model_server
ver 2024.5
El servidor de modelos aloja modelos y los hace accesibles para los componentes de software a través de los protocolos de red estándar: un cliente envía una solicitud al servidor de modelos, que realiza una inferencia del modelo y envía una respuesta al cliente. Model Server ofrece muchas ventajas para la implementación de modelos eficiente:
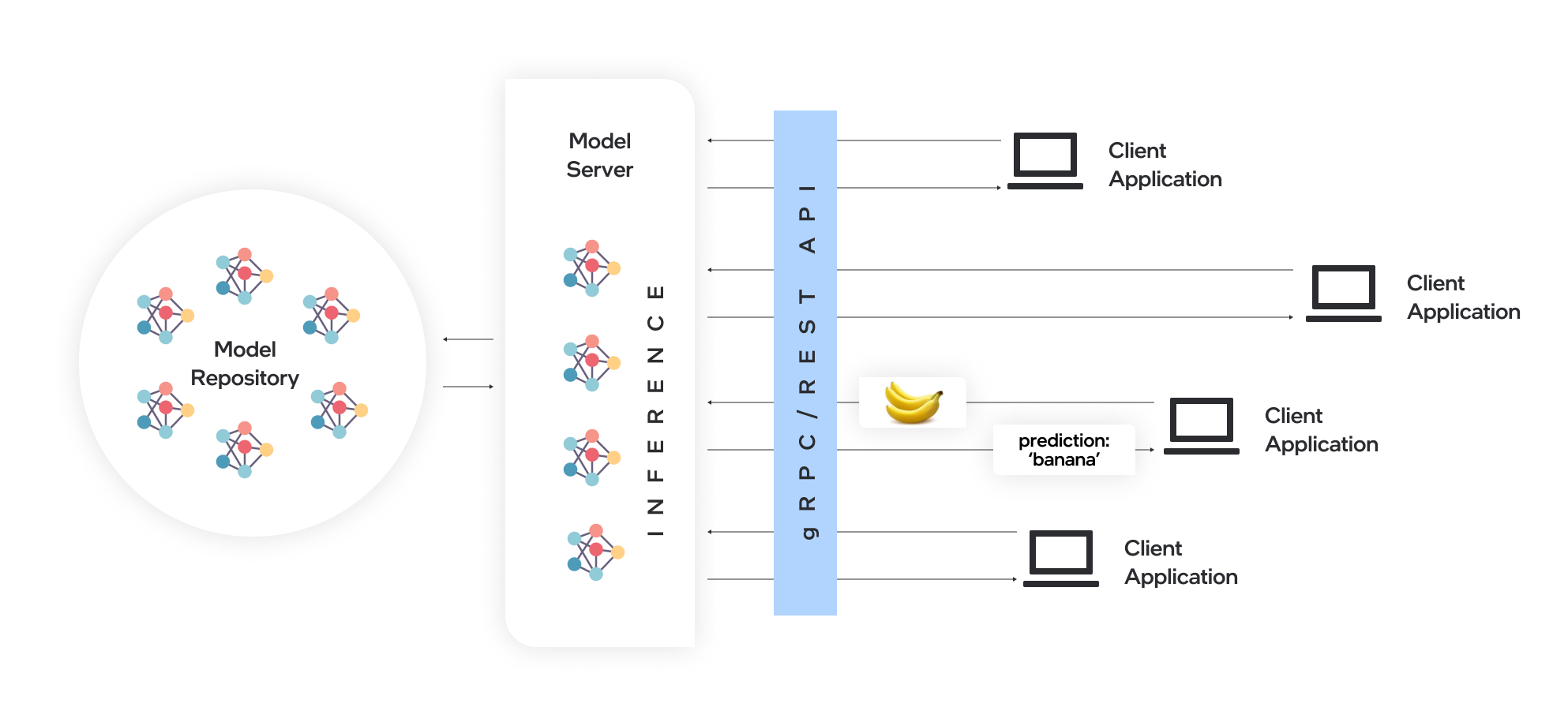
OpenVino ™ Model Server (OVMS) es un sistema de alto rendimiento para servir modelos. Implementado en C ++ para la escalabilidad y optimizado para la implementación en las arquitecturas Intel, el servidor de modelos utiliza la misma arquitectura y API que TensorFlow Serving y KServe al aplicar OpenVino para la ejecución de inferencia. El servicio de inferencia se proporciona a través de GRPC o API REST, lo que facilita la implementación de nuevos algoritmos y experimentos de IA.
