SLM -опрос
Комплексное обследование моделей малых языков: технологии, приложения на девице, эффективность, улучшения для LLM и надежность
Это репо включает в себя документы, обсуждаемые в нашей последней статье по опросам о моделях мелких языков.
Прочитайте полную бумагу здесь: бумажная ссылка
Новости
- 2024/11/04: первая версия нашего опроса на Arxiv!
Ссылка
Если наш опрос полезен для вашего исследования, пожалуйста, цитируйте нашу статью:
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
Обзор SLMS
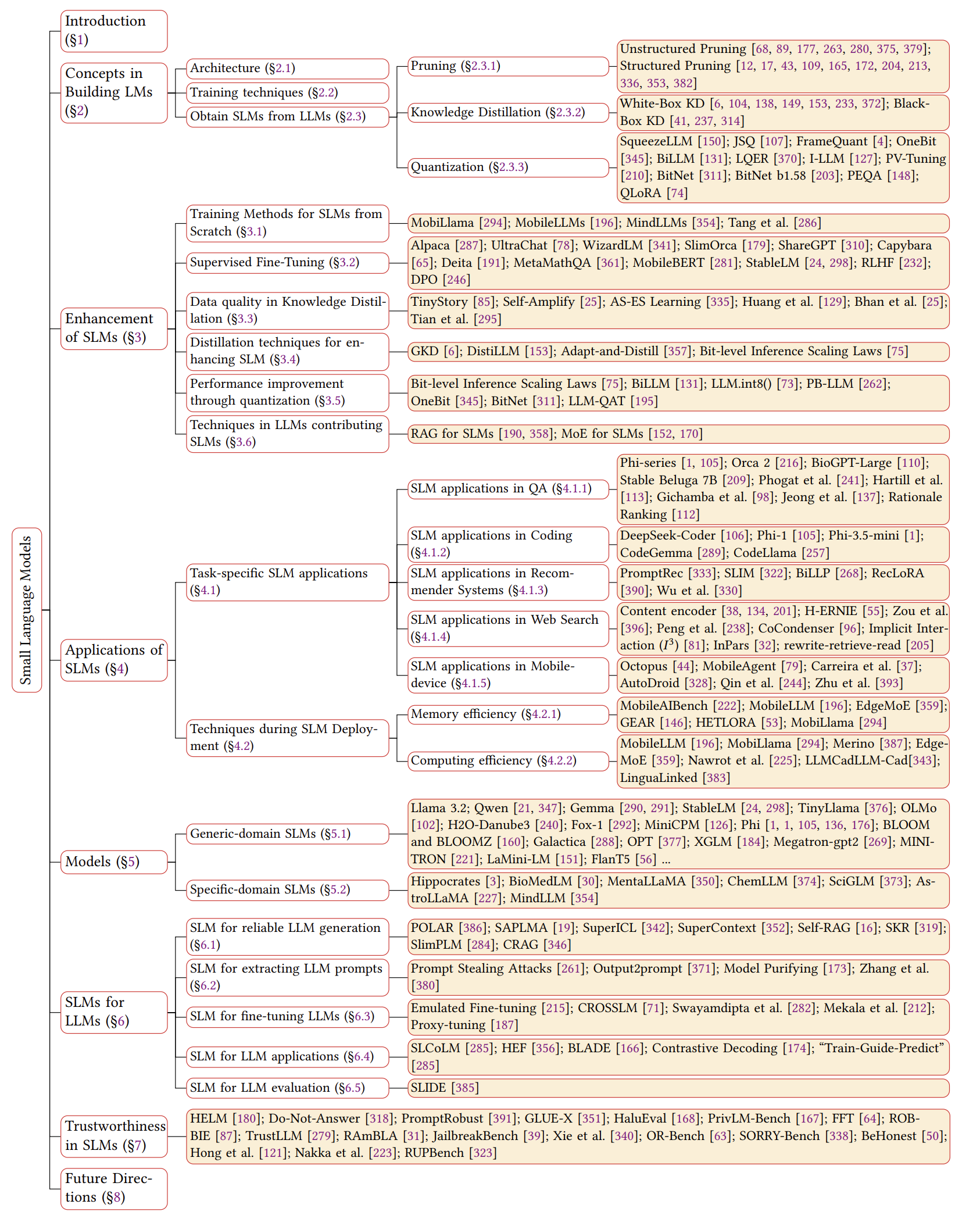
Временная шкала SLMS
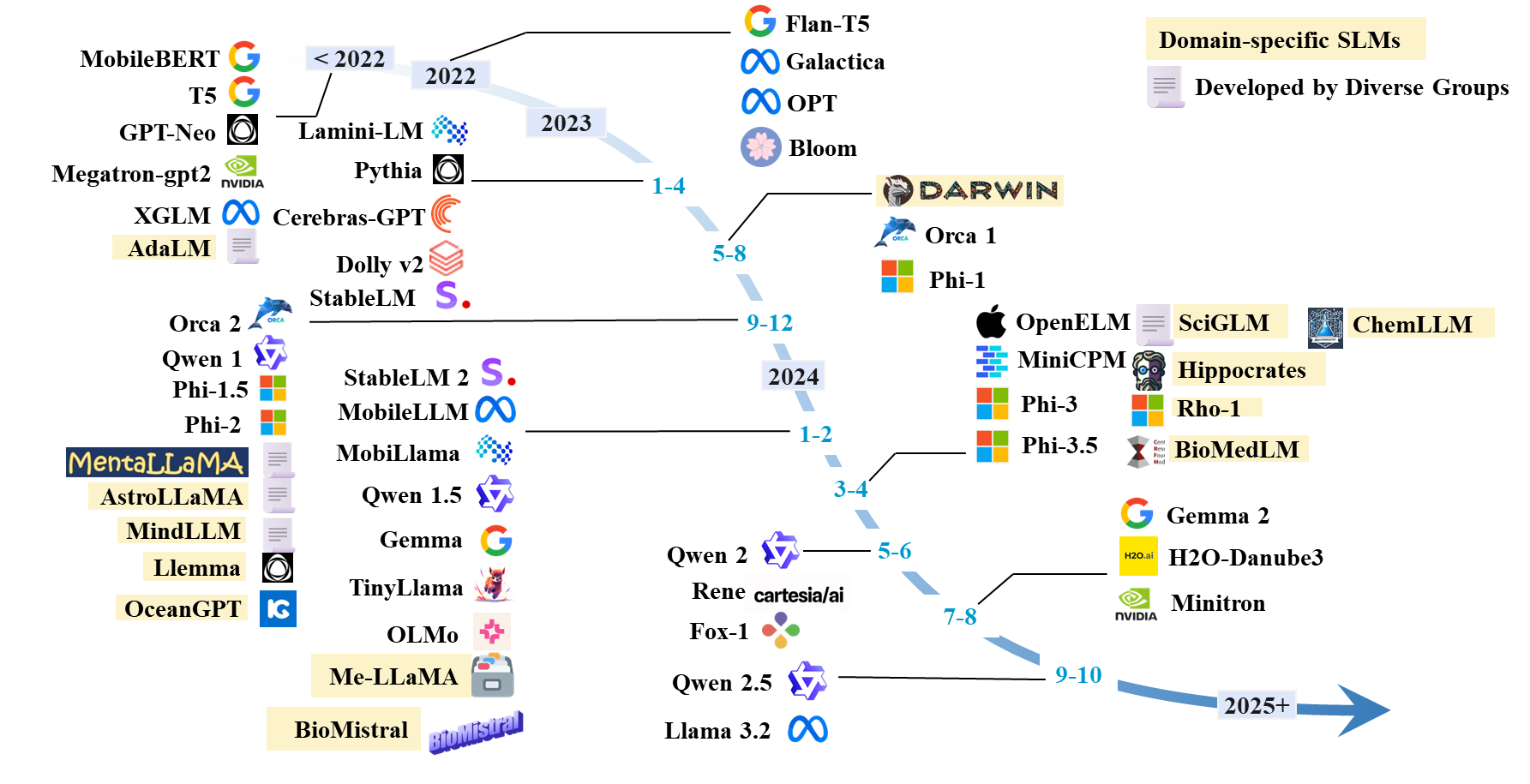
Список бумаги SLMS
Существующие SLM
| Модель | #Парамы | Дата | Парадигма | Домен | Код | Модель HF | Бумага/блог |
|---|
| Лама 3.2 | 1b; 3B | 2024.9 | Предварительный тренировки | Общий | GitHub | Hf | Блог |
| Qwen 1 | 1,8B; 7b; 14b; 72b | 2023.12 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| QWEN 1.5 | 0,5B; 1,8B; 4b; 7b; 14b; 32b; 72b | 2024.2 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Qwen 2 | 0,5B; 1,5B; 7b; 57b; 72b | 2024.6 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| QWEN 2.5 | 0,5B; 1,5B; 3b; 7b; 14b; 32b; 72b | 2024.9 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Джемма | 2b; 7b | 2024.2 | Предварительный тренировки | Общий | | Hf | Бумага |
| Джемма 2 | 2b; 9b; 27b | 2024,7 | Предварительный тренировки | Общий | | Hf | Бумага |
| H2O-Danube3 | 500 м; 4B | 2024,7 | Предварительный тренировки | Общий | | Hf | Бумага |
| LLM-neo | 1B | 2024.11 | Непрерывное обучение | Общий | | Hf | Бумага |
| Fox-1 | 1,6B | 2024.6 | Предварительный тренировки | Общий | | Hf | Блог |
| Рене | 1.3b | 2024,5 | Предварительный тренировки | Общий | | Hf | Бумага |
| Minicpm | 1.2b; 2.4b | 2024.4 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Ольмо | 1b; 7b | 2024.2 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Тиниллама | 1B | 2024.1 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| PHI-1 | 1.3b | 2023,6 | Предварительный тренировки | Кодирование | | Hf | Бумага |
| PHI-1.5 | 1.3b | 2023,9 | Предварительный тренировки | Общий | | Hf | Бумага |
| Phi-2 | 2.7b | 2023.12 | Предварительный тренировки | Общий | | Hf | Бумага |
