Enquête SLM
Une étude complète des modèles de petits langues: technologie, applications sur les appareils, efficacité, améliorations pour les LLM et fiabilité
Ce repo inclut les articles discutés dans notre dernier article d'enquête sur les modèles de petits langues.
Lisez le papier complet ici: lien papier
Nouvelles
- 2024/11/04: La première version de notre enquête est sur Arxiv!
Référence
Si notre enquête est utile pour vos recherches, veuillez citer notre article:
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
Aperçu des SLM
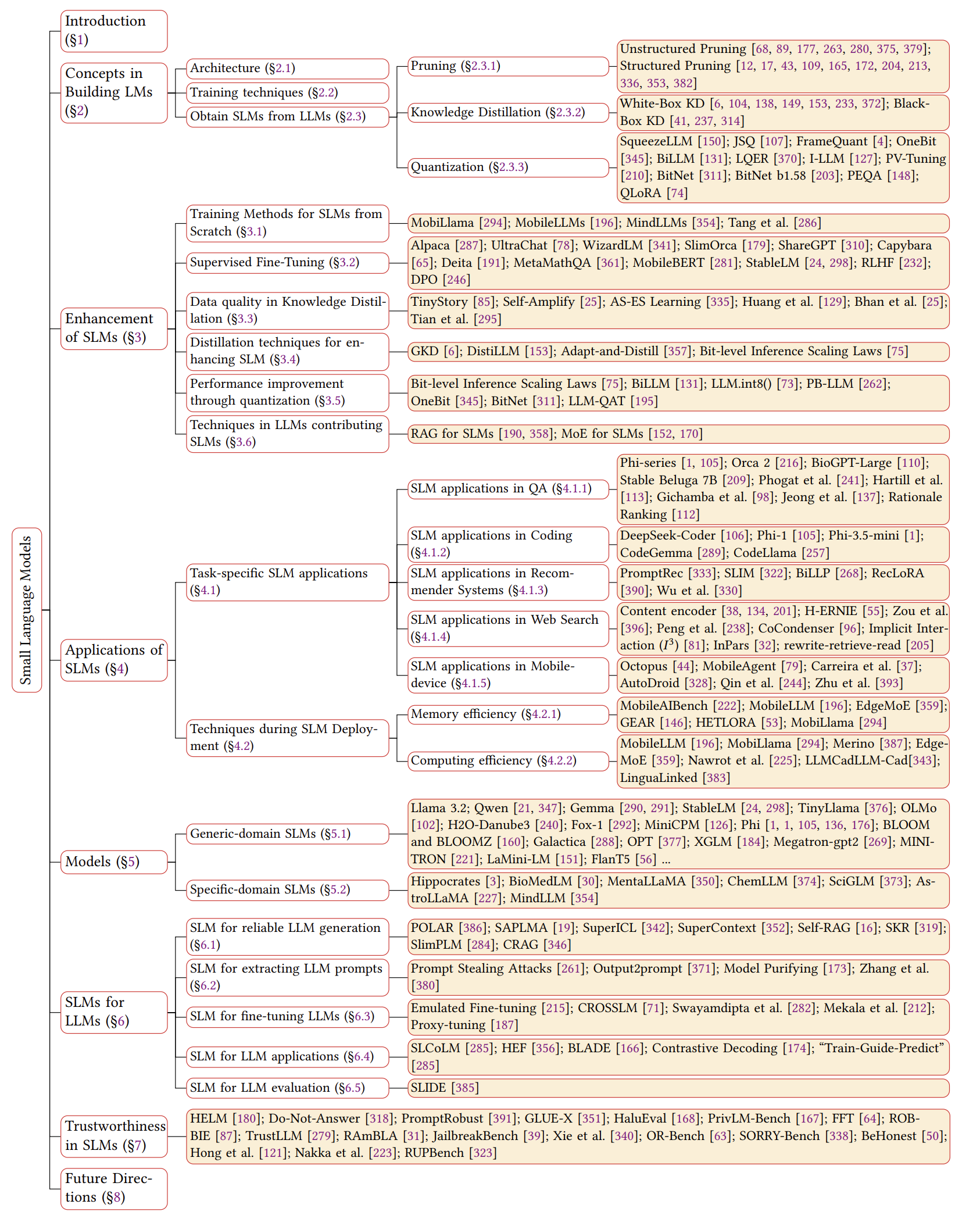
Chronologie des SLM
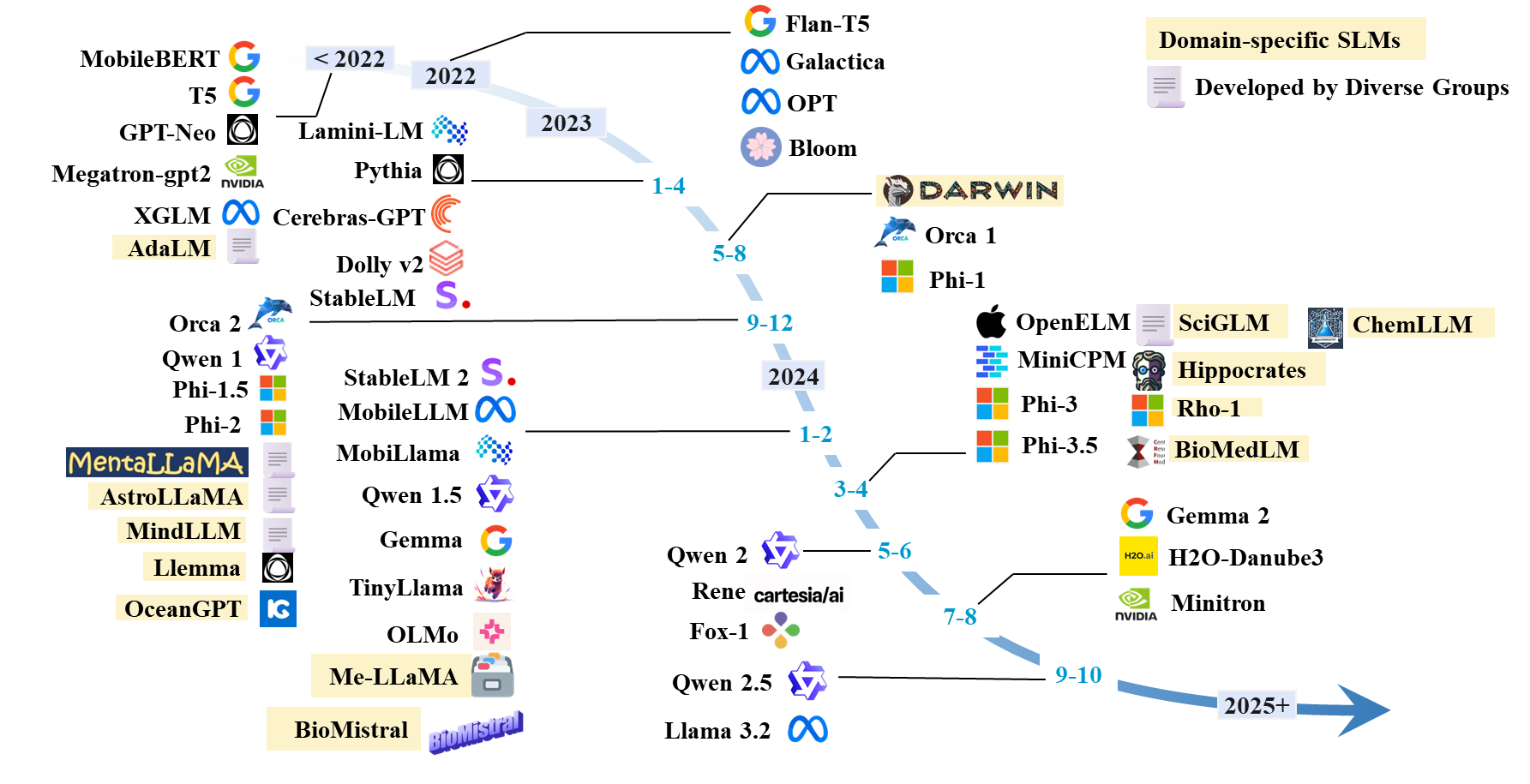
Liste de papier SLMS
SLMS existants
| Modèle | #Params | Date | Paradigme | Domaine | Code | Modèle HF | Papier / blog |
|---|
| Lama 3.2 | 1B; 3B | 2024.9 | Prétraitement | Générique | Github | HF | Blog |
| Qwen 1 | 1.8b; 7B; 14B; 72b | 2023.12 | Prétraitement | Générique | Github | HF | Papier |
| Qwen 1.5 | 0,5b; 1.8b; 4B; 7B; 14B; 32b; 72b | 2024.2 | Prétraitement | Générique | Github | HF | Papier |
| Qwen 2 | 0,5b; 1,5b; 7B; 57b; 72b | 2024.6 | Prétraitement | Générique | Github | HF | Papier |
| Qwen 2.5 | 0,5b; 1,5b; 3B; 7B; 14B; 32b; 72b | 2024.9 | Prétraitement | Générique | Github | HF | Papier |
| Gemme | 2B; 7b | 2024.2 | Prétraitement | Générique | | HF | Papier |
| Gemma 2 | 2B; 9b; 27B | 2024.7 | Prétraitement | Générique | | HF | Papier |
| H2O-Danube3 | 500m; 4B | 2024.7 | Prétraitement | Générique | | HF | Papier |
