SLM -Umfrage
Eine umfassende Untersuchung kleiner Sprachmodelle: Technologie, Anwendungen vor Ort, Effizienz, Verbesserungen für LLMs und Vertrauenswürdigkeit
Dieses Repo enthält die Artikel, die in unserem neuesten Umfragepapier über kleine Sprachmodelle diskutiert wurden.
Lesen Sie das vollständige Papier hier: Papierlink
Nachricht
- 2024/11/04: Die erste Version unserer Umfrage ist auf Arxiv!
Referenz
Wenn unsere Umfrage für Ihre Forschung nützlich ist, zitieren Sie bitte unser Papier:
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
Überblick über SLMS
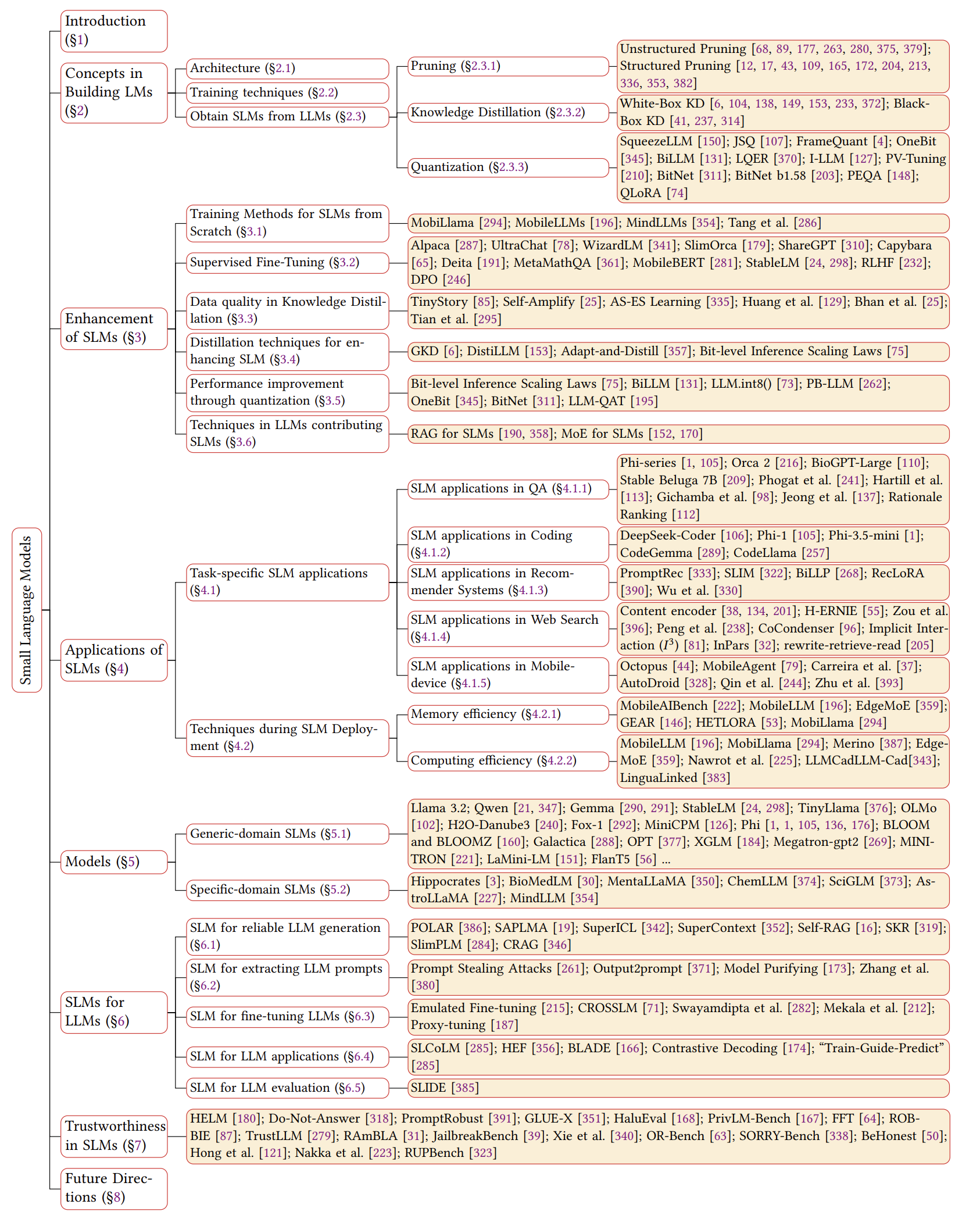
Zeitleiste von SLMs
SLMS -Papierliste
Bestehende SLMs
| Modell | #Params | Datum | Paradigma | Domain | Code | HF -Modell | Papier/Blog |
|---|
| Lama 3.2 | 1b; 3b | 2024.9 | Vor dem Training | Generisches | Github | Hf | Blog |
| Qwen 1 | 1,8b; 7b; 14b; 72b | 2023.12 | Vor dem Training | Generisches | Github | Hf | Papier |
| Qwen 1.5 | 0,5b; 1,8b; 4b; 7b; 14b; 32b; 72b | 2024.2 | Vor dem Training | Generisches | Github | Hf | Papier |
| Qwen 2 | 0,5b; 1,5b; 7b; 57b; 72b | 2024.6 | Vor dem Training | Generisches | Github | Hf | Papier |
| Qwen 2.5 | 0,5b; 1,5b; 3b; 7b; 14b; 32b; 72b | 2024.9 | Vor dem Training | Generisches | Github | Hf | Papier |
| Gemma | 2b; 7b | 2024.2 | Vor dem Training | Generisches | | Hf | Papier |
| Gemma 2 | 2b; 9b; 27b | 2024.7 | Vor dem Training | Generisches | | Hf | Papier |
| H2O-Danube3 | 500 m; 4b | 2024.7 | Vor dem Training | Generisches | | Hf | Papier |
| LLM-Neo | 1b | 2024.11 | Kontinous Training | Generisches | | Hf | Papier |
| Fox-1 | 1,6b | 2024.6 | Vor dem Training | Generisches | | Hf | Blog |
| Rene | 1.3b | 2024.5 | Vor dem Training | Generisches | | Hf | Papier |
| Minicpm | 1,2b; 2.4b | 2024.4 | Vor dem Training | Generisches | Github | Hf | Papier |
| Olmo | 1b; 7b | 2024.2 | Vor dem Training | Generisches | Github | Hf | Papier |
| Tinyllama | 1b | 2024.1 | Vor dem Training | Generisches | Github | Hf | Papier |
| PHI-1 | 1.3b | 2023.6 | Vor dem Training | Codierung | | Hf | Papier |
| PHI-1.5 | 1.3b | 2023.9 | Vor dem Training | Generisches | | Hf | Papier |
| Phi-2 | 2.7b | 2023.12 | Vor dem Training | Generisches | | Hf | Papier |