| PHI-3 | 3.8b; 7b; 14b | 2024.4 | Предварительный тренировки | Общий | | Hf | Бумага |
| PHI-3,5 | 3.8b; 4.2b; 6,6B | 2024.4 | Предварительный тренировки | Общий | | Hf | Бумага |
| Openelm | 270 м; 450 м; 1.1b; 3B | 2024.4 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Мобиллама | 0,5B; 0,8B | 2024.2 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Mobilellm | 125 м; 350м | 2024.2 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Стаблм | 3b; 7b | 2023,4 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Стаблм 2 | 1,6B | 2024.2 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Cerebras-Gpt | 111M-13b | 2023,4 | Предварительный тренировки | Общий | | Hf | Бумага |
| Блум, Блумз | 560 м; 1.1b; 1,7B; 3b; 7.1b; 176b | 2022.11 | Предварительный тренировки | Общий | | Hf | Бумага |
| Опт | 125 м; 350 м; 1,3b; 2.7b; 5,7B | 2022,5 | Предварительный тренировки | Общий | | Hf | Бумага |
| XGLM | 1,7B; 2.9b; 7,5B | 2021.12 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| GPT-neo | 125 м; 350 м; 1,3b; 2.7b | 2021.5 | Предварительный тренировки | Общий | GitHub | | Бумага |
| Мегатрон-GPT2 | 355 м; 2,5B; 8.3b | 2019.9 | Предварительный тренировки | Общий | GitHub | | Бумага, блог |
| Минитрон | 4b; 8b; 15B | 2024,7 | Обрезка и дистилляция | Общий | GitHub | Hf | Бумага |
| Миниверс | 7b | 2024,7 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Минимум-2 | 1b; 3B | 2023.12 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
| Минимум | 3B | 2023.11 | Обрезка и дистилляция | Общий | GitHub | Hf | Бумага |
| Orca 2 | 7b | 2023.11 | Дистилляция | Общий | | Hf | Бумага |
| Долли-В2 | 3b; 7b; 12B | 2023,4 | Настройка инструкции | Общий | GitHub | Hf | Блог |
| Lamini-lm | 61m-7b | 2023,4 | Дистилляция | Общий | GitHub | Hf | Блог |
| Специализированный флант5 | 250 м; 760 м; 3B | 2023.1 | Настройка инструкции | Общий (математика) | GitHub | - | Бумага |
| ФЛАНС5 | 80 м; 250 м; 780 м; 3B | 2022.10 | Настройка инструкции | Общий | Гихуб | Hf | Бумага |
| T5 | 60 м; 220 м; 770 м; 3b; 11b | 2019.9 | Предварительный тренировки | Общий | GitHub | Hf | Бумага |
SLM -архитектура
- Трансформатор: Внимание - это все, что вам нужно. Ашиш Васвани . Neurips 2017.