| LLM-NEO | 1b | 2024.11 | Formation continue | Générique | | HF | Papier |
| Renard | 1.6b | 2024.6 | Prétraitement | Générique | | HF | Blog |
| Rabot | 1.3b | 2024.5 | Prétraitement | Générique | | HF | Papier |
| Minimicpm | 1.2b; 2.4b | 2024.4 | Prétraitement | Générique | Github | HF | Papier |
| Olmo | 1B; 7b | 2024.2 | Prétraitement | Générique | Github | HF | Papier |
| Minuscule | 1b | 2024.1 | Prétraitement | Générique | Github | HF | Papier |
| Phi-1 | 1.3b | 2023.6 | Prétraitement | Codage | | HF | Papier |
| Phi-1,5 | 1.3b | 2023.9 | Prétraitement | Générique | | HF | Papier |
| Phi-2 | 2.7b | 2023.12 | Prétraitement | Générique | | HF | Papier |
| Phi-3 | 3.8b; 7B; 14B | 2024.4 | Prétraitement | Générique | | HF | Papier |
| PHI-3.5 | 3.8b; 4.2b; 6.6b | 2024.4 | Prétraitement | Générique | | HF | Papier |
| Ouvrir | 270m; 450m; 1.1b; 3B | 2024.4 | Prétraitement | Générique | Github | HF | Papier |
| Mobilma | 0,5b; 0,8b | 2024.2 | Prétraitement | Générique | Github | HF | Papier |
| Mobilellm | 125m; 350m | 2024.2 | Prétraitement | Générique | Github | HF | Papier |
| Stablel | 3B; 7b | 2023.4 | Prétraitement | Générique | Github | HF | Papier |
| Stablel 2 | 1.6b | 2024.2 | Prétraitement | Générique | Github | HF | Papier |
| Cerebras-gpt | 111m-13b | 2023.4 | Prétraitement | Générique | | HF | Papier |
| Bloom, Bloomz | 560m; 1.1b; 1.7b; 3B; 7.1b; 176b | 2022.11 | Prétraitement | Générique | | HF | Papier |
