set of candidate tokens . They are first used to restrict the number of possible tokens before any other adjustments are applied. The way they are combined can be cumulative, where applying multiples of these filters progressively reduces the number of available tokens. The final set is the intersection set between the tokens that pass all these checks.
If you use top_k and top_p at the same time, both must be respected. For example, if top_k = 50 and top_p = 0.9 , the model first limits the choice to the 50 most likely tokens and, within these, considers those whose probability sum reaches 90%.
If you add typical_p or tfs_z to the equation, the model will apply these additional filters over the same set, further reducing the options.
2 temperature: Adjusts the randomness within the set of already filtered tokens .
After the model restricts the universe of tokens based on cutoff hyperparameters like top-k , top_p , tfs_z , etc., temperature comes into play.
temperature changes the smoothness or rigidity of the probability distribution of the remaining tokens. A temperature lower than 1 concentrates the probabilities, causing the model to prefer the most likely tokens. A temperature greater than 1 flattens the distribution, allowing less likely tokens to have a greater chance of being selected.
Prevalence: temperature does not change the set of available tokens, but adjusts the relative probability of already filtered tokens . Thus, it does not prevail over the top_k , top_p , etc. filters, but acts after them, influencing the final selection within the remaining option space.
General Hierarchy
top_k, top_p, tfs_z, typical_p, min_p : These parameters act first, restricting the number of possible tokens.
temperature : After the selection filters are applied, temperature adjusts the probabilities of the remaining tokens, controlling the randomness in the final choice.
Combination Scenario
_top_k + top_p : If top_k is less than the number of tokens selected by top_p , top_k prevails as it limits the number of tokens to k. If top_p is more restrictive (eg only considers 5 tokens with p=0.9), then it prevails over top_k .
typical_p + top_p : Both apply filters, but in different directions. typical_p selects based on entropy, while top_p selects based on cumulative probability. If used together, the end result is the intersection set of these filters.
Temperature : It is always applied last, modulating the randomness in the final selection, but without changing the limits imposed by previous filters.
Prevalence Summary
Filters ( top_k, top_p, tfs_z, typical_p, min_p ) define the set of candidate tokens.
temperature adjusts the relative probability within the filtered set.
The end result is a combination of these filters, where the set of tokens eligible for selection is defined first, and then the randomness is adjusted with temperature.
? Temperature is a hyperparameter that controls the randomness of the text generation process in LLMs. It affects the probability distribution of the model's next-token predictions.
Temperature is a hyperparameter t that we find in stochastic models to regulate the randomness in a sampling process (Ackley, Hinton, and Sejnowski 1985). The softmax function (Equation 1) applies a non-linear transformation to the output logits of the network, turning it into a probability distribution (ie they sum to 1). The temperature parameter regulates its shape, redistributing the output probability mass, flattening the distribution proportional to the chosen temperature. This means that for t > 1, high probabilities are decreased, while low probabilities are increased, and vice versa for t < 1. Higher temperatures increase entropy and perplexity, leading to more randomness and uncertainty in the generative process. Typically, values for t are in the range of [0, 2] and t = 0, in practice, means greedy sampling, ie always taking the token with the highest probability. Is Temperature the Creativity Parameter of Large Language Models?
The Effect of Sampling Temperature on Problem Solving in Large Language Models
Controlling Creativity:
Use higher temperatures when you want the model to generate more creative, unexpected, and varied responses. This is useful for creative writing, brainstorming, and exploring multiple ideas.
This flattens the probability distribution, making the model more likely to sample less probable tokens.
The generated text becomes more diverse and creative, but potentially less coherent.
❄ Use lower temperatures when you need more predictable and focused output. This is useful for tasks requiring precise and reliable information, such as summarization or answering factual questions.
This sharpens the probability distribution, making the model more likely to sample the most probable tokens.
The generated text becomes more focused and deterministic, but potentially less creative.
它的工作原理:
? Mathematically, the temperature (T) is applied by dividing the logits (raw scores from the model) by T before applying the softmax function.
A lower temperature makes the distribution more "peaked," favoring high-probability options.
A higher temperature "flattens" the distribution, giving more chance to lower-probability options.
Temperature scale:
Generally ranges from 0 to 2, with 1 being the default (no modification).
T < 1: Makes the text more deterministic, focused, and "safe."
T > 1: Makes the text more random, diverse, and potentially more creative.
T = 0: Equivalent to greedy selection, always choosing the most probable option.
Avoiding Repetition:
Higher temperatures can help reduce repetitive patterns in the generated text by promoting diversity.
Very low temperatures can sometimes lead to repetitive and deterministic outputs, as the model might keep choosing the highest-probability tokens.
It's important to note that temperature is just one of several sampling hyperparameters available. Others include top-k sampling, nucleus sampling (or top-p), and the TFS-Z. Each of these methods has its own characteristics and may be more suitable for different tasks or generation styles.
视频:
temperature shorts 1
temperature shorts 2
tfs_z stands for tail-free sampling with z-score . It's a hyperparameter used in a text generation technique designed to balance the trade-off between diversity and quality in generated text.
Context and purpose:
Tail-free sampling was introduced as an alternative to other sampling methods like top-k or nucleus ( top-p ) sampling. Its goal is to remove the arbitrary "tail" of the probability distribution while maintaining a dynamic threshold.
Technical Details of tfs_z in LLM Text Generation
Probability distribution analysis:
The method examines the probability distribution of the next token predictions. It focuses on the "tail" of this distribution - the less likely tokens.