| Phi-3 | 3,8b; 7b; 14b | 2024.4 | Vor dem Training | Generisches | | Hf | Papier |
| Phi-3.5 | 3,8b; 4,2b; 6.6b | 2024.4 | Vor dem Training | Generisches | | Hf | Papier |
| OpenElm | 270 m; 450 m; 1,1b; 3b | 2024.4 | Vor dem Training | Generisches | Github | Hf | Papier |
| Mobillama | 0,5b; 0,8b | 2024.2 | Vor dem Training | Generisches | Github | Hf | Papier |
| Mobilellm | 125 m; 350 m | 2024.2 | Vor dem Training | Generisches | Github | Hf | Papier |
| Stablelm | 3b; 7b | 2023.4 | Vor dem Training | Generisches | Github | Hf | Papier |
| Stablelm 2 | 1,6b | 2024.2 | Vor dem Training | Generisches | Github | Hf | Papier |
| Cerebras-GPT | 111m-13b | 2023.4 | Vor dem Training | Generisches | | Hf | Papier |
| Blüte, Bloomz | 560 m; 1,1b; 1,7b; 3b; 7.1b; 176b | 2022.11 | Vor dem Training | Generisches | | Hf | Papier |
| Opt | 125 m; 350 m; 1,3b; 2,7b; 5.7b | 2022.5 | Vor dem Training | Generisches | | Hf | Papier |
| Xglm | 1,7b; 2,9b; 7.5b | 2021.12 | Vor dem Training | Generisches | Github | Hf | Papier |
| Gpt-neo | 125 m; 350 m; 1,3b; 2.7b | 2021.5 | Vor dem Training | Generisches | Github | | Papier |
| Megatron-gpt2 | 355 m; 2,5b; 8.3b | 2019.9 | Vor dem Training | Generisches | Github | | Papier, Blog |
| Minitron | 4b; 8b; 15b | 2024.7 | Beschneiden und Destillation | Generisches | Github | Hf | Papier |
| Minimix | 7b | 2024.7 | Vor dem Training | Generisches | Github | Hf | Papier |
| Minima-2 | 1b; 3b | 2023.12 | Vor dem Training | Generisches | Github | Hf | Papier |
| Minima | 3b | 2023.11 | Beschneiden und Destillation | Generisches | Github | Hf | Papier |
| Orca 2 | 7b | 2023.11 | Destillation | Generisches | | Hf | Papier |
| Dolly-V2 | 3b; 7b; 12b | 2023.4 | Anweisungsabstimmung | Generisches | Github | Hf | Blog |
| Lamini-lm | 61m-7b | 2023.4 | Destillation | Generisches | Github | Hf | Blog |
| Spezialer Flant5 | 250 m; 760 m; 3b | 2023.1 | Anweisungsabstimmung | Generische (Mathematik) | Github | - - | Papier |
| Flant5 | 80 m; 250 m; 780 m; 3b | 2022.10 | Anweisungsabstimmung | Generisches | Gihub | Hf | Papier |
| T5 | 60 m; 220 m; 770 m; 3b; 11b | 2019.9 | Vor dem Training | Generisches | Github | Hf | Papier |
SLM -Architektur
- Transformator: Aufmerksamkeit ist alles, was Sie brauchen. Ashish Vaswani . Neurips 2017.