| OPTER | 125m; 350m; 1.3b; 2.7b; 5.7b | 2022.5 | Prétraitement | Générique | | HF | Papier |
| XGlm | 1.7b; 2.9b; 7.5b | 2021.12 | Prétraitement | Générique | Github | HF | Papier |
| Gpt-neo | 125m; 350m; 1.3b; 2.7b | 2021.5 | Prétraitement | Générique | Github | | Papier |
| Mégatron-gpt2 | 355m; 2.5b; 8.3b | 2019.9 | Prétraitement | Générique | Github | | Papier, blog |
| Minitrons | 4B; 8B; 15B | 2024.7 | Élagage et distillation | Générique | Github | HF | Papier |
| Minime | 7b | 2024.7 | Prétraitement | Générique | Github | HF | Papier |
| Mini-2 | 1B; 3B | 2023.12 | Prétraitement | Générique | Github | HF | Papier |
| Minima | 3B | 2023.11 | Élagage et distillation | Générique | Github | HF | Papier |
| Orque 2 | 7b | 2023.11 | Distillation | Générique | | HF | Papier |
| Dolly-V2 | 3B; 7B; 12b | 2023.4 | Réglage des instructions | Générique | Github | HF | Blog |
| Lamini-lm | 61m-7b | 2023.4 | Distillation | Générique | Github | HF | Blog |
| Flant spécialisé5 | 250m; 760m; 3B | 2023.1 | Réglage des instructions | Générique (mathématiques) | Github | - | Papier |
| Flant5 | 80m; 250m; 780m; 3B | 2022.10 | Réglage des instructions | Générique | Gihub | HF | Papier |
| T5 | 60m; 220m; 770m; 3B; 11b | 2019.9 | Prétraitement | Générique | Github | HF | Papier |
Architecture SLM
- Transformateur: l'attention est tout ce dont vous avez besoin. Ashish Vaswani . Neirips 2017.
- Mamba 1: Mamba: modélisation de séquences linéaires avec des espaces d'état sélectifs. Albert Gu et Tri Dao . Colm 2024. [Paper].