- Мамба 1: Мамба: моделирование последовательности линейного времени с селективными пространствами состояния. Альберт Гу и Три Дао . Колм 2024. [Бумага].
- Мамба 2: Трансформаторы - это SSM: обобщенные модели и эффективные алгоритмы посредством двойственности пространства структурированного состояния. Три Дао и Альберт Гу . ICML 2024. [Paper] [Код]
Улучшение для SLM
Тренировка с нуля
- Mobillama: «Mobillama: к точному и легкому полностью прозрачному GPT» . Омкар Тавар, Ашмал Ваяни, Салман Хан, Хишам Чолакал, Рао М. Анвер, Майкл Фелсберг, Тим Болдуин, Эрик П. Син, Фахад Шахбаз Хан. Arxiv 2024. [Paper] [GitHub]
- Mobilellm: «Mobilellm: оптимизация моделей языка параметров поджильонов для вариантов использования на устройствах» . Зечун Лю, Чаншенг Чжао, Форрест Яндола, Чен Лай, Юандонг Тиан, Игорь Федоров, Юньян Сионг, Эрни Чанг, Янгьян Ши, Рагураман Кришнамурти, Лянген Лай, Викас Чандра Икмл 2024.
- Переосмысление оптимизации и архитектуры для крошечных языковых моделей. Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han и Yunhe Wang. ICML 2024. [Paper] [Код]
- Mindllm: «Mindllm: перед тренировкой легкой большой языковой модели с нуля, оценки и приложений домена» . Йиже Ян, Хуашан Сан, Цзявей Ли, Рунхенг Лю, Йинхао Ли, Юхан Лю, Хейан Хуанг, Ян Гао . Arxiv 2023. [Paper] [Huggingface]
Напряженная точная настраиваемая настройка
- Прямая оптимизация предпочтений: ваша языковая модель тайно является моделью вознаграждения. Рафаэль Рафайлов, Архит Шарма, Эрик Митчелл, Кристофер Д. Мэннинг, Стефано Эрмон и Челси Финн. Neurips, 2024. [Paper] [Код]
- Улучшение языковых моделей чата за счет масштабирования высококачественных учебных разговоров. Нин Дин, Юлин Чен, Бокай Сюй, Юдзия Цинь, Чжи Чжэн, Шенгдинг Ху, Чжиюань Лю, Маосонг Солнце и Боуэн Чжоу. EMNLP 2023. [Paper] [Код]
- Slimorca: открытый набор данных GPT-4 дополненных следов рассуждений с фланком, с проверкой. Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Остин Кук, Чанвикет Вонг и «Teknium». Huggingface, 2023. [Data]
- Стэнфордская альпака: модель Llama, посвященная инструкциям. Рохан Таори, Ишаан Гулраджани, Тиани Чжан, Янн Дюбуа, Сюэхен Ли, Карлос Гесстрин, Перси Лян и Тацунори Б. Хасимото. GitHub, 2023. [Блог] [GitHub] [HuggingFace]
- OpenChat: продвижение языковых моделей с открытым исходным кодом с данными смешанного качества. Гуан Ван, Сидзи Ченг, Сяньюан Чжан, Сянганг Ли, Сен Сон и Ян Лю. ICLR, 2024.
