model_server
ver 2024.5
Le serveur modèle héberge les modèles et les rend accessibles aux composants logiciels sur les protocoles réseau standard: un client envoie une demande au serveur de modèles, qui effectue l'inférence du modèle et renvoie une réponse au client. Model Server offre de nombreux avantages pour un déploiement de modèles efficace:
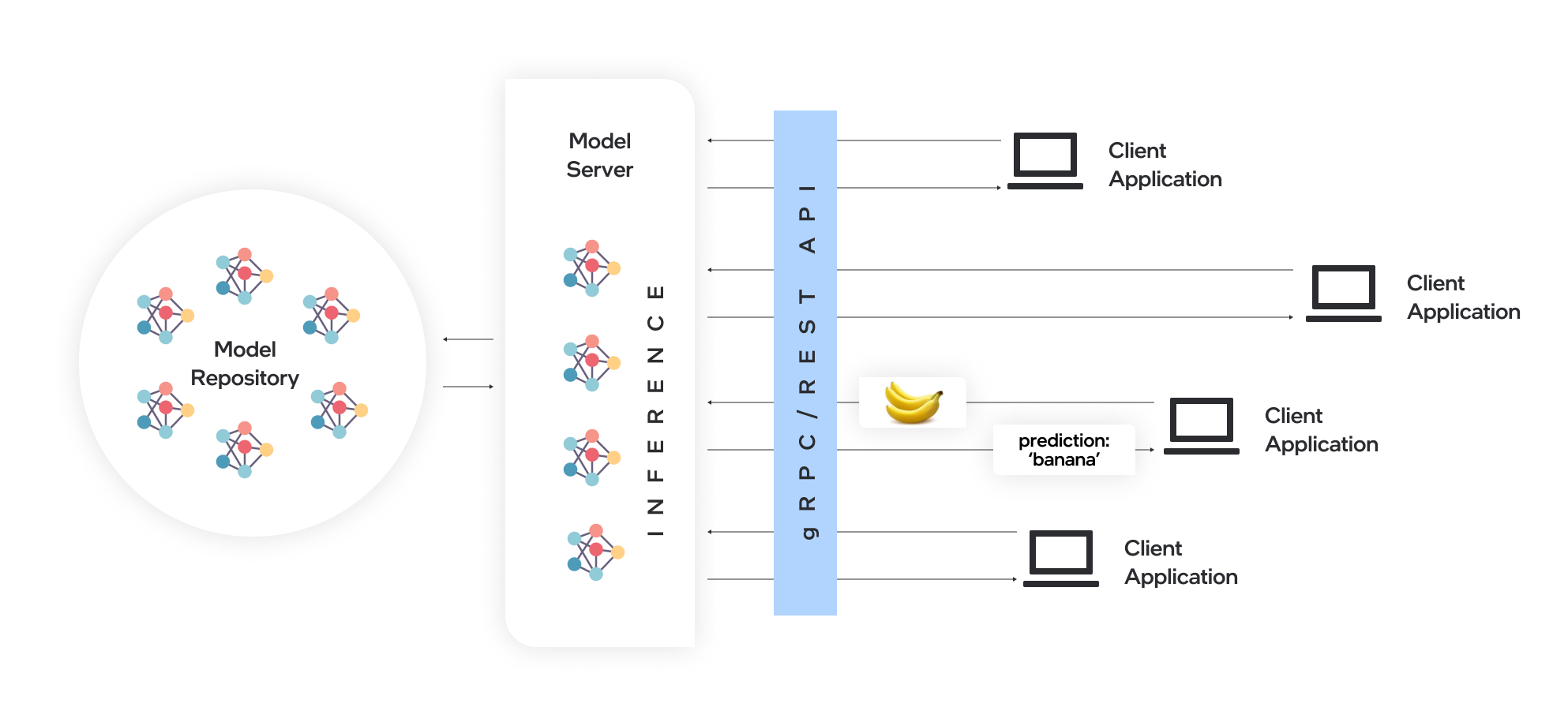
OpenVino ™ Model Server (OVMS) est un système haute performance pour les modèles de service. Implémenté en C ++ pour l'évolutivité et optimisé pour le déploiement sur les architectures Intel, le serveur modèle utilise la même architecture et l'API que TensorFlow Serving et KServe lors de l'application d'OpenVino pour l'exécution d'inférence. Le service d'inférence est fourni via l'API GRPC ou REST, facilitant le déploiement de nouveaux algorithmes et des expériences d'IA.