- Mamba 1: Mamba: Linear-Zeit-Sequenzmodellierung mit selektiven Zustandsräumen. Albert Gu und Tri Dao . Colm 2024. [Papier].
- Mamba 2: Transformatoren sind SSMs: Generalisierte Modelle und effiziente Algorithmen durch strukturierte Zustandsraum -Dualität. Tri Dao und Albert Gu . ICML 2024. [Papier] [Code]
Verbesserung für SLM
Training von Grund auf neu
- Mobillama: "Mobillama: Auf dem Weg zu genauem und leichtem, vollständig transparentem GPT" . Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan. ARXIV 2024. [Papier] [GitHub] [Huggingface]
- Mobilellm: "Mobilellm: Optimierung der Parametersprachenmodelle der Subbillion für Anwendungsfälle auf dem Gerät" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra Icml 2024.
- Optimierung und Architektur für winzige Sprachmodelle überdenken. Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han und Yunhe Wang. ICML 2024. [Papier] [Code]
- Mindllm: "Mindllm: Leichtes großes Sprachmodell vor dem Training von Grund auf, Evaluierungen und Domänenanwendungen" . Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, Yang Gao . ARXIV 2023. [Papier] [Suggingface]
Übersichtliche Feinabstimmung
- Direkte Präferenzoptimierung: Ihr Sprachmodell ist heimlich ein Belohnungsmodell. Rafael Rafailov, Architiker Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon und Chelsea Finn. Neurips, 2024. [Papier] [Code]
- Verbesserung von Chat-Sprachmodellen durch Skalierung hochwertiger Unterrichtsgespräche. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun und Bowen Zhou. EMNLP 2023. [Papier] [Code]
- Slimorca: Ein offener Datensatz von GPT-4-Augmented Flan-Argumentationsspuren mit Überprüfung. Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Spong und "Teknium". Suggingface, 2023. [Daten]
- Stanford Alpaka: Ein lamatisiertes Anweisungsmodell. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang und Tatsunori B. Hashimoto. Github, 2023. [Blog] [GitHub] [Huggingface]
- OpenChat: Weiterentwicklung von Open-Source-Sprachmodellen mit Daten mit gemischter Qualität. Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Lied und Yang Liu. ICLR, 2024. [Papier] [Code] [Huggingface]
- Trainingssprachmodelle, um Anweisungen mit menschlichem Feedback zu befolgen. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, Ryan Lowe. Neurips, 2022. [Papier]
- RLHF: "Trainingssprachmodelle, um Anweisungen mit menschlichem Feedback zu befolgen" . Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. 2022. [Papier]
- Mobiltt: "Mobiltt: Ein kompaktes Task-Agnostic Bert für ressourcenbegrenzte Geräte" . Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou. ACL 2020. [Papier] [GitHub] [Suggingface]
- Sprachmodelle sind unbeaufsichtigte Multitasking -Lernende. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. OpenAI -Blog, 2019. [Papier]
Datenqualität in KD
- TinyStory: "Tinystories: Wie klein können Sprachmodelle kohärentes Englisch sein und sprechen?" . Ronen Eldan, Yuanzhi Li. 2023. [Papier] [Suggingface]
- AS-ES: "AS-ES-Lernen: Auf dem Weg zu effizientem Kinderbettler in kleinen Modellen" . Nuwa XI, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu. 2024. [Papier]
- Selbstamplifikation: "Selbstamping: Verbesserung kleiner Sprachmodelle mit Selbstpost-hoc-Erklärungen" . Mailand Bhan, Jean-Noel Vittaut, Nicolas Chesneau, Marie-Jeanne Lesot. 2024. [Papier]
- Große Sprachmodelle können sich selbst verbessern. Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu und Jiawei Han. EMNLP 2023. [Papier]
- In Richtung Selbstverbesserung von LLMs durch Vorstellungskraft, Suche und Kritik. Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao MI und Dong Yu. Neurips 2024. [Papier] [Code]
Destillation für SLM
