Pesquisa SLM
Uma pesquisa abrangente de pequenos modelos de idiomas: tecnologia, aplicações no dispositivo, eficiência, aprimoramentos para LLMs e confiabilidade
Este repositório inclui os documentos discutidos em nosso mais recente artigo de pesquisa sobre modelos de idiomas pequenos.
Leia o papel completo aqui: link de papel
Notícias
- 2024/11/04: A primeira versão da nossa pesquisa é no Arxiv!
Referência
Se nossa pesquisa for útil para sua pesquisa, cite gentilmente nosso artigo:
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
Visão geral do SLMS
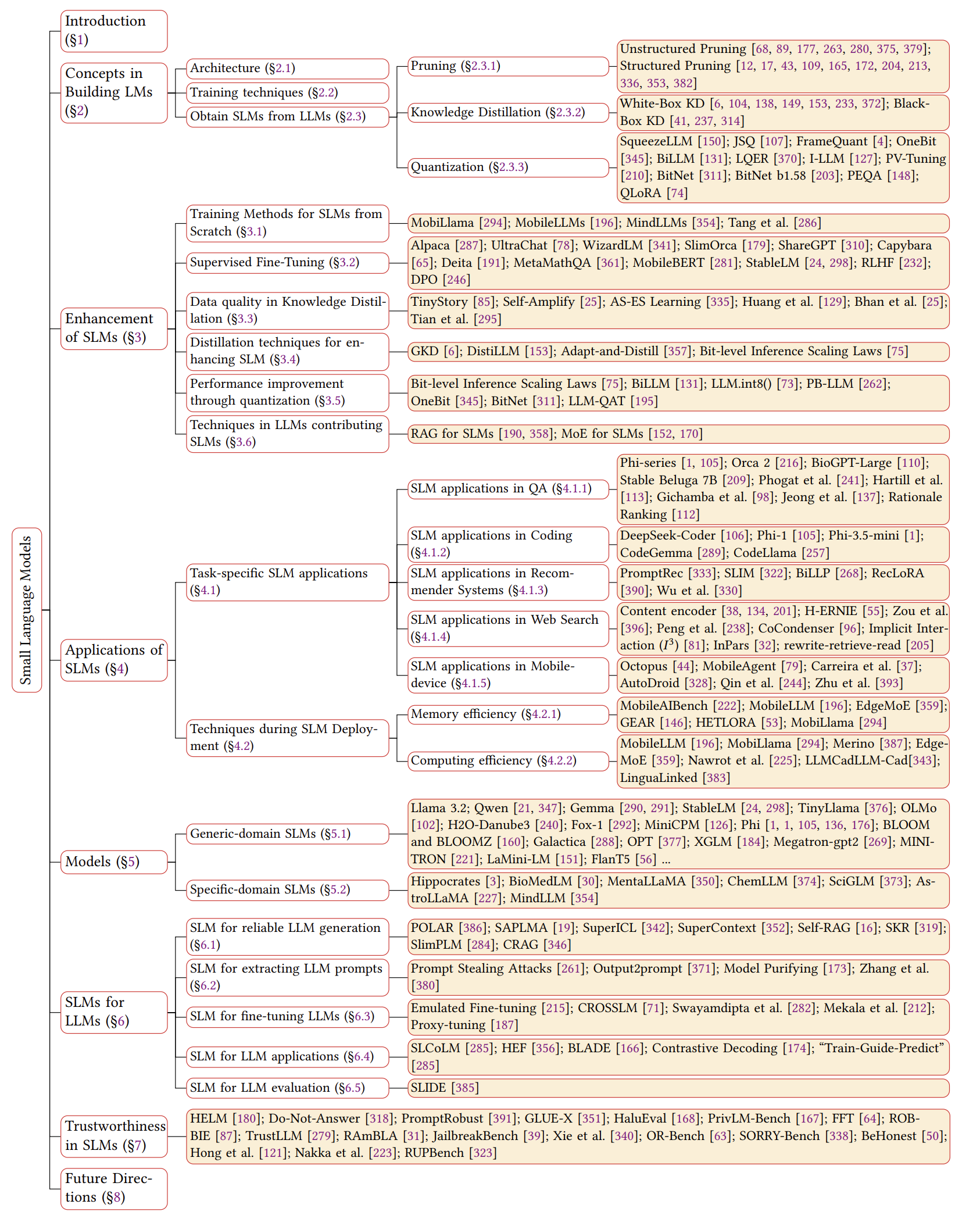
Linha do tempo do SLMS
Lista de papel SLMS
SLMS existente
| Modelo | #Params | Data | Paradigma | Domínio | Código | Modelo HF | Papel/blog |
|---|
| LLAMA 3.2 | 1b; 3b | 2024.9 | Pré-treino | Genérico | Github | HF | Blog |
| Qwen 1 | 1.8b; 7b; 14b; 72b | 2023.12 | Pré-treino | Genérico | Github | HF | Papel |
| Qwen 1.5 | 0,5b; 1.8b; 4b; 7b; 14b; 32b; 72b | 2024.2 | Pré-treino | Genérico | Github | HF | Papel |
| Qwen 2 | 0,5b; 1.5b; 7b; 57b; 72b | 2024.6 | Pré-treino | Genérico | Github | HF | Papel |
| Qwen 2.5 | 0,5b; 1.5b; 3b; 7b; 14b; 32b; 72b | 2024.9 | Pré-treino | Genérico | Github | HF | Papel |
| Gemma | 2b; 7b | 2024.2 | Pré-treino | Genérico | | HF | Papel |
| Gemma 2 | 2b; 9b; 27b | 2024.7 | Pré-treino | Genérico | | HF | Papel |
| H2O-Danube3 | 500m; 4b | 2024.7 | Pré-treino | Genérico | | HF | Papel |
| LLM-NEO | 1b | 2024.11 | Treinamento contínuo | Genérico | | HF | Papel |
| Fox-1 | 1.6b | 2024.6 | Pré-treino | Genérico | | HF | Blog |
| RENE | 1.3b | 2024.5 | Pré-treino | Genérico | | HF | Papel |
| Minicpm | 1.2b; 2.4b | 2024.4 | Pré-treino | Genérico | Github | HF | Papel |
| Olmo | 1b; 7b | 2024.2 | Pré-treino | Genérico | Github | HF | Papel |
| Tinyllama | 1b | 2024.1 | Pré-treino | Genérico | Github | HF | Papel |
| Phi-1 | 1.3b | 2023.6 | Pré-treino | Codificação | | HF | Papel |
| Phi-1.5 | 1.3b | 2023.9 | Pré-treino | Genérico | | HF | Papel |
| Phi-2 | 2.7b | 2023.12 | Pré-treino | Genérico | | HF | Papel |
| Phi-3 | 3.8b; 7b; 14b | 2024.4 | Pré-treino | Genérico | | HF | Papel |
| Phi-3.5 | 3.8b; 4.2b; 6.6b | 2024.4 | Pré-treino | Genérico | | HF | Papel |
| OpenElm | 270m; 450m; 1.1b; 3b | 2024.4 | Pré-treino | Genérico | Github | HF | Papel |
| Mobillama | 0,5b; 0,8b | 2024.2 | Pré-treino | Genérico | Github | HF | Papel |
| Mobilellm | 125m; 350m | 2024.2 | Pré-treino | Genérico | Github | HF | Papel |
| Stablelm | 3b; 7b | 2023.4 | Pré-treino | Genérico | Github | HF | Papel |
| Stablelm 2 | 1.6b | 2024.2 | Pré-treino | Genérico | Github | HF | Papel |
| Cerebras-Gpt | 111M-13B | 2023.4 | Pré-treino | Genérico | | HF | Papel |
| Bloom, Bloomz | 560m; 1.1b; 1.7b; 3b; 7.1b; 176b | 2022.11 | Pré-treino | Genérico | | HF | Papel |
| OPTAR | 125m; 350m; 1.3b; 2.7b; 5.7b | 2022.5 | Pré-treino | Genérico | | HF | Papel |
| Xglm | 1.7b; 2.9b; 7.5b | 2021.12 | Pré-treino | Genérico | Github | HF | Papel |
| GPT-Neo | 125m; 350m; 1.3b; 2.7b | 2021.5 | Pré-treino | Genérico | Github | | Papel |
| Megatron-GPT2 | 355m; 2.5b; 8.3b | 2019.9 | Pré-treino | Genérico | Github | | Papel, blog |
| Minitron | 4b; 8b; 15b | 2024.7 | Poda e destilação | Genérico | Github | HF | Papel |
| Minimix | 7b | 2024.7 | Pré-treino | Genérico | Github | HF | Papel |
| Minima-2 | 1b; 3b | 2023.12 | Pré-treino | Genérico | Github | HF | Papel |
