model_server
ver 2024.5
O Model Server hospeda modelos e os torna acessíveis a componentes de software em protocolos de rede padrão: um cliente envia uma solicitação para o servidor de modelos, que executa a inferência do modelo e envia uma resposta de volta ao cliente. O Model Server oferece muitas vantagens para implantação eficiente de modelos:
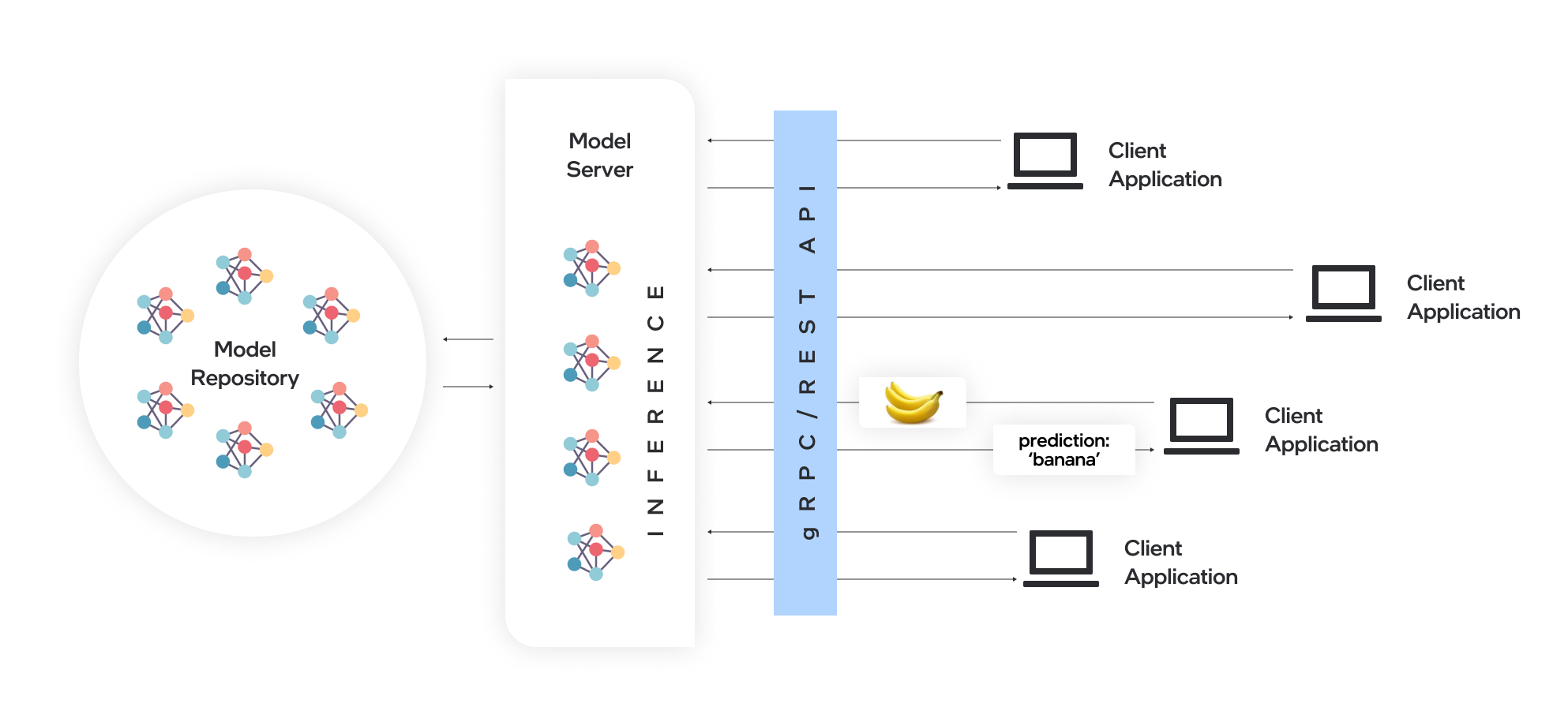
O OpenVino ™ Model Server (OVMS) é um sistema de alto desempenho para servir modelos. Implementado em C ++ para escalabilidade e otimizado para implantação em arquiteturas Intel, o Model Server usa a mesma arquitetura e API que o Tensorflow Serving e o Kserve enquanto aplica o OpenVino para execução de inferência. O serviço de inferência é fornecido via API GRPC ou REST, facilitando a implantação de novos algoritmos e experimentos de IA.