- GKD: "On-Policy Destillation von Sprachmodellen: Lernen aus selbst erzeugten Fehlern" . Rishabh Agarwal et al. ICLR 2024. [Papier]
- Destilllm: "Destillm: In Richtung optimierter Destillation für große Sprachmodelle" . Jongwoo Ko et al. ICML 2024. [Papier] [GitHub]
- Anpassungs und Distill: "Anpassungs und Distill: Entwicklung kleiner, schneller und effektiver pretrazierter Sprachmodelle für Domänen" . Yunzhi Yao et al. ACL2021. [Papier] [GitHub]
- AKL: "Kullback-Leibler-Divergenz in der Wissensdestillation für große Sprachmodelle überdenken" . Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, Ngai Wong. ARXIV 2024. [Papier] [GitHub]
- Gewicht inneeritierte Destillation für Task-Agnostic Bert-Kompression Taiqiang Wu, Cheng Hou, Shanshan Lao, Jiayi Li, Ngai Wong, Zhe Zhao, Yujiu Yang Naacl, 2024, [Papier] [Code]
Quantisierung
- Smoothquant: "Smoothquant: Genauige und effiziente Quantisierung nach dem Training für Großsprachenmodelle" . Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Lied Han. ICML 2023. [Papier] [GitHub] [Slides] [Video]
- BILLM: "Billm: Drücken Sie die Grenze der Quantisierung nach dem Training für LLMs" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [Papier] [GitHub]
- LLM-QAT: "LLM-QAT: Datenfreies Quantisierungs-Training für Großsprachenmodelle" . Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra. 2023. [Papier]
- PB-LlM: "PB-LlM: Teilweise binarisierte Großsprachenmodelle" . Zhihang Yuan, Yuzhang Shang, Zhen Dong. ICLR 2024. [Papier] [GitHub]
- OneBit: "Onebit: Auf dem Weg zu extrem niedrigen großartigen großartigen Modellen" . Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che. Neurips 2024. [Papier]
- Bitnet: "Bitnet: Skalierung von 1-Bit-Transformatoren für große Sprachmodelle" . Hongyu Wang, Shuming MA, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao MA, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei. 2023. [Papier]
- Bitnet B1.58: "Die Ära von 1-Bit-LLMs: Alle großsprachigen Modelle sind in 1,58 Bit" . Shuming MA, Hongyu Wang, Lingxia MA, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei. 2024. [Papier]
- Squeezellm: "Squeezellm: Dicht-und-Parse-Quantisierung" . Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Ketzer. ICML 2024. [Papier] [GitHub]
- JSQ: "Komprimieren von großsprachigen Modellen durch gemeinsame Sparsifikation und Quantisierung" . Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, Xianglong Liu. ICML 2024. [Papier] [GitHub]
- Framequant: "Framequant: Flexible Quantisierung mit niedrigem Bit für Transformatoren" . Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh. 2024. [Papier] [GitHub]
- BILLM: "Billm: Drücken Sie die Grenze der Quantisierung nach dem Training für LLMs" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [Papier] [GitHub]
- LQER: "LQER: Low-Rang Quantisierungsfehlerrekonstruktion für LLMs" . Cheng Zhang, Jianyi Cheng, George A. Konstantinides, Yiren Zhao. ICML 2024. [Papier] [GitHub]
- I-LlM: "I-LlM: Effiziente Ganzzahl-Inferenz für vollquantisierte große Sprachmodelle mit niedrigem Bit" . Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou. 2024. [Papier] [GitHub]
- PV-Tuning: "PV-Tuning: Beyond Straight-Through-Schätzung für die extreme LLM-Komprimierung" . Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik. 2024. [Papier]
- PEQA: "Speichereffiziente Feinabstimmung komprimierter großer Sprachmodelle über die Quantisierung von Sub-4-Bit-Ganzzahl" . Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee. NIPS 2023. [Papier]
- Qlora: "Qlora: Effiziente Finetuning von quantisierten LLMs" . Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyerautor Info & Ansprüche. NIPS 2023. [Papier] [GitHub]
LLM -Techniken für SLMs