| Mínimos | 3b | 2023.11 | Poda e destilação | Genérico | Github | HF | Papel |
| Orca 2 | 7b | 2023.11 | Destilação | Genérico | | HF | Papel |
| Dolly-v2 | 3b; 7b; 12b | 2023.4 | Ajuste de instrução | Genérico | Github | HF | Blog |
| Lamini-lm | 61M-7B | 2023.4 | Destilação | Genérico | Github | HF | Blog |
| Flant Specialized5 | 250m; 760m; 3b | 2023.1 | Ajuste de instrução | Genérico (matemática) | Github | - | Papel |
| Flant5 | 80m; 250m; 780m; 3b | 2022.10 | Ajuste de instrução | Genérico | Gihub | HF | Papel |
| T5 | 60m; 220m; 770m; 3b; 11b | 2019.9 | Pré-treino | Genérico | Github | HF | Papel |
Arquitetura SLM
- Transformador: Atenção é tudo o que você precisa. Ashish Vaswani . Neurips 2017.
- Mamba 1: Mamba: modelagem de sequência de tempo linear com espaços de estado seletivos. Albert Gu e Tri Dao . Colm 2024. [Papel].
- Mamba 2: Os transformadores são SSMs: modelos generalizados e algoritmos eficientes através da dualidade de espaço de estado estruturado. Tri Dao e Albert Gu . ICML 2024. [Paper] [Código]
Aprimoramento para SLM
Treinamento do zero
- MOBILLAMA: "MOBILLAMA: Rumo ao GPT preciso e leve e totalmente transparente" . Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan. Arxiv 2024. [Paper] [Github] [Huggingface]
- MOBILELLM: "MOBILELLM: Otimizando os modelos de linguagem de parâmetros de sub-bilhões para casos de uso no dispositivo" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra Icml 2024.
- Repensando a otimização e a arquitetura para pequenos modelos de linguagem. Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han e Yunhe Wang. ICML 2024. [Paper] [Código]
- MINDLLM: "Mindllm: modelo de idioma grande de pré-treinamento de grandes idiomas do zero, avaliações e aplicações de domínio" . Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, Yang Gao . Arxiv 2023. [Paper] [Huggingface]
Tuneamento fino supervisionado
- Otimização de preferência direta: seu modelo de idioma é secretamente um modelo de recompensa. Rafael Rafailov, Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon e Chelsea Finn. Neurips, 2024. [Paper] [Código]
- Aprimorando os modelos de linguagem de bate-papo, dimensionando conversas instrucionais de alta qualidade. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun e Bowen Zhou. EMNLP 2023. [Paper] [Código]
- Slimorca: um conjunto de dados aberto dos traços de raciocínio de flan aumentado GPT-4, com verificação. Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong e "Teknium". Huggingface, 2023. [Dados]
- Stanford Alpaca: Um modelo de llama que segue a instrução. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang e Tatsunori B. Hashimoto. Github, 2023. [Blog] [Github] [Huggingface]
- OpenChat: Avançando modelos de idiomas de código aberto com dados de qualidade mista. Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song e Yang Liu. ICLR, 2024. [Paper] [Code] [Huggingface]
- Treinando modelos de idiomas para seguir as instruções com feedback humano. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, Ryan Lowe. Neurips, 2022. [Papel]
- RLHF: "Treinando modelos de idiomas para seguir as instruções com feedback humano" . Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. 2022. [Papel]
- MobileBert: "MobileBert: um bert agnóstico compacto para dispositivos de recursos limitados" . Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou. ACL 2020. [Paper] [Github] [Huggingface]