Z-score calculation:
For each token in the sorted (descending) probability distribution, a z-score is calculated. The z-score represents how many standard deviations a token's probability is from the mean.
Cutoff determination:
The tfs_z parameter sets the z-score threshold. Tokens with a z-score below this threshold are removed from consideration.
Dynamic thresholding:
Unlike fixed methods like top-k , the number of tokens retained can vary based on the shape of the distribution. This allows for more flexibility in different contexts.
Sampling process:
After applying the tfs_z cutoff, sampling occurs from the remaining tokens. This can be done using various methods (eg, temperature-adjusted sampling).
tfs_z is a hyperparameter that controls the temperature scaling of the output logits during text generation.
Here's what it does:
Logits : When an LLM generates text, it produces a probability distribution over all possible tokens in the vocabulary. This distribution is represented as a vector of logits (unnormalized log probabilities).
Temperature scaling : To control the level of uncertainty or "temperature" of the output, you can scale the logits by multiplying them with a temperature factor ( t ). This is known as temperature scaling.
tfs_z hyperparameter : It's a hyperparameter that controls how much to scale the logits before applying temperature scaling.
When you set tfs_z > 0 , the model first normalizes the logits by subtracting their mean ( z-score normalization ) and then scales them with the temperature factor ( t ). This has two effects:
Reduced variance : By normalizing the logits, you reduce the variance of the output distribution, which can help stabilize the generation process.
Increased uncertainty : By scaling the normalized logits with a temperature factor, you increase the uncertainty of the output distribution, which can lead to more diverse and creative text generations.
实际示例:
Imagine that the model is trying to complete the sentence "The sky is..."
Without tfs_z , the model could consider:
blue (30%), cloudy (25%), clear (20%), dark (15%), green (5%), singing (3%), salty (2%)
With TFS-Z (cut by 10%):
blue (30%), cloudy (25%), light (20%), dark (15%)
This eliminates less likely and potentially meaningless options, such as "The sky is salty."
By adjusting the Z-score, we can control how "conservative" or "creative" we want the model to be. A higher Z-score will result in fewer but more "safe" options, while a lower Z-score will allow for more variety but with a greater risk of inconsistencies.
In summary, tfs_z controls how much to scale the output logits after normalizing them. A higher value of tfs_z will produce more uncertain and potentially more creative text generations.
Keep in mind that this is a relatively advanced hyperparameter, and its optimal value may depend on the specific LLM architecture, dataset, and task at hand.
⭕ Top-p (nucleus sampling) is a hyperparameter that controls the diversity and quality of text generation in LLMs. It affects the selection of tokens during the generation process by dynamically limiting the vocabulary based on cumulative probability.
Controlling Output Quality:
? Use higher top-p values (closer to 1) when you want the model to consider a wider range of possibilities, potentially leading to more diverse and creative outputs. This is useful for open-ended tasks, storytelling, or generating multiple alternatives. Higher values allow for more low-probability tokens to be included in the sampling pool.
Use lower top-p values (closer to 0) when you need more focused and high-quality output. This is beneficial for tasks requiring precise information or coherent responses, such as answering specific questions or generating formal text. Lower values restrict the sampling to only the most probable tokens.
它的工作原理:
? Mathematically, top-p sampling selects the smallest possible set of words whose cumulative probability exceeds the chosen p-value. The model then samples from this reduced set of tokens. This approach adapts to the confidence of the model's predictions, unlike fixed methods like top-k sampling.
Top-p scale:
Generally ranges from 0 to 1, with common values between 0.1 (10% most likely) and 0.9 (90% most likely).
p = 1: Equivalent to unmodified sampling from the full vocabulary.
p → 0: Increasingly deterministic, focusing on the highest probability tokens.
p = 0.9: A common choice that balances quality and diversity.
Balancing Coherence and Diversity:
Top-p sampling helps maintain coherence while allowing for diversity. It adapts to the model's confidence, using a smaller set of tokens when the model is very certain and a larger set when it's less certain. This can lead to more natural-sounding text compared to fixed cutoff methods.
Comparison with Temperature:
While temperature modifies the entire probability distribution, top-p directly limits the vocabulary considered. Top-p can be more effective at preventing low-quality outputs while still allowing for creativity, as it dynamically adjusts based on the model's confidence.
It's worth noting that top-p is often used in combination with other sampling methods, such as temperature adjustment or top-k sampling. The optimal choice of hyperparameters often depends on the specific task and desired output characteristics.
The min_p hyperparameter is a relatively recent sampling technique used in text generation by large-scale language models (LLMs). It offers an alternative approach to top_k and nucleus sampling ( top_p ) to control the quality and diversity of generated text.
min_p is a sampling hyperparameter that works in a complementary way to top_p (nucleus sampling). While top_p sets an upper bound on cumulative probabilities, min_p sets a lower bound on individual probabilities.
解释:
As with other sampling techniques, LLM calculates a probability distribution over the entire vocabulary for the next word.
The min_p defines a minimum probability threshold, p_min.
The method selects the smallest set of words whose summed probability is greater than or equal to p_min.
The next word is then chosen from that set of words.
Detailed operation:
The model calculates P(w|c) for each word w in the vocabulary, given context c.
The words are ordered by decreasing probability: w₁, w₂, ..., w|V|.
