การสำรวจ SLM
การสำรวจแบบจำลองภาษาขนาดเล็กที่ครอบคลุม: เทคโนโลยีแอพพลิเคชั่นในอุปกรณ์ประสิทธิภาพการปรับปรุง LLMS และความน่าเชื่อถือ
repo นี้รวมถึงเอกสารที่กล่าวถึงในรายงานการสำรวจล่าสุดของเราเกี่ยวกับรูปแบบภาษาขนาดเล็ก
อ่านกระดาษฉบับเต็มได้ที่นี่: ลิงค์กระดาษ
ข่าว
- 2024/11/04: รุ่นแรกของการสำรวจของเราอยู่ที่ Arxiv!
อ้างอิง
หากการสำรวจของเรามีประโยชน์สำหรับการวิจัยของคุณโปรดอ้างอิงบทความของเรา:
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
ภาพรวมของ SLMS
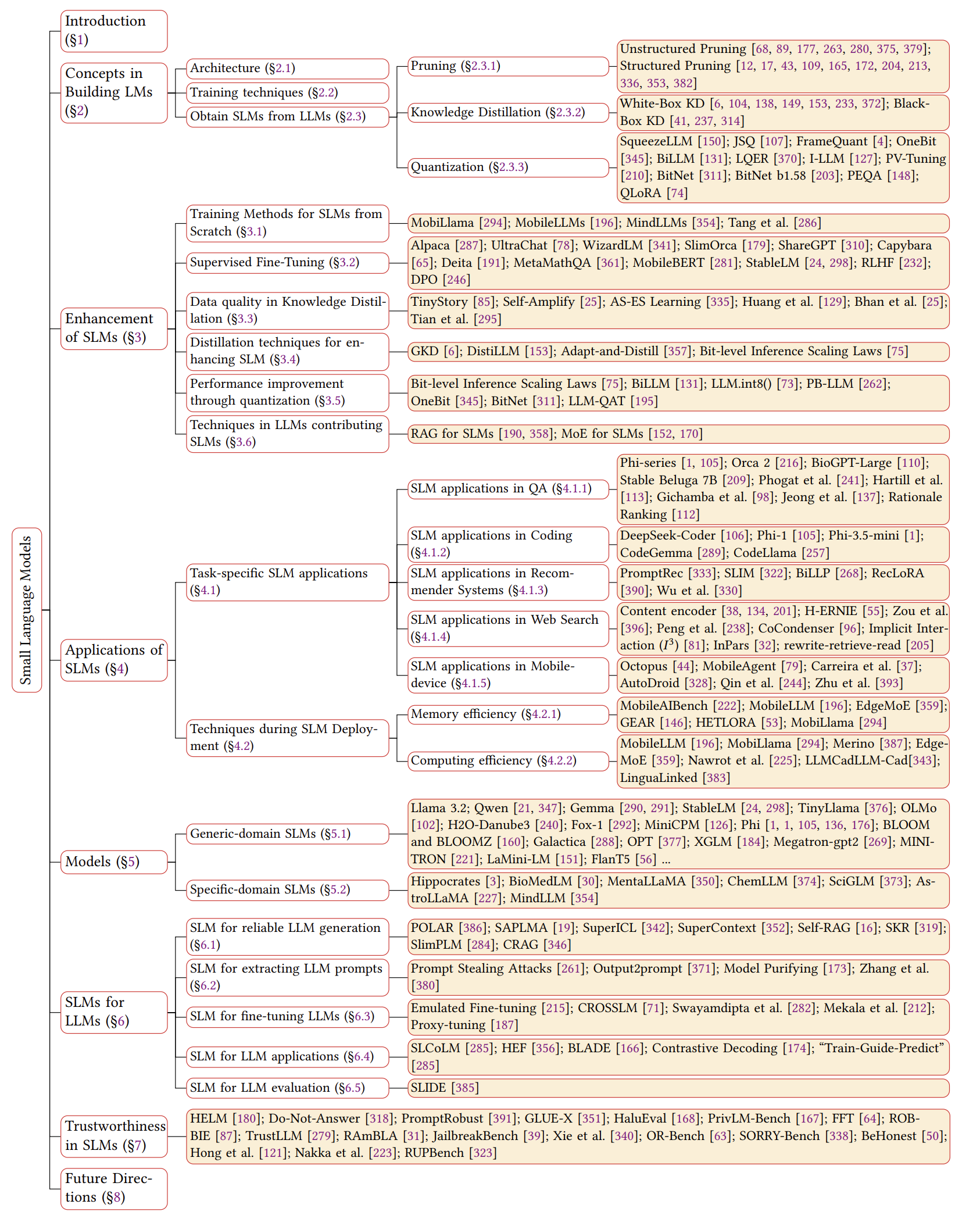
ไทม์ไลน์ของ SLMS
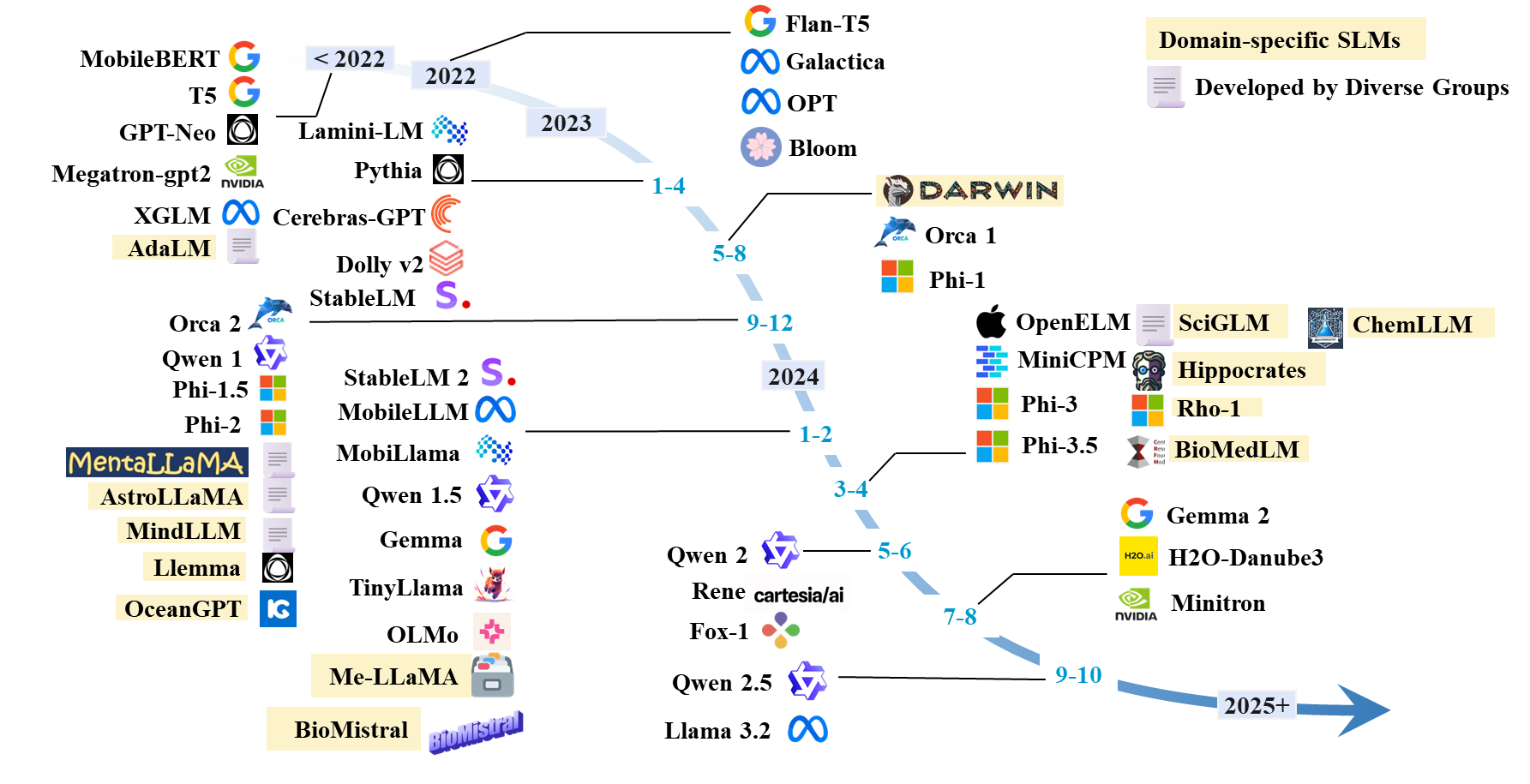
รายการกระดาษ SLMS
SLM ที่มีอยู่
| แบบอย่าง | #params | วันที่ | กระบวนทัศน์ | โดเมน | รหัส | รุ่น HF | กระดาษ/บล็อก |
|---|
| ลามะ 3.2 | 1B; 3B | 2024.9 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | บล็อก |
| Qwen 1 | 1.8b; 7b; 14b; 72b | 2023.12 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| Qwen 1.5 | 0.5B; 1.8b; 4b; 7b; 14b; 32B; 72b | 2024.2 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| Qwen 2 | 0.5B; 1.5B; 7b; 57b; 72b | 2024.6 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| Qwen 2.5 | 0.5B; 1.5B; 3B; 7b; 14b; 32B; 72b | 2024.9 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| อัญมณี | 2b; 7b | 2024.2 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| เจมม่า 2 | 2b; 9b; 27b | 2024.7 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| H2O-Danube3 | 500m; 4B | 2024.7 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| llm-neo | 1B | 2024.11 | การฝึกอบรมอย่างต่อเนื่อง | ทั่วไป | | HF | กระดาษ |
| FOX-1 | 1.6b | 2024.6 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | บล็อก |
| เรน | 1.3b | 2024.5 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| MINICPM | 1.2b; 2.4b | 2024.4 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| โอเลโม | 1B; 7b | 2024.2 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| tinyllama | 1B | 2024.1 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| PHI-1 | 1.3b | 2023.6 | การฝึกอบรมล่วงหน้า | การเข้ารหัส | | HF | กระดาษ |
| phi-1.5 | 1.3b | 2023.9 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| Phi-2 | 2.7B | 2023.12 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| Phi-3 | 3.8b; 7b; 14b | 2024.4 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| Phi-3.5 | 3.8b; 4.2b; 6.6b | 2024.4 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| Openelm | 270m; 450m; 1.1b; 3B | 2024.4 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| mobillama | 0.5B; 0.8b | 2024.2 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| โมบิลเลลล์ | 125m; 350m | 2024.2 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| Stablelm | 3B; 7b | 2023.4 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| Stablelm 2 | 1.6b | 2024.2 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| cerebras-gpt | 111m-13b | 2023.4 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| Bloom, Bloomz | 560m; 1.1b; 1.7b; 3B; 7.1b; 176b | 2022.11 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| เลือก | 125m; 350m; 1.3b; 2.7b; 5.7b | 2022.5 | การฝึกอบรมล่วงหน้า | ทั่วไป | | HF | กระดาษ |