- MAMBA 2: Les transformateurs sont SSMS: modèles généralisés et algorithmes efficaces grâce à la dualité d'espace d'état structurée. Tri Dao et Albert Gu . ICML 2024. [Paper] [Code]
Amélioration de SLM
Formation à partir de zéro
- Mobillama: "Mobilma: vers un GPT précis et léger entièrement transparent" . Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan. Arxiv 2024. [Paper] [github] [HuggingFace]
- Mobilellm: "Mobilellm: Optimiser les modèles de langage de paramètres inférieurs à un million pour les cas d'utilisation sur les appareils" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi
- Repenser l'optimisation et l'architecture pour les modèles de langage minuscules. Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han et Yunhe Wang. ICML 2024. [Paper] [Code]
- Mindllm: "Mindllm: modèle de langage léger pré-formation à partir de zéro, évaluations et applications de domaine" . Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, Yang Gao . Arxiv 2023. [Paper] [HuggingFace]
Réglage fin supervisé
- Optimisation directe des préférences: votre modèle de langue est secrètement un modèle de récompense. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon et Chelsea Finn. NEIRIPS, 2024. [Paper] [Code]
- Amélioration des modèles de langage de chat en étendant les conversations pédagogiques de haute qualité. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun et Bowen Zhou. EMNLP 2023. [Paper] [Code]
- Slimorca: un ensemble de données ouvert des traces de raisonnement de flan augmenté GPT-4, avec vérification. Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong et "Teknium". Huggingface, 2023. [Données]
- Stanford Alpaca: un modèle LLAMA suivant les instructions. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang et Tatsunori B. Hashimoto. GitHub, 2023. [Blog] [GitHub] [HuggingFace]
- OpenChat: Faire progresser les modèles de langue open source avec des données de qualité mixte. Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song et Yang Liu. ICLR, 2024. [Paper] [Code] [HuggingFace]
- Modèles de la langue de formation pour suivre les instructions avec les commentaires humains. Long Oulang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Paul F. Christike, Jande, Maddie, Amanda Aska Ryan Lowe. Neirips, 2022. [Papier]
- RLHF: "Modèles de la langue de formation pour suivre les instructions avec les commentaires humains" . Long Oulang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal Lowe. 2022. [Papier]
- Mobilebert: "Mobilebert: un Bert agnostique de tâche compact pour les appareils limitées en ressources" . Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou. ACL 2020. [Paper] [GitHub] [HuggingFace]
- Les modèles de langue sont des apprenants multitâches non surveillés. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Openai Blog, 2019. [Paper]
Qualité des données dans KD
- TinyStory: "Tinystories: Quelle est la petite taille des modèles de langue et parle toujours un anglais cohérent?" . Ronen Eldan, Yuanzhi Li. 2023. [Paper] [HuggingFace]
- As-ES: "As-ES Apprentissage: vers un apprentissage de COT efficace dans les petits modèles" . Nuwa Xi, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu. 2024. [Papier]
- Auto-amplify: "auto-amplifier: améliorer les modèles de petits langues avec des explications auto-post hoc" . Milan Bhan, Jean-Noel Vittaut, Nicolas Chesneau, Marie-Jeanne Lesot. 2024. [Papier]
- Les modèles de grandes langues peuvent s'auto-impression. Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu et Jiawei Han. EMNLP 2023. [Papier]
- Vers l'auto-amélioration des LLM via l'imagination, la recherche et la critique. Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi et Dong Yu. Neirips 2024. [Paper] [Code]
Distillation pour SLM
- GKD: "Distillation sur la politique des modèles de langue: apprendre des erreurs auto-générées" . Rishabh Agarwal et al. ICLR 2024. [Papier]
- Distilllm: "Distillm: Vers la distillation rationalisée pour les modèles de grande langue" . Jongwoo Ko et al. ICML 2024. [Paper] [GitHub]
- Adapt-and-Distill: "Adapt-and-Distill: Développer de petits modèles de langage pré-étendus rapides et efficaces pour les domaines" . Yunzhi Yao et al. ACL2021. [Papier] [github]
- AKL: "Repenser la divergence de Kullback-Lebler dans la distillation des connaissances pour les modèles de grands langues" . Taiqiang Wu, Chaofan Tao, Jahahao Wang, Runming Yang, Zhe Zhao, Ngai Wong. Arxiv 2024. [Paper] [GitHub]
- Distillation héritée du poids pour la compression de Bert agnostique de la tâche Taiqiang WU, Cheng Hou, Shanshan Lao, Jiayi Li, Ngai Wong, Zhe Zhao, Yujiu Yang Naacl, 2024, [papier] [Code]
Quantification