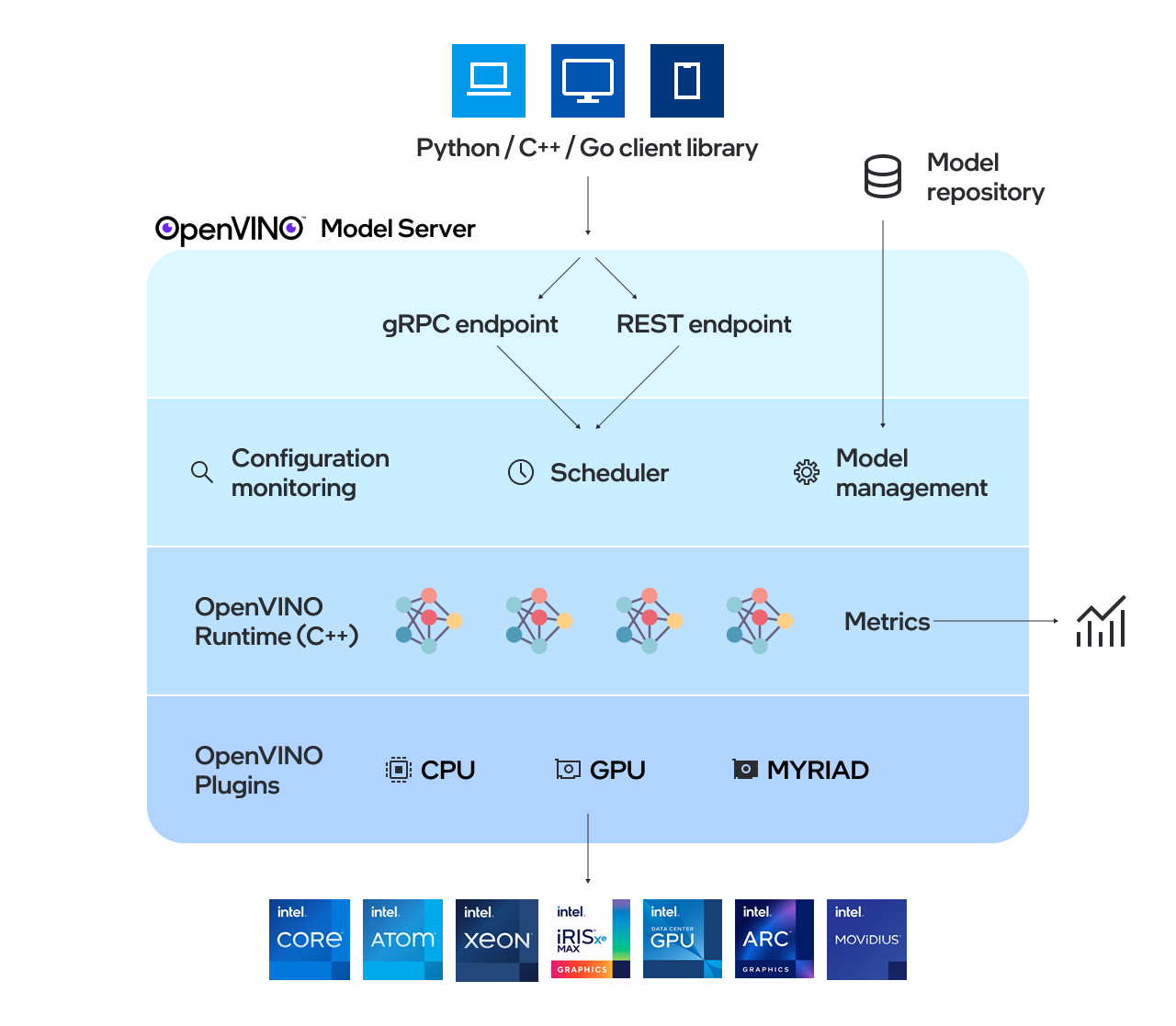
Os modelos usados pelo servidor precisam ser armazenados localmente ou hospedados remotamente por serviços de armazenamento de objetos. Para obter mais detalhes, consulte a preparação da documentação do repositório de modelos. O Model Server funciona dentro dos contêineres do Docker, no ambiente bare metal e no Kubernetes. Comece a usar o OpenVino Model Server com um exemplo de porção de avanço rápido dos recursos do QuickStart Guide ou Explore Model Server.
Leia as notas de lançamento para descobrir o que há de novo.
Nota: OVMS foi testado no Redhat e Ubuntu. As mais recentes imagens do Docker divulgadas publicamente são baseadas no Ubuntu e no UBI. Eles são armazenados em:
Uma demonstração sobre como usar o OpenVino Model Server pode ser encontrada em nosso guia de partida rápida para o caso de uso da visão e a geração de texto LLM. Para obter mais informações sobre o uso do Model Server em vários cenários, você pode verificar os seguintes guias:
Configuração do repositório de modelos
Opções de implantação
Ajuste de desempenho
Agendador de gráficos aciclicos direcionados
Desenvolvimento de nós personalizados
Servindo modelos com estado
Implantar usando um gráfico de comando Kubernetes
Implantação usando o operador Kubernetes
Usando dados de entrada binária
Openvino ™
Serviço Tensorflow
GRPC
API repouso
Resultados de benchmarking
Velocidade e escala de operações de inferência de AI em várias arquiteturas - gravação de webinar
O que há de novo no servidor de modelos Openvino C ++
A Capital Health melhora o atendimento de AI com AI - exemplo de caso de uso
Se você tiver uma pergunta, uma solicitação de recurso ou um relatório de bug, fique à vontade para enviar um problema do GitHub.
* Outros nomes e marcas podem ser reivindicados como propriedade de outros.