- Ma et al.: "Großes Sprachmodell ist kein guter Informationen zum Auszügen von Informationen, sondern ein guter Reranker für harte Muster!" . Yubo MA, Yixin Cao, Yongching Hong, Aixin Sun. EMNLP 2023. [Papier] [GitHub]
- MOQE: "Mischung aus quantisierten Experten (MOQE): Komplementärer Effekt der Quantisierung und Robustheit mit niedriger Bit" . Junge Jin Kim, Raffy Fahim, Hany Hassan Awadalla. 2023. [Papier]
- SLM-RAG: "Können kleine Sprachmodelle mit retrievaler Generation Großsprachmodelle beim Lernen von Informatik ersetzen?" . Suqing Liu, Zezhu Yu, Feiran Huang, Yousef Bulbulia, Andreas Bergen, Michael Liut. Iticse 2024. [Papier]
Aufgabenspezifische SLM-Anwendungen
SLM in QA
- ALPACA: "Alpaka: Ein starkes, reproduzierbares Anweisungsmodell" . Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto. 2023. [Papier] [GitHub] [Huggingface] [Website]
- Stabiler Beluga 7b: "Stable Beluga 2" . Mahan, Dakota und Carlow, Ryan und Castricato, Louis und Cooper, Nathan und Laforte, Christian. 2023. [Umarmung]
- Fein abgestimmter Biogpt Guo et al.: "Verbesserung kleiner Sprachmodelle auf PubMedqa über generative Datenvergrößerung" . Zhen Guo, Peiqi Wang, Yanwei Wang, Shangdi Yu. 2023. [Papier]
- Financial SLMs: "Feinabstimmung kleinere Sprachmodelle zur Beantwortung von Finanzdokumenten" . Karmvir Singh Phogat Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, Shashishekar Ramakrishna. 2024. [Papier]
- Colbert: "Colbert Retrieval und Ensemble Response Scoring für Sprachmodellfrage Beantwortung" . Alex Gichamba, Tewodros Kederalah Idris, Brian Ebiyau, Eric Nyberg, Teruko Mitamura. IEEE 2024. [Papier]
- T-SAS: "Tester-Zeit-selbst-adaptive kleine Sprachmodelle zur Beantwortung von Fragen" . Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park. ACL 2023. [Papier] [GitHub]
- Begründung Ranking: "Beantwortung unsichtbarer Fragen mit kleineren Sprachmodellen mithilfe der Erzeugung von Begründungen und einer dichten Wiederholung" . Tim Hartill, Diana Benavides-Prado, Michael Witbrock, Patricia J. Riddle. 2023. [Papier]
SLM in der Codierung
- Phi-3,5-Mini: "PHI-3-Technischer Bericht: Ein hochkarätiges Sprachmodell vor Ort auf Ihrem Telefon" . Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, ..., Chunyu Wang, Guanhua Wang, Lijuan Wang et al. 2024. [Papier] [Huggingface] [Website]
- Tinyllama: "Tinyllama: Ein Open-Source-Modell mit kleinem Sprache" . Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu. 2024. [Papier] [Huggingface] [CHAT -Demo] [Discord]
- Codellama: "Code Lama: Open Foundation Models für Code" . Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Savestre, Tal Remez, ..., Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. 2024. [Papier] [Suggingface]
- Codegemma: "Codegemma: Code -Modelle basierend auf Gemma" . Codegemma-Team: Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christopher A. Choquette-Choo, Jingyue Shen, Joe Kelley, Kshitij Bansal, ..., Kathy Korevec, Kelly Schaefer, Scott Huffman. 2024. [Papier] [Suggingface]
SLM in Empfehlung
- PrOMPTREC: "Könnten kleine Sprachmodelle als Empfehlungen auf datenzentrierte Empfehlungen zum Kaltstart dienen?" Xuansheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu. 2024. [Papier] [GitHub]
- Slim: "Können kleine Sprachmodelle gute Gründe für die sequentielle Empfehlung sein?" . Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, Xiao Wang. 2024. [Papier]
- BILLP: "Großsprachige Modelle sind lernbare Planer für langfristige Empfehlungen" . Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, Fuli Feng. 2024. [Papier]
- Einmal: "Einmal: Steigern Sie die inhaltsbasierte Empfehlung mit Open- und Closed-Source-großsprachigen Modellen" . Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu. WSDM 2024. [Papier] [GitHub]