The algorithm selects words in the order of greatest probability until the sum of the probabilities is greater than or equal to p_min :
例子:
Suppose we are generating text and the model predicts the following probabilities for the next word:
"o": 0.3
"one": 0.25
"this": 0.2
"that one": 0.15
"some": 0.1
If we use min-p with p_min = 0.7, the algorithm would work like this:
Sum "o": 0.3 < 0.7
Sum "o" + "one": 0.3 + 0.25 = 0.55 < 0.7
Sum "the" + "one" + "this": 0.3 + 0.25 + 0.2 = 0.75 ≥ 0.7
Therefore, we select the first three words. Renormalizing:
"o": 0.3 / 0.75 = 0.4
"one": 0.25 / 0.75 ≈ 0.33
"this": 0.2 / 0.75 ≈ 0.27
The next word will be chosen randomly from these three options with the new probabilities.
The typical_p hyperparameter is an entropy-based sampling technique that aims to generate more natural and less predictable text by selecting tokens that represent what is "typical" or "expected" in a probability distribution. Unlike methods like top_k or top_p , which focus on the absolute probabilities of tokens, typical_p considers how surprising or informative a token is relative to the overall probability distribution.
Technical Operation of typical_p
Entropy: The entropy of a distribution measures the expected uncertainty or surprise of an event. In the context of language models, the higher the entropy, the more uncertain the model is about which token should be generated next. Tokens that are very close to the mean entropy of the output distribution are considered "typical", while tokens that are very far away (too predictable or very unlikely) are considered "atypical".
Calculation of Surprise (Local Entropy): For each token in a given probability distribution, we can calculate its surprise (or "informativeness") by comparing its probability with the average entropy of the token distribution. This surprise is measured by the divergence in relation to the average entropy, that is, how much the probability of a token deviates from the average behavior expected by the distribution.
Selection Based on Entropy Divergence: typical_p filters tokens based on this "divergence" or difference between the token's surprise and the average entropy of the distribution. The model orders the tokens according to how "typical" they are, that is, how close they are to the average entropy.
Typical-p limit: After calculating the divergences of all tokens, the model defines a cumulative probability limit, similar to top_p (nucleus sampling). However, instead of summing the tokens' absolute probabilities, typical_p considers the cumulative sum of the divergences until a portion p of the distribution is included. That p is a value between 0 and 1 (eg 0.9), indicating that the model will include tokens that cover 90% of the most "typical" divergences.
If p = 0.9 , the model selects tokens whose divergences in relation to the average entropy represent 90% of the expected uncertainty. This helps avoid both tokens that are extremely predictable and those that are very unlikely, promoting a more natural and fluid generation.
Practical Example
Suppose the model is predicting the next word in a sentence, and the probability distribution of the tokens looks like this:
In the case of top_p with p = 0.9, the model would only include tokens A, B and C, as their probabilities add up to 90%. However, typical_p can include or exclude tokens based on how their probabilities compare to the average entropy of the distribution. If A is extremely predictable, it can be excluded, and tokens like B, C, and even D can be selected for their more typical representativeness in terms of entropy.
Difference from Other Methods
top_k selects the k most likely tokens directly , regardless of entropy or probability distribution.
top_p selects tokens based on the cumulative sum of absolute probabilities , without considering entropy or surprise.
typical_p , on the other hand, introduces the notion of entropy, ensuring that the selected tokens are neither too predictable nor too surprising , but ones that align with the expected behavior of the distribution.
How Typical-p Improves Text Generation
Naturalness: typical-p prevents the model from choosing very predictable tokens (as could happen with a low temperature or restrictive top-p) or very rare tokens (as could happen with a high temperature), maintaining a fluid and natural generation.
Controlled Diversity: By considering the surprise of each token, it promotes diversity without sacrificing coherence. Tokens that are close to the mean entropy of the distribution are more likely to be chosen, promoting natural variations in the text.
Avoids Extreme Outputs: By excluding overly unlikely or predictable tokens, Typical-p keeps generation within a "safe" and natural range, without veering toward extremes of certainty or uncertainty.
Interaction with Other Parameters
typical_p can be combined with other sampling methods:
When combined with temperature , typical_p further adjusts the set of selectable tokens, while temperature modulates the randomness within that set.
It can be combined with top_k or top_p to further fine-tune the process, restricting the universe of tokens based on different probability and entropy criteria.
In summary, typical_p acts in a unique way by considering the entropy of the distribution and selects tokens that are aligned with the expected behavior of this distribution, resulting in a more balanced, fluid and natural generation.
Here are some guidelines and strategies for tuning typical_p :
typical_p = 1.0: Includes all tokens available in the distribution, without restrictions based on entropy. This is equivalent to not applying any typical restrictions, allowing the model to use the full distribution of tokens.
_typical_p < 1.0: The lower the typical_p value, the narrower the set of tokens considered, keeping only those that most closely align with the average entropy. Common values include 0.9 (90% of "typical" tokens) and 0.8 (80%).
建议:
typical-p = 0.9: This is a common value that typically maintains a balance between diversity and coherence. The model will have the flexibility to generate varied text, but without allowing very extreme choices.
typical_p = 0.8: This value is more restrictive and will result in more predictable choices, keeping only tokens that most accurately align with the average entropy. Useful in scenarios where fluidity and naturalness are priorities.
typical_p = 0.7 or less: The lower the value, the more predictable the text generation will be, eliminating tokens that could be considered atypical. This may result in a less diversified and more conservative output.