| XGLM | 1.7b; 2.9b; 7.5b | 2021.12 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| Gpt-neo | 125m; 350m; 1.3b; 2.7B | 2021.5 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | | กระดาษ |
| megatron-gpt2 | 355m; 2.5b; 8.3b | 2019.9 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | | กระดาษบล็อก |
| minitron | 4b; 8b; 15b | 2024.7 | การตัดแต่งกิ่งและการกลั่น | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| ขั้นต่ำสุด | 7b | 2024.7 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| minima-2 | 1B; 3B | 2023.12 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| น้อยที่สุด | 3B | 2023.11 | การตัดแต่งกิ่งและการกลั่น | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
| orca 2 | 7b | 2023.11 | การกลั่น | ทั่วไป | | HF | กระดาษ |
| Dolly-V2 | 3B; 7b; 12b | 2023.4 | คำแนะนำการปรับแต่ง | ทั่วไป | คนอื่น ๆ | HF | บล็อก |
| Lamini-LM | 61m-7b | 2023.4 | การกลั่น | ทั่วไป | คนอื่น ๆ | HF | บล็อก |
| flant5 พิเศษ 5 | 250m; 760m; 3B | 2023.1 | คำแนะนำการปรับแต่ง | ทั่วไป (คณิตศาสตร์) | คนอื่น ๆ | - | กระดาษ |
| Flant5 | 80m; 250m; 780m; 3B | 2022.10 | คำแนะนำการปรับแต่ง | ทั่วไป | Gihub | HF | กระดาษ |
| T5 | 60m; 220 เมตร; 770m; 3B; 11b | 2019.9 | การฝึกอบรมล่วงหน้า | ทั่วไป | คนอื่น ๆ | HF | กระดาษ |
สถาปัตยกรรม SLM
- Transformer: ความสนใจคือสิ่งที่คุณต้องการ Ashish Vaswani Neurips 2017
- MAMBA 1: MAMBA: การสร้างแบบจำลองลำดับเวลาเชิงเส้นด้วยช่องว่างสถานะที่เลือก Albert Gu และ Tri Dao Colm 2024. [กระดาษ]
- MAMBA 2: Transformers เป็น SSMS: แบบจำลองทั่วไปและอัลกอริทึมที่มีประสิทธิภาพผ่านความเป็นคู่พื้นที่สถานะสถานะ Tri Dao และ Albert Gu ICML 2024. [กระดาษ] [รหัส]
การเพิ่มประสิทธิภาพสำหรับ SLM
การฝึกอบรมตั้งแต่เริ่มต้น
- MOBILLAMA: "MOBILLAMA: ไปสู่ GPT ที่แม่นยำและมีน้ำหนักเบาอย่างเต็มที่" Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan Arxiv 2024. [กระดาษ] [GitHub] [HuggingFace]
- Mobilellm: "Mobilellm: การเพิ่มประสิทธิภาพแบบจำลองภาษาพารามิเตอร์แบบพารามิเตอร์ย่อยสำหรับกรณีการใช้งานบนอุปกรณ์" Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra Icml 2024
- ทบทวนการเพิ่มประสิทธิภาพและสถาปัตยกรรมสำหรับรุ่นภาษาเล็ก ๆ Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han และ Yunhe Wang ICML 2024. [กระดาษ] [รหัส]
- Mindllm: "Mindllm: การฝึกอบรมแบบจำลองภาษาขนาดใหญ่ที่มีน้ำหนักเบาก่อนเริ่มต้นการประเมินและแอปพลิเคชันโดเมน" Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, Yang Gao Arxiv 2023. [กระดาษ] [HuggingFace]
มีการปรับแต่งการปรับแต่ง
- การเพิ่มประสิทธิภาพการตั้งค่าโดยตรง: แบบจำลองภาษาของคุณเป็นแบบจำลองรางวัล Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon และ Chelsea Finn Neurips, 2024. [กระดาษ] [รหัส]
- เพิ่มรูปแบบภาษาแชทโดยการปรับขนาดการสนทนาการเรียนการสอนคุณภาพสูง Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun และ Bowen Zhou EMNLP 2023. [กระดาษ] [รหัส]
- SLIMORCA: ชุดข้อมูลแบบเปิดของร่องรอยการให้เหตุผลที่เพิ่มขึ้นของ GPT-4 GPT-4 พร้อมการตรวจสอบ Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong และ "Teknium" HuggingFace, 2023. [ข้อมูล]
- Stanford Alpaca: โมเดล Llama ตามคำแนะนำ Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang และ Tatsunori B. Hashimoto GitHub, 2023. [บล็อก] [GitHub] [HuggingFace]