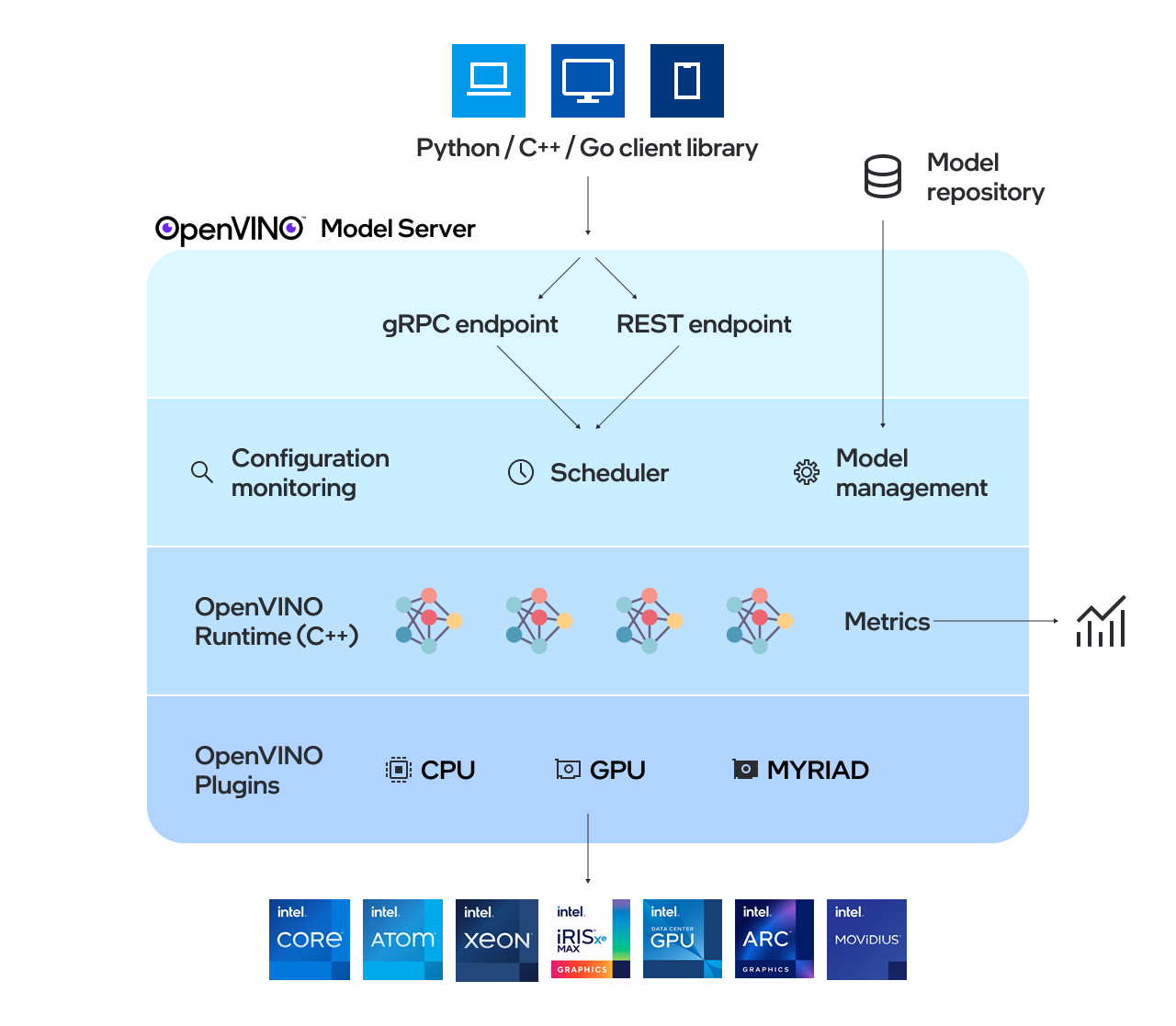
Les modèles utilisés par le serveur doivent être stockés localement ou hébergés à distance par les services de stockage d'objets. Pour plus de détails, reportez-vous à la préparation de la documentation du référentiel du modèle. Model Server fonctionne à l'intérieur des conteneurs Docker, sur le métal nu et dans l'environnement Kubernetes. Commencez à utiliser OpenVino Model Server avec un exemple de service rapide à partir du guide QuickStart ou explorez les fonctionnalités du serveur de modèles.
Lisez les notes de publication pour découvrir ce qui est nouveau.
Remarque: OVMS a été testé sur Redhat et Ubuntu. Les dernières images Docker publiées publiques sont basées sur Ubuntu et UBI. Ils sont stockés dans:
Une démonstration sur la façon d'utiliser le serveur de modèles OpenVino peut être trouvée dans notre guide rapide pour le cas d'utilisation de la vision et la génération de texte LLM. Pour plus d'informations sur l'utilisation du serveur Model dans divers scénarios, vous pouvez vérifier les guides suivants:
Configuration du référentiel du modèle
Options de déploiement
Réglage des performances
Planificateur de graphiques acycliques réalisé
Développement des nœuds personnalisés
Servir des modèles avec état
Déployer à l'aide d'un graphique de casque Kubernetes
Déploiement à l'aide de l'opérateur de Kubernetes
En utilisant des données d'entrée binaires
OpenVino ™
Tensorflow Service
grpc
API RESTFUL
Benchmarking Résultats
Vitesse et échelle des opérations d'inférence AI sur plusieurs architectures - enregistrement du webinaire
Quoi de neuf dans OpenVino Model Server C ++
Capital Health améliore les soins aux AVC avec l'IA - Exemple de cas d'utilisation
Si vous avez une question, une demande de fonctionnalité ou un rapport de bogue, n'hésitez pas à soumettre un problème GitHub.
* D'autres noms et marques peuvent être revendiqués comme la propriété d'autres.