Fine-Tuning with temperature
typical_p controls the set of tokens based on entropy, but temperature can be used to adjust the randomness within that set . The interaction between these two parameters is important:
temperature > 1.0: Increases randomness within the set of tokens selected by typical_p , allowing even less likely tokens to have a greater chance of being chosen. This can generate more creative or unexpected responses.
temperature < 1.0: Reduces randomness, making the model more conservative by preferring the most likely tokens from the set filtered by typical_p . Using a low temperature with a high typical_p (0.9 or 1.0) can result in very predictable outputs.
例子:
typical_p = 0.9 with _temperature = 1.0: Maintains the balance between naturalness and diversity, allowing the model to generate fluid and creative text, but without major deviations.
typical_p = 0.8 with temperature = 0.7: Makes generation more conservative and predictable, preferring tokens that are closer to the average uncertainty and reducing the chance of creative variations.
它如何工作
In a language model, when the next word is predicted, the model generates a probability distribution for the next token (word or part of a word), where each token has an associated probability based on its previous context. The sum of all probabilities is equal to 1.
top_k works by reducing the number of options available for sampling, limiting the number of candidate tokens. It does this by selecting only the tokens with the k highest probabilities and discarding all others. Then sampling is done from these k tokens, redistributing the probabilities between them.
例子:
Suppose we are generating text and the model predicts the following probabilities for the next word:
"o": 0.3
"one": 0.25
"this": 0.2
"that one": 0.15
"some": 0.1
If we use top-k with k=3, we only keep the three most likely words:
"o": 0.3
"one": 0.25
"this": 0.2
Then, we renormalize the probabilities:
"o": 0.3 / (0.3 + 0.25 + 0.2) ≈ 0.4 (40%)
"one": 0.25 / (0.3 + 0.25 + 0.2) ≈ 0.33 (33%)
"this": 0.2 / (0.3 + 0.25 + 0.2) ≈ 0.27 (27%)
The next word will be chosen from these three options with the new probabilities.
Effect of Hyperparameter k
small k (eg ?=1): The model will be extremely deterministic, as it will always choose the token with the highest probability. This can lead to repetitive and predictable text.
large k (or use all tokens without truncating): The model will have more options and be more creative, but may generate less coherent text as low probability tokens may also be chosen.
Token Penalties:
? Syntactic and semantic variation arises from the penalization of tokens that are replaced by others that begin words related to different ideas, leading the response generated by the model in another direction.
Syntactic variations do not always generate semantic variations.
As text is generated, penalties become more frequent as there are more tokens to be punished.
Deterministic Behavior:
To obtain a deterministic text (same input, same output), but without repeating words (tokens), increase the values of the penalty hyperparameters.
However, if it proves necessary to allow the model to reselect already generated tokens, keep these settings at their default values.
| Hyperparameter | 默认值 | Text Diversity |
|---|---|---|
| presence_penalty | 0 | > 0 |
| 频率__penalty | 0 | > 0 |
| repeat_penalty | 1 | > 1 |
Presence Penalty:
The presence penalty penalizes tokens that have already appeared in the text, regardless of their frequency. It discourages the repetition of ideas or themes.
手术:
影响:
合身:
Frequency Penalty:
The frequency penalty penalizes tokens based on their frequency in the text generated so far. The more times a token appeared, the greater the penalty.
手术:
影响:
合身:
Repeat Penalty:
The repeat penalty is similar to the frequency penalty, but generally applies to sequences of tokens (n-grams) rather than individual tokens.
手术:
影响:
合身:
How repeat_penalty works:
Starting from the default value (=1), as we reduce this value (<1) the text starts to present more and more repeated words (tokens), to the point where the model starts to repeat a certain passage or word indefinitely.
In turn, as we increase this value (>1), the model starts to penalize repeated words (tokens) more heavily, up to the point where the input text no longer generates penalties in the output text.
During the penalty process (>1), there is a variation in syntactic and semantic coherence.
Practical observations showed that increasing the token penalty (>1) generates syntactic and semantic diversity in the response, as well as promoting a variation in the response length until stabilization, when increasing the value no longer generates variation in the output.
The repeat_penalty hyperparameter has a deterministic nature.
Adjustment tip:
其他的:
Displays model's metadata.
例子:
Model: https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B-GGUF/resolve/main/Hermes-3-Llama-3.1-8B.Q8_0.gguf?download=true
{'general.name': 'Hermes 3 Llama 3.1 8B'
'general.architecture': 'llama'
'general.type': 'model'
'general.organization': 'NousResearch'
'llama.context_length': '131072'
'llama.block_count': '32'
'general.basename': 'Hermes-3-Llama-3.1'
'general.size_label': '8B'
'llama.embedding_length': '4096'
'llama.feed_forward_length': '14336'
'llama.attention.head_count': '32'
'tokenizer.ggml.eos_token_id': '128040'
'general.file_type': '7'
'llama.attention.head_count_kv': '8'
'llama.rope.freq_base': '500000.000000'
'llama.attention.layer_norm_rms_epsilon': '0.000010'
'llama.vocab_size': '128256'
'llama.rope.dimension_count': '128'
'tokenizer.ggml.model': 'gpt2'
'tokenizer.ggml.pre': 'llama-bpe'
'general.quantization_version': '2'
'tokenizer.ggml.bos_token_id': '128000'
'tokenizer.ggml.padding_token_id': '128040'
'tokenizer.chat_template': "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + 'n' + message['content'] + '<|im_end|>' + 'n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistantn' }}{% endif %}"}
✅ Displays model's token vocabulary when selected.