- Modelos de idiomas são alunos de multitarefa não supervisionados. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Blog Openai, 2019. [Paper]
Qualidade de dados em kd
- Tinystory: "Tinystories: quão pequenos os modelos de idiomas podem ser e ainda falar inglês coerente?" . Ronen Eldan, Yuanzhi Li. 2023. [Paper] [Huggingface]
- AS-ES: "Aprendizagem AS-ES: Rumo a um aprendizado eficiente em modelos pequenos" . Nuwa Xi, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu. 2024. [Papel]
- Auto-amplificar: "Auto-amplificar: Melhorando os pequenos modelos de idiomas com explicações auto-post hoc" . Milan Bhan, Jean-Noel Vittaut, Nicolas Chesneau, Marie-Jeanne Lesot. 2024. [Papel]
- Modelos de idiomas grandes podem se auto-melhorar. Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu e Jiawei Han. EMNLP 2023. [Papel]
- Em direção ao auto-aperfeiçoamento dos LLMs via imaginação, pesquisa e crítica. Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi e Dong Yu. Neurips 2024. [Paper] [Código]
Destilação para SLM
- GKD: "Destilação na política de modelos de linguagem: aprendendo com erros auto-gerados" . Rishabh Agarwal et al. ICLR 2024. [Papel]
- Destilllm: "destillm: em direção à destilação simplificada para grandes modelos de idiomas" . Jongwoo Ko et al. ICML 2024. [Paper] [Github]
- Adapt-and-Distill: "Adapt-and-Distill: Desenvolvendo modelos de idiomas pequenos, rápidos e eficazes para domínios" . Yunzhi Yao et al. ACL2021. [Papel] [Github]
- AKL: "Repensando a divergência de Kullback-Leibler na destilação do conhecimento para grandes modelos de idiomas" . Taiqiang Wu, Chaofan Tao, Jiahao Wang, Running Yang, Zhe Zhao, Ngai Wong. Arxiv 2024. [Paper] [Github]
- Destilação herdada por peso para a compressão de Bert com tarefas Bert Taiqiang Wu, Cheng Hou, Shanshan Lao, Jiayi Li, Ngai Wong, Zhe Zhao, Yujiu Yang Naacl, 2024, [Paper] [Código]
Quantização
- Smoothquant: "Smoothquant: quantização pós-treinamento precisa e eficiente para modelos de linguagem grande" . Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han. ICML 2023. [Paper] [Github] [Slides] [Vídeo]
- Billm: "Billm: empurrando o limite de quantização pós-treinamento para LLMs" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [Paper] [Github]
- LLM-QAT: "LLM-QAT: Treinamento consciente da quantização sem dados para modelos de idiomas grandes" . Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra. 2023. [Papel]
- Pb-llm: "pb-llm: modelos de linguagem grande parcialmente binarizados" . Zhihang Yuan, Yuzhang Shang, Zhen Dong. ICLR 2024. [Paper] [Github]
- Onebit: "Onebit: em direção a modelos de idiomas grandes extremamente baixos" . Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che. Neurips 2024. [Papel]
- BitNet: "BitNet: dimensionando transformadores de 1 bit para grandes modelos de idiomas" . Hongyu Wang, Shuming MA, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao MA, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei. 2023. [Papel]
- BitNet B1.58: "A era dos LLMs de 1 bit: todos os modelos de idiomas grandes estão em 1,58 bits" . Shuming Ma, Hongyu Wang, Lingxiao MA, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei. 2024. [Papel]
- Squeezellm: "Squeezellm: quantização densa e escolar" . Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer. ICML 2024. [Paper] [Github]