- Обучающие языковые модели, чтобы следовать инструкциям с отзывом человека. Лонг Уян, Джеффри Ву, Сюй Цзян, Диого Алмейда, Кэрролл Уэйнрайт, Памела Мишкин, Чонг Чжан, Сандхини Агарвал, Катарина Слама, Алекс Рэй, Джон Шульман, Джейкоб Хилтон, Фрейзер Келтон, Луке Миллер, Мадди Сименс, Аманда Айлдел, Паулнер, Павл. Райан Лоу. Neurips, 2022. [Paper]
- RLHF: «Тренировочные языковые модели, чтобы следовать инструкциям с обратной связью с человека» . Лонг Оуян, Джефф Ву, Сюй Цзян, Диого Алмейда, Кэрролл Л. Уэйнрайт, Памела Мишкин, Чонг Чжан, Сандхини Агарвал, Катарина Слама, Алекс Рэй, Джон Шульман, Джейкоб Хилтон, Фрейзер Келтон, Руке Миллер, Мэдди Сименс, Аманда Аскал, Питерс -Лиййй, Паул, Паул, Паул, Паул, Пол, Паул, Паул, Паул, Паул, Паул, Паул, Паул. Лоу. 2022. [Бумага]
- Mobilebert: «Mobilebert: компактная задача-агрессивная Bert для устройств с ограниченными ресурсами» . Чжикин Солн, Хонкун Ю, Сяодан Сонг, Ренджи Лю, Йиминг Ян, Денни Чжоу. ACL 2020. [Paper] [GitHub]
- Языковые модели - это неконтролируемые многозадачные ученики. Алек Рэдфорд, Джеффри Ву, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Блог Openai, 2019. [Paper]
Качество данных в KD
- Tinystory: «Tinystories: насколько маленькие языковые модели могут быть и все еще говорить по -английски?» Полем Ронен Эльдан, Юаньжи Ли. 2023. [Paper] [Huggingfice]
- АСП: «АСС ОБУЧЕНИЕ: К Эффективному обучению кровь в небольших моделях» . Нува XI, Юхан Чен, Сенг Чжао, Хаучун Ван, Бинг Цинь, Тинг Лю. 2024. [Бумага]
- Самоализация: «Самоализация: улучшение малых языковых моделей с самостоятельными объяснениями» . Милан Бхан, Жан-Ноэль Виттаут, Николя Чесно, Мари-Жанна Лесо. 2024. [Бумага]
- Большие языковые модели могут самостоятельно заполнить. Джиасин Хуанг, Шиксиан Шейн Гу, Ле Хоу, Юэксин Ву, Сюэжи Ван, Хонкун Ю и Цзявей Хан. EMNLP 2023. [Paper]
- На пути к самосовершенствованию LLM через воображение, поиск и критику. Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi и Dong Yu. Neurips 2024. [Paper] [Код]
Дистилляция для SLM
- GKD: «Политика дистилляция языковых моделей: обучение на самоогенерированных ошибках» . Rishabh Agarwal et al. ICLR 2024. [Бумага]
- Distilllm: «Distillm: к обтекаемой дистилляции для больших языковых моделей» . Jongwoo Ko et al. ICML 2024. [Paper] [GitHub]
- Адаптируйте и дистинируйте: «Адаптируйте и дистинируйте: разработка небольших, быстрых и эффективных моделей с доменом для доменов» . Yunzhi Yao et al. ACL2021. [Бумага] [GitHub]
- AKL: «Переосмысление Kullback-Leibler Divergence в дистилляции знаний для крупных языковых моделей» . Тайцян Ву, Хаофан Тао, Цзяо Ванг, Рунминг Ян, Чжэ Чжао, Нгай Вонг. Arxiv 2024. [Paper] [GitHub]
- Весопочтеное дистилляция для сжатия, агрессия, сжатия Берта , Тайцян Ву, Ченг Ху, Шаншан Лао, Цзяйи Ли, Нгай Вонг, Чжэ Чжао, Юдзиу Ян Наакл, 2024, [бумага] [Код]
Квантование
- Swackquant: «Speakquant: точная и эффективная квантование после тренировки для крупных языковых моделей» . Гуанксуань Сяо, Джи Лин, Микаэль Сезнек, Хао Ву, Жюльен Демут, Сонг Хан. ICML 2023. [Paper] [GitHub] [слайды] [Видео]
- Биллм: «Биллм: продвижение предела квантования после тренировки для LLMS» . Вэй Хуанг, Яндонг Лю, Хатонг Цинь, Йин Ли, Шиминг Чжан, Сянглонг Лю, Мишель Магно, Сяоджуан Ци. 2024. [Paper] [GitHub]
- LLM-QAT: «LLM-QAT: Обучение к квантованию без данных для больших языковых моделей» . Зечун Лю, Барлас Огуз, Чаншенг Чжао, Эрни Чанг, Пьер Сток, Яшар Мехдад, Янгьян Ши, Рагураман Кришнамурти, Викас Чандра. 2023. [Бумага]
- PB-LLM: «PB-LLM: частично бинаризовали большие языковые модели» . Чжихан Юань, Южхан Шан, Чжэнь Донг. ICLR 2024. [Paper] [GitHub]
- Onebit: «Onebit: к очень низкому большим языковым моделям» . Юзхуан Сюй, Сюй Хан, Зонган Ян, Шуо Ван, Цинфу Чжу, Чжиюань Лю, Вейдонг Лю, Вансиан Че. Neurips 2024. [Paper]
- Bitnet: «Bitnet: масштабирование 1-битных трансформаторов для больших языковых моделей» . Хонгю Ван, Шуминг М.А., Ли Донг, Шаохан Хуанг, Хуайджи Ван, Линсиао М.А., Фан Ян, Руипинг Ван, И Ву, Фуру Вей. 2023. [Бумага]
- Bitnet B1.58: «Эра 1-битного LLMS: все большие языковые модели находятся в 1,58 битах» . Шуминг М.А., Хонгю Ван, Линсиао М.А., Лей Ван, Венхуй Ван, Шаохан Хуан, Ли Донг, Рублянг Ван, Джилонг Сюэ, Фуру Вэй. 2024. [Бумага]
