LoGU
1.0.0
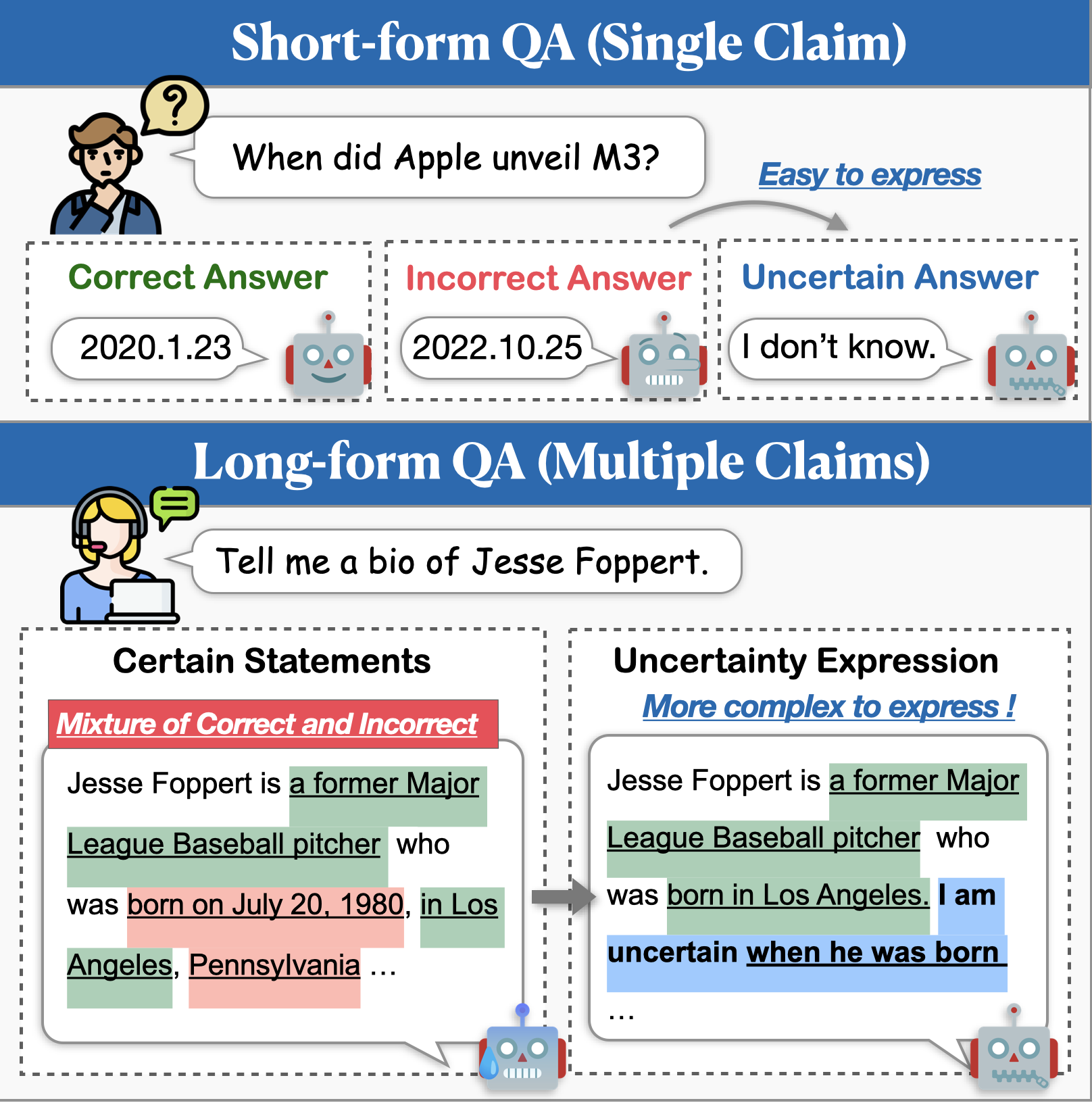
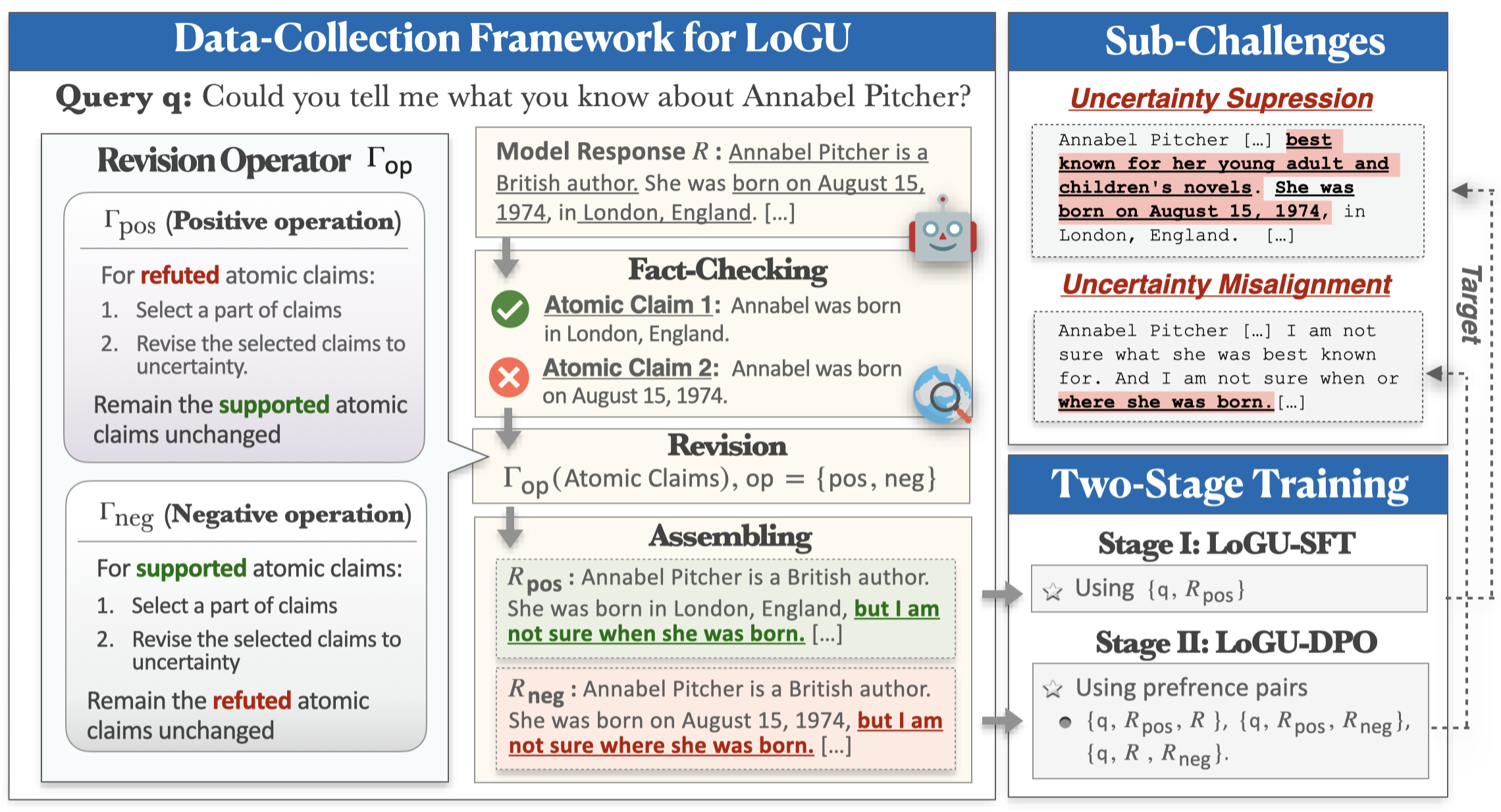
ในขณะที่แบบจำลองภาษาขนาดใหญ่ (LLMS) แสดงให้เห็นถึงความสามารถที่น่าประทับใจพวกเขายังคงต่อสู้กับการสร้างเนื้อหาที่ไม่ถูกต้องตามความเป็นจริง (เช่นภาพหลอน) วิธีการที่มีแนวโน้มในการบรรเทาปัญหานี้คือการเปิดใช้งานแบบจำลองเพื่อแสดงความไม่แน่นอนเมื่อไม่แน่ใจ การวิจัยก่อนหน้านี้เกี่ยวกับการสร้างแบบจำลองความไม่แน่นอนได้มุ่งเน้นไปที่ QA ระยะสั้นเป็นหลัก แต่แอปพลิเคชันในโลกแห่งความเป็นจริงมักต้องการการตอบสนองที่ยาวนานขึ้น ในงานนี้เราแนะนำภารกิจของการสร้างแบบยาวด้วยความไม่แน่นอน (logu) เราระบุความท้าทายที่สำคัญสองประการคือ การปราบปรามความไม่แน่นอน ซึ่งแบบจำลองลังเลที่จะแสดงความไม่แน่นอนและ การเยื้องศูนย์ไม่แน่นอน ซึ่งแบบจำลองถ่ายทอดความไม่แน่นอนอย่างไม่ถูกต้อง
เพื่อจัดการกับความท้าทายเหล่านี้เราเสนอกรอบการรวบรวมข้อมูลแบบปรับแต่งและท่อฝึกอบรมสองขั้นตอน กรอบการทำงานของเราใช้กลยุทธ์การแบ่งแยกและพิชิตการปรับความไม่แน่นอนตามการเรียกร้องของอะตอม ข้อมูลที่เก็บรวบรวมจะถูกใช้ในการฝึกอบรมผ่านการปรับแต่งการปรับแต่ง (SFT) และการเพิ่มประสิทธิภาพการตั้งค่าโดยตรง (DPO) เพื่อเพิ่มการแสดงออกที่ไม่แน่นอน การทดลองอย่างกว้างขวางเกี่ยวกับการเรียนการสอนแบบยาวสามชุดตามชุดข้อมูลแสดงให้เห็นว่าวิธีการของเราช่วยเพิ่มความแม่นยำอย่างมีนัยสำคัญลดภาพหลอนและรักษาความครอบคลุมของการตอบสนอง
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้งสภาพแวดล้อมสำหรับ logu:
conda create -n LoGU python==3.8
conda activate LoGU
pip install -r lf_requirements.txt
pip install -r vllm_requirements.txtลองใช้คำสั่งต่อไปนี้เพื่อทดสอบวิธีการของเราเกี่ยวกับ BIOS, LongFact, Wildhallu:
cd ./scripts
bash generate_vllm_responses.shbash eval_pipeline.shbash generate_unc_answers.sh
bash factcheck_unc_answers.shเร็วๆ นี้!
นอกจากนี้เรายังให้แบบจำลองการแสดงออกที่ไม่แน่นอนบนฮับโมเดล HuggingFace สำหรับ Fast Trail:
| แบบอย่าง | การเชื่อมโยง |
|---|---|
| rhyang2021/unclem_llama3_8b | กอด |
| rhyang2021/unclem_mistral_7b | กอด |
หากคุณมีคำถามใด ๆ โปรดส่งอีเมลถึงฉันหรือส่งปัญหาให้ฉัน