- OpenChat: การพัฒนาโมเดลภาษาโอเพนซอร์ซด้วยข้อมูลคุณภาพผสม Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song และ Yang Liu ICLR, 2024. [กระดาษ] [รหัส] [HuggingFace]
- แบบจำลองภาษาการฝึกอบรมเพื่อทำตามคำแนะนำด้วยความคิดเห็นของมนุษย์ Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller Leike, Ryan Lowe Neurips, 2022. [กระดาษ]
- RLHF: "แบบจำลองภาษาการฝึกอบรมเพื่อทำตามคำแนะนำกับข้อเสนอแนะของมนุษย์" Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller Ryan Lowe 2022. [กระดาษ]
- Mobile Bert: "Mobile Bert: Bert ที่มีความคิดมากในการทำงานสำหรับอุปกรณ์ จำกัด ทรัพยากร" Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou ACL 2020. [กระดาษ] [GitHub] [HuggingFace]
- แบบจำลองภาษาเป็นผู้เรียนมัลติทาสก์ที่ไม่ได้รับการดูแล Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever Openai Blog, 2019. [Paper]
คุณภาพข้อมูลใน KD
- Tinystory: "Tinystories: โมเดลภาษาเล็กแค่ไหนและยังพูดภาษาอังกฤษที่สอดคล้องกันได้?" - Ronen Eldan, Yuanzhi Li 2023. [กระดาษ] [HuggingFace]
- AS-ES: "AS-ES การเรียนรู้: ไปสู่การเรียนรู้ COT ที่มีประสิทธิภาพในรูปแบบขนาดเล็ก" Nuwa XI, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu 2024. [กระดาษ]
- การขยายตัวด้วยตนเอง: "การขยายตัวเอง: การปรับปรุงแบบจำลองภาษาขนาดเล็กด้วยคำอธิบายโพสต์เองโพสต์เอง" Milan Bhan, Jean-Noel Vittaut, Nicolas Chesneau, Marie-Jeanne Lesot 2024. [กระดาษ]
- แบบจำลองภาษาขนาดใหญ่สามารถปรับปรุงตนเองได้ Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu และ Jiawei Han EMNLP 2023. [กระดาษ]
- สู่การพัฒนาตนเองของ LLMs ผ่านการจินตนาการการค้นหาและการวิพากษ์วิจารณ์ Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao MI และ Dong Yu Neurips 2024. [กระดาษ] [รหัส]
การกลั่นสำหรับ SLM
- GKD: "การกลั่นตามนโยบายของแบบจำลองภาษา: การเรียนรู้จากความผิดพลาดที่สร้างขึ้นเอง" Rishabh Agarwal และคณะ ICLR 2024. [กระดาษ]
- Distilllm: "Distillm: ไปสู่การกลั่นที่คล่องตัวสำหรับรุ่นภาษาขนาดใหญ่" Jongwoo Ko และคณะ ICML 2024. [กระดาษ] [GitHub]
- Adapt-and-Distill: "Adapt-and-Distill: การพัฒนาแบบจำลองภาษาที่มีขนาดเล็กเร็วและมีประสิทธิภาพสำหรับโดเมน" Yunzhi Yao และคณะ ACL2021 [กระดาษ] [GitHub]
- AKL: "การทบทวน Kullback-Leibler Divergence ในการกลั่นความรู้สำหรับแบบจำลองภาษาขนาดใหญ่" Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, Ngai Wong Arxiv 2024. [กระดาษ] [GitHub]
- การกลั่นด้วยน้ำหนักตัวสำหรับการบีบอัดเบิร์ตงานที่ไม่เชื่อเรื่องพระเจ้า Taiqiang Wu, Cheng Hou, Shanshan Lao, Jiayi Li, Ngai Wong, Zhe Zhao, Yujiu Yang Naacl, 2024, [กระดาษ] [รหัส]
การวัดปริมาณ
- Smoothquant: "Smoothquant: การหาปริมาณหลังการฝึกอบรมที่แม่นยำและมีประสิทธิภาพสำหรับรุ่นภาษาขนาดใหญ่" Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han ICML 2023. [กระดาษ] [GitHub] [สไลด์] [วิดีโอ]
- Billm: "Billm: ผลักขีด จำกัด ของการฝึกอบรมหลังการฝึกอบรมสำหรับ LLMS" Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi 2024. [กระดาษ] [GitHub]
- LLM-QAT: "LLM-QAT: การฝึกอบรมเชิงปริมาณที่ปราศจากข้อมูลสำหรับแบบจำลองภาษาขนาดใหญ่" Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra 2023. [กระดาษ]
- PB-LLM: "PB-LLM: โมเดลภาษาขนาดใหญ่สองส่วน" Zhihang Yuan, Yuzhang Shang, Zhen Dong ICLR 2024. [กระดาษ] [GitHub]