- Squeezellm: «Squeezellm: квантование с плотным и сбором» . Сехун Ким, Коулман Хупер, Амир Голами, Чжэнь Донг, Сюйю Ли, Шенг Шен, Майкл У. Махони, Курт Кейцер. ICML 2024. [Paper] [GitHub]
- JSQ: «Сжатие крупных языковых моделей путем совместной спарсификации и квантования» . Цзяньанг Го, Цзянью Ву, Зининг Ван, Цзяхенг Лю, Г.Е. Ян, Ифу Дин, Руихао Гонг, Хатонг Цин, Сянглонг Лю. ICML 2024. [Paper] [GitHub]
- Framequant: «Framequant: Гибкая квантовация с низким содержанием кусочков для трансформаторов» . Харшавардхан Адепу, Чжанпенг Зенг, Ли Чжан, Викас Сингх. 2024. [Paper] [GitHub]
- Биллм: «Биллм: продвижение предела квантования после тренировки для LLMS» . Вэй Хуанг, Яндонг Лю, Хатонг Цинь, Йин Ли, Шиминг Чжан, Сянглонг Лю, Мишель Магно, Сяоджуан Ци. 2024. [Paper] [GitHub]
- LQER: «LQER: Реконструкция ошибок квантования с низкой оценкой для LLMS» . Ченг Чжан, Цзяньи Ченг, Джордж А. Константинид, Ирен Чжао. ICML 2024. [Paper] [GitHub]
- I-LLM: «i-llm: эффективный вывод только для целочисленного только для полностью квалифицированных низкобиточных моделей больших языков» . Син Ху, Юань Ченг, Давей Ян, Чжиханг Юань, Цзяньгьонг Ю, Чен Сюй, Сифан Чжоу. 2024. [Paper] [GitHub]
- PV-настройка: «PV-настройка: за пределами прямой оценки для экстремального сжатия LLM» . Владимир Малиновский, Денис Мазур, Иван Илин, Денис Кузнделев, Константин Берлахенко, Кай Йи, Дэн Алистарх, Питер Ричтарик. 2024. [Бумага]
- PEQA: «Эффективная память тонкая настройка сжатых крупных языковых моделей посредством квантования с 4-разрядным целым числом» . Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee. Nips 2023. [Бумага]
- Qlora: «Qlora: Эффективное создание квантовых LLM» . Тим Деттмерс, Артидоро Пагнони, Ари Хольцман, Люк Зеттлемойератарс Информация и претензии. NIPS 2023. [Paper] [GitHub]
Методы LLM для SLMS
- Ma et al.: «Большая языковая модель-не хороший информационный экстрактор, а хороший переупотребление для твердых образцов!» Полем Юбо М.А., Йисин Цао, Юнчинг Хонг, Эйксин Сан. EMNLP 2023. [Paper] [GitHub]
- MOQE: «Смесь квантованных экспертов (MOQE): комплементарный эффект квантования и устойчивости с низким батом» . Молодой Джин Ким, Раффи Фахим, Хэни Хасан Авадалла. 2023. [Бумага]
- SLM-RAG: «Могут ли маленькие языковые модели с помощью поколения, полученного в поисках, заменить большие языковые модели при изучении компьютерных наук?» Полем Суцинг Лю, Зечжу Ю, Фейран Хуанг, Юсеф Булбулия, Андреас Берген, Майкл Лит. Iticse 2024. [Бумага]
Задача SLM-приложения
SLM в QA
- Альпака: «Альпака: сильная, воспроизводимая модель, связанная с инструкциями» . Рохан Таори, Ишаан Гулраджани, Тиани Чжан, Янн Дюбуа, Сюэхен Ли, Карлос Гесстрин, Перси Лян, Тацунори Б. Хасимото. 2023. [Paper] [github] [huggingface]
- Стабильная Beluga 7b: «Стабильная Beluga 2» . Махан, Дакота и Карлоу, Райан и Кастрикато, Луи и Купер, Натан и Лафорте, христианин. 2023. [Huggingface]
- Тонко настроенная Biogpt Guo et al.: «Улучшение малых языковых моделей на PubMedQA посредством увеличения генеративных данных» . Чжэнь Го, Пейки Ван, Янвей Ван, Шанди Ю. 2023. [Бумага]
- Финансовые SLM: «тонкая настройка меньших языковых моделей для вопросов, отвечая на финансовые документы» . Кармвир Сингх Фогат Кармвир Сингх Фогат, Саи Ахил Пуранам, Шридхар Дасарата, Четан Харша, Шашишекар Рамакришна. 2024. [Бумага]
- Колберт: «Поиск из поиска Колберта и Ансамбля для ответа на вопрос о языковой модели» . Алекс Гичамба, Тьюодрос Кедерала Идрис, Брайан Эбияу, Эрик Ниберг, Теруко Митамура. IEEE 2024. [Бумага]
- T-SAS: «Самоадаптивные модели с самого адаптируемых языков для ответа на вопросы» . Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park. ACL 2023. [Paper] [GitHub]
- Обоснование ранжирования: «Отвечая на невидимые вопросы с помощью более мелких языковых моделей с использованием обоснования поколения и плотного поиска» . Тим Хартил, Диана Бенавид-Прадо, Майкл Витброк, Патриция Дж. Риддл. 2023. [Бумага]
SLM в кодировании
- PHI-3,5-минутный: «Технический отчет PHI-3: высокоэффективная языковая модель локально на вашем телефоне» . Мара Абдин, Джиоти Анея, Хэни Авадалла, Ахмед Авадалла, Аммар Ахмад Аван, Нгуен Бах, Амит Бахри, Араш Бахтиари, Цзянмин Бао, Харкират Бехл, ..., Чуню Ван, Гуанхуа Ван, Лиджун Ван и др. 2024. [Paper] [HuggingFace] [Веб -сайт]
- Tinylyma: «Thinyllama: модель маленького языка с открытым исходным кодом» . Пейюан Чжан, Гуантао Зенг, Тяндуо Ван, Вэй Лу. 2024.