- JSQ: "Comprimindo modelos de linguagem grande por escarsificação e quantização articular" . Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, Xianglong Liu. ICML 2024. [Paper] [Github]
- FrameQuant: "FrameQuant: quantização flexível de baixo bit para transformadores" . Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh. 2024. [Paper] [Github]
- Billm: "Billm: empurrando o limite de quantização pós-treinamento para LLMs" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [Paper] [Github]
- LQER: "LQER: reconstrução de erro de quantização de baixa rank para LLMS" . Cheng Zhang, Jianyi Cheng, George A. Constantinides, Yiren Zhao. ICML 2024. [Paper] [Github]
- I-llm: "I-llm: inferência eficiente apenas para modelos de idiomas grandes de baixo bit totalmente quantizados" . Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou. 2024. [Paper] [Github]
- Tuneamento PV: "Tunagem PV: além da estimativa direta para a compressão extrema LLM" . Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik. 2024. [Papel]
- PEQA: "Ajuste fino com eficiência de memória de modelos de linguagem grande compactada via quantização inteira sub-4 bits" . Jeenghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee. Nips 2023. [Papel]
- Qlora: "Qlora: Finetuning eficiente de LLMs quantizados" . Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke ZettleMoyerauthores Informações e reivindicações. Nips 2023. [Paper] [Github]
Técnicas LLM para SLMS
- Ma et al.: "Modelo de idioma grande não é um bom extrator de informações de poucos anos, mas um bom re-reranício para amostras duras!" . Yubo Ma, Yixin Cao, Yongching Hong, Aixin Sun. EMNLP 2023. [Paper] [Github]
- MOQE: "Mistura de especialistas quantizados (MOQE): efeito complementar da quantização e robustez de baixo bit" . Young Jin Kim, Raffy Fahim, Hany Hassan Awadalla. 2023. [Papel]
- SLM-RAG: "Os pequenos modelos de idiomas com geração de recuperação com agente de recuperação substituem grandes modelos de linguagem ao aprender ciência da computação?" . Suqing Liu, Zezhu Yu, Feiran Huang, Yousef Bulbulia, Andreas Bergen, Michael Liut. Iticse 2024. [Papel]
Aplicativos SLM específicos de tarefas
SLM em controle de qualidade
- ALPACA: "Alpaca: um modelo forte e replicável de seguir as seguintes" . Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto. 2023. [Paper] [Github] [Huggingface] [Site]
- Estável beluga 7b: "estável beluga 2" . Mahan, Dakota e Carlow, Ryan e Castricato, Louis e Cooper, Nathan e Laforte, Christian. 2023. [Huggingface]
- Biogpt de ajuste fino Guo et al.: "Melhorando os pequenos modelos de idiomas no PubMedqa por aumento de dados generativos" . Zhen Guo, Peiqi Wang, Yanwei Wang, Shangdi Yu. 2023. [Papel]
- SLMs financeiros: "Modelos de idiomas menores de ajuste fino para responder a perguntas sobre documentos financeiros" . Karmvir Singh Phogat Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, Shashishekar Ramakrishna. 2024. [Papel]
- Colbert: "Colbert Recuperação e a pontuação de respostas para o modelo de resposta para o modelo de resposta" . Alex Gichamba, Tewodros Kederalah Idris, Brian Ebiyau, Eric Nyberg, Teruko Mitamura. IEEE 2024. [Papel]
- T-SAS: "Modelos de idiomas pequenos de teste de tempo de teste para responder a perguntas" . Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park. ACL 2023. [Paper] [Github]