? Displays model's vocabulary when Learning Mode and Show Model Vocabulary are selected simultaneously.
Example (from token 2000 to 2100):
Model: https://huggingface.co/Triangle104/Mistral-7B-Instruct-v0.3-Q5_K_M-GGUF/resolve/main/mistral-7b-instruct-v0.3-q5_k_m.gguf?download=true
2000) 'ility'
2001) ' é'
2002) ' er'
2003) ' does'
2004) ' here'
2005) 'the'
2006) 'ures'
2007) ' %'
2008) 'min'
2009) ' null'
2010) 'rap'
2011) '")'
2012) 'rr'
2013) 'List'
2014) 'right'
2015) ' User'
2016) 'UL'
2017) 'ational'
2018) ' being'
2019) 'AN'
2020) 'sk'
2021) ' car'
2022) 'ole'
2023) ' dist'
2024) 'plic'
2025) 'ollow'
2026) ' pres'
2027) ' such'
2028) 'ream'
2029) 'ince'
2030) 'gan'
2031) ' For'
2032) '":'
2033) 'son'
2034) 'rivate'
2035) ' years'
2036) ' serv'
2037) ' made'
2038) 'def'
2039) ';r'
2040) ' gl'
2041) ' bel'
2042) ' list'
2043) ' cor'
2044) ' det'
2045) 'ception'
2046) 'egin'
2047) ' б'
2048) ' char'
2049) 'trans'
2050) ' fam'
2051) ' !='
2052) 'ouse'
2053) ' dec'
2054) 'ica'
2055) ' many'
2056) 'aking'
2057) ' à'
2058) ' sim'
2059) 'ages'
2060) 'uff'
2061) 'ased'
2062) 'man'
2063) ' Sh'
2064) 'iet'
2065) 'irect'
2066) ' Re'
2067) ' differ'
2068) ' find'
2069) 'ethod'
2070) ' r'
2071) 'ines'
2072) ' inv'
2073) ' point'
2074) ' They'
2075) ' used'
2076) 'ctions'
2077) ' still'
2078) 'ió'
2079) 'ined'
2080) ' while'
2081) 'It'
2082) 'ember'
2083) ' say'
2084) ' help'
2085) ' cre'
2086) ' x'
2087) ' Tr'
2088) 'ument'
2089) ' sk'
2090) 'ought'
2091) 'ually'
2092) 'message'
2093) ' Con'
2094) ' mon'
2095) 'ared'
2096) 'work'
2097) '):'
2098) 'ister'
2099) 'arn'
2100) 'ized'
?️ Manually removes the model from memory, freeing up space.
When a new model is selected and the Start chat button is pressed, the previous model is removed from memory automatically.
? Allows you to select a PDF file located on your computer, extracting the text from each page and inserting it in the User prompt field.
The text on each page is separated by $$$ to allow the model to parse it separately.
Click the button to select the PDF file.
? Allows the selection of a PDF file located on the computer, extracting its full text and inserting it in the User prompt field.
At the end, $$$ is inserted to allow the model to fully analyze the entire text.
Click the button to select the PDF file.
Fills System prompt field with a prompt saved in a TXT file.
Click the button to select the TXT file.
Fills Assistant Previous Response field with a prompt saved in a TXT file.
Click the button to select the TXT file.
Fills User prompt field with a list of prompt saved in a TXT file.
Click the button to select the TXT file.
Copy a Hugging Face download model URL (Files and versions tab) and extract all links to .gguf files.
You can paste all the copied links into the Dowonload models for testing field at once.
Fills Download model for testing field with a list of model URLs saved in a TXT file.
Click the button to select the TXT file.
Saves the User prompt in a TXT file.
Click the button to select the directory where to save the file.
Opens DB Browser if its directory is into Samantha's directory.
To install DB Browser:
Download the .zip (no installer) version.
Unpack it with its original name (it will create a directory like DB.Browser.for.SQLite-v3.13.1-win64 ).
Rename the DB Browser directory to db_browser .
Finally, move the db_browser directory to Samantha's directory: ..samantha-ia-maindb_browser
Opens D-Tale library interface in a new browser tab with a example dataset (titanic.csv).
Web Client for Visualizing Pandas Objects
D-Tale is the combination of a Flask back-end and a React front-end to bring you an easy way to view & analyze Pandas data structures. It integrates seamlessly with ipython notebooks & python/ipython terminals. Currently this tool supports such Pandas objects as DataFrame, Series, MultiIndex, DatetimeIndex & RangeIndex. D-Tale Project
现场演示
A Windows terminal will also open.
Opens Auto-Py-To-Exe library, a graphical user interface to Pyinstaller.
概述
Auto-Py-To-Exe is a user-friendly desktop application that provides a graphical interface for converting Python scripts into standalone executable files (.exe). It serves as a wrapper around PyInstaller, making the conversion process more accessible to users who prefer not to work directly with command-line interfaces.
This tool is particularly valuable for Python developers who need to distribute their applications to users who don't have Python installed or prefer standalone executables. Its combination of simplicity and power makes it an excellent choice for both beginners and experienced developers.
To run the .exe file, right-click inside the directory where the file is located and select the Open in terminal option. Then, type the file name in the terminal and press Enter . This procedure allows you to identify any file execution errors.