- Smoothand: "Smoothand: Quantification post-entraînement précise et efficace pour les modèles de gros langues" . Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han. ICML 2023. [Paper] [github] [diapositives] [VIDEO]
- Billm: "Billm: repousser la limite de la quantification post-formation pour les LLM" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [Paper] [GitHub]
- LLM-QAT: "LLM-QAT: Formation de conscience de quantification sans données pour les modèles de grande langue" . Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra. 2023. [Papier]
- PB-LLM: "PB-LLM: Modèles de grande langue partiellement binarisés" . Zhihang Yuan, Yuzhang Shang, Zhen Dong. ICLR 2024. [Paper] [GitHub]
- Onebit: "Onebit: Vers des modèles de langues très faibles extrêmement faibles" . Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che. Neirips 2024. [Papier]
- Bitnet: "Bitnet: mise à l'échelle des transformateurs 1 bits pour les grands modèles de langue" . Hongyu Wang, Shuming MA, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao MA, fan yang, ruiping wang, yi wu, furu wei. 2023. [Papier]
- Bitnet B1.58: "L'ère des LLMS 1 bits: tous les modèles de langage grand sont en 1,58 bits" . Shuming MA, Hongyu Wang, Lingxiao MA, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei. 2024. [Papier]
- Squeezellm: "Squeezellm: Quantification dense et séparée" . Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer. ICML 2024. [Paper] [GitHub]
- JSQ: "Compression des modèles de grande langue par la sparsification et la quantification conjointes" . Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, Xianglong Liu. ICML 2024. [Paper] [GitHub]
- FrameQuant: "Framequant: quantification flexible à faible bit pour les transformateurs" . Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh. 2024. [Paper] [GitHub]
- Billm: "Billm: repousser la limite de la quantification post-formation pour les LLM" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [Paper] [GitHub]
- LQER: "LQER: Reconstruction d'erreur de quantification de faible rang pour LLMS" . Cheng Zhang, Jianyi Cheng, George A. Constantinides, Yiren Zhao. ICML 2024. [Paper] [GitHub]
- I-llm: "I-llm: inférence efficace en entier uniquement pour les modèles de langage à faible bit entièrement qualifiés" . Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou. 2024. [Paper] [GitHub]
- PV-TUNING: "PV-TUNING: Au-delà de l'estimation directe pour la compression LLM extrême" . Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik. 2024. [Papier]
- PEQA: "Fonction d'administration économe en mémoire de modèles de langage grand compressé via une quantification entière de sub-4 bits" . Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, SE Jung Kwon, Dongsoo Lee. Nips 2023. [Papier]
- Qlora: "Qlora: Finetuning efficace des LLM quantifiés" . Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke ZettlemoyerAuthors Info & affirmations. NIPS 2023. [Paper] [GitHub]
Techniques LLM pour les SLM
- Ma et al .: "Le modèle de grand langage n'est pas un bon extracteur d'informations à quelques coups, mais un bon remaner pour des échantillons durs!" . Yubo MA, Yixin Cao, Yongching Hong, Aixin Sun. EMNLP 2023. [Paper] [GitHub]
- MOQE: "Mélange d'experts quantifiés (MOQE): Effet complémentaire de la quantification et de la robustesse faibles-bits" . Young Jin Kim, Raffy Fahim, Hany Hassan Awadalla. 2023. [Papier]
- SLM-RAG: "Les modèles de petits langues avec une génération de récupération peuvent-ils remplacer de grands modèles de langue lors de l'apprentissage de l'informatique?" . Suqing Liu, Zezhu Yu, Feiran Huang, Yousef Bulbulia, Andreas Bergen, Michael Liut. Iticse 2024. [Papier]
Applications SLM spécifiques à la tâche
SLM en QA
- Alpaga: "Alpaga: un modèle de suivi des instructions fort et reproductible" . Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto. 2023. [Paper] [GitHub] [HuggingFace] [Site Web]
- Stable Beluga 7b: "Stable Beluga 2" . Mahan, Dakota et Carlow, Ryan et Castricato, Louis et Cooper, Nathan et Laforte, Christian. 2023. [Huggingface]
- Biogpt ajusté Guo et al .: "Amélioration des modèles de petits langues sur PubMedqa via une augmentation générative des données" . Zhen Guo, Peiqi Wang, Yanwei Wang, Shangdi Yu. 2023. [Papier]
- SLMS financiers: "Affinement des modèles linguistiques plus petits pour la réponse aux questions sur les documents financiers" . Karmvir Singh Phogat Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, Shashishekar Ramakrishna. 2024. [Papier]
- Colbert: "Colbert Retrieval et Ensemble Response Scoring pour la question du modèle de langue répondant" . Alex Gichamba, Tewodros Kederalah Idris, Brian Ebiyau, Eric Nyberg, Teruko Mitamura. IEEE 2024. [Papier]