- Коделлама: «Код Llama: Open Foundation Models для кода» . Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Soootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, ..., Николас Усунье, Томас Скиалом, Габриэль Синневе. 2024. [Paper] [Huggingfice]
- CodeGemma: «CodeGemma: Open Code Models на основе Gemma» . Команда Codegemma: Heri Zhao, Джеффри Хуэй, Джошуа Хоуленд, Нам Нгуен, Сики Зуо, Андреа Ху, Кристофер А. Човет-Чо, Цзинюэ Шен, Джо Келли, Кшитидж Бансал, ..., Кэти Коревек, Келли Шефер, Скотт Хаффман. 2024. [Paper] [Huggingfice]
SLM в рекомендации
- PROMPTREC: «Могут ли малые языковые модели служить рекомендациями? На направлении рекомендаций, ориентированных на данные о холоде,» . Xuanssheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu. 2024. [Paper] [GitHub]
- Слим: «Могут ли маленькие языковые модели быть хорошими рассуждениями для последовательной рекомендации?» Полем Юлинг Ван, Чансин Тянь, Бинбин Ху, Янхуа Ю, Зики Лю, Чжицян Чжан, Джун Чжоу, Лян Панг, Сяо Ван. 2024. [Бумага]
- Billp: «Большие языковые модели являются обучаемыми планировщиками для долгосрочной рекомендации» . Вледо Ши, Сянган Хе, Ян Чжан, Чонминг Гао, Синьей Ли, Джижи Чжан, Цифан Ван, Фули Фэн. 2024. [Бумага]
- Однажды: «Однажды: повышение рекомендации на основе контента с большими языковыми моделями как с открытым, так и с закрытым источником» . Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu. WSDM 2024. [Paper] [GitHub]
- Reclora: «Персонализированная адаптация крупных языковых моделей с низким уровнем ранга на всю жизнь» для рекомендаций » . Цзяхен Чжу, Цзянгао Лин, Синьи Дай, Бо Чен, Ронг Шан, Цзиминг Чжу, Руиминг Тан, Юн Ю, Вайнан Чжан. 2024. [Бумага]
SLM в веб -поиске
- Контент-энкодер: «Задачи перед тренировкой для встраивания крупномасштабного поиска» . Вэй-Ченг Чанг, Феликс X. Ю, Инь-Вэнь Чанг, Йиминг Ян, Санджив Кумар. ICLR 2020. [Бумага]
- Поли-кодеры: «Поли-кодеры: архитектуры трансформаторов и стратегии предварительного обучения для быстрой и точной оценки с несколькими предложениями» . Сэмюэль Хюмо, Курт Шустер, Мари-Энн Лахау, Джейсон Уэстон. ICLR 2020. [Бумага]
- ТВИН-Берт: «Твинберт: дистилляция знаний в двойные модели BERT для эффективного поиска» . Венхао Лу, Цзянь Цзяо, Руофей Чжан. 2020. [Бумага]
- H-Ennie: «H-Ennie: модель с многоканальным языком, предварительно обученная для веб-поиска» . Сякай Чу, Цзяшу Чжао, Ликсин Зу, Давей Инь. Sigir 2022. [Paper]
- Ранкер: «Переезд переход с Бертом» . Родриго Ногейра, Кюнхён Чо. 2019. [Paper] [GitHub]
- Перезапись: «Переписывание запросов для получения больших языковых моделей поиска» . Синейбей М.А., Yeyun Gong, Pengcheng HE, Hai Zhao, Nan Duan. EMNLP2023. [Бумага] [GitHub]
SLM в мобильном устройстве
- Octopus: «Осьминог: модель языка на границе для функций вызовов программного обеспечения» . Вэй Чен, Чжиюань Ли, Миньюан М.А. 2024. [Paper] [Huggingfice]
- MobileAgent: «Mobile-Agent-V2: помощник по эксплуатации мобильного устройства с эффективной навигацией посредством многоагентного сотрудничества» . Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang. 2024. [Paper] [GitHub]
- Революционизация мобильного взаимодействия: «Революционизация мобильного взаимодействия: включение 3 миллиарда параметров GPT LLM на мобильных устройствах» . Сэмюэль Каррейра, Томас Маркес, Хосе Рибейро, Карлос Грило. 2023. [Бумага]
- AutoDroid: «AutoDroid: автоматизация задач на основе LLM в Android» . Хао Вэнь, Юнчун Ли, Гухонг Лю, Шанхуй Чжао, Тао Ю, Тоби Цзя-Джун Ли, Шики Цзян, Юнхао Лю, Якин Чжан, Юньсин Лю. 2023. [Бумага]
- Агент по перезаписи текста: «На пути к агенту для переписывания текста» . Юн Чжу, Инксиао Лю, Феликс Шталберг, Шанкар Кумар, Юю-Хуи Чен, Лянхен Луо, Лей Шу, Ренджи Лю, Джиндонг Чен, Лей Менг. 2023. [Бумага]
Методы оптимизации развертывания на границе
Оптимизация эффективности памяти
- Edge-LLM: «Edge-LLM: обеспечение эффективной адаптации модели большой языка на устройствах Edge с помощью настройки и голосования адаптивного слоя и адаптивного слоя» . Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Ян Кэти Чжао, Юньян Селин Лин. 2024. [Paper] [GitHub]
- LLM-PQ: «LLM-PQ: обслуживание LLM на гетерогенных кластерах с фазовым разделением и адаптивным квантованием» . Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu. 2024. [Paper] [GitHub]
