model_server
ver 2024.5
Model Server托管模型,并使它们可以通过标准网络协议可以通过软件组件访问:客户端将请求发送到模型服务器,该模型服务器执行模型推理并将响应发送回客户端。 Model Server为有效的模型部署提供了许多优势:
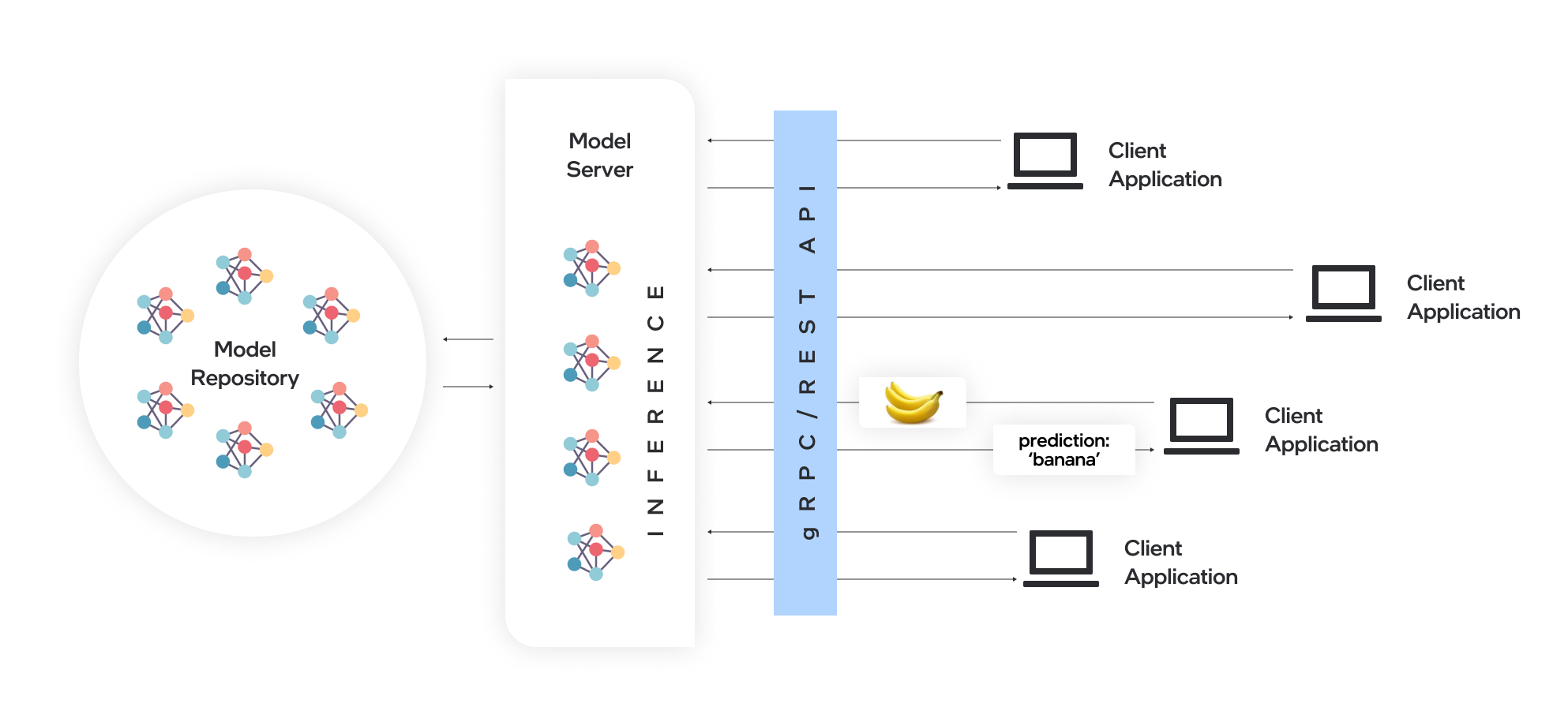
OpenVino™Model Server(OVM)是用于服务模型的高性能系统。该模型服务器在C ++中实现,以用于可扩展性,并针对英特尔体系结构进行了优化,在应用OpenVino进行推理执行时,使用了与TensorFlow Serving和Kserve相同的体系结构和API。推理服务是通过GRPC或REST API提供的,使部署新算法和AI实验变得容易。
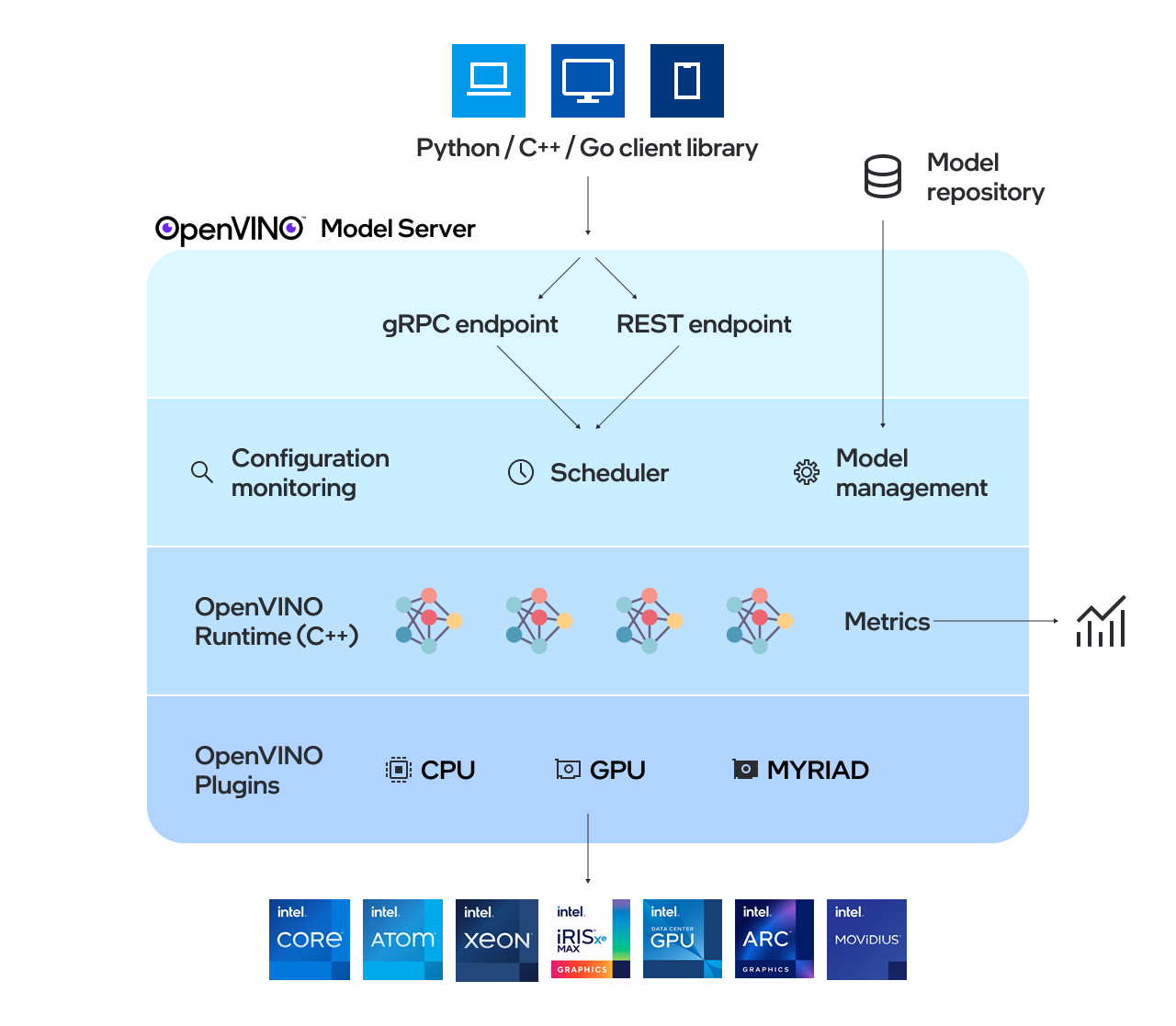
服务器使用的模型需要在本地存储或通过对象存储服务远程托管。有关更多详细信息,请参阅准备模型存储库文档。模型服务器在Docker容器,裸机和Kubernetes环境中的工作。从QuickStart指南或探索模型服务器功能中使用OpenVino Model Server使用OpenVino Model Server。
阅读发行说明以找出什么新功能。
注意: OVM已在Redhat和Ubuntu上进行了测试。最新发布的Docker图像基于Ubuntu和Ubi。它们存储在:
有关如何使用OpenVino Model Server的演示,可以在我们的Vision用例和LLM文本生成的快速启动指南中找到。有关在各种情况下使用Model Server的更多信息,您可以检查以下指南:
模型存储库配置
部署选项
性能调整
定向无环形图调度程序
自定义节点开发
服务状态模型
使用kubernetes头盔图表部署
使用Kubernetes操作员部署
使用二进制输入数据
OpenVino™
TensorFlow服务
grpc
宁静的API
基准测试结果
跨多个体系结构 - 网络研讨会记录的速度和规模AI推理操作
OpenVino Model Server C ++中的新事物是什么
Capital Health通过AI-用例示例改善了中风护理
如果您有问题,功能请求或错误报告,请随时提交GitHub问题。
*其他名称和品牌可能被称为他人的财产。