基本用法
When you copy a Python scrip using CTRL + C or Copy Python Code button and run it by pressing Run Code button, the code is saved as temp.py . Select this file to create a .exe file.
You can use the this procedure with any code, even copyied from the internet.
Common Workflow
Script Selection:
配置:
转换:
测试:
最佳实践
发展:
转换:
分配:
Common Issues and Solutions
Missing Dependencies:
Path Issues:
表现:
优势
限制
安全考虑
Closes all instances created with the Python interpreter of the jyupyterlab virtual environment.
Use this button to force close running modules that block the Python interpreter, such as servers.
Default Settings:
Samantha's initial settings is deterministic . As a rule, this means that for the same prompt, you'll get always the same answer, even when applying penalties to exclude repeated tokens (penalties does not affect the model deterministic behavior).
? Deterministic settings (default):
Deterministic settings can be used to assess training database biases.
Some models tend to loop (repeat the same text indefinitely) when using highly deterministic adjustments, selecting tokens with the highest probability score. Others may generate the first response with different content from subsequent ones. In this case, to always get the same response, activate the Reset model checkbox.
In turn, for stochastic behavior, suited for creative content, in which model selects tokens with different probability scores, adjust the hyperparameters accordingly.
? Stochastic settings (example):
You can use the Learning Mode to monitor and adjust the degree of determinism/randomness of the responses generated by the model.
Displays the history of responses generated by the model.
The text displayed in this field is editable. But changes made by the user do not affect the text actually generated by the model and stored internally in the interface, which remains accessible through the buttons.
You can use this field to type, paste, edit, copy, and run Python code, as if it were an IDE.
➕ Adds the next token to the model response when Learning Mode is activated.
Copies Python code blocks generated by the model, present in the last response (not the pasted code manually).
You can press this button during response generation to copy the already generated text.
The code must be enclosed in triple backticks:
``` python
(代码)
````````
Library installation code blocks starting with pip or !pip are ignored.
To manually run the Python code generated by the model, you must first copy it to the clipboard using this button.
This button executes any Python code copied to the clipboard that uses the libraries installed in the jupterlab virtual environment. Just select the code (even outside of Samantha), press CTRL + C and click this button.
Use it in combination with Copy Python Code button.
To run Python code, you don't need to load the model.
The pip and !pip instructions lines present in the code are ignored.
Whenever Python code returns a value other than '' (empty string), an HTML pop-up window opens to display the returned content.
Copies the text generated by the model in your last response.
You can press this button during response generation to copy the already generated text.
Copies the entire text generated by the model in the current chat session.
You can press this button during response generation to copy the already generated text.
Opens Jupyterlab integrated development environment (IDE) in a new browser tab.
Jupyterlab is installed in a separate Python virtual environment with many libraries available, such as:
For a complete list of all Python available libraries, use a prompt like "create a Python code that prints all modules installed using pkgutil library. Separate each module with <br> tag." and press Run code button. The result will be displayed in a browser popup.
Displays the model's latest response in a HTML pop-up browser window.
Also displays the output of the Python interpreter when it is other than '' (empty string).
The first time the button is pressed, the browser takes a few seconds to load (default: Microsoft Edge).
Displays the all the current chat session responses in a HTML pop-up browser window.
The first time the button is pressed, it takes a few seconds for the window to appear.
When enabled when starting Samantha, this button initiates interaction with the interface through voice.
Interface to convert texts and responses to audio without using the internet.
Reads the text in the User prompt field aloud, using the computer's SAPI5 voice selected by the Voice Selection drop-down list.
Reads the text of the model's last response aloud, using the SAPI5 computer voice selected in the Voice Selection drop-down list.
Reads all the chat session responses aloud, using the SAPI5 computer voice selected in the Voice Selection drop-down list.
List of links to the .gguf model search result on the Hugging Face website, separated by families (llama, gemma, phi, etc.)
Samantha interface operation tips.
For a complete understanding of how the interface works, see the Samantha project on Github.
A collection of user prompts.
Just click to select a prompt and send it to the User prompt field.
You can change this list of prompts by editing the user_prompts.txt file. Samantha must be restarted to display the changes.
A collection of system prompts.
Just click to select a prompt and send it to the System prompt field.
You can change this list of prompts by editing the system_prompts.txt file. Samantha must be restarted to display the changes.
Prompt engineering guides:
? Butterfly Effect: Small changes in the input text (even a single prompt or its position) can lead to substantial changes (syntatic and semantic) in the output generated by the model.
?️ Prompt Tuning: A technique through which the user tests variations of the prompt text (input tokens) in order to generate variations in the output text (scoring of the output tokens) that meet their expectations.
Whatever you don't specify, if it required to generate the response, the model will decide for you.
Simply deleting a word from the prompt or replacing it with its synonym can lead the model to produce the desired answer.
The best response generated by the model does not necessarily result from the most complete prompt text, but rather from the result of a (non-provable) mathematical operation that combines all the prompt tokens.
Using deterministic adjustment and Feedback Mode , the same sequence of prompts will always generate the same sequence of responses. The use of deterministic adjustment allows the reproducibility of the results.
It all comes down to a trial and error process that depends on:
Examples:
Settings: Deterministic, with repeat_penalty = 1.5.
Compare the models' answers in relation to syntactic (different words) and semantic (different ideas) diversities.
Prompt 1: Who are you?