- T-SAS: "Modèles de petit langage auto-adaptatifs à temps d'essai pour la réponse aux questions" . Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park. ACL 2023. [Paper] [GitHub]
- Classement de justification: "Répondre aux questions invisibles avec des modèles de langage plus petits en utilisant la génération de justification et la récupération dense" . Tim Hartill, Diana Benavides-Prado, Michael Witbrock, Patricia J. Riddle. 2023. [Papier]
SLM en codage
- PHI-3.5-MINI: "Rapport technique PHI-3: un modèle de langue hautement capable localement sur votre téléphone" . Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, ..., Chunyu Wang, Guanhua Wang, Lijuan Wang et al. 2024. [Paper] [HuggingFace] [Site Web]
- Tinyllama: "Tinyllama: un modèle de petit langage open source" . Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu. 2024. [Paper] [HuggingFace] [Demo de chat] [Discord]
- Codellama: "Code Llama: Open Foundation Models for Code" . Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, ..., Niconas Usuniier, Thomas Scialom, Gabriel Synnaeve. 2024. [Paper] [HuggingFace]
- CodeGemma: "CodeGemma: Open Code Modèles basés sur Gemma" . Équipe de Codegemma: Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christopher A. Choquette-Choo, Jingyue Shen, Joe Kelley, Scottij Bansal, ..., Kathy Korevec, Kelly Schaefer, Scott Huffman. 2024. [Paper] [HuggingFace]
SLM en recommandation
- PROMPTREC: "Les modèles de petits langues pourraient-ils servir de recommandateurs? Vers les recommandations de démarrage à froid centrées sur les données" . Xuansheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu. 2024. [Paper] [GitHub]
- SLIM: "Les petits modèles de langue peuvent-ils être de bons raisonneurs pour une recommandation séquentielle?" . Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, Xiao Wang. 2024. [Papier]
- BILLP: "Les modèles de grands langues sont des planificateurs apprenables pour une recommandation à long terme" . Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, Fuli Feng. 2024. [Papier]
- Une fois: "Une fois: augmenter la recommandation basée sur le contenu avec des modèles de langage à grande source ouverte et fermée" . Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu. WSDM 2024. [Paper] [GitHub]
- Reclora: "Adaptation à faible rang personnalisée à vie des modèles de grande langue pour recommandation" . Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang. 2024. [Papier]
SLM dans la recherche Web
- Encodeur de contenu: "Tâches de pré-formation pour l'intégration de la récupération à grande échelle" . Wei-Cheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, Sanjiv Kumar. ICLR 2020. [Papier]
- Poly-Encoders: "Poly-Encoders: Architectures de transformateur et stratégies de pré-formation pour une notation multi-phrase rapide et précise" . Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, Jason Weston. ICLR 2020. [Papier]
- Twin-Bert: "Twinbert: Distilling Knowledge to Twin-structuré des modèles Bert pour une récupération efficace" . Wenhao Lu, Jian Jiao, Ruofei Zhang. 2020. [Papier]
- H-ERNIE: "H-ERNIE: Un modèle de langue pré-formé multi-granularité pour la recherche Web" . Xiaokai Chu, Jiashu Zhao, Lixin Zou, Dawei Yin. Sigir 2022. [Papier]
- Ranker: "Passage Re-Ranking avec Bert" . Rodrigo Nogueira, Kyunghyun Cho. 2019. [Paper] [Github]
- Réécriture: "Réécriture de la requête pour les modèles de grande langue de récupération à la récupération" . Xinbei MA, Yeyun Gong, Pengcheng He, Hai Zhao, Nan Duan. EMNLP2023. [Papier] [github]
SLM dans le disque mobile
- Octopus: "Octopus: modèle de langage sur périphérique pour l'appel de fonction des API logiciels" . Wei Chen, Zhiyuan Li, Mingyuan MA. 2024. [Paper] [HuggingFace]
- MobileAgent: "Mobile-Agent-V2: Assistant de fonctionnement de l'appareil mobile avec une navigation efficace via une collaboration multi-agents" . Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang. 2024. [Paper] [GitHub] [HuggingFace]
- Révolutionner l'interaction mobile: "Révolutionner l'interaction mobile: activer un paramètre de 3 milliards GPT LLM sur mobile" . Samuel Carreira, Tomás Marques, José Ribeiro, Carlos Grilo. 2023. [Papier]
- Autodroid: "Autodroid: Automatisation des tâches alimentée par LLM dans Android" . Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, Yunxin Liu. 2023. [Papier]
- Agent à disque pour la réécriture de texte: "Vers un agent à disque pour la réécriture de texte" . Yun Zhu, Yinxiao Liu, Felix Stahlberg, Shankar Kumar, Yu-Hui Chen, Liangchen Luo, Lei Shu, Renjie Liu, Jindong Chen, Lei Meng. 2023. [Papier]
Techniques d'optimisation de déploiement sur dispositif