- AWQ: «AWQ: квантование веса с активацией для сжатия и ускорения LLM» . Джи Лин, Джиамин Тан, Хаотиан Тан, Шанг Ян, Вей-Мин Чен, Вэй-Чен Ван, Гуансуан Сяо, Синью Данг, Чуан Ган, Сонг Хан. MLSYS 2024. [Paper] [GitHub]
- MobileAibench: «MobileAibench: Benderking LLMS и LMMS для вариантов использования на устройстве» . Ритеш Мурти, Лянгвей Ян, Хунтао Тан, Тулика Манодж Авальгаонкар, Иилун Чжоу, Шелби Хейнек, Сачин Десаи, Джейсон Ву, Ран Сюй, Сара Тан, Цзяньго Чжан, Чживей Лю, Ширли Кокане, Зусин Лю, Мин Зин, Хин У, Хин У, Хин, Хюн, Хин, Хин, Хин, Хин, Хин, Хин, Хин, Хун, Хуин, Хин, Хин, Хуин Сильвио Саваресел. 2024. [Paper] [GitHub]
- Mobilellm: «Mobilellm: оптимизация моделей языка параметров поджильонов для вариантов использования на устройствах» . Зечун Лю, Чаншенг Чжао, Форрест Яндола, Чен Лай, Юандонг Тиан, Игорь Федоров, Юньян Сионг, Эрни Чанг, Янгьян Ши, Рагураман Кришнамурти, Лянген Лай, Викас Чандра. ICML 2024. [Paper] [GitHub]
- Edgemoe: «Edgemoe: Быстрый вывод на крупных языковых моделях на основе MOE» . Ронгджи Йи, Ливей Го, Шиюн Вэй, Ао Чжоу, Шангуанг Ван, Менгвей Сюй. 2023. [Paper] [GitHub]
- Руководство: «передача: эффективный рецепт сжатия кэша KV для генеративного вывода LLM без луча» . Хао Канг, Цинру Чжан, Сувик Кунду, Геонва Чжонг, Закссинг Лю, Тушар Кришна, Туо Чжао. 2024. [Paper] [GitHub]
- DMC: «Динамическое сжатие памяти: модернизация LLMS для ускоренного вывода» . Петр Наврот, Адриан Ганкуки, Марцин Чохивски, Дэвид Тарджан, Эдоардо М. Понти. 2024. [Бумага]
- Transformer-Lite: «Transformer-Lite: Высокоэффективное развертывание крупных языковых моделей на графических процессорах мобильного телефона» . Лучанг Ли, Шенг Цянь, Цзе Лу, Ланси Юань, Руи Ван, Цинь Се. 2024. [Бумага]
- LLMAAS: «LLM как системная служба на мобильных устройствах» . Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu. 2024. [Бумага]
Оптимизация эффективности выполнения
- Edgemoe: «Edgemoe: Быстрый вывод на крупных языковых моделях на основе MOE» . Ронгджи Йи, Ливей Го, Шиюн Вэй, Ао Чжоу, Шангуанг Ван, Менгвей Сюй. 2023. [Paper] [GitHub]
- Llmcad: «llmcad: быстрый и масштабируемый вывод на большую языковую модель на устройстве» . Даляниг Сюй, Вангсонг Инь, Синь Цзинь, Ю Чжан, Шиюн Вей, Менгвей Сюй, Сюанесхе Лю. 2023. [Бумага]
- LingualIced: «LingualIced: распределенная система вывода с большой языковой модели для мобильных устройств» . Джунчун Чжао, Юрун Сонг, Сименг Лю, Ян Г. Харрис, Сангита Абду Джиоти. 2023 [Бумага]
SLMS улучшает LLMS
SLM для калибровки LLM и обнаружения галлюцинации
- Калибровка больших языковых моделей с использованием только своих поколений. Деннис Ульмер, Мартин Губри, Хваран Ли, Сангду Юн, Сон Джун Ох . ACL 2024 Long, [pdf] [Код]
- Парето Оптимальное обучение для оценки ошибок в больших языковых моделях. Теодор Чжао, Му Вэй, Дж. Сэмюэль Престон, Хойфунг Пун . ACL 2024 Long, [PDF]
- Внутреннее состояние LLM знает, когда он лжет. Амос Азария, Том Митчелл . EMNLP 2023 Результаты. [PDF]
- Небольшой агент также может качаться! Расширение возможностей малых языковых моделей в качестве детектора галлюцинации. Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen. EMNLP 2024 Long. [PDF]
- Reconfidencing LLM с точки зрения потери групп. Лиху Чен, Александр Перес-Лебель, Фабиан М. Суханек, Гаэль Вароку. EMNLP 2024 Результаты. [PDF]
SLM для LLM Rag
- Небольшие модели, Big Insights: используя тонкие прокси -модели, чтобы решить, когда и что получить для LLMS. Цзеюн Тан, Чжиченг Доу, Ютао Чжу, Пейдонг Го, Кун Фанг, Джи-Ронг Вэнь. ACL 2024 Long. [pdf] [код] [Huggingfice]
- Самопроизводство: научиться извлекать, генерировать и критиковать посредством саморефлексии. Акари Асай, Зециу Ву, Йижонг Ван, Авируп Сил, Ханнане Хаджиширзи. ICLR 2024 Оральный. [PDF] [HuggingFace] [Code] [Веб -сайт] [Модель] [DATA]
- Longllmlingua: ускорение и улучшение LLM в сценариях длинных контекстов посредством быстрого сжатия. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu. ICLR 2024 Workshop Me-Fomo плакат. [PDF]
- Корректирующее извлечение дополненное поколение. Ши-ци Ян, Цзя-Чен Гу, Юн Чжу, Чжэнь-хуа Лин. Arxiv 2024.1. [PDF] [Код]
- Самопознание Увеличение поиска для больших языковых моделей. Yile Wang, Peng Li, Maosong Sun, Yang Liu. EMNLP 2023 Результаты. [PDF] [Код]
- В поисках-аугированных моделях в поисках контекста. Ори Рам, Йоав Левин, Итай Далмедигос, Дор Мюльгай, Амнон Шашуа, Кевин Лейтон-Браун, Йоав Шохам. TACL 2023. [PDF] [Код]