- Classificação da justificativa: "Respondendo a perguntas invisíveis com modelos de idiomas menores usando geração justificativa e recuperação densa" . Tim Hartill, Diana Benavides-Prado, Michael Witbrock, Patricia J. Riddle. 2023. [Papel]
SLM na codificação
- Phi-3.5-mini: "Relatório técnico PHI-3: um modelo de idioma altamente capaz localmente no seu telefone" . Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, ..., Chunyu Wang, Guanhua Wang, Lijuan Wang et al. 2024. [Paper] [Huggingface] [Site]
- Tinyllama: "Tinyllama: um modelo de idioma pequeno de código aberto" . Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu. 2024. [Paper] [Huggingface] [Demo de bate -papo] [Discord]
- Codellama: "Código Llama: Modelos de fundação aberta para código" . Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, ..., Nicolas Usunier, Thomas Scialom, Gabrynnaeve. 2024. [Paper] [Huggingface]
- CodeGemma: "CodeGemma: modelos de código aberto baseados em gemma" . Equipe de Codegemma: Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christopher A. Choquette-choo, Jingyue Shen, Joe Kelley, Kshitij Bansal, ..., Kathy Korevec. 2024. [Paper] [Huggingface]
SLM em recomendação
- Promptrec: "Os pequenos modelos de idiomas poderiam servir como recomendadores? Para recomendações de partida a frio centradas em dados" . Xuansheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu. 2024. [Paper] [Github]
- Slim: "Os pequenos modelos de idiomas podem ser bons motivos para recomendação seqüencial?" . Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, Xiao Wang. 2024. [Papel]
- BillP: "Os grandes modelos de idiomas são planejadores aprendidos para recomendação de longo prazo" . Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, Fuli Feng. 2024. [Papel]
- Uma vez: "Uma vez: aumentando a recomendação baseada em conteúdo com modelos de idiomas grandes e de código fechado e de código fechado" . Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu. WSDM 2024. [Paper] [Github]
- Reclora: "Adaptação personalizada ao longo da vida de modelos de idiomas grandes para recomendação" . Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, arruinando Tang, Yong Yu, Weinan Zhang. 2024. [Papel]
SLM na pesquisa na web
- Codificador de conteúdo: "Tarefas de pré-treinamento para incorporar a recuperação em larga escala" . Wei-Cheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, Sanjiv Kumar. ICLR 2020. [Papel]
- Poli-codificadores: "poli-codificadores: arquiteturas de transformadores e estratégias de pré-treinamento para pontuação rápida e precisa de várias frases" . Samuel Humau, Kurt Shuster, Marie-Anne Lachaux, Jason Weston. ICLR 2020. [Papel]
- Twin-Bert: "Twinbert: destilar o conhecimento de modelos Bert de estrutura dupla para recuperação eficiente" . Wenhao Lu, Jian Jiao, Ruofei Zhang. 2020. [Papel]
- H-Nernie: "H-Nernie: Um modelo de idioma pré-treinado com várias granularidade para pesquisa na web" . Xiaokai Chu, Jiashu Zhao, Lixin Zou, Dawei Yin. Sigir 2022. [Papel]
- Ranker: "Passagem re-ranking com Bert" . Rodrigo Nogueira, Kyunghyun Cho. 2019. [Paper] [Github]
- REWRITER: "Reescrita de consulta para grandes modelos de idiomas de recuperação de recuperação" . Xinbei MA, Yeyun Gong, Pengcheng He, Hai Zhao, Nan Duan. EMNLP2023. [Papel] [Github]
SLM em dispositivos móveis