- Reclora: "Lebenslange personalisierte Anpassung von großer Sprachmodellen für Empfehlungen" . Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang. 2024. [Papier]
SLM in der Websuche
- Inhaltscodierer: "Aufgaben vor dem Training zum Einbettungsbasis groß angelegte Abruf" . Wei-Acheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, Sanjiv Kumar. ICLR 2020. [Papier]
- Poly -codeer: "Poly-Coder: Transformatorarchitekturen und Strategien vor der Ausbildung für schnelle und genaue Multi-Sentenz-Bewertungen" . Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, Jason Weston. ICLR 2020. [Papier]
- Twin-Bert: "Twinbert: Destillieren von Wissen zu zweistrukturierten Bert-Modellen für das effiziente Abruf" . Wenhao Lu, Jian Jiao, Ruofei Zhang. 2020. [Papier]
- H-Erie: "H-Ernie: Ein Multi-Granularität-Vorgebliebenen-Sprachmodell für die Websuche" . Xiaokai Chu, Jishu Zhao, Lixin Zou, Dawei Yin. Sigir 2022. [Papier]
- Ranker: "Passage erneut mit Bert" . Rodrigo Nogueira, Kyunghyun Cho. 2019. [Papier] [Github]
- Rewritriter: "Abfrage Umschreiben zum Abrufen von Großsprachmodellen" . Xinbei MA, Yeyun Gong, Pengcheng HE, Hai Zhao, Nan Duan. EMNLP2023. [Papier] [GitHub]
SLM in Mobile-Geräte
- Octopus: "Octopus: Sprachmodell für Funktionen für Funktionsaufrufe von Software-APIs" . Wei Chen, Zhiyuan Li, Mingyuan MA. 2024. [Papier] [Suggingface]
- MobileAgent: "Mobile-Agent-V2: Betriebsassistent für Mobilgeräte mit einer effektiven Navigation über Multi-Agent-Zusammenarbeit" . Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang. 2024. [Papier] [GitHub] [Huggingface]
- Revolutionäre mobile Interaktion: "revolutionieren mobiler Interaktion: Aktivieren eines 3 -Milliarden -Parameter -GPT -LLM auf Mobilgeräten" . Samuel Carreira, Tomás Marques, José Ribeiro, Carlos Grilo. 2023. [Papier]
- Autodroid: "Autodroid: LLM-Anbieter-Taskautomation in Android" . Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, Yunxin Liu. 2023. [Papier]
- On-Device-Agent zum Umschreiben von Text: "In Richtung eines On-Device-Agenten für die Umschreibung des Textes" . Yun Zhu, Yinxia Liu, Felix Stahlberg, Shankar Kumar, Yu-Hui Chen, Liangchen Luo, Lei Shu, Renjie Liu, Jindong Chen, Lei Meng. 2023. [Papier]
Optimierungstechniken zur Bereitstellung von On-Device-Bereitstellungen
Speichereffizienzoptimierung
- KantenllM: "Randllm: Aktivierung einer effizienten Großsprachenmodellanpassung auf Kantengeräten über Layerwise Unified Compression und adaptive Layer-Tuning und -abstimmung" . Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran du, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin. 2024. [Papier] [GitHub]
- LLM-PQ: "LLM-PQ: Serving LLM auf heterogenen Clustern mit phasenbewusster Partition und adaptiver Quantisierung" . Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu. 2024. [Papier] [GitHub]
- AWQ: "AWQ: Aktivierungsbewusstes Gewichtsquantisierung für LLM-Komprimierung und -beschleunigung" . Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-m-Ming Chen, Wei-Achen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Lied Han. MLSYS 2024. [Papier] [GitHub]
- MobileAibench: "MobileAibench: Benchmarking-LLMs und LMMs für Anwendungsfälle auf dem Gerät" . Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savaresel. 2024. [Papier] [GitHub]
- Mobilellm: "Mobilellm: Optimierung der Parametersprachenmodelle der Subbillion für Anwendungsfälle auf dem Gerät" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra. ICML 2024. [Papier] [GitHub] [Huggingface]
- Edgemoe: "Edgemoe: Fast On-Device-Inferenz von MOE-basierten Großsprachenmodellen" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [Papier] [GitHub]