- RA-ISF: научиться отвечать и понимать из получения поиска через итеративную обратную связь. Лю, Янминг и Пенг, Синьей и Чжан, Сюхон и Лю, Вейхао и Инь, Цзяньвей и Као, Цзяньнан и Ду, Тянью. ACL 2024 Выводы. [PDF]
- Меньше больше: сделать более мелкие языковые модели компетентными подграфами для мульти-хопа {kgqa}. Вениу Хуанг, Гуэнг Чжоу, Хонгру Ван, Павлос Вугиуклис, Мирелла Лапата, Джефф З. Пан. EMNLP 2024 Результаты. [PDF]
SLMS для рассуждения LLM
- Канвен Сюй, Йичонг Сюй, Шуоханг Ван, Ян Лю, Ченгуан Чжу и Джулиан Макоули. Небольшие модели являются ценными плагинами для больших языковых моделей. ACL 2024 Выводы. [PDF]
- Лини Ян, Шуибай Чжан, Чжуохао Ю, Гуансенг Бао, Йидонг Ван, Джиндонг Ван, Рурохен Сюй, Вэй Йе, Син Се, Вейху Чен и Юэ Чжан. Следующие знания делают крупные языковые модели лучше в контексте учеников. ICLR 2024 Плакат. [PDF]
- Zhuofeng Wu, He Bai, Aonan Zhang, Jiatao Gu, VG Vydiswaran, Navdeep Jaitly и Yizhe Zhang. Разделение или совещание? Какую часть вы должны пережить LLM? EMNLP 2024 Результаты. [PDF]
SLMS для облегчения авторских прав и конфиденциальности LLMS
- Тяньлин Ли, Цянь Лю, Тянью Панг, Чао Ду, Цин Го, Ян Лю и Мин Лин. Очищение крупных языковых моделей путем ансаммента небольшой языковой модели. Arxiv 2024. [PDF]
SLMS для извлечения подсказок LLM
- Йиминг Чжан, Николас Карлини и Дафна Ипполито. Эффективное быстрое извлечение из языковых моделей. Colm 2024 [PDF]
- Зеян Ша и Ян Чжан. Оперативная кража атак против крупных языковых моделей. Arxiv (2024). [PDF]
- Коллин Чжан, Джон Х Моррис и Виталий Шматиков. Извлечение подсказок путем инвертирования выходов LLM. [PDF]
SLM для тонкой настройки LLMS
- Эрик Митчелл, Рафаэль Рафайлов, Архит Шарма, Челси Финн и Кристофер Д. Мэннинг. 2024. Эмулятор для тонкой настройки больших языковых моделей с использованием малых языковых моделей. ICLR 2024. [PDF]
- Алиса Лю, Сяочуан Хан, Йижонг Ванг, Юлия Цветков, Йецзин Чой и Ноа А. Смит. 2024. Настройка языковых моделей по прокси. Колм 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen и Jingbo Shang. 2024. Меньшие языковые модели способны выбирать учебные данные для настройки обучения для более крупных языковых моделей. ACL 2024 Выводы. [PDF]
- Йонгенг Денг, Зики Циао, Джу Рен, Ян Лю и Яксю Чжан. 2023. Взаимное улучшение моделей крупных и мелких языков с перекрестной передачей знаний. Arxiv 2023. [PDF]
- Smalltolarge (S2L): масштабируемый выбор данных для тонкой настройки больших языковых моделей путем суммирования тренировочных траекторий небольших моделей. Ю Ян · Сиддхартха Мишра · Джеффри Чианг · Бахаран Мирзасолейман. Плакат 2024 года. [PDF]
- Слабо-сильное поиск: выровнять большие языковые модели с помощью поиска по моделям мелких языков. Zhanhui Zhou · Zhixuan Liu · Jie Liu · Zhichen Dong · Chao Yang · Yu Qiao. Плакат 2024 года. [PDF]
SLM для безопасности LLM
- Llama Guard: LLM на основе входного вывода для разговоров человека-AI. Meta arxiv 2024 [pdf]
- SLM как Guardian: новаторская безопасность искусственного интеллекта с небольшим языковым моделью. Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park. EMNLP 2024. [PDF]
SLM для оценки LLM
- Кун Чжао, Богао Ян, Чен Тан, Ченхуа Лин и Лян Чжан . 2024. Слайд: структура, интегрирующая малые и большие языковые модели для оценки диалогов с открытым доменом . ACL 2024 Выводы. [PDF]
- Семантическая неопределенность: лингвистические инварианты для оценки неопределенности в генерации естественного языка. Лоренц Кун, Ярин Гал, Себастьян Фаркухар. ICLR 2023. [PDF]
- SelfCheckgpt: Обнаружение галлюцинации черного ящика с нулевым ресурсом для генеративных моделей крупных языков. Потсави Манакул, Адиан Лиуси, Марк Гейлс. EMNLP 2023 Main. [PDF]
- Proxylm: прогнозирование производительности языковой модели на многоязычных задачах с помощью прокси -моделей. Дэвид Ануглаха, Генда Индра Вината, Ченю Ли, Патрик Амадеус Ираван, Эн-Шиун Энни Ли. Arxiv 2024. [PDF]
- FactScore: мелкозернистая атомная оценка фактической точности в генерации текста в длинной форме. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hannaneh Hajishirzi. EMNLP 2023 Main. [PDF]
- Посмотрите, прежде чем прыгнуть: исследовательское исследование измерения неопределенности для крупных языковых моделей. Юхенг Хуанг, Цзяян Сонг, Чжиджи Ван, Шенминг Чжао, Хуаминг Чен, Феликс Юэфе-Ху, Лей Ма Арксив 2023. [PDF]
Звездная история