- Octopus: "Octopus: modelo de idioma no dispositivo para chamadas de função de APIs de software" . Wei Chen, Zhiyuan Li, Mingyuan MA. 2024. [Paper] [Huggingface]
- Mobileagent: "Mobile-Agent-V2: Assistente de operação de dispositivos móveis com navegação eficaz por colaboração multi-agente" . Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang. 2024. [Paper] [Github] [Huggingface]
- Revolucionando a interação móvel: "Revolucionando a interação móvel: permitindo um parâmetro de 3 bilhões GPT LLM no celular" . Samuel Carreira, Tomás Marques, José Ribeiro, Carlos Grilo. 2023. [Papel]
- Autodroid: "Autodroid: Automação de tarefas movida a LLM no Android" . Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, Yunxin Liu. 2023. [Papel]
- Agente de dispositivos para reescrita de texto: "em direção a um agente no dispositivo para reescrita por texto" . Yun Zhu, Yinxiao Liu, Felix Stahlberg, Shankar Kumar, Yu-Hui Chen, Liangchen Luo, Lei Shu, Renjie Liu, Jindong Chen, Lei Meng. 2023. [Papel]
Técnicas de otimização de implantação no dispositivo
Otimização da eficiência da memória
- Edge-llm: "Edge-llm: permitindo uma adaptação eficiente de modelos de linguagem em dispositivos de borda por meio de compressão unificada em camadas e ajuste e votação de camada adaptativa" . Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran você, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin. 2024. [Paper] [Github]
- LLM-PQ: "LLM-PQ: Servindo LLM em clusters heterogêneos com partição com reconhecimento de fase e quantização adaptativa" . Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu. 2024. [Paper] [Github]
- AWQ: "AWQ: quantização de peso com consciência de ativação para compactação e aceleração LLM" . Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han. MLSYS 2024. [Paper] [Github]
- MobileAibench: "MobileAibench: Benchmarking LLMS e LMMS para casos de uso no dispositivo" . Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savaresel. 2024. [Paper] [Github]
- MOBILELLM: "MOBILELLM: Otimizando os modelos de linguagem de parâmetros de sub-bilhões para casos de uso no dispositivo" . Zechun Liu, Changsheng Zhao, Forrest Indola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra. ICML 2024. [Paper] [Github] [Huggingface]
- Edgemoe: "Edgemo: inferência rápida no dispositivo de grandes modelos de idiomas baseados em MOE" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [Paper] [Github]
- ENGRENAGEM: "ENGRENAGEM: Uma receita eficiente de compressão de cache KV para inferência generativa de LLM quase sem perda de perda" . Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao. 2024. [Paper] [Github]
- DMC: "Compressão de memória dinâmica: Retrofitting LLMS para inferência acelerada" . Piotr Nawrot, Adrian łańcucki, Marcin ChoChowski, David Tarjan, Edoardo M. Ponti. 2024. [Papel]
- Transformer-Lite: "Transformer-Lite: implantação de alta eficiência de grandes modelos de idiomas nas GPUs de telefone celular" . Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie. 2024. [Papel]
- LLMAAs: "LLM como um serviço de sistema em dispositivos móveis" . Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu. 2024. [Papel]
Otimização da eficiência do tempo de execução
- Edgemoe: "Edgemo: inferência rápida no dispositivo de grandes modelos de idiomas baseados em MOE" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [Paper] [Github]