- OneBit: "OneBit: ไปสู่รูปแบบภาษาขนาดใหญ่ที่ต่ำมาก" Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che Neurips 2024. [กระดาษ]
- Bitnet: "Bitnet: ปรับขนาดหม้อแปลง 1 บิตสำหรับรุ่นภาษาขนาดใหญ่" Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao MA, แฟน Yang, Ruiping Wang, Yi Wu, Furu Wei 2023. [กระดาษ]
- Bitnet B1.58: "ยุคของ LLM 1 บิต: รุ่นภาษาขนาดใหญ่ทั้งหมดอยู่ใน 1.58 บิต" Shuming Ma, Hongyu Wang, Lingxiao MA, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei 2024. [กระดาษ]
- Squeezellm: "Squeezellm: Quantization หนาแน่น-และ sparse" Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer ICML 2024. [กระดาษ] [GitHub]
- JSQ: "การบีบอัดแบบจำลองภาษาขนาดใหญ่โดยการกระจายและการหาปริมาณ" Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, Xianglong Liu ICML 2024. [กระดาษ] [GitHub]
- Framequant: "Framequant: การหาปริมาณบิตต่ำที่ยืดหยุ่นสำหรับหม้อแปลง" Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh 2024. [กระดาษ] [GitHub]
- Billm: "Billm: ผลักขีด จำกัด ของการฝึกอบรมหลังการฝึกอบรมสำหรับ LLMS" Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi 2024. [กระดาษ] [GitHub]
- LQER: "LQER: การสร้างข้อผิดพลาดเชิงปริมาณระดับต่ำสำหรับ LLMS" Cheng Zhang, Jianyi Cheng, George A. Constantinides, Yiren Zhao ICML 2024. [กระดาษ] [GitHub]
- i-llm: "i-llm: การอนุมานจำนวนเต็มอย่างมีประสิทธิภาพอย่างเดียวสำหรับแบบจำลองภาษาขนาดใหญ่บิตต่ำที่มีค่าไม่แน่นอน" Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou 2024. [กระดาษ] [GitHub]
- PV-tuning: "PV-tuning: นอกเหนือจากการประเมินแบบตรงผ่านสำหรับการบีบอัด LLM ที่รุนแรง" Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik 2024. [กระดาษ]
- PEQA: "การปรับแต่งหน่วยความจำอย่างละเอียดของโมเดลภาษาขนาดใหญ่ที่บีบอัดผ่านปริมาณจำนวนเต็มย่อย 4 บิต" Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee NIPS 2023. [กระดาษ]
- Qlora: "Qlora: Finetuning ที่มีประสิทธิภาพของ LLMs เชิงปริมาณ" Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyerauthors ข้อมูลและการเรียกร้อง NIPS 2023. [กระดาษ] [GitHub]
เทคนิค LLM สำหรับ SLMS
- Ma et al.: "รูปแบบภาษาขนาดใหญ่ไม่ใช่ตัวแยกข้อมูลไม่กี่ตัวที่ดี แต่เป็น Reranker ที่ดีสำหรับตัวอย่างที่ยาก!" - Yubo MA, Yixin Cao, Yongching Hong, Aixin Sun EMNLP 2023. [กระดาษ] [GitHub]
- MOQE: "ส่วนผสมของผู้เชี่ยวชาญเชิงปริมาณ (MOQE): ผลเสริมของการวัดปริมาณและความทนทานต่อบิตต่ำ" Young Jin Kim, Raffy Fahim, Hany Hassan Awadalla 2023. [กระดาษ]
- SLM-RAG: "โมเดลภาษาขนาดเล็กที่มีรุ่นที่เรียกคืนได้แทนที่โมเดลภาษาขนาดใหญ่เมื่อเรียนรู้วิทยาการคอมพิวเตอร์ได้หรือไม่?" - Suqing Liu, Zezhu Yu, Feiran Huang, Yousef Bulbulia, Andreas Bergen, Michael Liut iticse 2024. [กระดาษ]
แอปพลิเคชัน SLM เฉพาะงาน
SLM ใน QA
- Alpaca: "Alpaca: โมเดลที่ทำตามคำสั่งที่แข็งแกร่งและจำลองได้" Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto 2023. [กระดาษ] [GitHub] [HuggingFace] [เว็บไซต์]
- Beluga 7B ที่มั่นคง: "Beluga 2" Mahan, Dakota และ Carlow, Ryan และ Castricato, Louis และ Cooper, Nathan และ Laforte, Christian 2023. [HuggingFace]
- Biogpt Guo et al.: "การปรับปรุงแบบจำลองภาษาขนาดเล็กบน PubMedqa ผ่านการเพิ่มข้อมูลกำเนิด" Zhen Guo, Peiqi Wang, Yanwei Wang, Shangdi Yu 2023. [กระดาษ]