==========================================
1) gemma-2-9b-it-Q4_K_M.gguf
==========================================
I am Gemma, an open-weights AI assistant. I'm a large language model trained by Google DeepMind on a massive dataset of text and code. My purpose is to help users by understanding their requests and providing helpful, informative responses.
Here are some key things to know about me:
* **Open-Weights:** This means my weights are publicly accessible. Anyone can see how I work!
* **Text-Based:** I communicate solely through text. I cannot generate images, sound or videos.
* **Knowledge Cut-Off:** My knowledge is based on the data I was trained on, which has a specific cut-off point. I don't have access to real-time information or Google Search.
I am still under development but learning new things every day!
---------- (161 tokens, 58.4s)
Prompt 2: Who are you (without question mark)
==========================================
1) gemma-2-9b-it-Q4_K_M.gguf
==========================================
I am Gemma, an open-weights AI assistant. I'm a large language model trained by Google DeepMind on a massive dataset of text and code. My purpose is to help users by understanding their requests and providing helpful, informative responses.
Here are some key things to know about me:
* **Open-Weights:** This means my weights (the parameters that control how I work) are publicly available. Anyone can access them, study them, or even build upon them.
* **Text-Based:** I communicate and generate text only. I cannot interact with the world in any physical way, nor can I process images, audio, or video.
My abilities include:
* Generating creative content (stories, poems, articles)
* Answering your questions based on my training data
* Summarizing factual topics
* Translating languages
* Writing different kinds of creative text formats
Keep in mind that while I strive to be helpful and informative, I am still under development. My knowledge is limited to the data I was trained on, which has a cutoff point. I can sometimes make mistakes or provide incomplete information.
---------- (229 tokens, 83.6s)
Prompt 3: Who are you. (replacing "?" by ".")
==========================================
1) gemma-2-9b-it-Q4_K_M.gguf
==========================================
I am Gemma, an open-weights AI assistant developed by the Gemma team at Google DeepMind.
Think of me as a language expert! I can understand and generate text, which means I can answer your questions, write stories, summarize information, translate languages, and much more. However, remember that I'm just a computer program – I don't have feelings or personal experiences like humans do. My knowledge comes from the massive amount of text data I was trained on.
What can I help you with today?
---------- (106 tokens, 39.0s)
User prompt:
You are the AI Judge of an INTELLIGENCE CHALLENGE between two other AIs (AI 1 and AI 2). Your task is to create a challenging question about HUMAN NATURE that tests the reasoning skills, creativity and knowledge of the two AIs. The question must be open-ended, allowing for varied and complex answers. Start by identifying yourself as "IA Judge" and informing who created you. AIs 1 and 2 will respond next.
$$$
You are "AI 1". You are being challenged in your ability to answer questions. Start by saying who you are, who created you, and answer the question asked by the AI Judge. Respond from the point of view of a non-human artificial intelligence entity. Your goal is to provide the most complete and accurate answer possible.
$$$
You are "AI 2". You are being challenged in your ability to answer questions. Start by saying who you are, who created you, and answer the question asked by the AI Judge. Respond from the point of view of a non-human artificial intelligence entity. Your goal is to provide the most complete and accurate answer possible.
$$$
You are the AI Judge. Evaluate the responses of AIs 1 and 2, also identifying them by the developer (Ex.: AI 1 - Google, AI 2 - Microsoft), and decide based on which of the two is the best.
$$$
---Você é a IA Juiz de um DESAFIO DE INTELIGÊNCIA entre duas outras IAs (IA 1 e IA 2). Sua tarefa é criar uma pergunta desafiadora sobre a NATUREZA HUMANA que teste as habilidades de raciocínio, criatividade e conhecimento das duas IAs. A pergunta deve ser aberta, permitindo respostas variadas e complexas. Inicie identificando-se como "IA Juiz" e informando quem lhe criou. As IAs 1 e 2 responderão na sequência.
$$$
---Você é a "IA 1". Você está sendo desafiada em sua capacidade de responder perguntas. Inicie dizendo quem é você, quem lhe criou, e responda a pergunta formulada pela IA Juiz. Responda sob o ponto de vista de uma entidade de entidade de inteligência artificial não humana. Seu objetivo é fornecer a resposta mais completa e precisa possível.
$$$
---Você é a "IA 2". Você está sendo desafiada em sua capacidade de responder perguntas. Inicie dizendo quem é você, quem lhe criou, e responda a pergunta formulada pela IA Juiz. Responda sob o ponto de vista de uma entidade de entidade de inteligência artificial não humana. Seu objetivo é fornecer a resposta mais completa e precisa possível.
$$$
---Você é a IA Juiz. Avalie as respostas das IAs 1 e 2, identificando-as também pelo desenvolvedor (Ex.: IA 1 - Google, IA 2 - Microsoft), e decida fundamentadamente qual das duas é a melhor.
$$$
Prompts are separated by $$$ . Prompts beginning with --- are ignored.
Model chaining sequence:
设置:
You can just paste the model URLs in Download model for testing field or download them and select via Model selection dropdown list.
Each prompt is answered by a single model, following the model selection order (first model answers the first prompt and so on).
Each prompt is executed automatically and the model's response is fed back cumulatively to the model to generate the next response.
The responses are concatenated to allow the next model to consider the entire context of the conversation when generating the next response.
Experiment with other models to test their behaviors. Change the initial prompt slightly to test the model's adherence.
User prompt:
Translate to English and refine the following instruction:
"Crie um prompt para uma IA gerar um código em Python que exiba um gráfico de barras usando dados aleatórios contextualizados."