- Ausrüstung: "Ausrüstung: Ein effizientes KV-Cache-Kompressionsrezept für die nahezu verlustlose generative Inferenz von LLM" . Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao. 2024. [Papier] [GitHub]
- DMC: "Dynamische Speicherkomprimierung: Nachrüsten von LLMs für beschleunigte Inferenz" . Piotr Nawrot, Adrian łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti. 2024. [Papier]
- Transformator-Lite: "Transformer-Lite: Hocheffiziente Bereitstellung von großsprachigen Modellen für Mobiltelefon-GPUs" . Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie. 2024. [Papier]
- LLMAAS: "LLM als Systemdienst auf mobilen Geräten" . Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu. 2024. [Papier]
Laufzeit -Effizienzoptimierung
- Edgemoe: "Edgemoe: Fast On-Device-Inferenz von MOE-basierten Großsprachenmodellen" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [Papier] [GitHub]
- LLMCAD: "LLMCAD: Schnell und skalierbares Einschluss in der Einheit von großer Sprache" . Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu. 2023. [Papier]
- Lingualinked: "Lingualinked: Ein verteiltes großes Sprachmodell -Inferenzsystem für mobile Geräte" . Junken Zhao, Yurun Song, Simeng Liu, Ian G. Harris, Sangeetha Abdu Jyothi. 2023 [Papier]
SLMs verbessern LLMs
SLMs für die LLM -Kalibrierung und Halluzinationserkennung
- Kalibrieren großer Sprachmodelle nur mit ihren Generationen. Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, Seong Joon Oh . ACL 2024 lang, [PDF] [Code]
- Pareto optimales Lernen zur Schätzung von großen Sprachmodellfehlern. Theodore Zhao, Mu Wei, J. Samuel Preston, Hoifung Poon . ACL 2024 lang, [PDF]
- Der innere Zustand eines LLM weiß, wann es lügt. Amos Azaria, Tom Mitchell . EMNLP 2023 Ergebnisse. [PDF]
- Kleiner Agent kann auch rocken! Ermächtigung kleiner Sprachmodelle als Halluzinationsdetektor. Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen. EMNLP 2024 lang. [PDF]
- Rekonfizierung von LLMs aus der Perspektive des Gruppierungsverlusts. Lihu Chen, Alexandre Perez-Lebel, Fabian M. Suchanek, Gaël Varoquaux. EMNLP 2024 Ergebnisse. [PDF]
SLMs für LLM Lappen
- Kleine Modelle, große Erkenntnisse: Nutzung schlanker Proxy -Modelle, um zu entscheiden, wann und was für LLMs abgerufen werden soll. Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen. ACL 2024 lang. [PDF] [Code] [Huggingface]
- Selbstabschnitte: Durch Selbstreflexion lernen, generieren und kritisieren. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi. ICLR 2024 Oral. [PDF] [Huggingface] [Code] [Website] [Modell] [Daten]
- Longllmlingua: Beschleunigen und Verbesserung von LLMs in langen Kontextszenarien durch schnelle Komprimierung. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu. ICLR 2024 Workshop Me-Fomo-Poster. [PDF]
- Vergrößerung der korrektiven Wiederholung. Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling. ARXIV 2024.1. [PDF] [Code]
- Selbsterkenntnis geführte Abrufvergrößerung für Großsprachenmodelle. Yile Wang, Peng Li, Maosong Sun, Yang Liu. EMNLP 2023 Ergebnisse. [PDF] [Code]
- In-Kontext-Abruf-Sprachmodelle. Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. TaCl 2023. [PDF] [Code]
- RA-ISF: Lernen, zu antworten und aus dem Abruf Augmentation durch iterative Selbstversorgungsback zu beantworten und zu verstehen. Liu, Yanming und Peng, Xinyue und Zhang, Xuhong und Liu, Weihao und Yin, Jianwei und Cao, Jiannan und Du, Tianyu. ACL 2024 Befunde. [PDF]
- Weniger ist mehr: Erstellen kleinerer Sprachmodelle kompetente Subgraph-Retriever für Multi-Hop {kgqa}. Wenyu Huang, Guanchg Zhou, Hongru Wang, Pavlos Vougiouklis, Mirella Lapata, Jeff Z. Pan. EMNLP 2024 Ergebnisse. [PDF]
SLMs für LLM -Argumentation
- Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu und Julian McAuley. Kleine Modelle sind wertvolle Plug-Ins für große Sprachmodelle. ACL 2024 Befunde. [PDF]
- Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei, Xing Xie, Weizhu Chen und Yue Zhang. Auf überwachendes Wissen macht große Sprachmodelle in den Kontext-Lernenden besser. ICLR 2024 Poster. [PDF]
- Zhuofeng Wu, er Bai, Aonan Zhang, Jiatao Gu, VG Vydiswaran, Navdeep Jaitly und Yizhe Zhang. Divide-or-Conquer? Welchen Teil sollten Sie Ihre LLM destillieren? EMNLP 2024 Ergebnisse. [PDF]
SLMs zur Linderung des Urheberrechts und der Privatsphäre von LLMs
- Tianlin Li, Qian Liu, Tianyu Pang, Chao du, Qing Guo, Yang Liu und Min Lin. Reinigen von großsprachigen Modellen durch Ensembling eines kleinen Sprachmodells. ARXIV 2024. [PDF]
SLMs zum Extrahieren von LLM -Eingaben
- Yiming Zhang, Nicholas Carlini und Daphne Ippolito. Effektive schnelle Extraktion aus Sprachmodellen. Colm 2024 [PDF]
- Zeyang Sha und Yang Zhang. Erfordernde Angriffe gegen große Sprachmodelle. Arxiv (2024). [PDF]
- Collin Zhang, John X Morris und Vitaly Shmatikov. Extrahieren von Eingabeaufforderungen durch Inverting von LLM -Ausgängen. [PDF]
SLMs für Feinabstimmung LLMs
- Eric Mitchell, Rafael Rafailov, Architektur Sharma, Chelsea Finn und Christopher D Manning. 2024. Ein Emulator für Feinabstimmungsmodelle mit kleinen Sprachmodellen. ICLR 2024. [PDF]
- Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi und Noah A Smith. 2024. Tuning -Sprachmodelle nach Proxy. Colm 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen und Jingbo Shang. 2024. Kleinere Sprachmodelle können Trainingsdaten für Anweisungen für größere Sprachmodelle auswählen. ACL 2024 Befunde. [PDF]
- Yongheng Deng, Ziqing Qiao, Ju Ren, Yang Liu und Yaoxue Zhang. 2023. gegenseitige Verbesserung großer und kleiner Sprachmodelle mit Cross-Silo-Wissenstransfer. ARXIV 2023. [PDF]
- Smalltolarge (S2L): Skalierbare Datenauswahl für Feinabstimmungsmodelle durch Zusammenfassung der Trainingsbahnen kleiner Modelle. Yu Yang · Siddhartha Mishra · Jeffrey Chiang · Baharan Mirzasoleiman. NIPS 2024 Poster. [PDF]
- Schwache-zu-starken Suche: Richtige große Sprachmodelle durch die Suche nach kleinen Sprachmodellen. Zhanhui zhou · zhixuan liu · jie liu · zhichen dong · chao yang · yu qiao. NIPS 2024 Poster. [PDF]
SLMs für LLM -Sicherheit
- LLAMA Guard: LLM-basiertes Eingabebereich für Human-AI-Gespräche. Meta Arxiv 2024 [PDF]
- SLM als Guardian: Pionier -KI -Sicherheit mit kleinem Sprachmodell. Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park. EMNLP 2024. [PDF]
SLM für die LLM -Bewertung
- Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin und Liang Zhan . 2024. Folie: Ein Framework, das kleine und große Sprachmodelle für die Bewertung der Dialoge mit offener Domänen integriert . ACL 2024 Befunde. [PDF]
- Semantische Unsicherheit: Sprachintervarianzen zur Unsicherheitsschätzung in der Erzeugung der natürlichen Sprache. Lorenz Kuhn, Yarin Gal, Sebastian Farquhar. ICLR 2023. [PDF]
- SelfCheckgpt: Null-Ressource-Black-Box-Halluzinationserkennung für generative Großsprachenmodelle. Potsawee Manakul, Adian Liusie, Mark Gales. EMNLP 2023 Main. [PDF]
- Proxylm: Vorhersage der Sprachmodellleistung bei mehrsprachigen Aufgaben über Proxy -Modelle. David Anugraha, Genta Indra Winata, Chenyue Li, Patrick Amadeus Irawan, En-Shiun Annie Lee. ARXIV 2024. [PDF]
- FACTSCORE: Feinkörnige atomare Bewertung der sachlichen Präzision in der Erzeugung von Langstücken. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hannaneh Hajishirzi. EMNLP 2023 Main. [PDF]
- Schauen Sie vor dem Sprung: Eine explorative Untersuchung der Unsicherheitsmessung für große Sprachmodelle. Yuheng Huang, Jiyang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, Lei Ma Arxiv 2023. [PDF]
Sterngeschichte