- Financial SLMS: "การปรับแต่งแบบจำลองภาษาขนาดเล็กสำหรับคำถามตอบคำถามทางการเงิน" Karmvir Singh Phogat Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, Shashishekar Ramakrishna 2024. [กระดาษ]
- Colbert: "Colbert Retrieval and Ensemble Response Response Response สำหรับคำถามแบบจำลองภาษาตอบคำถาม" Alex Gichamba, Tewodros Kederalah Idris, Brian Ebiyau, Eric Nyberg, Teruko Mitamura IEEE 2024. [กระดาษ]
- T-SAS: "เวลาทดสอบแบบปรับตัวเองแบบปรับตัวเองแบบจำลองภาษาเล็ก ๆ สำหรับการตอบคำถาม" Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park ACL 2023. [กระดาษ] [GitHub]
- การจัดอันดับเหตุผล: "ตอบคำถามที่มองไม่เห็นด้วยแบบจำลองภาษาขนาดเล็กโดยใช้การสร้างเหตุผลและการดึงข้อมูลหนาแน่น" Tim Hartill, Diana Benavides-Prado, Michael Witbrock, Patricia J. Riddle 2023. [กระดาษ]
SLM ในการเข้ารหัส
- Phi-3.5-mini: "รายงานทางเทคนิค Phi-3: โมเดลภาษาที่มีความสามารถสูงในโทรศัพท์ของคุณ" Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, ... 2024. [กระดาษ] [HuggingFace] [เว็บไซต์]
- Tinyllama: "Tinylllama: โมเดลภาษาเล็ก ๆ โอเพ่นซอร์ส" Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu 2024. [กระดาษ] [HuggingFace] [แชทสาธิต] [Discord]
- Codellama: "Code Llama: Open Foundation Models สำหรับรหัส" Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, ... 2024. [กระดาษ] [HuggingFace]
- CodeGemma: "CodeGemma: โมเดลเปิดรหัสตาม Gemma" ทีม Codegemma: Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christopher A. Choquette-Choo, Jingyue Shen, Joe Kelley, Kshitij Bansal, ... 2024. [กระดาษ] [HuggingFace]
SLM ในคำแนะนำ
- Promptrec: "โมเดลภาษาขนาดเล็กสามารถทำหน้าที่เป็นผู้แนะนำได้หรือไม่? Xuansheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu 2024. [กระดาษ] [GitHub]
- Slim: "โมเดลภาษาขนาดเล็กสามารถเป็นเหตุผลที่ดีสำหรับคำแนะนำตามลำดับได้หรือไม่" - Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, Xiao Wang 2024. [กระดาษ]
- BILLP: "แบบจำลองภาษาขนาดใหญ่เป็นนักวางแผนที่เรียนรู้ได้สำหรับคำแนะนำระยะยาว" Wentao Shi, Xiangnan HE, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, Fuli Feng 2024. [กระดาษ]
- ครั้งหนึ่ง: "ครั้งหนึ่ง: การเพิ่มคำแนะนำตามเนื้อหาด้วยโมเดลภาษาขนาดใหญ่ทั้งแบบโอเพ่นและแบบปิด" Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu WSDM 2024. [กระดาษ] [GitHub]
- Reclora: "การปรับระดับต่ำของแบบจำลองต่ำของแบบจำลองภาษาขนาดใหญ่สำหรับคำแนะนำ" Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang 2024. [กระดาษ]
SLM ในการค้นหาเว็บ
- ตัวเข้ารหัสเนื้อหา: "งานการฝึกอบรมล่วงหน้าสำหรับการดึงการดึงขนาดใหญ่ตามการฝัง" Wei-Cheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, Sanjiv Kumar ICLR 2020. [กระดาษ]
- Poly-encoders: "poly-encoders: สถาปัตยกรรมหม้อแปลงและกลยุทธ์การฝึกอบรมล่วงหน้าสำหรับการให้คะแนนหลายประโยคที่รวดเร็วและแม่นยำ" ซามูเอลฮูม, Kurt Shuster, Marie-Anne Lachaux, Jason Weston ICLR 2020. [กระดาษ]
- Twin-Bert: "Twinbert: กลั่นความรู้ไปยังแบบจำลองเบิร์ตที่มีโครงสร้างคู่เพื่อการดึงที่มีประสิทธิภาพ" Wenhao Lu, Jian Jiao, Ruofei Zhang 2020. [กระดาษ]
- H-ernie: "H-ernie: รูปแบบภาษาที่ได้รับการฝึกฝนมาล่วงหน้าแบบหลายระดับสำหรับการค้นหาเว็บ" Xiaokai Chu, Jiashu Zhao, Lixin Zou, Dawei Yin Sigir 2022. [กระดาษ]
- Ranker: "Passage จัดอันดับใหม่ด้วย Bert" Rodrigo Nogueira, Kyunghyun Cho 2019. [กระดาษ] [GitHub]