- LLMCAD: "LLMCAD: Inferência de modelo de linguagem grande e escalável e escalável no dispositivo" . Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu. 2023. [Papel]
- Lingualinked: "Lingualinked: um sistema de inferência de modelo de linguagem grande distribuído para dispositivos móveis" . Junchen Zhao, música de Yurun, Simeng Liu, Ian G. Harris, Sangeetha Abdu Jyothi. 2023 [papel]
SLMS APRONECIMENTO LLMS
SLMS para calibração LLM e detecção de alucinação
- Calibrar modelos de linguagem grandes usando apenas suas gerações. Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, Seong Joon OH . ACL 2024 Long, [PDF] [Código]
- Aprendizagem ideal de Pareto para estimar grandes erros de modelo de linguagem. Theodore Zhao, Mu Wei, J. Samuel Preston, Hoifung Poon . ACL 2024 Long, [PDF]
- O estado interno de um LLM sabe quando está mentindo. Amos Azaria, Tom Mitchell . Descobertas do EMNLP 2023. [PDF]
- O pequeno agente também pode arrasar! Capacitando pequenos modelos de idiomas como detector de alucinação. Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen. EMNLP 2024 Long. [PDF]
- Reconfidencing LLMS da perspectiva de perda de agrupamento. Lihu Chen, Alexandre Perez-Lebel, Fabian M. Suchanek, Gaël Varoquaux. Descobertas do EMNLP 2024. [PDF]
SLMS para LLM Rag
- Modelos pequenos, grandes idéias: alavancando modelos Slim Proxy para decidir quando e o que recuperar para o LLMS. Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen. ACL 2024 Long. [PDF] [Code] [Huggingface]
- Auto-RAG: Aprendendo a recuperar, gerar e criticar através da auto-reflexão. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi. ICLR 2024 ORAL. [PDF] [Huggingface] [Code] [Site] [Model] [Data]
- Longllmlingua: acelerando e aprimorando LLMs em cenários de contexto de longo prazo por meio de compactação imediata. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu. ICLR 2024 Workshop ME-FOMO Poster. [PDF]
- Geração aumentada de recuperação corretiva. Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling. ARXIV 2024.1. [PDF] [Código]
- Autorização de recuperação guiada de autoconhecimento para grandes modelos de idiomas. Yile Wang, Peng Li, Maosong Sun, Yang Liu. Descobertas do EMNLP 2023. [PDF] [Código]
- Modelos de linguagem de recuperação de recuperação no contexto. Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. TACL 2023. [PDF] [Código]
- RA-MISS: Aprendendo a responder e entender o aumento da recuperação por meio de auto-alimentação iterativa. Liu, Yanming e Peng, Xinyue e Zhang, Xuhong e Liu, Weihao e Yin, Jianwei e Cao, Jiannan e Du, Tianyu. ACL 2024 ACLUTAS. [PDF]
- Menos é mais: tornando os modelos de idiomas menores Retrievers de subgrafias competentes para o Multi-hop {kgqa}. Wenyu Huang, Guancheng Zhou, Hongru Wang, Pavlos Vougiouklis, Mirella Lapata, Jeff Z. Pan. Descobertas do EMNLP 2024. [PDF]
SLMS para o raciocínio LLM
- Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu e Julian McAuley. Modelos pequenos são plug-ins valiosos para grandes modelos de linguagem. ACL 2024 ACLUTAS. [PDF]
- Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen e Yue Zhang. O conhecimento supervisionado torna os grandes modelos de idiomas melhores alunos do contexto. Pôster ICLR 2024. [PDF]
- Zhuofeng Wu, ele Bai, Aonan Zhang, Jiatao Gu, Vg Vydiswaran, Navdeep Jaitly e Yizhe Zhang. Dividir ou conquistar? Qual parte você deve destilar seu LLM? Descobertas do EMNLP 2024. [PDF]