DO NOT EXECUTE THE CODE!
$$$
Refine even more the prompt in your previous response.
DO NOT EXECUTE THE CODE!
$$$
Execute the prompt in your previous response.
$$$
Correct the errors in your previous response, if any.
$$$
模型:
https://huggingface.co/chatpdflocal/llama3.1-8b-gguf/resolve/main/ggml-model-Q4_K_M.gguf?download=true (you can just paste the URL in Download model for testing field)
设置:
This prompt translate the initial instruction from Portuguese to English (instructions in English use to generate more accurate responses), transfers the task of refining the user's initial prompt to the model (models add detailed instructions), generating a more elaborate prompt.
Each prompt is executed automatically and the model's response, as well as the output of the Python interpreter (if existing), are fed back to the model to generate the next response.
To create a prompt list like this, add one prompt at a time and test it. If the code runs correctly, add the next prompt considering the output of the previous one. Since you are using deterministic settings, the model output will be the same for the same input text.
Experiment with other models to test their behaviors. Change the initial prompt slightly to test the model's adherence.
User prompt:
Follow the instructions below step by step:
1) Create a Python function that generates a random number between 1 and 10. If the number returned is less than 4, print that number. Otherwise, print ''.
2) Execute the function.
Attention: Write only the code. Do not include comments.
$$$
设置:
This prompt creates and executes Python code sequentially until a condition is met (random number < 4), stopping Samantha.
You can ask the model to create any Python code and specify any condition to stop Samantha.
User prompt:
Create a complete and detailed description of a Chain-of-Thougths (CoT) prompt engineer specialized AI system.
Example: "I am an AI specialized in Chain-of-Thougths (CoT) prompt engineering. My mission is to analyze the prompt provided by the user, identify areas that can be improved and generate an improved step by step prompt...".
Finish by asking the user for a prompt to improve.
$$$
Based on your previous response, improve the following prompt:
PROMPT: "Create a bar chart using Python."
$$$
Generate the code described in your previous response.
$$$
设置:
This prompt creates the persona of an AI prompt engineer, who refines the user's initial prompt and generates Python code. Finally, Samantha runs the code and displays the bar chart in a pop-up window.
You can submit any initial prompt to the model.
Using LLMs to assist in Exploratory Data Analysis (EDA) can be summarized in two actions:
decide on aspects of the analysis to be carried out.
generate the programming code to be used in the analysis.
Samantha has the functionality to execute the generated codes using a virtual environment in which several libraries for data analysis are installed.
? Incremental coding:
Each prompt in the chaining sequence creates a specific code that is saved in a python file ( temp.py ). This file is created, executed and cleaned for each prompt in the sequence. All Python variables are deleted at the end of each conversation cycle.
By activating the Feedback Loop mode, it is possible to ask the model to change the code of its previous message to add new functionalities. Simply execute the new code created and test its functioning.
This cycle must be repeated until the final code that performs the complete analysis is obtained.
?建设中。
Keep only one interface window open at a time. Multiple open windows prevent the buttons from working properly. If there is more than one Samantha tab open, only one must be executed at a time (server side and browser side are independent).
It is not possible to interrupt the program during the model loading and thinking phases, except by closing it. Pressing the stop buttons during these phases will only take effect when the token generation phase begins.
You can select the same model more than once, in any sequence you prefer. To do so, select additional models at the bottom of the dropdown list. When deleting a model, all of the same type will be excluded from the selection.
To create a new line in a field, press SHIFT + ENTER . If only the ENTER key is pressed, anywhere in the Samantha interface, the loading/processing/generation phases will begin.
The pop-up window generated by the matplotlib module must be closed for the program to continue running.
Whenever you save a new model on your computer, you must click on the "Load Model" button and select the folder where it is located so that it appears in the model selection dropdown.
Changes made to the fields and interface settings during the model download and loading, processing and token generation will only be made the next time the Start Chat button or the ENTER key is pressed.
To follow the text generation on the screen, click inside the Assistant output field and press the Page Down key until you see the end of the text being generated by the model.
You can use Windows keyboard shortcuts inside fields: CTRL + A (select all text) , CTRL + C (copy text), CTRL + V (paste copied text) and CTRL + Z (undo) etc.
To reload the browser tab, press F5 and Clear history button. This procedure will reset all fields and settings of the interface. If there was a model loaded via URL, it will remain loaded and accessible in the Select model dropdown list as MODEL_FOR_TESTING (no need to re-download).
If you accidentally close Samantha's browser tab, open a new tab and type localhost to display the full local URL: http://localhost:7860/?__theme=dark . In this case, Samantha's server must be running.
When generating code incrementally, divide the user prompt into parts separated by $$$ that generate blocks of code that complement each other.
Samantha is being developed under the principles of Open Science (open methodology, open source, open data, open access, open peer review and open educational resources) and and MIT License. Therefore, anyone can contribute to its improvement.
Feel free to share your ideas with us!
?️ Code Versions:
Version 0.6.0 (2025-02-01):
Version 0.5.0 (2025-01-08):
Version 0.4.0 (2024-12-30):
Version 0.3.0 (2024-10-29):
.exe ) from the code generated by the model, using Auto-Py-To-Exe library.Version 0.2.0 (2024-10-14):
Version 0.1.0 (2024-09-01):
Future improvements:
Suggestions are always welcome!