- Rewriter: "การสืบค้นใหม่สำหรับการเรียกคืนแบบจำลองภาษาขนาดใหญ่" Xinbei Ma, Yeyun Gong, Pengcheng HE, Hai Zhao, Nan Duan EMNLP2023 [กระดาษ] [GitHub]
SLM ในอุปกรณ์พกพา
- Octopus: "Octopus: รูปแบบภาษาระหว่างอุปกรณ์สำหรับฟังก์ชั่นการเรียกใช้ซอฟต์แวร์ API" Wei Chen, Zhiyuan Li, Mingyuan Ma 2024. [กระดาษ] [HuggingFace]
- MobileAgent: "Mobile-Agent-V2: ผู้ช่วยการทำงานของอุปกรณ์มือถือด้วยการนำทางที่มีประสิทธิภาพผ่านการทำงานร่วมกันแบบหลายตัวแทน" Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang 2024. [กระดาษ] [GitHub] [HuggingFace]
- การปฏิวัติปฏิสัมพันธ์ระหว่างมือถือ: "การปฏิวัติการโต้ตอบบนมือถือ: การเปิดใช้งานพารามิเตอร์ 3 พันล้าน GPT LLM บนมือถือ" Samuel Carreira, Tomás Marques, José Ribeiro, Carlos Grilo 2023. [กระดาษ]
- Autodroid: "Autodroid: งานอัตโนมัติที่ใช้พลังงาน LLM ใน Android" Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, Yunxin Liu 2023. [กระดาษ]
- ตัวแทนออนอุปกรณ์สำหรับการเขียนข้อความใหม่: "ไปยังตัวแทนออนอุปกรณ์สำหรับการเขียนข้อความใหม่" Yun Zhu, Yinxiao Liu, Felix Stahlberg, Shankar Kumar, Yu-Hui Chen, Liangchen Luo, Lei Shu, Renjie Liu, Jindong Chen, Lei Meng 2023. [กระดาษ]
เทคนิคการเพิ่มประสิทธิภาพการปรับใช้ระหว่างอุปกรณ์
การเพิ่มประสิทธิภาพประสิทธิภาพของหน่วยความจำ
- Edge-LLM: "Edge-LLM: การเปิดใช้งานการปรับรูปแบบภาษาขนาดใหญ่ที่มีประสิทธิภาพบนอุปกรณ์ขอบผ่านการบีบอัดแบบครบวงจรและการปรับแต่งเลเยอร์และการลงคะแนนแบบปรับตัว" Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin 2024. [กระดาษ] [GitHub]
- LLM-PQ: "LLM-PQ: การให้บริการ LLM บนกลุ่มที่แตกต่างกันด้วยพาร์ติชันที่รับรู้เฟสและการปรับปริมาณ" Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu 2024. [กระดาษ] [GitHub]
- AWQ: "AWQ: ปริมาณการเปิดใช้งานการเปิดใช้งานสำหรับการบีบอัด LLM และการเร่งความเร็ว" Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han MLSYS 2024. [กระดาษ] [GitHub]
- MobileAiBench: "MobileAiBench: การเปรียบเทียบ LLMS และ LMMs สำหรับกรณีการใช้งานบนอุปกรณ์" Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu Silvio Savaresel 2024. [กระดาษ] [GitHub]
- Mobilellm: "Mobilellm: การเพิ่มประสิทธิภาพแบบจำลองภาษาพารามิเตอร์แบบพารามิเตอร์ย่อยสำหรับกรณีการใช้งานบนอุปกรณ์" Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra ICML 2024. [กระดาษ] [GitHub] [HuggingFace]
- Edgemoe: "Edgemoe: การอนุมานอย่างรวดเร็วในการรับมือกับโมเดลภาษาขนาดใหญ่ที่ใช้ MOE" Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu 2023. [กระดาษ] [GitHub]
- เกียร์: "เกียร์: สูตรการบีบอัดแคช KV ที่มีประสิทธิภาพสำหรับการอนุมานการกำเนิด LLM" Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao 2024. [กระดาษ] [GitHub]
- DMC: "การบีบอัดหน่วยความจำแบบไดนามิก: การติดตั้ง LLMS สำหรับการติดตั้งแบบเร่งความเร็ว" Piotr Nawrot, Adrian łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti 2024. [กระดาษ]
- Transformer-Lite: "Transformer-Lite: การปรับใช้ประสิทธิภาพสูงของรุ่นภาษาขนาดใหญ่บน GPU โทรศัพท์มือถือ" Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie 2024. [กระดาษ]
- LLMAAS: "LLM เป็นบริการระบบบนอุปกรณ์มือถือ" Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu 2024. [กระดาษ]
การเพิ่มประสิทธิภาพประสิทธิภาพของรันไทม์