Optimisation de l'efficacité de la mémoire
- Edge-llm: "Edge-llm: permettant une adaptation efficace du modèle de langue grande sur les périphériques Edge via une compression unifiée couche-couches et un réglage et un vote de couche adaptatif" . Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin. 2024. [Paper] [GitHub]
- LLM-PQ: "LLM-PQ: servant LLM sur des grappes hétérogènes avec partition consacrée à la phase et quantification adaptative" . Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu. 2024. [Paper] [GitHub]
- AWQ: "AWQ: quantification de poids de l'activation pour la compression et l'accélération LLM" . Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han. MLSYS 2024. [Paper] [GitHub]
- MobileAibench: "MobileAibench: Benchmarking LLMS et LMMS pour les cas d'utilisation à disque" . Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Caiming, Zuxin Liu, Ming Zhu, Huan Wang, Caiming, Zuxin Liu, Ming Zhu, Huan Wang, Caiming, Zuxin LiU, Silvio Savaresel. 2024. [Paper] [GitHub]
- Mobilellm: "Mobilellm: Optimiser les modèles de langage de paramètres inférieurs à un million pour les cas d'utilisation sur les appareils" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra. ICML 2024. [Paper] [GitHub] [HuggingFace]
- Edgemoe: "Edgemoe: Inférence rapide sur les appareils de grande langue basée sur MOE" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [Paper] [GitHub]
- Équipement: "Équipement: une recette efficace de compression de cache KV pour une inférence générative presque sans perte de LLM" . Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao. 2024. [Paper] [GitHub]
- DMC: "Compression de mémoire dynamique: Retrofit LLMS pour l'inférence accélérée" . Piotr Nawrot, Adrian łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti. 2024. [Papier]
- Transformateur-Lite: "Transformateur-Lite: déploiement à haut rendement de modèles de gros langues sur les GPU de téléphone mobile" . Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie. 2024. [Papier]
- LLMAAS: "LLM en tant que service système sur les appareils mobiles" . Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu. 2024. [Papier]
Optimisation de l'efficacité du temps d'exécution
- Edgemoe: "Edgemoe: Inférence rapide sur les appareils de grande langue basée sur MOE" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [Paper] [GitHub]
- LLMCAD: "LLMCAD: Inférence rapide et évolutive sur le modèle de grande langue" . Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu. 2023. [Papier]
- Lingualined: "Lingualined: un système d'inférence de modèle de grande langue distribué pour les appareils mobiles" . Junchen Zhao, Yurun Song, Simeng Liu, Ian G. Harris, Sangeetha Abdu Jyothi. 2023 [papier]
SLMS améliore les LLM
SLMS pour l'étalonnage LLM et détection d'hallucination
- Calibrage de grands modèles de langage en utilisant leurs générations uniquement. Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, Seong Joon OH . ACL 2024 Long, [PDF] [Code]
- Apprentissage optimal de Pareto pour estimer les erreurs de modèle de langue importantes. Theodore Zhao, Mu Wei, J. Samuel Preston, Hoifung Poon . ACL 2024 Long, [PDF]
- L'état interne d'un LLM sait quand il ment. Amos Azaria, Tom Mitchell . Résultats EMNLP 2023. [PDF]
- Le petit agent peut également rock! Autonomiser les petits modèles de langage comme détecteur d'hallucination. Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen. EMNLP 2024 Long. [PDF]
- Reconfinicing LLMS du point de vue des pertes de regroupement. Lihu Chen, Alexandre Perez-Lebel, Fabian M. Suchanek, Gaël Varoquaux. Résultats EMNLP 2024. [PDF]
SLMS pour le chiffon LLM
- Petits modèles, grandes idées: tirant parti des modèles de proxy mince pour décider quand et quoi récupérer pour les LLM. Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen. ACL 2024 Long. [PDF] [Code] [HuggingFace]
- Auto-Rag: apprendre à récupérer, générer et critiquer à travers l'auto-réflexion. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi. ICLR 2024 oral. [PDF] [HuggingFace] [Code] [Site Web] [Modèle] [Données]
- LongllMlingua: accélérer et améliorer les LLM dans les scénarios de contexte long via une compression rapide. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-yew Lin, Yuqing Yang, Lili Qiu. Affiche ICLR 2024 Affaire Me-Fomo. [PDF]
- Génération augmentée de récupération corrective. Shi-Qi Yan, Jia-Chen GU, Yun Zhu, Zhen-Hua Ling. Arxiv 2024.1. [pdf] [code]
- Augmentation de récupération guidée par la connaissance de soi pour les modèles de grands langues. Yile Wang, Peng Li, Maosong Sun, Yang Liu. Résultats EMNLP 2023. [pdf] [code]