SLMs para aliviar os direitos autorais e a privacidade do LLMS
- Tianlin Li, Qian Liu, Tianyu Pang, Chao DU, Qing Guo, Yang Liu e Min Lin. Purificar grandes modelos de linguagem, conjunto de um pequeno modelo de idioma. Arxiv 2024. [PDF]
SLMS para extrair prompts LLM
- Yiming Zhang, Nicholas Carlini e Daphne Ippolito. Extração imediata eficaz dos modelos de linguagem. Colm 2024 [PDF]
- Zeyang Sha e Yang Zhang. Roubar ataques prontos contra grandes modelos de linguagem. Arxiv (2024). [PDF]
- Collin Zhang, John X Morris e Vitaly Shmatikov. Extração de avisos invertendo saídas LLM. [PDF]
SLMS para LLMs de ajuste fino
- Eric Mitchell, Rafael Rafailov, Sharma, Chelsea Finn e Christopher D Manning. 2024. Um emulador para modelos de linguagem grande e fino usando modelos de idiomas pequenos. ICLR 2024. [PDF]
- Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi e Noah A Smith. 2024. Modelos de linguagem de ajuste por proxy. Colm 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen e Jingbo Shang. 2024. Os modelos de linguagem menor são capazes de selecionar dados de treinamento de ajuste de instrução para modelos de idiomas maiores. ACL 2024 ACLUTAS. [PDF]
- Yongheng Deng, Ziqing Qiao, Ju Ren, Yang Liu e Yaoxue Zhang. 2023. Melhoramento mútuo de modelos de linguagem grande e pequena com transferência de conhecimento em silolos. ARXIV 2023. [PDF]
- Smalltolarge (S2L): Seleção de dados escaláveis para modelos de linguagem de grande ajuste, resumindo as trajetórias de treinamento de pequenos modelos. Yu Yang · Siddhartha Mishra · Jeffrey Chiang · Baharan mirzasoleiman. Poster 2024 NIPS. [PDF]
- Pesquisa fraca a forte: alinhe grandes modelos de linguagem através da pesquisa em pequenos modelos de idiomas. ZHANHUI ZHOU · Zhixuan Liu · Jie Liu · Zhichen Dong · Chao Yang · Yu Qiao. Poster 2024 NIPS. [PDF]
SLMS para segurança LLM
- Guarda da LLama: LLM Basey Input-Output Saveguard para conversas em humanos-AI. Meta Arxiv 2024 [PDF]
- SLM como Guardian: Segurança pioneira na IA com um pequeno modelo de idioma. Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Ino Kang, Sun Kim, Taiwoo Park. EMNLP 2024. [PDF]
SLM para avaliação de LLM
- Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin e Liang Zhan . 2024. Slide: Uma estrutura que integra modelos de idiomas pequenos e grandes para avaliação de diálogos de domínio aberto . ACL 2024 ACLUTAS. [PDF]
- Incerteza semântica: invariâncias linguísticas para estimativa de incerteza na geração de linguagem natural. Lorenz Kuhn, Yarin Gal, Sebastian Farquhar. ICLR 2023. [PDF]
- SelfceckGPT: Detecção de hallucinação de caixa preta de resistência zero para modelos generativos de grandes idiomas. Potsawee Manakul, Adian Liusie, Mark Gales. EMNLP 2023 Main. [PDF]
- Proxilm: previsão do desempenho do modelo de linguagem em tarefas multilíngues por meio de modelos proxy. David Anugraha, Genta Indra Winata, Chenyue Li, Patrick Amadeus Irawan, En-Shiun Annie Lee. Arxiv 2024. [PDF]
- FACTSCORE: Avaliação atômica de granulação fina da precisão factual na geração de texto de forma longa. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hannaneh Hajishirzi. EMNLP 2023 Main. [PDF]
- Olhe antes de saltar: um estudo exploratório da medição da incerteza para grandes modelos de idiomas. Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, Lei Ma Arxiv 2023. [PDF]
História da estrela