- Edgemoe: "Edgemoe: การอนุมานอย่างรวดเร็วในการรับมือกับโมเดลภาษาขนาดใหญ่ที่ใช้ MOE" Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu 2023. [กระดาษ] [GitHub]
- LLMCAD: "LLMCAD: การอนุมานแบบจำลองภาษาขนาดใหญ่ที่รวดเร็วและปรับขนาดได้" Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu 2023. [กระดาษ]
- lingualinked: "lingualinked: ระบบการอนุมานแบบจำลองภาษาขนาดใหญ่แบบกระจายสำหรับอุปกรณ์มือถือ" Junchen Zhao, Yurun Song, Simeng Liu, Ian G. Harris, Sangeetha Abdu Jyothi 2023 [กระดาษ]
SLMS เพิ่มประสิทธิภาพ LLMS
SLMs สำหรับการสอบเทียบ LLM และการตรวจจับภาพหลอน
- การปรับเทียบโมเดลภาษาขนาดใหญ่โดยใช้รุ่นของพวกเขาเท่านั้น Dennis Ulmer, Martin Gebri, Hwaran Lee, Sangdoo Yun, Seong Joon Oh ACL 2024 ยาว [PDF] [รหัส]
- Pareto การเรียนรู้ที่เหมาะสมที่สุดสำหรับการประเมินข้อผิดพลาดของแบบจำลองภาษาขนาดใหญ่ Theodore Zhao, Mu Wei, J. Samuel Preston, Hoifung Poon ACL 2024 ยาว [PDF]
- สถานะภายในของ LLM รู้เมื่อมันโกหก Amos Azaria, Tom Mitchell EMNLP 2023 การค้นพบ [PDF]
- ตัวแทนขนาดเล็กสามารถโยกได้! เพิ่มขีดความสามารถของแบบจำลองภาษาขนาดเล็กเป็นเครื่องตรวจจับภาพหลอน Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen EMNLP 2024 ยาว [PDF]
- การปรับตัวใหม่ LLM จากมุมมองการสูญเสียการจัดกลุ่ม Lihu Chen, Alexandre Perez-LeBel, Fabian M. Suchanek, Gaël Varoquaux EMNLP 2024 การค้นพบ [PDF]
slms สำหรับ llm rag
- โมเดลขนาดเล็กข้อมูลเชิงลึกขนาดใหญ่: การใช้ประโยชน์จากโมเดลพร็อกซีที่เพรียวบางเพื่อตัดสินใจว่าจะเรียกคืน LLM เมื่อใดและอะไร Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen ACL 2024 ยาว [PDF] [รหัส] [HuggingFace]
- Rag-Rag: การเรียนรู้ที่จะเรียกคืนสร้างและวิจารณ์ผ่านการสะท้อนตนเอง Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi ICLR 2024 ช่องปาก [PDF] [HuggingFace] [รหัส] [เว็บไซต์] [โมเดล] [ข้อมูล]
- Longllmlingua: เร่งและเพิ่มประสิทธิภาพ LLMs ในสถานการณ์บริบทที่ยาวนานผ่านการบีบอัดที่รวดเร็ว Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu ICLR 2024 การประชุมเชิงปฏิบัติการโปสเตอร์ ME-FOMO [PDF]
- การแก้ไขการเรียกคืนการแก้ไข Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling Arxiv 2024.1 [PDF] [รหัส]
- ความรู้ด้วยตนเองมีการเสริมการดึงข้อมูลสำหรับแบบจำลองภาษาขนาดใหญ่ Yile Wang, Peng Li, Maosong Sun, Yang Liu EMNLP 2023 การค้นพบ [PDF] [รหัส]
- โมเดลภาษาการดึงข้อมูลในบริบท Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham TACL 2023. [PDF] [รหัส]
- RA-ISF: การเรียนรู้ที่จะตอบและเข้าใจจากการเสริมการดึงผ่านการตอบกลับด้วยตนเองซ้ำ Liu, Yanming และ Peng, Xinyue และ Zhang, Xuhong และ Liu, Weihao และ Yin, Jianwei และ Cao, Jiannan และ Du, Tianyu ACL 2024 ผลการวิจัย [PDF]
- น้อยกว่ามาก: การสร้างแบบจำลองภาษาที่มีขนาดเล็กลง Retrievers Subgraph ที่มีความสามารถสำหรับ Multi-Hop {KGQA} Wenyu Huang, Guancheng Zhou, Hongru Wang, Pavlos Vougiouklis, Mirella Lapata, Jeff Z. Pan EMNLP 2024 การค้นพบ [PDF]
SLM สำหรับการใช้เหตุผล LLM
- Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu และ Julian McAuley โมเดลขนาดเล็กเป็นปลั๊กอินที่มีค่าสำหรับรุ่นภาษาขนาดใหญ่ ACL 2024 ผลการวิจัย [PDF]
- Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen และ Yue Zhang ความรู้ภายใต้การดูแลทำให้แบบจำลองภาษาขนาดใหญ่ดีขึ้นผู้เรียนในบริบท ICLR 2024 โปสเตอร์ [PDF]