- Modèles de langage auprès de la récupération dans le contexte. Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. TACL 2023. [PDF] [CODE]
- RA-ISF: Apprendre à répondre et à comprendre de la récupération d'augmentation via l'autonomie itérative. Liu, Yanming et Peng, Xinyue et Zhang, Xuhong et Liu, Weihao et Yin, Jianwei et Cao, Jiannan et Du, Tianyu. Résultats de l'ACL 2024. [PDF]
- Moins est plus: faire des modèles de langage plus petits Retrievers de sous-graphes compétents pour le multi-HOP {KGQA}. Wenyu Huang, Guancheng Zhou, Hongru Wang, Pavlos Vougiouklis, Mirella Lapata, Jeff Z. Pan. Résultats EMNLP 2024. [PDF]
SLMS pour le raisonnement LLM
- Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu et Julian McAuley. Les petits modèles sont de précieux plug-ins pour les modèles de grands langues. Résultats de l'ACL 2024. [PDF]
- Linyi Yang, Shibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen et Yue Zhang. Les connaissances supervisées font de grands modèles de langage de meilleurs apprenants dans le contexte. Affiche ICLR 2024. [PDF]
- Zhuofeng Wu, He Bai, Aonan Zhang, Jiatao Gu, VG Vydiswaran, Navdeep Jaitly et Yizhe Zhang. Diviser ou conquérir? Quelle partie devriez-vous distiller votre LLM? Résultats EMNLP 2024. [PDF]
SLMS pour soulager le droit d'auteur et la confidentialité des LLM
- Tianlin Li, Qian Liu, Tianyu Pang, Chao Du, Qing Guo, Yang Liu et Min Lin. Purifiant les modèles de grandes langues en créant un petit modèle de langue. Arxiv 2024. [PDF]
SLMS pour extraire les invites LLM
- Yiming Zhang, Nicholas Carlini et Daphne Ippolito. Extraction provide efficace des modèles de langage. COLM 2024 [PDF]
- Zeyang Sha et Yang Zhang. Des attaques de vol invite contre les grands modèles de langue. ArXIV (2024). [PDF]
- Collin Zhang, John X Morris et Vitaly Shmatikov. Extraction des invites par les sorties LLM inversantes. [PDF]
SLMS pour le réglage fin des LLM
- Eric Mitchell, Rafael Rafailov, Archit Sharma, Chelsea Finn et Christopher D Manning. 2024. Un émulateur pour les modèles de gros langage affinés à l'aide de petits modèles de langage. ICLR 2024. [PDF]
- Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi et Noah A Smith. 2024. Tapiter des modèles de langue par proxy. COLM 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen et Jingbo Shang. 2024. Les modèles de langage plus petits sont capables de sélectionner des données de formation d'instruction pour les modèles de langage plus grands. Résultats de l'ACL 2024. [PDF]
- Yongheng Deng, Ziqing Qiao, Ju Ren, Yang Liu et Yaoxue Zhang. 2023. Amélioration mutuelle des modèles de grands et petits langues avec transfert de connaissances inter-silo. Arxiv 2023. [PDF]
- Smalltolarge (S2L): Sélection de données évolutive pour le réglage des modèles de langage fin en résumant les trajectoires d'entraînement de petits modèles. Yu Yang · Siddhartha Mishra · Jeffrey Chiang · Baharan Mirzasoleiman. Affiche Nips 2024. [PDF]
- Recherche faible à forte: Alignez les modèles de grands langues via la recherche sur des modèles de petits langues. Zhanhui Zhou · Zhixuan liu · jie liu · zhichen dong · chao yang · yu qiao. Affiche Nips 2024. [PDF]
SLMS pour la sécurité LLM
- Llama Guard: sauvegarde de sortie d'entrée basée sur LLM pour les conversations humaines-AI. Meta Arxiv 2024 [PDF]
- SLM en tant que gardien: Pionnier de la sécurité de l'IA avec un modèle de petit langage. Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park. EMNLP 2024. [PDF]
SLM pour l'évaluation LLM
- Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin et Liang Zhan . 2024. Diapositive: un cadre intégrant des modèles de petits et grands langues pour l'évaluation des dialogues du domaine ouvert . Résultats de l'ACL 2024. [PDF]
- Incertitude sémantique: invariances linguistiques pour l'estimation de l'incertitude dans la génération du langage naturel. Lorenz Kuhn, Yarin Gal, Sebastian Farquhar. ICLR 2023. [PDF]
- SelfCheckgpt: Détection d'hallucination noire de ressources zéro pour les modèles génératifs de grande langue. Potsawee Manakul, Adian Liusie, Mark Gales. EMNLP 2023 Main. [PDF]
- Proxylm: prédire les performances du modèle de langue sur des tâches multilingues via des modèles proxy. David Anugraha, Genta Indra Winata, Chenyue Li, Patrick Amadeus Irawan, en-shiun Annie Lee. Arxiv 2024. [PDF]
- FactsCore: Évaluation atomique à grain fin de la précision factuelle dans la génération de texte longue. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hannaneh Hajishirzi. EMNLP 2023 Main. [PDF]
- Regardez avant de sauter: une étude exploratoire de la mesure de l'incertitude pour les grands modèles de langage. Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, Lei Ma Arxiv 2023. [PDF]
Histoire des étoiles