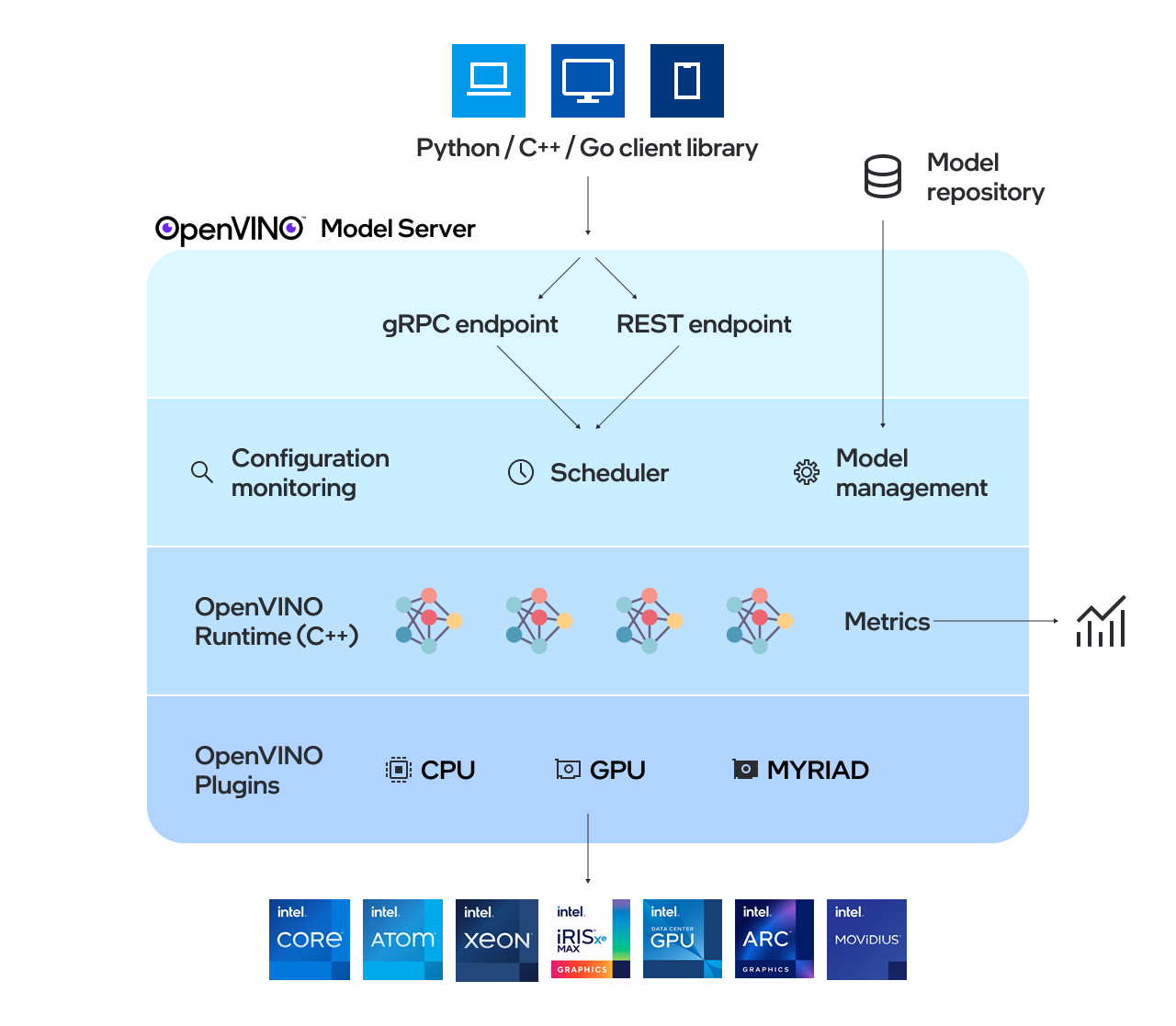
Los modelos utilizados por el servidor deben almacenarse localmente o alojados de forma remota por los servicios de almacenamiento de objetos. Para obtener más detalles, consulte la preparación de la documentación del repositorio de modelos. El servidor de modelos funciona dentro de los contenedores Docker, en el metal desnudo y en el entorno Kubernetes. Comience a usar el servidor de modelos OpenVino con un ejemplo de servicio rápido desde la guía QuickStart o explore las funciones del servidor de modelos.
Lea las notas de la versión para averiguar qué hay de nuevo.
Nota: OVMS ha sido probado en Redhat y Ubuntu. Las últimas imágenes de Docker publicadas públicamente se basan en Ubuntu y Ubi. Se almacenan en:
Puede encontrar una demostración sobre cómo usar el servidor de modelos OpenVino en nuestra guía de inicio rápido para el caso de uso de la visión y la generación de texto LLM. Para obtener más información sobre el uso del servidor de modelos en varios escenarios, puede verificar las siguientes guías:
Configuración del repositorio de modelos
Opciones de implementación
Ajuste de rendimiento
Programador de gráficos acíclicos dirigidos
Desarrollo de nodos personalizados
Sirviendo modelos con estado
Implementar usando un gráfico de timón de Kubernetes
Implementación utilizando el operador de Kubernetes
Uso de datos de entrada binaria
OpenVino ™
TensorFlow Serving
GRPC
API de reposo
Resultados de la evaluación comparativa
Operaciones de inferencia de IA de velocidad y escala en múltiples arquitecturas: grabación de seminarios web
¿Qué hay de nuevo en el servidor de modelos OpenVino C ++?
Capital Health mejora la atención de accidente cerebrovascular con IA - Ejemplo de caso de uso
Si tiene una pregunta, una solicitud de función o un informe de errores, no dude en enviar un problema de GitHub.
* Otros nombres y marcas pueden ser reclamados como propiedad de otros.