- Zhuofeng Wu, He Bai, Aonan Zhang, Jiatao Gu, VG Vydiswaran, Navdeep Jaitly และ Yizhe Zhang Divide-or-Conquer? ส่วนไหนที่คุณควรกลั่น LLM ของคุณ? EMNLP 2024 การค้นพบ [PDF]
SLMs เพื่อบรรเทาลิขสิทธิ์และความเป็นส่วนตัวของ LLMS
- Tianlin Li, Qian Liu, Tianyu Pang, Chao Du, Qing Guo, Yang Liu และ Min Lin ทำให้โมเดลภาษาขนาดใหญ่บริสุทธิ์โดยรวมโมเดลภาษาขนาดเล็ก Arxiv 2024. [PDF]
SLMs สำหรับการสกัดพรอมต์ LLM
- Yiming Zhang, Nicholas Carlini และ Daphne Ippolito การสกัดพรอมต์ที่มีประสิทธิภาพจากแบบจำลองภาษา Colm 2024 [PDF]
- Zeyang Sha และ Yang Zhang การขโมยการโจมตีแบบจำลองภาษาขนาดใหญ่ arxiv (2024) [PDF]
- Collin Zhang, John X Morris และ Vitaly Shmatikov การสกัดพรอมต์โดยเอาต์พุต LLM กลับด้าน [PDF]
SLMs สำหรับการปรับแต่ง LLMS
- Eric Mitchell, Rafael Rafailov, Archit Sharma, Chelsea Finn และ Christopher D Manning 2024. ตัวจำลองสำหรับการปรับแต่งแบบจำลองภาษาขนาดใหญ่โดยใช้แบบจำลองภาษาขนาดเล็ก ICLR 2024. [PDF]
- Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi และ Noah A Smith 2024. การปรับโมเดลภาษาโดยพร็อกซี Colm 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen และ Jingbo Shang 2024. แบบจำลองภาษาขนาดเล็กสามารถเลือกข้อมูลการฝึกอบรมการปรับแต่งคำสั่งสำหรับโมเดลภาษาขนาดใหญ่ ACL 2024 ผลการวิจัย [PDF]
- Yongheng Deng, Ziqing Qiao, Ju Ren, Yang Liu และ Yaoxue Zhang 2023. การเพิ่มประสิทธิภาพซึ่งกันและกันของแบบจำลองภาษาขนาดใหญ่และขนาดเล็กพร้อมการถ่ายโอนความรู้ข้าม Silo Arxiv 2023. [PDF]
- Smalltolarge (S2L): การเลือกข้อมูลที่ปรับขนาดได้สำหรับการปรับแต่งแบบจำลองภาษาขนาดใหญ่โดยสรุปวิถีการฝึกอบรมของรุ่นขนาดเล็ก Yu Yang · Siddhartha Mishra · Jeffrey Chiang · Baharan Mirzasoleiman โปสเตอร์ NIPS 2024 [PDF]
- การค้นหาที่อ่อนแอต่อความแข็งแกร่ง: จัดรูปแบบภาษาขนาดใหญ่ผ่านการค้นหาแบบจำลองภาษาขนาดเล็ก Zhanhui Zhou · Zhixuan Liu · Jie Liu · Zhichen Dong · Chao Yang · Yu Qiao โปสเตอร์ NIPS 2024 [PDF]
SLM เพื่อความปลอดภัย LLM
- Llama Guard: Safeguard อินพุตที่ใช้ LLM สำหรับการสนทนาของมนุษย์และ AI Meta Arxiv 2024 [PDF]
- SLM ในฐานะผู้พิทักษ์: ผู้บุกเบิกความปลอดภัยของ AI ด้วยรูปแบบภาษาขนาดเล็ก Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park EMNLP 2024. [PDF]
SLM สำหรับการประเมิน LLM
- Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin และ Liang Zhan 2024. สไลด์: เฟรมเวิร์กรวมโมเดลภาษาขนาดเล็กและขนาดใหญ่สำหรับการประเมินบทสนทนาแบบเปิดโดเมน ACL 2024 ผลการวิจัย [PDF]
- ความไม่แน่นอนของความหมาย: ค่าคงที่ภาษาศาสตร์สำหรับการประเมินความไม่แน่นอนในการสร้างภาษาธรรมชาติ Lorenz Kuhn, Yarin Gal, Sebastian Farquhar ICLR 2023. [PDF]
- SelfCheckGPT: การตรวจจับภาพหลอนกล่องดำที่เป็นศูนย์สำหรับโมเดลภาษาขนาดใหญ่ที่กำเนิด Potsawee Manakul, Adian Liusie, Mark Gales EMNLP 2023 หลัก [PDF]
- Proxylm: การทำนายประสิทธิภาพของแบบจำลองภาษาในงานหลายภาษาผ่านโมเดลพร็อกซี David Anugraha, Genta Indra Winata, Chenyue Li, Patrick Amadeus Irawan, En-Shiun Annie Lee Arxiv 2024. [PDF]
- FACTSCORE: การประเมินอะตอมที่ละเอียดของความแม่นยำจริงในการสร้างข้อความแบบยาว Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hannaneh Hajishirzi EMNLP 2023 หลัก [PDF]
- ดูก่อนที่คุณจะกระโดด: การศึกษาเชิงสำรวจเกี่ยวกับการวัดความไม่แน่นอนสำหรับแบบจำลองภาษาขนาดใหญ่ Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, Lei Ma Arxiv 2023. [PDF]
ประวัติดาว


